

文档简介:



如果说PaddleHub提供的是AI任务快速运行方案(POC),飞桨的开发套件则是比PaddleHub提供“更丰富的模型调节”和“领域相关的配套工具”,开发者基于这些开发套件可以实现当前应用场景中的最优方案(State of the Art)。
为什么这么说呢?经过前文我们已了解到,PaddleHub属于预训练模型应用工具,集成了最优秀的算法模型,开发者可以快速使用高质量的预训练模型结合Fine-tune API快速完成模型迁移到部署的全流程工作。但是在某些场景下,开发者不仅仅满足于快速运行,而是希望能在开源算法的基础上继续调优,实现最佳方案。如果将PaddleHub视为一个拿来即用的工具,飞桨的开发套件则是工具箱,工具箱中不仅包含多种多样的工具(深度学习算法模型),更包含了这些工具的制作方法(模型训练调优方案)。如果工具不合适,可以自行调整工具以便使用起来更顺手。
飞桨提供了一系列的开发套件,内容涵盖各个领域和方向:
- 计算机视觉领域:图像分割 PaddleSeg、目标检测 PaddleDetection、图像分类 PaddleClas、海量类别分类 PLSC,文字识别 PaddleOCR;
- 自然语言领域:语义理解 ERNIE;
- 语音领域:语音识别 DeepSpeech、语音合成 Parakeet;
- 推荐领域:弹性计算推荐 ElasticCTR;
- 其他领域:图学习框架 PGL、深度强化学习框架 PARL。
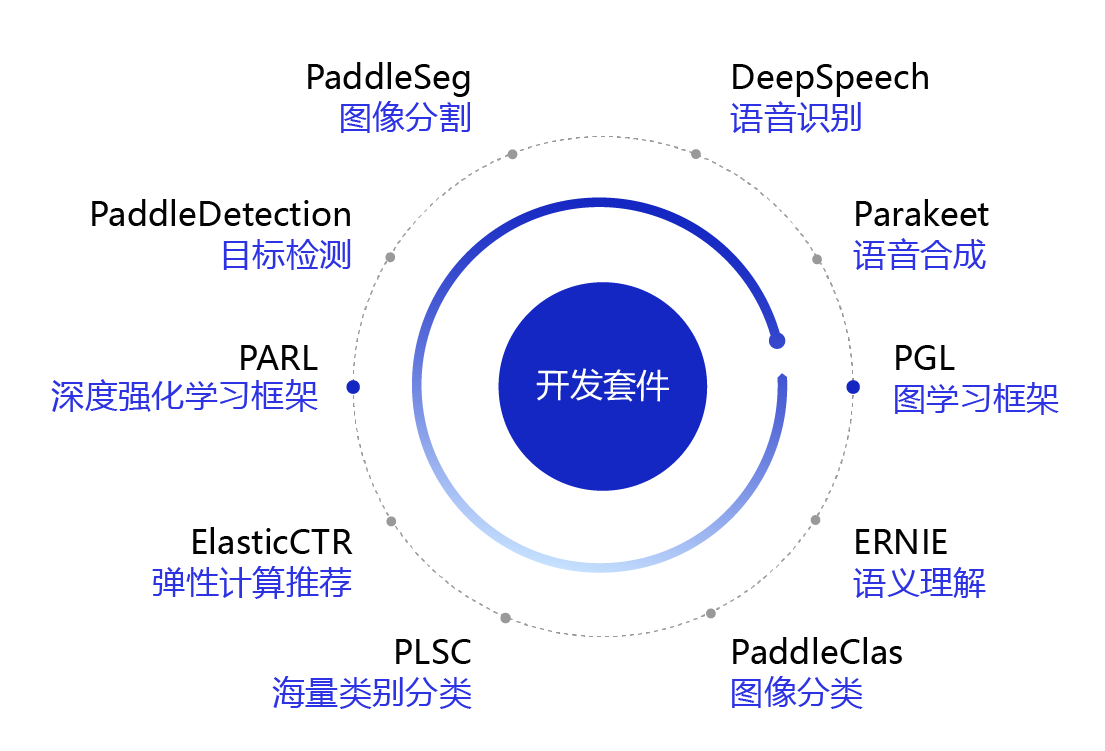
图1:飞桨开发套件
开发套件的设计具有两个特点:
- 开发套件采用模块化设计,通过“精细化定制”可以实现SOTA的产业实践模型。
- 开发套件实现了端到端的工具串联,一站式的完成“数据处理、模型训练到部署上线”全流程。 如下图展示了PaddleDet和PadddleOCR的内部组件构成,它们的设计是类似的。通过修改数据处理的方法、每阶段采用的网络结构、损失函数、部署工具的配置项或调用API即可以定制出符合自己应用场景的SOTA模型。
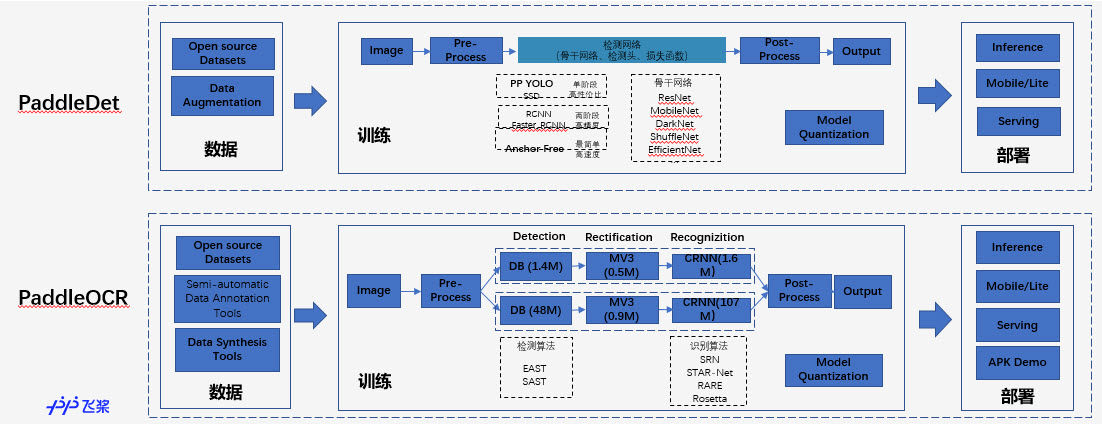
本节以PaddleSeg为例,介绍飞桨开发套件的使用方式。其余开发套件的使用模式相似,均包括快速运行的命令、丰富优化选项的配置文件和与该领域问题配套的专项工具。如果读者对其他领域有需求,可以查阅对应开发套件的使用文档。
PaddleSeg用于解决图像分割的问题
PaddleSeg是飞桨为工业界和学术界提供的一款工具箱般便捷实用的图像分割开发套件,帮助用户高效地完成图像分割任务。图像分割任务,即通过给出图像中每个像素点的标签,将图像分割成若干带类别标签的区块,可以看作对每个像素进行分类。图像分割是图像处理的重要组成部分,也是难点之一。随着人工智能的发展,图像分割技术已经在无人驾驶、视频监控、影视特效、医疗影像、遥感影像、工业质检巡检等多个领域获得了广泛的应用。
- 如果用户直接使用Python设计、编写图像分割模型并进行训练,则需要消耗较大的工作量。通过PaddleSeg来实现则只需要10行左右的代码和命令,就可以完成不同应用领域的图像分割功能,如 图2 所示。

图2:PaddleSeg的应用场景
PaddleSeg覆盖了DeepLabv3+、U-Net、PSPNet、HRNet和Fast-SCNN等20+主流分割模型,并提供了多个损失函数和多种数据增强方法等高级功能,用户可以根据使用场景从PaddleSeg中选择出合适的图像分割方案,从而更快捷高效地完成图像分割应用。
这么多种类的模型都可以解决图像分割的问题,实际该怎么选用呢?回答这个问题之前,我们先看一下典型的图像分割模型的架构,如 图3 所示。
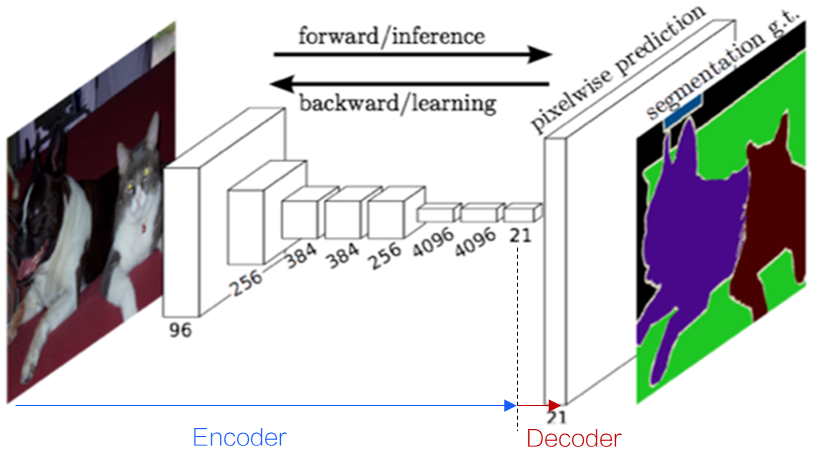
图3:图像分割模型的基本套路
观察以上网络结构,可以看到:
(1)网络的输入是H×W(H为高、W为宽)像素的图片,输出是N×H×W的概率图。前文提到,图像分割任务是对每个像素点进行分类,需要给出每个像素点是什么分类的概率,所以输出的概率图大小和输入一致(H×W),而这个N就是类别。
(2)中间的网络结构分为Encoder(编码)和Decoder(解码)两部分。Encoder部分是下采样的过程,这是为了增大网络感受野,类似于缩小地图,利于看到更大的区域范围找到区域边界;Decoder部分是上采样的过程,为了恢复像素级别的特征地图,以实现像素点的分类,类似于放大地图,标注图像分割边界时更精细。
目前多数图像分割模型都是采用这一套路,每个模型的详细介绍可以通过PaddleSeg 的文档了解。这里介绍一个比较通用的模型选择技巧:
- 如果是图像分割的初学者,则推荐使用U-Net、FCN模型。
- 如果希望以较快的速度完成训练和预测,则推荐使用Fast-SCNN、BiSeNetv2模型。
- 如果希望获得最高的精度,则推荐使用OCRNet、GSCNN模型。
PaddleSeg的特点和优势
PaddleSeg的有四方面的优势特点:
-
提供了20+个主流分割网络,50+个的高质量预训练模型。
-
提供了模块化的设计,支持不改动代码就能完成模型的深度调优。
-
在高性能计算和显存做了极致的优化。
-
同时支持配置化驱动和API调用两种应用方式,方便进行代码级别的二次研发。
如图4所示为PaddleSeg的全景图。
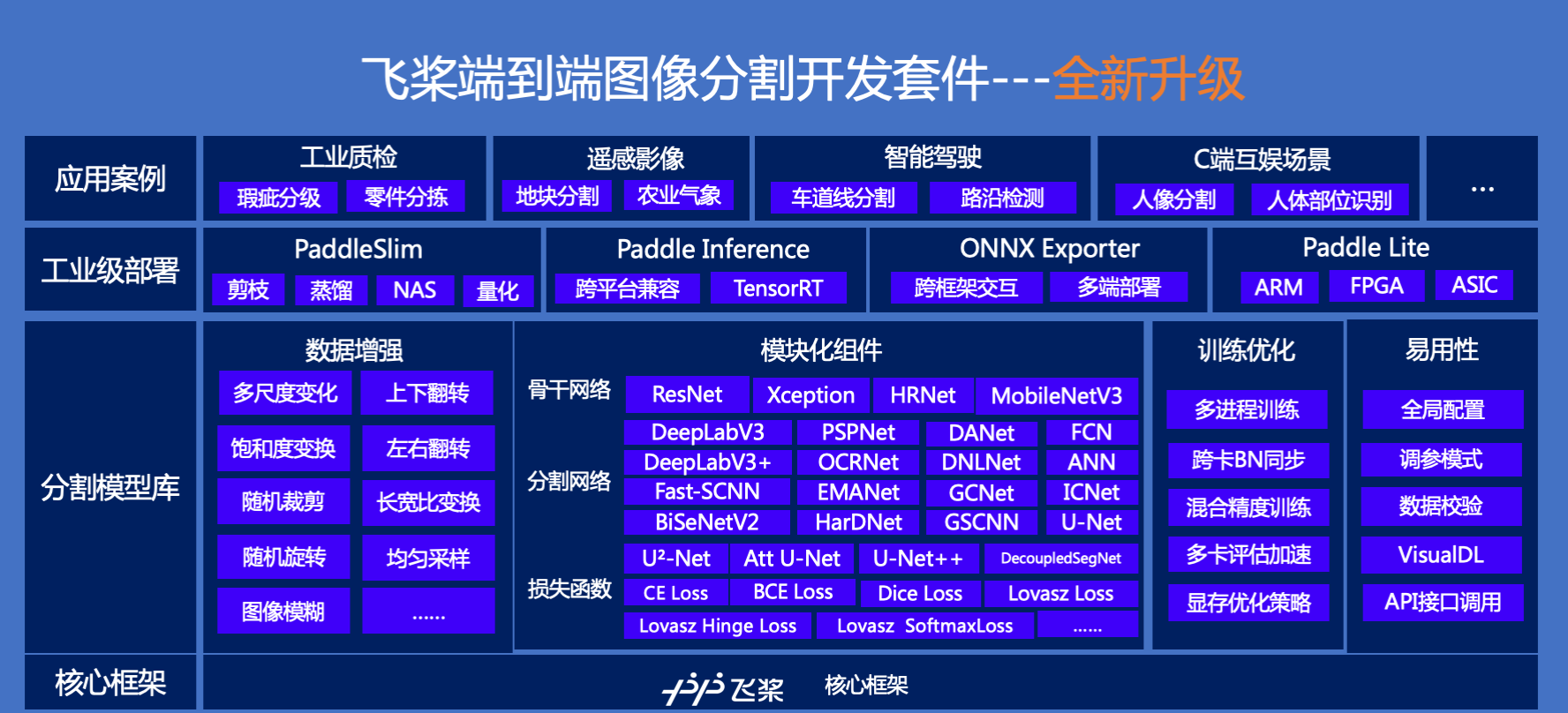
图4:PaddleSeg全景图
高精度模型
PaddleSeg提供50+种高质量预训练的分割模型,用户可以选择的预训练模型如 表1 所示。
表1 预训练模型列表
| 模型\骨干网络 | ResNet50 | ResNet101 | HRNetw18 | HRNetw48 |
|---|---|---|---|---|
| ANN | ✔ | ✔ | ||
| BiSeNetv2 | - | - | - | - |
| DANet | ✔ | ✔ | ||
| Deeplabv3 | ✔ | ✔ | ||
| Deeplabv3P | ✔ | ✔ | ||
| Fast-SCNN | - | - | - | - |
| FCN | ✔ | ✔ | ||
| GCNet | ✔ | ✔ | ||
| GSCNN | ✔ | ✔ | ||
| HarDNet | - | - | - | - |
| OCRNet | ✔ | ✔ | ||
| PSPNet | ✔ | ✔ | ||
| U-Net | - | - | - | - |
| U2-Net | - | - | - | - |
| Att U-Net | - | - | - | - |
| U-Net++ | - | - | - | - |
| DecoupledSegNet | ✔ | ✔ | ||
| EMANet | ✔ | ✔ | - | - |
