文档简介:



工业部署
飞桨不仅是一个深度学习框架,还是集深度学习核心框架、基础模型库、端到端开发套件、工具组件和服务平台于一体,为用户提供了多样化的配套服务产品,助力深度学习技术的应用落地。如 图1 所示,飞桨针对不同的模型部署场景,提供了多种部署工具。同时也提供了模型压缩工具PaddleSlim,满足对模型尺寸和速度有更高需求的部署场景。
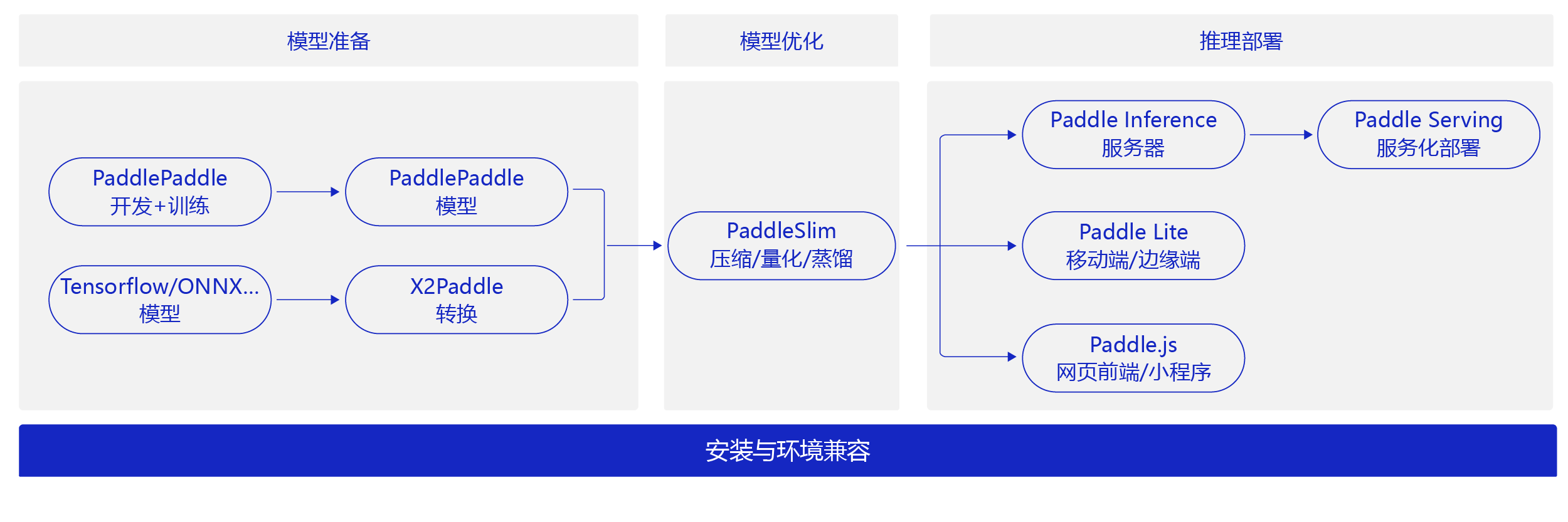
图1:飞桨模型部署组件 概览
对于人工智能领域的研究者来说,一般算法模型的改进是其最关心的;对于企业用户和开发者而言,更希望应用现有的算法,部署到服务器或者端侧硬件上,解决一些实际应用问题。
模型部署面临和训练完全不一样的硬件环境和性能要求:
- 更广泛的硬件环境适配:资讯推荐(高性能服务器),人脸支付(移动端),工业质检(嵌入式端)。
- 更极致的计算性能:服务压力导致对时延(用户交互体验)和吞吐(海量用户并发)的要求。
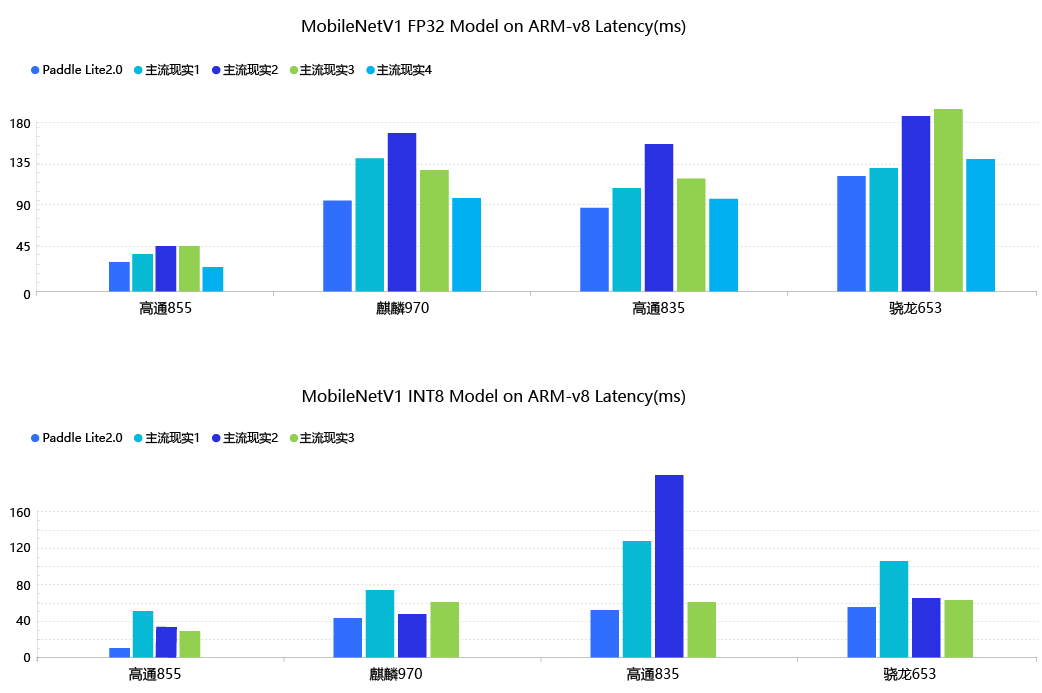
飞桨在这两个方面都有优秀的体现,如下图所示,与其他框架相比较,Paddle Lite在模型部署的预测速度上具备明显的优势:
飞桨模型部署组件介绍
飞桨模型部署全景和使用场景如下图所示:
-