| ISANet | ✔ | ✔ | - | - |
| DNLNet | ✔ | ✔ | - | - |
模块化设计
-
支持20+主流分割网络 ,结合模块化设计的数据增强策略 、骨干网络、损失函数 等不同组件,开发者可以基于实际应用场景出发,组装多样化的训练配置,满足不同性能和精度的要求。
-
提供了不同的损失函数,如Cross Entropy Loss、Dice Loss、BCE Loss等类型,通过选择合适的损失函数,可以强化小目标和不均衡样本场景下的分割精度。
高性能
PaddleSeg支持多进程异步I/O、多卡并行训练、评估等加速策略,结合飞桨核心框架的显存优化功能,可大幅度减少分割模型的训练开销,让开发者更低成本、更高效地完成图像分割训练。
易用灵活
PaddleSeg提供了配置化驱动和基于API调用的研发两种应用方式,配置化驱动比较简单、容易上手,基于API调用的研发则支持更加灵活的功能。
PaddleSeg实战
下面以BiSeNetV2和医学视盘分割数据集为例介绍PaddleSeg的配置化驱动使用方式。如果想了解API调用的使用方法,可点击PaddleSeg高级教程。
按以下几个步骤来介绍使用流程。
- 准备环境:使用PaddleSeg的软件环境,具体包括安装Python和飞桨的版本号和如何下载PaddleSeg代码库等内容
- 数据说明:用户如何自定义数据集
- 模型训练:训练配置和启动训练命令
- 可视化训练过程:PaddleSeg提供了一系列展示训练过程的可视化工具
- 模型评估:评估模型效果
- 效果可视化:使用训练好的模型进行预测,同时对结果进行可视化
- 模型导出:如何导出可进行部署的模型
- 模型部署:快速使用Python实现高效部署
1.1环境安装
在使用PaddleSeg训练图像分割模型之前,用户需要完成如下任务:
- 安装Python3.7或更高版本。
- 安装飞桨2.2或更高版本,具体安装方法请参见快速安装。由于图像分割模型计算开销大,推荐在GPU版本的PaddlePaddle下使用PaddleSeg。
- 下载PaddleSeg的代码库。
-
1.2确认环境安装成功
执行下面命令,并在PaddleSeg/output文件夹中出现预测结果,则证明安装成功
! python predict.py \ --config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \ --model_path https://bj.bcebos.com/paddleseg/dygraph/optic_disc/bisenet_optic_disc_512x512_1k/model.pdparams\ --image_path docs/images/optic_test_image.jpg \ --save_dir output/result/home/aistudio/PaddleSeg/paddleseg/models/losses/rmi_loss.py:78: DeprecationWarning: invalid escape sequence \i """ 2022-05-06 11:14:36 [INFO] ---------------Config Information--------------- batch_size: 4 iters: 1000 loss: coef: - 1 - 1 - 1 - 1 - 1 types: - type: CrossEntropyLoss lr_scheduler: end_lr: 0 learning_rate: 0.01 power: 0.9 type: PolynomialDecay model: pretrained: null type: BiSeNetV2 optimizer: momentum: 0.9 type: sgd weight_decay: 4.0e-05 train_dataset: dataset_root: data/optic_disc_seg mode: train transforms: - target_size: - 512 - 512 type: Resize - type: RandomHorizontalFlip - type: Normalize type: OpticDiscSeg val_dataset: dataset_root: data/optic_disc_seg mode: val transforms: - type: Normalize type: OpticDiscSeg ------------------------------------------------ W0506 11:14:36.319901 255 gpu_context.cc:244] Please NOTE: device: 0, GPU Compute Capability: 7.0,2. 数据集下载与说明
-
Driver API Version: 10.1, Runtime API Version: 10.1 W0506 11:14:36.319964 255 gpu_context.cc:272] device: 0, cuDNN Version: 7.6. 2022-05-06 11:14:48 [INFO] Number of predict images = 1 2022-05-06 11:14:48 [INFO] Loading pretrained model from https://bj.bcebos.com
-
/paddleseg/dygraph/optic_disc/bisenet_optic_disc_512x512_1k/model.pdparams Connecting to https://bj.bcebos.com/paddleseg/dygraph/optic_disc/bisenet_optic_disc_512x512_1k/model.pdparams Downloading model.pdparams [==================================================] 100.00% 2022-05-06 11:14:51 [INFO] There are 356/356 variables loaded into BiSeNetV2. 2022-05-06 11:14:51 [INFO] Start to predict... 1/1 [==============================] - 0s 99ms/step
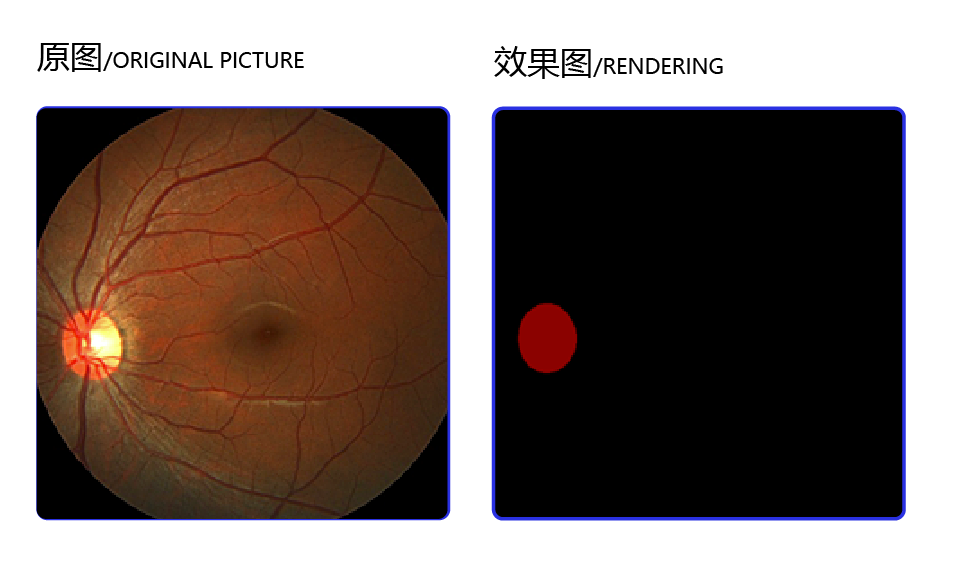
2.1数据集说明
如何使用自己的数据集进行训练是开发者最关心的事情,下面我们将着重说明一下如果要自定义数据集,我们该准备成什么样子?数据集准备好,如何在配置文件中进行改动.
2.1.1数据集说明
-
推荐整理成如下结构
-
文件夹命名为custom_dataset、images、labels不是必须,用户可以自主进行命名。
-
train.txt val.txt test.txt中文件并非要和custom_dataset文件夹在同一目录下,可以通过配置文件中的选项修改,但一般推荐整理成如下格式:
custom_dataset | |–images | |–image1.jpg | |–image2.jpg | |–… | |–labels | |–label1.png
其中train.txt和val.txt的内容如下所示: images/image1.jpg labels/label1.png images/image2.jpg labels/label2.png ...
-
| |–label2.png | |–… | |–train.txt | |–val.txt | |–test.txt
我们刚刚下载的数据集格式也与之类似(label.txt可有可以无),如果用户要进行数据集标注和数据划分,请参考文档。
我们一般推荐用户将数据集放置在PaddleSeg下的dataset文件夹下。

3.2 配置文件详细解读
在了解完BiseNetV2原理后,我们便可准备进行训练了。上文中我们谈到PaddleSeg提供了配置化驱动进行模型训练。那么在训练之前,先来了解一下配置文件,在这里我们以bisenet_optic_disc_512x512_1k.yml为例子说明,该yaml格式配置文件包括模型类型、骨干网络、训练和测试、预训练数据集和配套工具(如数据增强)等信息。
PaddleSeg在配置文件中详细列出了每一个可以优化的选项,用户只要修改这个配置文件就可以对模型进行定制(所有的配置文件在PaddleSeg/configs文件夹下面),如自定义模型使用的骨干网络、模型使用的损失函数以及关于网络结构等配置。除了定制模型之外,配置文件中还可以配置数据处理的策略,如改变尺寸、归一化和翻转等数据增强的策略。
重点参数说明:
-
1:在PaddleSeg的配置文件给出的学习率中,除了"bisenet_optic_disc_512x512_1k.yml"中为单卡学习率外,其余配置文件中均为4卡的学习率,如果用户是单卡训练,则学习率设置应变成原来的1/4。
-
2:在PaddleSeg中的配置文件,给出了多种损失函数:CrossEntropy Loss、BootstrappedCrossEntropy Loss、Dice Loss、BCE Loss、OhemCrossEntropyLoss、RelaxBoundaryLoss、OhemEdgeAttentionLoss、Lovasz Hinge Loss、Lovasz Softmax Loss,用户可根据自身需求进行更改。
-
3.4 正式开启训练
当我们修改好对应的配置参数后,就可以上手体验使用了
!export CUDA_VISIBLE_DEVICES=0 # 设置1张可用的卡 # windows下请执行以下命令2022-05-06 11:14:57 [INFO] ------------Environment Information------------- platform: Linux-4.4.0-150-generic-x86_64-with-debian-stretch-sid Python: 3.7.4 (default, Aug 13 2019, 20:35:49) [GCC 7.3.0] Paddle compiled with cuda: True NVCC: Cuda compilation tools, release 10.1, V10.1.243 cudnn: 7.6 GPUs used: 1 CUDA_VISIBLE_DEVICES: None GPU: ['GPU 0: Tesla V100-SXM2-32GB'] GCC: gcc (Ubuntu 7.5.0-3ubuntu1~16.04) 7.5.0 PaddleSeg: 2.5.0 PaddlePaddle: 2.3.0-rc0 OpenCV: 4.1.1 ------------------------------------------------ Connecting to https://paddleseg.bj.bcebos.com/dataset/optic_disc_seg.zip Downloading optic_disc_seg.zip [==================================================] 100.00% Uncompress optic_disc_seg.zip [==================================================] 100.00% 2022-05-06 11:14:59 [INFO] ---------------Config Information--------------- batch_size: 4 iters: 1000 loss: coef: - 1 - 1 - 1 - 1 - 1 types: - ignore_index: 255 type: CrossEntropyLoss lr_scheduler: end_lr: 0 learning_rate: 0.01 power: 0.9 type: PolynomialDecay model: pretrained: null type: BiSeNetV2 optimizer: momentum: 0.9 type: sgd weight_decay: 4.0e-05 train_dataset: dataset_root: data/optic_disc_seg mode: train transforms: - target_size: - 512 - 512 type: Resize - type: RandomHorizontalFlip - type: Normalize type: OpticDiscSeg val_dataset: dataset_root: data/optic_disc_seg mode: val transforms: - type: Normalize type: OpticDiscSeg ------------------------------------------------ W0506 11:14:59.152062 350 gpu_context.cc:244] Please NOTE: device: 0, GPU Compute- 结果文件
output ├── iter_500 #表示在500步保存一次模型 ├── model.pdparams #模型参数 └── model.pdopt #训练阶段的优化器参数 ├── iter_1000 ├── model.pdparams └── model.pdopt └── best_model #在训练的时候,训练时候增加--do_eval后,每保存一次模型,都会eval一次,miou最高的模型会被另存为bset_model └── model.pdparams3.5 训练参数解释
参数名 用途 是否必选项 默认值 iters 训练迭代次数 否 配置文件中指定值 batch_size 单卡batch size 否 配置文件中指定值 learning_rate 初始学习率 否 配置文件中指定值 config 配置文件 是 - save_dir 模型和visualdl日志文件的保存根路径 否 output num_workers 用于异步读取数据的进程数量, 大于等于1时开启子进程读取数据 否 0 use_vdl 是否开启visualdl记录训练数据 否 否 save_interval_iters 模型保存的间隔步数 否 1000 do_eval 是否在保存模型时启动评估, 启动时将会根据mIoU保存最佳模型至best_model 否 否 log_iters 打印日志的间隔步数 否 10 resume_model 恢复训练模型路径,如:output/iter_1000 否 None keep_checkpoint_max 最新模型保存个数 否 5 3.6 配置文件的深度探索
-
刚刚我们拿出一个BiSeNetV2的配置文件让大家去体验一下如何数据集配置,在这里例子中,所有的参数都放置在了一个yml文件中,但是实际PaddleSeg的配置文件为了具有更好的复用性和兼容性,采用了更加耦合的设计,即一个模型需要两个以上配置文件来实现,下面我们具体一DeeplabV3p为例子来为大家说明配置文件的耦合设置。
-
例如我们要更改deeplabv3p_resnet50_os8_cityscapes_1024x512_80k.yml 文件的配置,则会发现该文件还依赖(base)cityscapes.yml文件。此时,我们就需要同步打开 cityscapes.yml 文件进行相应参数的设置。
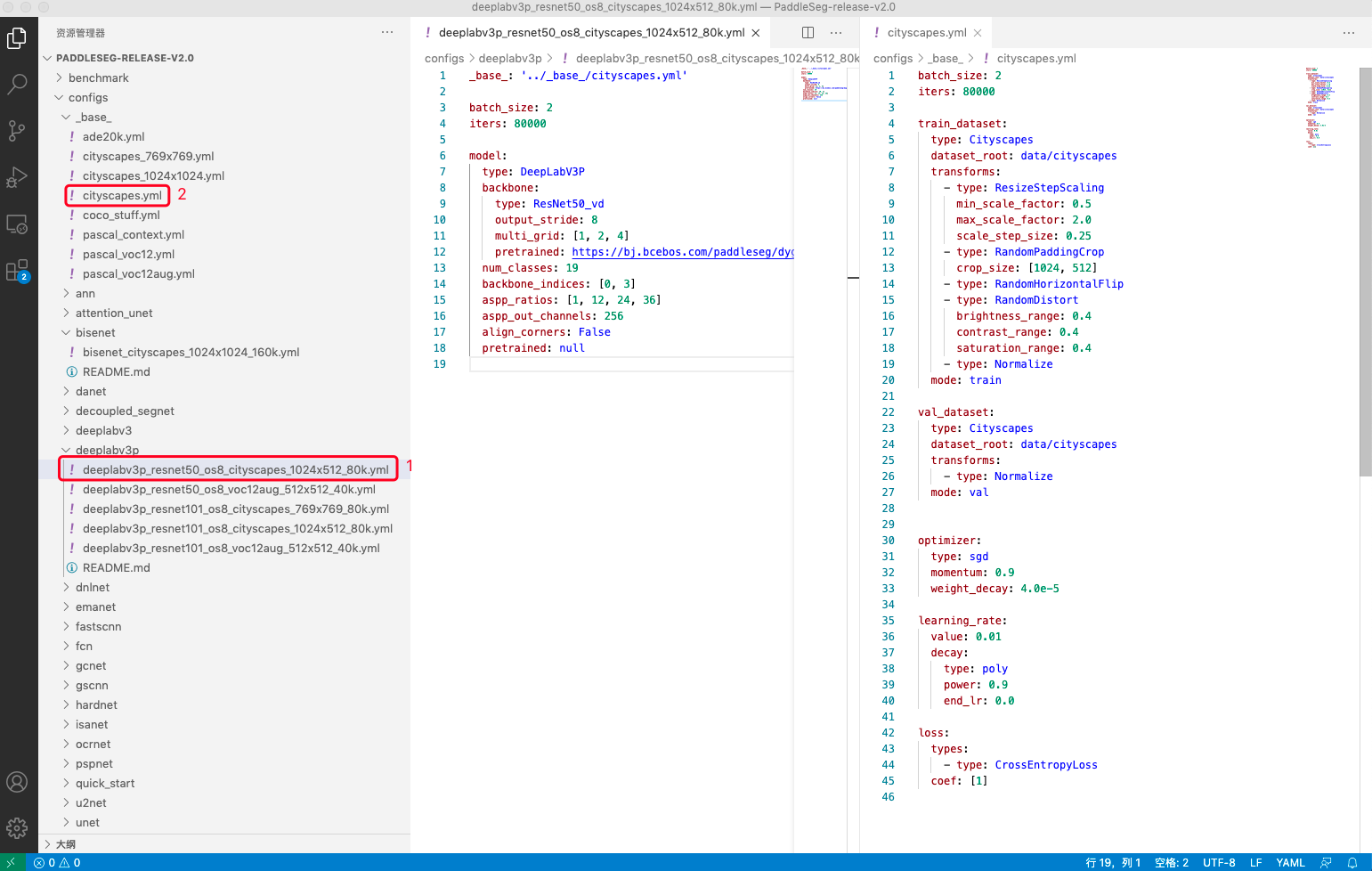
图7:配置文件深入探索
在PaddleSeg2.0模式下,用户可以发现,PaddleSeg采用了更加耦合的配置设计,将数据、优化器、损失函数等共性的配置都放在了一个单独的配置文件下面,当我们尝试换新的网络结构的是时候,只需要关注模型切换即可,避免了切换模型重新调节这些共性参数的繁琐节奏,避免用户出错。
FAQ
Q:有些共同的参数,多个配置文件下都有,那么我以哪一个为准呢?