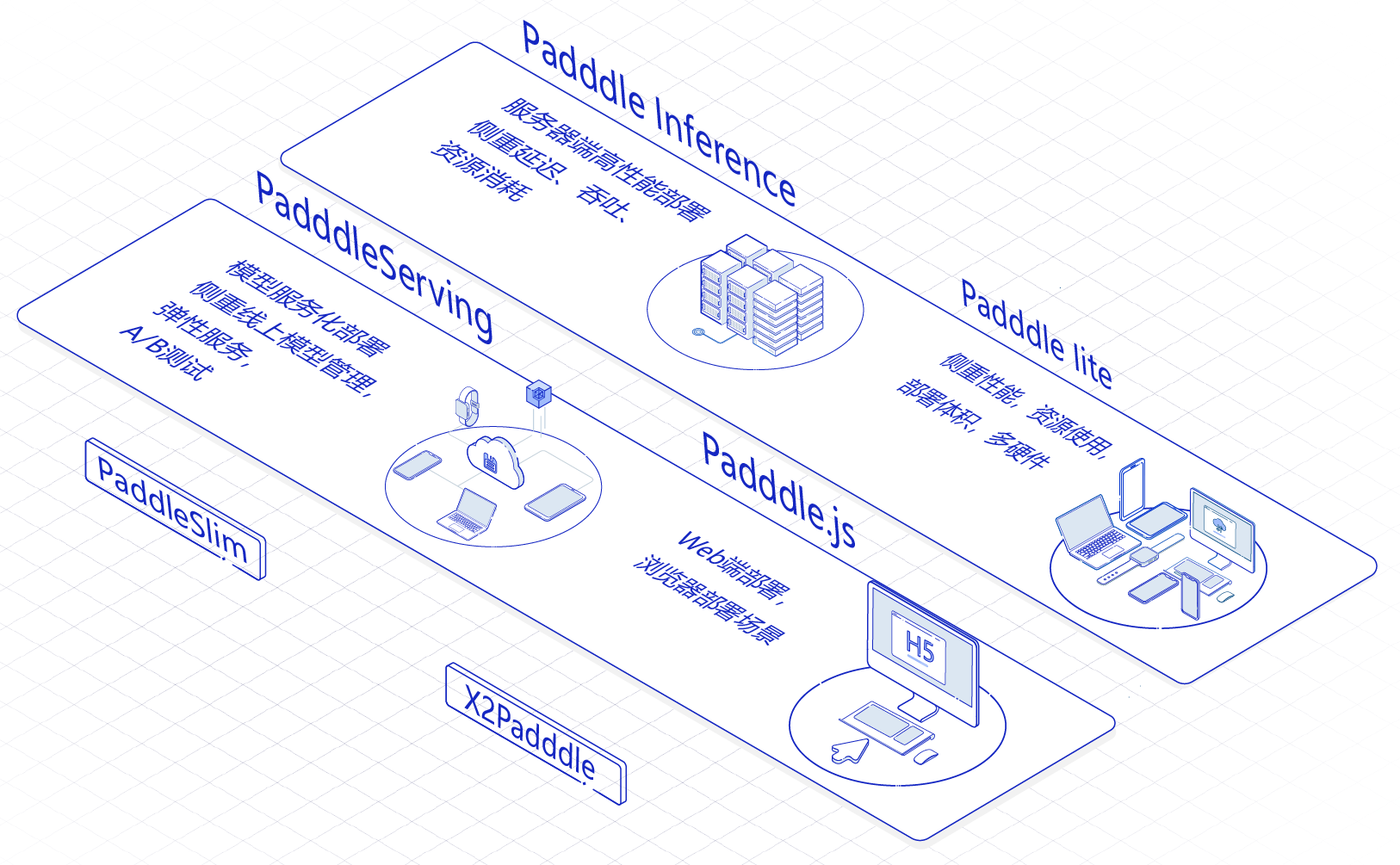 Paddle Inference:飞桨原生推理库,用于服务器端模型部署,支持Python、C/ C++等多语言。
Paddle Inference:飞桨原生推理库,用于服务器端模型部署,支持Python、C/ C++等多语言。
- Paddle Serving:飞桨服务化部署框架 ,用于云端服务化部署,可以将模型作为单独的预测服务。
- Paddle Lite:飞桨轻量化推理引擎,用于 Mobile 及 IoT (如嵌入式设备芯片)等场景的部署。
- Paddle.js:使用 JavaScript(Web)语言部署模型,在网页和小程序中便捷的部署模型。
- 部署辅助工具1 - PaddleSlim:模型压缩,在保证模型精度的基础上减少模型尺寸,以得到更好的性能或便于放入存储较小的嵌入式芯片。
- 部署辅助工具2 - X2 Paddle:将其他框架模型转换成Paddle模型,然后即可使用飞桨的一系列工具部署模型。
飞桨模型部署组件适用4个用户场景
- 跑一批测试样本,快速预测结果:使用Paddle Inference的Python接口,跑一批测试样本,快速得到结果。