A:如图中序号所示,1号yml文件的参数可以覆盖2号yml文件的参数,即1号的配置文件优于2号文件
3.7 多卡训练
注意:如果想要使用多卡训练的话,需要将环境变量CUDA_VISIBLE_DEVICES指定为多卡(不指定时默认使用所有的gpu),并使用paddle.distributed.launch启动训练脚本(windows下由于不支持nccl,无法使用多卡训练):
export CUDA_VISIBLE_DEVICES=0,1,2,3 # 设置4张可用的卡 python -m paddle.distributed.launch train.py \ --config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \ --do_eval \ --use_vdl \ --save_interval 500 \ --save_dir output3.8 恢复训练
python train.py \ --config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \ --resume_model output/iter_500 \ --do_eval \ --use_vdl \ --save_interval 500 \ --save_dir output- 为了更直观我们的网络训练过程,对网络进行分析从而更快速的得到更好的网络,飞桨提供了可视化分析工具:VisualDL
当打开use_vdl开关后,PaddleSeg会将训练过程中的数据写入VisualDL文件,可实时查看训练过程中的日志。记录的数据包括:
- loss变化趋势
- 学习率变化趋势
- 训练时间
- 数据读取时间
- mean IoU变化趋势(当打开了do_eval开关后生效)
- mean pixel Accuracy变化趋势(当打开了do_eval开关后生效)
使用如下命令启动VisualDL查看日志
# 下述命令会在127.0.0.1上启动一个服务,支持通过前端web页面查看,可以通过--host这个参数指定实际ip地址 visualdl --logdir output/在浏览器输入提示的网址,效果如下:
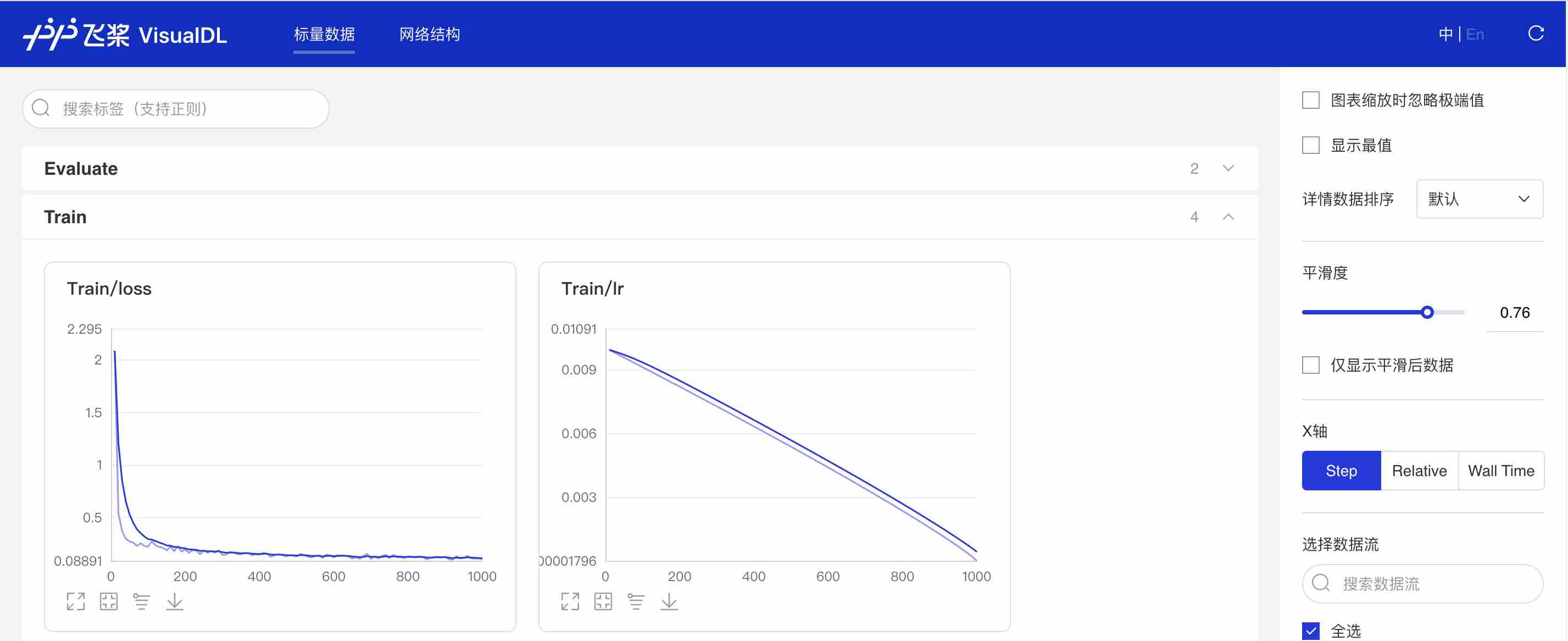
图8:VDL效果演示
训练完成后,用户可以使用评估脚本val.py来评估模型效果。假设训练过程中迭代次数(iters)为1000,保存模型的间隔为500,即每迭代1000次数据集保存2次训练模型。因此一共会产生2个定期保存的模型,加上保存的最佳模型best_model,一共有3个模型,可以通过model_path指定期望评估的模型文件。
!python val.py \ --config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \ --model_path output/iter_1000/model.pdparams2022-05-06 11:16:56 [INFO] ---------------Config Information--------------- batch_size: 4 iters: 1000 loss: coef: - 1 - 1 - 1 - 1 - 1 types: - type: CrossEntropyLoss lr_scheduler: end_lr: 0 learning_rate: 0.01 power: 0.9 type: PolynomialDecay model: pretrained: null type: BiSeNetV2 optimizer: momentum: 0.9 type: sgd weight_decay: 4.0e-05 train_dataset: dataset_root: data/optic_disc_seg mode: train transforms: - target_size: - 512 - 512 type: Resize - type: RandomHorizontalFlip - type: Normalize type: OpticDiscSeg val_dataset: dataset_root: data/optic_disc_seg mode: val transforms: - type: Normalize type: OpticDiscSeg ------------------------------------------------ W0506 11:16:56.952605 536 gpu_context.cc:244] Please NOTE: device: 0, GPU Compute如果想进行多尺度翻转评估可通过传入--aug_eval进行开启,然后通过--scales传入尺度信息, --flip_horizontal开启水平翻转, flip_vertical开启垂直翻转。使用示例如下:
python val.py \ --config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \ --model_path output/iter_1000/model.pdparams \ --aug_eval \ --scales 0.75 1.0 1.25 \ --flip_horizontal如果想进行滑窗评估可通过传入--is_slide进行开启, 通过--crop_size传入窗口大小, --stride传入步长。使用示例如下:
python val.py \ --config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \ --model_path output/iter_1000/model.pdparams \ --is_slide \ --crop_size 256 256 \ --stride 128 128在图像分割领域中,评估模型质量主要是通过三个指标进行判断,准确率(acc)、平均交并比(Mean Intersection over Union,简称mIoU)、Kappa系数。
- 准确率:指类别预测正确的像素占总像素的比例,准确率越高模型质量越好。
- 平均交并比:对每个类别数据集单独进行推理计算,计算出的预测区域和实际区域交集除以预测区域和实际区域的并集,然后将所有类别得到的结果取平均。在本例中,正常情况下模型在验证集上的mIoU指标值会达到0.80以上,显示信息示例如下所示,第3行的mIoU=0.8526即为mIoU。
- Kappa系数:一个用于一致性检验的指标,可以用于衡量分类的效果。kappa系数的计算是基于混淆矩阵的,取值为-1到1之间,通常大于0。其公式如下所示,P0P_0P0为分类器的准确率,PeP_ePe为随机分类器的准确率。Kappa系数越高模型质量越好。
Kappa=P0−Pe1−PeKappa= \frac{P_0-P_e}{1-P_e}Kappa=1−PeP0−Pe
随着评估脚本的运行,最终打印的评估日志如下。
... 2021-01-13 16:41:29 [INFO] Start evaluating (total_samples=76, total_iters=76)... 76/76 [==============================] - 2s 30ms/step - batch_cost: 0.0268 - reader cost: 1.7656e- 2021-01-13 16:41:31 [INFO] [EVAL] #Images=76 mIoU=0.8526 Acc=0.9942 Kappa=0.8283 2021-01-13 16:41:31 [INFO] [EVAL] Class IoU: [0.9941 0.7112] 2021-01-13 16:41:31 [INFO] [EVAL] Class Acc: [0.9959 0.8886]!python predict.py \ --config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \ --model_path output/iter_1000/model.pdparams \ --image_path dataset/optic_disc_seg/JPEGImages/H0003.jpg \ --save_dir output/result2022-05-06 11:17:11 [INFO] ---------------Config Information--------------- batch_size: 4 iters: 1000 loss: coef: - 1 - 1 - 1 - 1 - 1 types: - type: CrossEntropyLoss lr_scheduler: end_lr: 0 learning_rate: 0.01 power: 0.9 type: PolynomialDecay model: pretrained: null type: BiSeNetV2 optimizer: momentum: 0.9 type: sgd weight_decay: 4.0e-05 train_dataset: dataset_root: data/optic_disc_seg mode: train transforms: - target_size: - 512 - 512 type: Resize - type: RandomHorizontalFlip - type: Normalize type: OpticDiscSeg val_dataset: dataset_root: data/optic_disc_seg mode: val transforms: - type: Normalize type: OpticDiscSeg ------------------------------------------------ W0506 11:17:11.684365 589 gpu_context.cc:244] Please NOTE: device: 0, GPU Compute其中image_path也可以是一个目录,这时候将对目录内的所有图片进行预测并保存可视化结果图。
同样的,可以通过--aug_pred开启多尺度翻转预测, --is_slide开启滑窗预测。
我们选择1张图片进行查看,效果如下。我们可以直观的看到模型的切割效果和原始标记之间的差别,从而产生一些优化的思路,比如是否切割的边界可以做规则化的处理等。
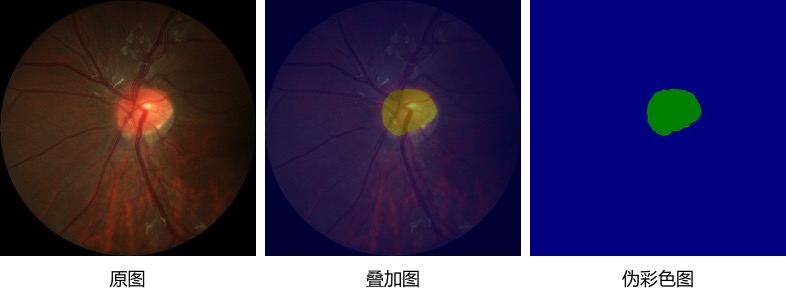
图9:预测效果展示
! python export.py \ --config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \ --model_path output/iter_1000/model.pdparamsW0506 11:17:23.453977 639 gpu_context.cc:244] Please NOTE: device: 0, GPU Compute
- 参数说明如下
参数名 用途 是否必选项 默认值 config 配置文件 是 - save_dir 模型和visualdl日志文件的保存根路径 否 output model_path 预训练模型参数的路径 否 配置文件中指定值 - 结果文件
output ├── deploy.yaml # 部署相关的配置文件 ├── model.pdiparams # 静态图模型参数 ├── model.pdiparams.info # 参数额外信息,一般无需关注 └── model.pdmodel # 静态图模型文件
- PaddleSeg目前支持以下部署方式:
端侧 库 教程 Python端部署 Paddle预测库 已完善 移动端部署 ONNX 完善中 服务端部署 HubServing 完善中 前端部署 PaddleJS 完善中 #运行如下命令,会在output文件下面生成一张H0003.png的图像 !python deploy/python/infer.py \ --config output/deploy.yaml\ --image_path dataset/optic_disc_seg/JPEGImages/H0003.jpg\ --save_dir output2022-05-06 11:17:38 [INFO] Use GPU W0506 11:17:42.305490 681 analysis_predictor.cc:1079] The one-time configuration
- 参数说明如下:
参数名 用途 是否必选项 默认值 config 导出模型时生成的配置文件, 而非configs目录下的配置文件 是 - image_path 预测图片的路径或者目录 是 - use_trt 是否开启TensorRT来加速预测 否 否 use_int8 启动TensorRT预测时,是否以int8模式运行 否 否 batch_size 单卡batch size 否 配置文件中指定值 save_dir 保存预测结果的目录 否 output 9 二次开发
- 在尝试完成使用配置文件进行训练之后,肯定有小伙伴想基于PaddleSeg进行更深入的开发,在这里,我们大概介绍一下PaddleSeg代码结构,
PaddleSeg ├── configs #配置文件文件夹 ├── paddleseg #训练部署的核心代码 ├── core ├── cvlibs # Config类定义在该文件夹中。它保存了数据集、模型配置、主干网络、损失函数等所有的超参数。 ├── callbacks.py └── ... ├── datasets #PaddleSeg支持的数据格式,包括ade、citycapes等多种格式 ├── ade.py ├── citycapes.py └── ... ├── models #该文件夹下包含了PaddleSeg组网的各个部分 ├── backbone # paddleseg的使用的主干网络 ├── hrnet.py ├── resnet_vd.py └── ... ├── layers # 一些组件,例如attention机制 ├── activation.py ├── attention.py └── ... ├── losses #该文件夹下包含了PaddleSeg所用到的损失函数 ├── dice_loss.py ├── lovasz_loss.py └── ... ├── ann.py #该文件表示的是PaddleSeg所支持的算法模型,这里表示ann算法。 ├── deeplab.py #该文件表示的是PaddleSeg所支持的算法模型,这里表示Deeplab算法。 ├── unet.py #该文件表示的是PaddleSeg所支持的算法模型,这里表示unet算法。 └── ... ├── transforms #进行数据预处理的操作,包括各种数据增强策略 ├── functional.py └── transforms.py └── utils ├── config_check.py ├── visualize.py └── ... ├── train.py # 训练入口文件,该文件里描述了参数的解析,训练的启动方法,以及为训练准备的资源等。 ├── predict.py # 预测文件 └── ...- 同学们还可以尝试使用PaddleSeg的API来自己开发,开发人员在使用pip install命令安装PaddleSeg后,仅需通过几行代码即可轻松实现图像分割模型的训练、评估和推理。 感兴趣的小伙伴们可以访问PaddleSeg动态图API使用教程
PaddleSeg等各领域的开发套件已经为真正的工业实践提供了顶级方案,有国内的团队使用PaddleSeg的开发套件取得国际比赛的好成绩,可见开发套件提供的效果是State Of The Art的。
如果想查看模型实现的源代码以便进一步优化,或者所从事的领域没有现成的开发套件支持,那就需要进一步了解飞桨提供的业界最广泛和出色的模型库了(模型实现代码全部开源),我们在下一节进行介绍。
往届优秀学员作品展示
给头像添加圣诞帽
- 项目背景
每当圣诞节来临时,大家都会把自己的QQ和微信头像加上一顶小圣诞帽。通过AI技术,有没有可能批量的生成戴圣诞帽的头像呢?
- 项目内容
通过识别图片中的人脸,针对人脸大小调整圣诞帽的大小,并放在对应位置上。
- 实现方案
运用Paddle Hub中的ultra_light_fast_generic_face_detector_1mb_320模型,对人脸进行识别,并返回人脸位置的坐标值。根据坐标值调整圣诞帽大小,并放置圣诞帽。
- 实现结果

- 项目点评
该项目使用Paddle Hub对人脸位置进行检测并返回坐标值,很好的与生活中的应用联系到一起,实用性较高。
- 项目链接 https://aistudio.baidu.com/aistudio/projectdetail/527863
目标检测简单应用——电影任务捕捉
- 项目背景
对于单张图片的人物检测已较为成熟,那如何人物检测运用到视频中呢?此项目以电影视频为例,进行在视频流中的人物检测。
- 项目内容
获取一段mp4格式的视频,经过程序,生成的新的视频中每一帧都包含了人物的检测。
- 实现方案
通过CV2读取视频中的每一帧并统计数量,再经过Paddle Hub预训练模型yolov3_resnet50_vd_coco2017,输出每一帧的检测结果,并生成新视频。
- 实现结果

-
项目点评 本项目将图片的目标检测运用在视频流中,这也是实际应用中大多数场景会采用的检测策略。不过仍存在较大的提升空间——比如可以在视频流中实时监测,那样对模型的预测速度会有更高要求。
-
项目链接 https://aistudio.baidu.com/aistudio/projectdetail/505986
-
Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0506 11:14:59.152119 350 gpu_context.cc:272] device: 0, cuDNN Version: 7.6. /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/d
-
ygraph/math_op_patch.py:259: UserWarning: The dtype of left and right variables are
-
not the same, left dtype is paddle.float32, but right dtype is paddle.int64, the righ
-
t dtype will convert to paddle.float32 format(lhs_dtype, rhs_dtype, lhs_dtype)) 2022-05-06 11:15:08 [INFO] [TRAIN] epoch: 1, iter: 10/1000, loss: 1.9352, lr:
-
0.009919, batch_cost: 0.1387, reader_cost: 0.02331, ips: 28.8454 samples/sec | ETA 00:02:17 2022-05-06 11:15:09 [INFO] [TRAIN] epoch: 1, iter: 20/1000, loss: 0.5128, lr:
-
0.009829, batch_cost: 0.0981, reader_cost: 0.00027, ips: 40.7832 samples/sec | ETA 00:01:36 2022-05-06 11:15:10 [INFO] [TRAIN] epoch: 1, iter: 30/1000, loss: 0.3835, lr:
-
0.009739, batch_cost: 0.0980, reader_cost: 0.00027, ips: 40.8305 samples/sec | ETA 00:01:35 2022-05-06 11:15:11 [INFO] [TRAIN] epoch: 1, iter: 40/1000, loss: 0.3233, lr:
-
0.009648, batch_cost: 0.0976, reader_cost: 0.00025, ips: 40.9767 samples/sec | ETA 00:01:33 2022-05-06 11:15:12 [INFO] [TRAIN] epoch: 1, iter: 50/1000, loss: 0.2909, lr:
-
0.009558, batch_cost: 0.1061, reader_cost: 0.00026, ips: 37.7125 samples/sec | ETA 00:01:40 2022-05-06 11:15:13 [INFO] [TRAIN] epoch: 1, iter: 60/1000, loss: 0.2815, lr:
-
0.009467, batch_cost: 0.0977, reader_cost: 0.00026, ips: 40.9595 samples/sec | ETA 00:01:31 2022-05-06 11:15:14 [INFO] [TRAIN] epoch: 2, iter: 70/1000, loss: 0.2392, lr:
-
0.009377, batch_cost: 0.1061, reader_cost: 0.00983, ips: 37.7019 samples/sec | ETA 00:01:38 2022-05-06 11:15:15 [INFO] [TRAIN] epoch: 2, iter: 80/1000, loss: 0.2577, lr:
-
0.009286, batch_cost: 0.1013, reader_cost: 0.00031, ips: 39.4707 samples/sec | ETA 00:01:33 2022-05-06 11:15:16 [INFO] [TRAIN] epoch: 2, iter: 90/1000, loss: 0.2332, lr:
-
0.009195, batch_cost: 0.0985, reader_cost: 0.00026, ips: 40.5886 samples/sec | ETA 00:01:29 2022-05-06 11:15:17 [INFO] [TRAIN] epoch: 2, iter: 100/1000, loss: 0.2323, lr:
-
0.009104, batch_cost: 0.0969, reader_cost: 0.00027, ips: 41.2732 samples/sec | ETA 00:01:27 2022-05-06 11:15:18 [INFO] [TRAIN] epoch: 2, iter: 110/1000, loss: 0.2690, lr:
-
0.009013, batch_cost: 0.0970, reader_cost: 0.00026, ips: 41.2443 samples/sec | ETA 00:01:26 2022-05-06 11:15:19 [INFO] [TRAIN] epoch: 2, iter: 120/1000, loss: 0.2356, lr:
-
0.008922, batch_cost: 0.0977, reader_cost: 0.00027, ips: 40.9250 samples/sec | ETA 00:01:26 2022-05-06 11:15:20 [INFO] [TRAIN] epoch: 2, iter: 130/1000, loss: 0.2114, lr:
-
0.008831, batch_cost: 0.0967, reader_cost: 0.00026, ips: 41.3566 samples/sec | ETA 00:01:24 2022-05-06 11:15:21 [INFO] [TRAIN] epoch: 3, iter: 140/1000, loss: 0.2114, lr:
-
0.008740, batch_cost: 0.1084, reader_cost: 0.00955, ips: 36.9120 samples/sec | ETA 00:01:33 2022-05-06 11:15:22 [INFO] [TRAIN] epoch: 3, iter: 150/1000, loss: 0.1721, lr:
-
0.008648, batch_cost: 0.1016, reader_cost: 0.00029, ips: 39.3552 samples/sec | ETA 00:01:26 2022-05-06 11:15:23 [INFO] [TRAIN] epoch: 3, iter: 160/1000, loss: 0.2199, lr:
-
0.008557, batch_cost: 0.0967, reader_cost: 0.00026, ips: 41.3668 samples/sec | ETA 00:01:21 2022-05-06 11:15:24 [INFO] [TRAIN] epoch: 3, iter: 170/1000, loss: 0.1691, lr:
-
0.008465, batch_cost: 0.0971, reader_cost: 0.00025, ips: 41.1858 samples/sec | ETA 00:01:20 2022-05-06 11:15:25 [INFO] [TRAIN] epoch: 3, iter: 180/1000, loss: 0.2216, lr:
-
0.008374, batch_cost: 0.0976, reader_cost: 0.00027, ips: 40.9960 samples/sec | ETA 00:01:20 2022-05-06 11:15:26 [INFO] [TRAIN] epoch: 3, iter: 190/1000, loss: 0.1685, lr:
-
0.008282, batch_cost: 0.0971, reader_cost: 0.00025, ips: 41.1736 samples/sec | ETA 00:01:18 2022-05-06 11:15:27 [INFO] [TRAIN] epoch: 4, iter: 200/1000, loss: 0.1869, lr:
-
0.008190, batch_cost: 0.1055, reader_cost: 0.00948, ips: 37.9324 samples/sec | ETA 00:01:24 2022-05-06 11:15:28 [INFO] [TRAIN] epoch: 4, iter: 210/1000, loss: 0.1608, lr:
-
0.008098, batch_cost: 0.1006, reader_cost: 0.00076, ips: 39.7523 samples/sec | ETA 00:01:19 2022-05-06 11:15:29 [INFO] [TRAIN] epoch: 4, iter: 220/1000, loss: 0.1935, lr:
-
0.008005, batch_cost: 0.0991, reader_cost: 0.00032, ips: 40.3728 samples/sec | ETA 00:01:17 2022-05-06 11:15:30 [INFO] [TRAIN] epoch: 4, iter: 230/1000, loss: 0.1826, lr:
-
0.007913, batch_cost: 0.0979, reader_cost: 0.00026, ips: 40.8574 samples/sec | ETA 00:01:15 2022-05-06 11:15:31 [INFO] [TRAIN] epoch: 4, iter: 240/1000, loss: 0.1425, lr:
-
0.007821, batch_cost: 0.0970, reader_cost: 0.00026, ips: 41.2577 samples/sec | ETA 00:01:13 2022-05-06 11:15:32 [INFO] [TRAIN] epoch: 4, iter: 250/1000, loss: 0.1768, lr:
-
0.007728, batch_cost: 0.0966, reader_cost: 0.00025, ips: 41.4150 samples/sec | ETA 00:01:12 2022-05-06 11:15:33 [INFO] [TRAIN] epoch: 4, iter: 260/1000, loss: 0.1571, lr:
-
0.007635, batch_cost: 0.0990, reader_cost: 0.00026, ips: 40.3847 samples/sec | ETA 00:01:13 2022-05-06 11:15:34 [INFO] [TRAIN] epoch: 5, iter: 270/1000, loss: 0.1750, lr:
-
0.007543, batch_cost: 0.1062, reader_cost: 0.00892, ips: 37.6550 samples/sec | ETA 00:01:17 2022-05-06 11:15:35 [INFO] [TRAIN] epoch: 5, iter: 280/1000, loss: 0.1666, lr:
-