- 在业务系统中加入模型:在业务系统中使用Paddle Inference的C++/C接口,其他编程语言的业务系统可以对接到C API扩展实现模型预测。如果业务系统是C/S或B/S模式,也可以使用Paddle Serving将模型服务化,供各种业务系统或客户端远程访问预测服务。
- 移动端软件/嵌入式软件(APP/Web/智能设备)中加入模型:使用PaddleSlim对模型大小进一步压缩后,可以使用Paddle Lite构建APP及嵌入式端的模型,或者使用Paddle.js构建Web/小程序中使用的模型。
- X2 Paddle: 将其他框架的模型转换成Paddle的模型,之后可以使用上述工具完成模型部署。
在模型实际部署时,不需要训练模型的部分,只需要模型的前向计算过程。同时,模型的推理和模型的训练有着不同的硬件环境和性能要求。所以,部署模型多是使用飞桨的save_inference_model保存的模型,而不是使用框架自带的paddle.save接口。Inference 模型会额外保存模型的结构信息,在推理速度上性能优越、灵活方便,适合与实际系统集成。
搭建完整系统的硬件选型建议
-
将深度学习模型应用到产业系统中,必不可少还涉及到配套硬件的选择。与运行模型配套的硬件主要是计算芯片,不同的芯片会带来性能上的极大差异。为应用场景的模型从类型、性能、存储、价格等方面选择合适的芯片是模型成功落地的前提。
-