0.007450, batch_cost: 0.1025, reader_cost: 0.00030, ips: 39.0399 samples/sec | ETA 00:01:13 2022-05-06 11:15:36 [INFO] [TRAIN] epoch: 5, iter: 290/1000, loss: 0.1758, lr:
-
0.007357, batch_cost: 0.0977, reader_cost: 0.00027, ips: 40.9246 samples/sec | ETA 00:01:09 2022-05-06 11:15:37 [INFO] [TRAIN] epoch: 5, iter: 300/1000, loss: 0.1375, lr:
-
0.007264, batch_cost: 0.0976, reader_cost: 0.00026, ips: 40.9986 samples/sec | ETA 00:01:08 2022-05-06 11:15:38 [INFO] [TRAIN] epoch: 5, iter: 310/1000, loss: 0.1407, lr:
-
0.007170, batch_cost: 0.0979, reader_cost: 0.00027, ips: 40.8465 samples/sec | ETA 00:01:07 2022-05-06 11:15:39 [INFO] [TRAIN] epoch: 5, iter: 320/1000, loss: 0.1665, lr:
-
0.007077, batch_cost: 0.0973, reader_cost: 0.00027, ips: 41.0914 samples/sec | ETA 00:01:06 2022-05-06 11:15:40 [INFO] [TRAIN] epoch: 5, iter: 330/1000, loss: 0.1532, lr:
-
0.006607, batch_cost: 0.0973, reader_cost: 0.00027, ips: 41.1151 samples/sec | ETA 00:01:01 2022-05-06 11:15:45 [INFO] [TRAIN] epoch: 6, iter: 380/1000, loss: 0.1317, lr:
-
0.006513, batch_cost: 0.0982, reader_cost: 0.00027, ips: 40.7505 samples/sec | ETA 00:01:00 2022-05-06 11:15:46 [INFO] [TRAIN] epoch: 6, iter: 390/1000, loss: 0.1458, lr:
-
0.006419, batch_cost: 0.1017, reader_cost: 0.00027, ips: 39.3418 samples/sec | ETA 00:01:02 2022-05-06 11:15:47 [INFO] [TRAIN] epoch: 7, iter: 400/1000, loss: 0.1340, lr:
-
0.006324, batch_cost: 0.1071, reader_cost: 0.00951, ips: 37.3329 samples/sec | ETA 00:01:04 2022-05-06 11:15:48 [INFO] [TRAIN] epoch: 7, iter: 410/1000, loss: 0.1526, lr:
-
0.006229, batch_cost: 0.1032, reader_cost: 0.00031, ips: 38.7605 samples/sec | ETA 00:01:00 2022-05-06 11:15:49 [INFO] [TRAIN] epoch: 7, iter: 420/1000, loss: 0.1429, lr:
-
0.006134, batch_cost: 0.0987, reader_cost: 0.00027, ips: 40.5121 samples/sec | ETA 00:00:57 2022-05-06 11:15:50 [INFO] [TRAIN] epoch: 7, iter: 430/1000, loss: 0.1189, lr:
-
0.006039, batch_cost: 0.0976, reader_cost: 0.00025, ips: 41.0038 samples/sec | ETA 00:00:55 2022-05-06 11:15:51 [INFO] [TRAIN] epoch: 7, iter: 440/1000, loss: 0.1239, lr:
-
0.005944, batch_cost: 0.0980, reader_cost: 0.00027, ips: 40.7981 samples/sec | ETA 00:00:54 2022-05-06 11:15:52 [INFO] [TRAIN] epoch: 7, iter: 450/1000, loss: 0.1482, lr:
-
0.005848, batch_cost: 0.0995, reader_cost: 0.00027, ips: 40.2018 samples/sec | ETA 00:00:54 2022-05-06 11:15:53 [INFO] [TRAIN] epoch: 7, iter: 460/1000, loss: 0.1389, lr:
-
0.005753, batch_cost: 0.0961, reader_cost: 0.00026, ips: 41.6027 samples/sec | ETA 00:00:51 2022-05-06 11:15:54 [INFO] [TRAIN] epoch: 8, iter: 470/1000, loss: 0.1179, lr:
-
0.005657, batch_cost: 0.1077, reader_cost: 0.00894, ips: 37.1542 samples/sec | ETA 00:00:57 2022-05-06 11:15:55 [INFO] [TRAIN] epoch: 8, iter: 480/1000, loss: 0.1328, lr:
-
0.005561, batch_cost: 0.0991, reader_cost: 0.00028, ips: 40.3449 samples/sec | ETA 00:00:51 2022-05-06 11:15:56 [INFO] [TRAIN] epoch: 8, iter: 490/1000, loss: 0.1308, lr:
-
0.005465, batch_cost: 0.0982, reader_cost: 0.00028, ips: 40.7368 samples/sec | ETA 00:00:50 2022-05-06 11:15:57 [INFO] [TRAIN] epoch: 8, iter: 500/1000, loss: 0.1161, lr:
-
0.005369, batch_cost: 0.0993, reader_cost: 0.00026, ips: 40.2755 samples/sec | ETA 00:00:49 2022-05-06 11:15:57 [INFO] Start evaluating (total_samples: 76, total_iters: 76)... 76/76 [==============================] - 3s 34ms/step - batch_cost: 0.0334 - reader cost: 4.6527e- 2022-05-06 11:16:00 [INFO] [EVAL] #Images: 76 mIoU: 0.8155 Acc: 0.9927 Kappa: 0.7756 Dice: 0.8878 2022-05-06 11:16:00 [INFO] [EVAL] Class IoU: [0.9926 0.6384] 2022-05-06 11:16:00 [INFO] [EVAL] Class Precision: [0.9944 0.8771] 2022-05-06 11:16:00 [INFO] [EVAL] Class Recall: [0.9982 0.7011] 2022-05-06 11:16:00 [INFO] [EVAL] The model with the best validation mIoU
-
(0.8155) was saved at iter 500. 2022-05-06 11:16:01 [INFO] [TRAIN] epoch: 8, iter: 510/1000, loss: 0.1496,
-
lr: 0.005272, batch_cost: 0.0977, reader_cost: 0.00028, ips: 40.9344 samples/sec | ETA 00:00:47 2022-05-06 11:16:02 [INFO] [TRAIN] epoch: 8, iter: 520/1000, loss: 0.1290,
-
lr: 0.005175, batch_cost: 0.0962, reader_cost: 0.00025, ips: 41.5962 samples/sec | ETA 00:00:46 2022-05-06 11:16:03 [INFO] [TRAIN] epoch: 9, iter: 530/1000, loss: 0.1242,
-
lr: 0.005078, batch_cost: 0.1037, reader_cost: 0.00893, ips: 38.5708 samples/sec | ETA 00:00:48 2022-05-06 11:16:04 [INFO] [TRAIN] epoch: 9, iter: 540/1000, loss: 0.1097,
-
lr: 0.004981, batch_cost: 0.0993, reader_cost: 0.00067, ips: 40.2963 samples/sec | ETA 00:00:45 2022-05-06 11:16:05 [INFO] [TRAIN] epoch: 9, iter: 550/1000, loss: 0.1286,
-
lr: 0.004884, batch_cost: 0.0972, reader_cost: 0.00031, ips: 41.1632 samples/sec | ETA 00:00:43 2022-05-06 11:16:06 [INFO] [TRAIN] epoch: 9, iter: 560/1000, loss: 0.1304,
-
lr: 0.004786, batch_cost: 0.0958, reader_cost: 0.00025, ips: 41.7588 samples/sec | ETA 00:00:42 2022-05-06 11:16:07 [INFO] [TRAIN] epoch: 9, iter: 570/1000, loss: 0.1085,
-
lr: 0.004688, batch_cost: 0.0953, reader_cost: 0.00026, ips: 41.9588 samples/sec | ETA 00:00:40 2022-05-06 11:16:08 [INFO] [TRAIN] epoch: 9, iter: 580/1000, loss: 0.1407,
-
lr: 0.004590, batch_cost: 0.0960, reader_cost: 0.00026, ips: 41.6859 samples/sec | ETA 00:00:40 2022-05-06 11:16:09 [INFO] [TRAIN] epoch: 9, iter: 590/1000, loss: 0.1317,
-
lr: 0.004492, batch_cost: 0.0964, reader_cost: 0.00025, ips: 41.4999 samples/sec | ETA 00:00:39 2022-05-06 11:16:10 [INFO] [TRAIN] epoch: 10, iter: 600/1000, loss: 0.1145
-
, lr: 0.004394, batch_cost: 0.1041, reader_cost: 0.00907, ips: 38.4225 samples/sec | ETA 00:00:41 2022-05-06 11:16:11 [INFO] [TRAIN] epoch: 10, iter: 610/1000, loss: 0.1386,
-
lr: 0.004295, batch_cost: 0.0983, reader_cost: 0.00031, ips: 40.7112 samples/sec | ETA 00:00:38 2022-05-06 11:16:12 [INFO] [TRAIN] epoch: 10, iter: 620/1000, loss: 0.1331,
-
lr: 0.004196, batch_cost: 0.0980, reader_cost: 0.00111, ips: 40.7957 samples/sec | ETA 00:00:37 2022-05-06 11:16:13 [INFO] [TRAIN] epoch: 10, iter: 630/1000, loss: 0.1288,
-
lr: 0.004097, batch_cost: 0.0969, reader_cost: 0.00026, ips: 41.2859 samples/sec | ETA 00:00:35 2022-05-06 11:16:14 [INFO] [TRAIN] epoch: 10, iter: 640/1000, loss: 0.1151,
-
lr: 0.003997, batch_cost: 0.0979, reader_cost: 0.00026, ips: 40.8411 samples/sec | ETA 00:00:35 2022-05-06 11:16:15 [INFO] [TRAIN] epoch: 10, iter: 650/1000, loss: 0.1022,
-
lr: 0.003897, batch_cost: 0.0968, reader_cost: 0.00025, ips: 41.3015 samples/sec | ETA 00:00:33 2022-05-06 11:16:16 [INFO] [TRAIN] epoch: 10, iter: 660/1000, loss: 0.1125,
-
lr: 0.003797, batch_cost: 0.0945, reader_cost: 0.00026, ips: 42.3387 samples/sec | ETA 00:00:32 2022-05-06 11:16:17 [INFO] [TRAIN] epoch: 11, iter: 670/1000, loss: 0.1000,