传统来说深度学习硬件可以分成云端的硬件及端侧的硬件(见下图),主要区分点在于算力及功耗大小。不过近年来硬件厂商推出了所谓边缘硬件的概念,算力和功耗都介于两者之间,因此场景的边界也越来越模糊。但传统意义来讲,训练的任务多发生在云端的硬件(端侧训练仍属小众,且联邦学习可以算作训练还是发生在云端),而端侧硬件多用于推理部署。
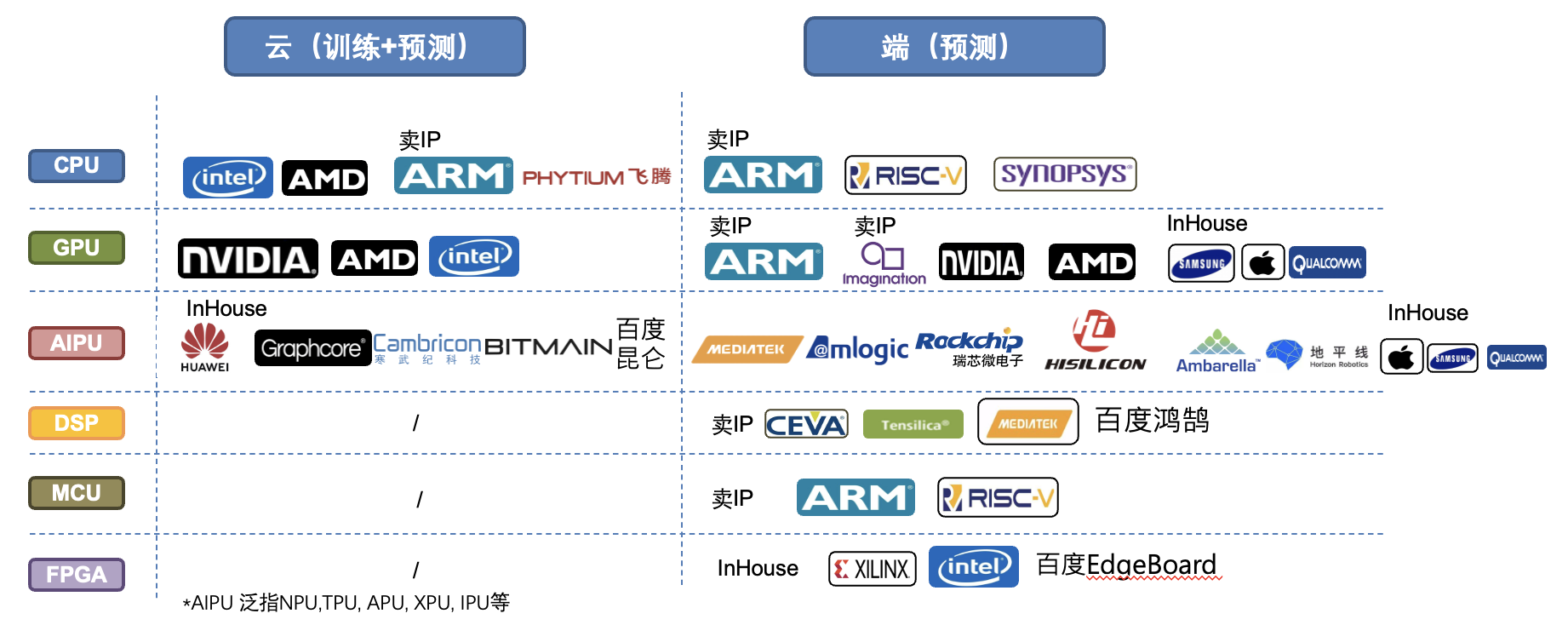
- 在人工智的时代,除了非常通用的GPU外,许多硬件厂商纷纷推出各种AI专用的加速芯片并且给予各种APU, BPU, IPU, NPU, XPU等命名,这边我们统称为AIPU。AIPU顾名思义是针对人工智能特定的计算如卷积、池化做了大量优化,因此在特定模型上的性能会超过一般通用的CPU、GPU等硬件。与此对应的是,这些芯片不适合通用及I/O密集的计算。以下是AIPU的特点及不建议使用AIPU的一些场景:

- AIPU的特点:
- 适合密集的计算(矩阵乘法),例如MatMul和Conv2D算子,在ResNet、MobileNet等类似模型性能好。
- 并不是对所有模型都有加速效果(实测往往会部分模型性能特别好,部分模型性能一般),需要有针对性的优化。
- 端侧的AIPU会更适合低功耗的应用场景。
- 适合CPU、GPU负载较高的场景,例如游戏、视频播放、相机类。