-
lr: 0.003697, batch_cost: 0.1070, reader_cost: 0.00855, ips: 37.3764 samples/sec | ETA 00:00:35 2022-05-06 11:16:18 [INFO] [TRAIN] epoch: 11, iter: 680/1000, loss: 0.1211,
-
lr: 0.003596, batch_cost: 0.0983, reader_cost: 0.00026, ips: 40.7031 samples/sec | ETA 00:00:31 2022-05-06 11:16:19 [INFO] [TRAIN] epoch: 11, iter: 690/1000, loss: 0.1436,
-
lr: 0.003495, batch_cost: 0.0962, reader_cost: 0.00026, ips: 41.5818 samples/sec | ETA 00:00:29 2022-05-06 11:16:20 [INFO] [TRAIN] epoch: 11, iter: 700/1000, loss: 0.0995,
-
lr: 0.003394, batch_cost: 0.0972, reader_cost: 0.00025, ips: 41.1362 samples/sec | ETA 00:00:29 2022-05-06 11:16:21 [INFO] [TRAIN] epoch: 11, iter: 710/1000, loss: 0.1196,
-
lr: 0.003292, batch_cost: 0.0955, reader_cost: 0.00026, ips: 41.8720 samples/sec | ETA 00:00:27 2022-05-06 11:16:22 [INFO] [TRAIN] epoch: 11, iter: 720/1000, loss: 0.1057,
-
lr: 0.003190, batch_cost: 0.0962, reader_cost: 0.00027, ips: 41.5604 samples/sec | ETA 00:00:26 2022-05-06 11:16:23 [INFO] [TRAIN] epoch: 12, iter: 730/1000, loss: 0.1208,
-
lr: 0.003088, batch_cost: 0.1032, reader_cost: 0.00818, ips: 38.7782 samples/sec | ETA 00:00:27 2022-05-06 11:16:24 [INFO] [TRAIN] epoch: 12, iter: 740/1000, loss: 0.1405,
-
lr: 0.002985, batch_cost: 0.0994, reader_cost: 0.00077, ips: 40.2241 samples/sec | ETA 00:00:25 2022-05-06 11:16:25 [INFO] [TRAIN] epoch: 12, iter: 750/1000, loss: 0.1035,
-
lr: 0.002882, batch_cost: 0.0965, reader_cost: 0.00027, ips: 41.4588 samples/sec | ETA 00:00:24 2022-05-06 11:16:26 [INFO] [TRAIN] epoch: 12, iter: 760/1000, loss: 0.1344,
-
lr: 0.002779, batch_cost: 0.0964, reader_cost: 0.00026, ips: 41.5061 samples/sec | ETA 00:00:23 2022-05-06 11:16:27 [INFO] [TRAIN] epoch: 12, iter: 770/1000, loss: 0.1177,
-
lr: 0.002675, batch_cost: 0.0959, reader_cost: 0.00024, ips: 41.7205 samples/sec | ETA 00:00:22 2022-05-06 11:16:28 [INFO] [TRAIN] epoch: 12, iter: 780/1000, loss: 0.1132,
-
lr: 0.002570, batch_cost: 0.0965, reader_cost: 0.00027, ips: 41.4708 samples/sec | ETA 00:00:21 2022-05-06 11:16:28 [INFO] [TRAIN] epoch: 12, iter: 790/1000, loss: 0.1042,
-
lr: 0.002465, batch_cost: 0.0951, reader_cost: 0.00028, ips: 42.0519 samples/sec | ETA 00:00:19 2022-05-06 11:16:29 [INFO] [TRAIN] epoch: 13, iter: 800/1000, loss: 0.1220,
-
lr: 0.002360, batch_cost: 0.1041, reader_cost: 0.00859, ips: 38.4246 samples/sec | ETA 00:00:20 2022-05-06 11:16:30 [INFO] [TRAIN] epoch: 13, iter: 810/1000, loss: 0.1216,
-
lr: 0.002254, batch_cost: 0.0986, reader_cost: 0.00028, ips: 40.5644 samples/sec | ETA 00:00:18 2022-05-06 11:16:31 [INFO] [TRAIN] epoch: 13, iter: 820/1000, loss: 0.1085,
-
lr: 0.002147, batch_cost: 0.0969, reader_cost: 0.00026, ips: 41.2966 samples/sec | ETA 00:00:17 2022-05-06 11:16:32 [INFO] [TRAIN] epoch: 13, iter: 830/1000, loss: 0.1176,
-
lr: 0.002040, batch_cost: 0.0959, reader_cost: 0.00026, ips: 41.7068 samples/sec | ETA 00:00:16 2022-05-06 11:16:33 [INFO] [TRAIN] epoch: 13, iter: 840/1000, loss: 0.1160,
-
lr: 0.001933, batch_cost: 0.0965, reader_cost: 0.00026, ips: 41.4621 samples/sec | ETA 00:00:15 2022-05-06 11:16:34 [INFO] [TRAIN] epoch: 13, iter: 850/1000, loss: 0.0965,
-
lr: 0.001824, batch_cost: 0.0957, reader_cost: 0.00026, ips: 41.7886 samples/sec | ETA 00:00:14 2022-05-06 11:16:35 [INFO] [TRAIN] epoch: 14, iter: 860/1000, loss: 0.1026,
-
lr: 0.001715, batch_cost: 0.1035, reader_cost: 0.00878, ips: 38.6382 samples/sec | ETA 00:00:14 2022-05-06 11:16:36 [INFO] [TRAIN] epoch: 14, iter: 870/1000, loss: 0.1163,
-
lr: 0.001605, batch_cost: 0.0986, reader_cost: 0.00035, ips: 40.5834 samples/sec | ETA 00:00:12 2022-05-06 11:16:37 [INFO] [TRAIN] epoch: 14, iter: 880/1000, loss: 0.1236,
-
lr: 0.001495, batch_cost: 0.0976, reader_cost: 0.00073, ips: 40.9696 samples/sec | ETA 00:00:11 2022-05-06 11:16:38 [INFO] [TRAIN] epoch: 14, iter: 890/1000, loss: 0.1152,
-
lr: 0.001383, batch_cost: 0.0964, reader_cost: 0.00027, ips: 41.5019 samples/sec | ETA 00:00:10 2022-05-06 11:16:39 [INFO] [TRAIN] epoch: 14, iter: 900/1000, loss: 0.1193,
-
lr: 0.001270, batch_cost: 0.0963, reader_cost: 0.00026, ips: 41.5537 samples/sec | ETA 00:00:09 2022-05-06 11:16:40 [INFO] [TRAIN] epoch: 14, iter: 910/1000, loss: 0.0979,
-
lr: 0.001156, batch_cost: 0.0959, reader_cost: 0.00026, ips: 41.6947 samples/sec | ETA 00:00:08 2022-05-06 11:16:41 [INFO] [TRAIN] epoch: 14, iter: 920/1000, loss: 0.0943,
-
lr: 0.001041, batch_cost: 0.0967, reader_cost: 0.00027, ips: 41.3725 samples/sec | ETA 00:00:07 2022-05-06 11:16:42 [INFO] [TRAIN] epoch: 15, iter: 930/1000, loss: 0.1236,
-
lr: 0.000925, batch_cost: 0.1061, reader_cost: 0.01007, ips: 37.7041 samples/sec | ETA 00:00:07 2022-05-06 11:16:43 [INFO] [TRAIN] epoch: 15, iter: 940/1000, loss: 0.1012,
-
lr: 0.000807, batch_cost: 0.0993, reader_cost: 0.00076, ips: 40.2644 samples/sec | ETA 00:00:05 2022-05-06 11:16:44 [INFO] [TRAIN] epoch: 15, iter: 950/1000, loss: 0.1142,
-
lr: 0.000687, batch_cost: 0.0972, reader_cost: 0.00027, ips: 41.1411 samples/sec | ETA 00:00:04 2022-05-06 11:16:45 [INFO] [TRAIN] epoch: 15, iter: 960/1000, loss: 0.1200,
-
lr: 0.000564, batch_cost: 0.0961, reader_cost: 0.00026, ips: 41.6269 samples/sec | ETA 00:00:03 2022-05-06 11:16:46 [INFO] [TRAIN] epoch: 15, iter: 970/1000, loss: 0.1038,
-
lr: 0.000439, batch_cost: 0.0960, reader_cost: 0.00026, ips: 41.6836 samples/sec | ETA 00:00:02 2022-05-06 11:16:47 [INFO] [TRAIN] epoch: 15, iter: 980/1000, loss: 0.1054,
-
lr: 0.000309, batch_cost: 0.0956, reader_cost: 0.00026, ips: 41.8465 samples/sec | ETA 00:00:01 2022-05-06 11:16:48 [INFO] [TRAIN] epoch: 15, iter: 990/1000, loss: 0.1050,
-
lr: 0.000173, batch_cost: 0.0942, reader_cost: 0.00027, ips: 42.4693 samples/sec | ETA 00:00:00 2022-05-06 11:16:49 [INFO] [TRAIN] epoch: 16, iter: 1000/1000, loss: 0.0974,
-
lr: 0.000020, batch_cost: 0.1086, reader_cost: 0.00817, ips: 36.8296 samples/sec | ETA 00:00:00 2022-05-06 11:16:49 [INFO] Start evaluating (total_samples: 76, total_iters: 76)... 76/76 [==============================] - 3s 35ms/step - batch_cost: 0.0346 - reader cost: 4.2331e-0 2022-05-06 11:16:52 [INFO] [EVAL] #Images: 76 mIoU: 0.8524 Acc: 0.9942 Kappa: 0.8280 Dice: 0.9140 2022-05-06 11:16:52 [INFO] [EVAL] Class IoU: [0.9941 0.7107] 2022-05-06 11:16:52 [INFO] [EVAL] Class Precision: [0.9959 0.8859] 2022-05-06 11:16:52 [INFO] [EVAL] Class Recall: [0.9981 0.7824] 2022-05-06 11:16:52 [INFO] [EVAL] The model with the best validation mIoU (0.8524) was saved at iter 1000.