- 多使用量化模型,低内存消耗。
- 哪些情况下不适合AIPU:
- 模型太小,过于简单(CPU耗时10ms以下),根本无法发挥AIPU的计算优势。
- 可变Shape或变长的序列信息(例如NLP模型),可变Shape包括模型内部shape存在变化,输入、输出尺寸依赖输入内容的(例如一些检测类模型)。这是因为AIPU芯片是按照规整的矩乘法来优化的。
- 对模型加载到第一次预测时延要求高的场景,除非应用场景可以采用提前加载的方案。
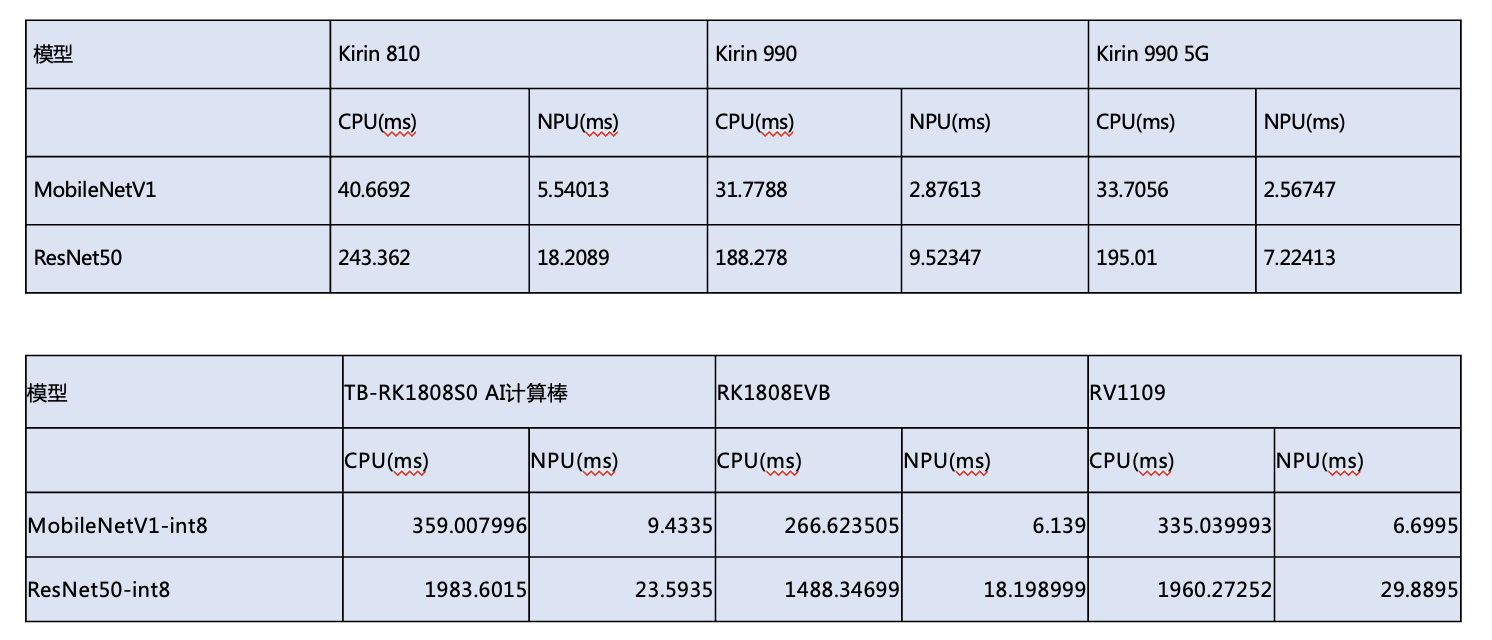
- CPU与AIPU分别在手机硬件(以华为Kirin系列为例),及边缘端硬件上的性能比较(以Rockchip RK1808及RV1109为例),可见对于常见的深度学习模型,AIPU的计算有非常大的性能优势(达到数量级的差距,几十倍的提速)。
- AIPU芯片选型的关键因素: 选型AIPU芯片,可以通过如下7个方面进行思考:
-
主打领域:每款芯片是厂商圈定了某个目标市场的需求进行设计的,需要注意选择与应用场景匹配的芯片类型的匹配。
-
制程及供货:现在主流云侧和端侧AI专用芯片14nm以下,其中14nm以下制程需注意供货稳定性(供货不稳定会导致系统扩容时候的困难)。
-
算力:需注意标定的TOPS(TOPS是Tera Operations