's flops has been counted Customize Function has been applied to 's flops has been counted Cannot find suitable count function for . Treat it as zero FLOPs. 's flops has been counted Cannot find suitable count function for . Treat it as zero FLOPs. 's flops has been counted Cannot find suitable count function for . Treat it as zero FLOPs. 's flops has been counted Total Flops: 8061051648 Total Params: 2328346 -
Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0506 11:17:11.684418 589 gpu_context.cc:272] device: 0, cuDNN Version: 7.6. 2022-05-06 11:17:19 [INFO] Number of predict images = 1 2022-05-06 11:17:19 [INFO] Loading pretrained model from output/iter_1000/model.pdparams 2022-05-06 11:17:19 [INFO] There are 356/356 variables loaded into BiSeNetV2. 2022-05-06 11:17:19 [INFO] Start to predict... 1/1 [==============================] - 0s 78ms/step
-
Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0506 11:16:56.952658 536 gpu_context.cc:272] device: 0, cuDNN Version: 7.6. 2022-05-06 11:17:05 [INFO] Loading pretrained model from output/iter_1000/model.pdparams 2022-05-06 11:17:05 [INFO] There are 356/356 variables loaded into BiSeNetV2. 2022-05-06 11:17:05 [INFO] Loaded trained params of model successfully 2022-05-06 11:17:05 [INFO] Start evaluating (total_samples: 76, total_iters: 76)... 76/76 [==============================] - 3s 36ms/step - batch_cost: 0.0359 - reader cost: 0.00 2022-05-06 11:17:08 [INFO] [EVAL] #Images: 76 mIoU: 0.8524 Acc: 0.9942 Kappa: 0.8280 Dice: 0.9140 2022-05-06 11:17:08 [INFO] [EVAL] Class IoU: [0.9941 0.7107] 2022-05-06 11:17:08 [INFO] [EVAL] Class Precision: [0.9959 0.8859] 2022-05-06 11:17:08 [INFO] [EVAL] Class Recall: [0.9981 0.7824]
-
Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0506 11:17:23.459280 639 gpu_context.cc:272] device: 0, cuDNN Version: 7.6. 2022-05-06 11:17:31 [INFO] Loaded trained params of model successfully. /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/laye
-
rs/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections'
-
instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working return (isinstance(seq, collections.Sequence) and /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/lay
-
ers/math_op_patch.py:341: UserWarning: /tmp/tmpve8r95h1.py:9 The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1)
-
from Paddle 2.0. If your code works well in the older versions but crashes in this
-
version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional
-
warning will be dropped in the future. op_type, op_type, EXPRESSION_MAP[method_name])) /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers
-
/math_op_patch.py:341: UserWarning: /tmp/tmpr63v2skk.py:8 The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1)
-
from Paddle 2.0. If your code works well in the older versions but crashes in this
-
version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional
-
warning will be dropped in the future. op_type, op_type, EXPRESSION_MAP[method_name])) /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers
-
/math_op_patch.py:341: UserWarning: /tmp/tmphvp3yaes.py:9 The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1)
-
from Paddle 2.0. If your code works well in the older versions but crashes in this version,
-
try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional
-
warning will be dropped in the future. op_type, op_type, EXPRESSION_MAP[method_name])) /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/laye
-
rs/math_op_patch.py:341: UserWarning: /tmp/tmp1qwc4w92.py:8 The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1)
-
from Paddle 2.0. If your code works well in the older versions but crashes in this
-
version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This
-
transitional warning will be dropped in the future. op_type, op_type, EXPRESSION_MAP[method_name])) /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math
-
_op_patch.py:341: UserWarning: /tmp/tmppt2ipa0l.py:9 The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1)
-
from Paddle 2.0. If your code works well in the older versions but crashes in this version,
-
try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will
-
be dropped in the future. op_type, op_type, EXPRESSION_MAP[method_name])) /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/m
-
ath_op_patch.py:341: UserWarning: /tmp/tmpj14_9vg7.py:8 The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from
-
Paddle 2.0. If your code works well in the older versions but crashes in this version,
-
try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will
-
be dropped in the future. op_type, op_type, EXPRESSION_MAP[method_name])) /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/
-
math_op_patch.py:341: UserWarning: /tmp/tmpuz7otg0m.py:8 The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from
-
Paddle 2.0. If your code works well in the older versions but crashes in this version, try
-
to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be
-
dropped in the future. op_type, op_type, EXPRESSION_MAP[method_name])) /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers
-
/math_op_patch.py:341: UserWarning: /tmp/tmp54jgdgc_.py:8 The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1)
-
from Paddle 2.0. If your code works well in the older versions but crashes in this ver
-
sion, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional
-
warning will be dropped in the future. op_type, op_type, EXPRESSION_MAP[method_name])) /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layer
-
s/math_op_patch.py:341: UserWarning: /tmp/tmp1cf956py.py:15
-
The behavior of expression A * B has been unified with elementwise_mul(X, Y, axis=-1)
-
from Paddle 2.0. If your code works well in the older versions but crashes in this vers
-
ion, try to use elementwise_mul(X, Y, axis=0) instead of A * B. This transitional
-
warning will be dropped in the future. op_type, op_type, EXPRESSION_MAP[method_name])) /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_
-
op_patch.py:341: UserWarning: /tmp/tmp1cf956py.py:16 The behavior of expression A * B has been unified with elementwise_mul(X, Y, axis=-1) from Paddle
-
2.0. If your code works well in the older versions but crashes in this version, try to use
-
elementwise_mul(X, Y, axis=0) instead of A * B. This transitional warning will be dropped in the future. op_type, op_type, EXPRESSION_MAP[method_name])) /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_pat
-
ch.py:341: UserWarning: /tmp/tmp1cf956py.py:20 The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2
-
.0. If your code works well in the older versions but crashes in this version, try to use elementwi
-
se_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future. op_type, op_type, EXPRESSION_MAP[method_name])) 2022-05-06 11:17:34 [INFO] Model is saved in ./output.
-
of analysis predictor failed, which may be due to native predictor called first and its configura
-
tions taken effect. --- Running analysis [ir_graph_build_pass] --- Running analysis
-
[ir_graph_clean_pass] --- Running analysis [ir_analysis_pass] --- Running IR pass
-
[is_test_pass] --- Running IR pass [simplify_with_basic_ops_pass] --- Running IR pass [conv_b
-
_fuse_pass] --- Running IR pass [conv_eltwiseadd_bn_fuse_pass] I0506 11:17:42.468394 681 fuse
-
_pass_base.cc:57] --- detected 36 subgraphs --- Running IR pass [embedding_eltwise_layernorm_fu -
se_pass] --- Running IR pass [multihead_matmul_fuse_pass_v2] --- Running IR pass [gpu_cpu_squeeze2
-
_matmul_fuse_pass] --- Running IR pass [gpu_cpu_reshape2_matmul_fuse_pass] --- Running IR pass [g
-
pu_cpu_flatten2_matmul_fuse_pass] --- Running IR pass [gpu_cpu_map_matmul_v2_to_mul_pass] --- Running
-
IR pass [gpu_cpu_map_matmul_v2_to_matmul_pass] --- Running IR pass [gpu_cpu_map_matmul_to_mul_pass]
-
--- Running IR pass [fc_fuse_pass] --- Running IR pass [fc_elementwise_layernorm_fuse_pass] ---
-
Running IR pass [conv_elementwise_add_act_fuse_pass] --- Running IR pass [conv_elementwise_add2_act
-
_fuse_pass] --- Running IR pass [conv_elementwise_add_fuse_pass] I0506 11:17:42.503649 681 fuse_
-
pass_base.cc:57] --- detected 15 subgraphs --- Running IR pass [transpose_flatten_concat_fuse_pass] -
--- Running IR pass [runtime_context_cache_pass] --- Running analysis [ir_params_sync_among_
-
devices_pass] I0506 11:17:42.514343 681 ir_params_sync_among_devices_pass.cc:100] Sync params from -
CPU to GPU --- Running analysis [adjust_cudnn_workspace_size_pass] --- Running analysis
-
[inference_op_replace_pass] --- Running analysis [memory_optimize_pass] I0506 11:17:42
-
.544112 681 memory_optimize_pass.cc:216] Cluster name : x size: 12 I0506 11:17:42.544168 681 memory_optimize_pass.cc:216] Cluster name : batch_norm_47.tmp_2 size: 512 I0506 11:17:42.544180 681 memory_optimize_pass.cc:216] Cluster name : depthwise_conv2d_12.tmp_1 size: 3072 I0506 11:17:42.544184 681 memory_optimize_pass.cc:216] Cluster name : depthwise_conv2d_11.tmp_1 size: 3072 I0506 11:17:42.544188 681 memory_optimize_pass.cc:216] Cluster name : conv2d_96.tmp_1 size: 512 I0506 11:17:42.544193 681 memory_optimize_pass.cc:216] Cluster name : batch_norm_43.tmp_1 size: 3072 I0506 11:17:42.544196 681 memory_optimize_pass.cc:216] Cluster name : batch_norm_43.tmp_0 size: 3072 I0506 11:17:42.544205 681 memory_optimize_pass.cc:216] Cluster name : relu_21.tmp_0 size: 512 - -
-- Running analysis [ir_graph_to_program_pass] I0506 11:17:42.638660 681 analysis_predict -
or.cc:1006] ======= optimize end ======= I0506 11:17:42.648136 681 naive_executor.cc:102] --- skip [feed], feed -> x I0506 11:17:42.651057 681 naive_executor.cc:102] --- skip [argmax_0.tmp_0], fetch -> fetch W0506 11:17:42.666846 681 gpu_context.cc:244] Please NOTE: device: 0, GPU Compute Capability:
-
7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0506 11:17:42.671198 681 gpu_context.cc:272] device: 0, cuDNN Version: 7.6. 2022-05-06 11:17:46 [INFO] Finish
-
# set CUDA_VISIBLE_DEVICES=0 !python train.py \ --config configs/quick_start/bisenet_optic_disc_512x512_1k.yml \ --do_eval \ --use_vdl \ --save_interval 500 \ --save_dir output
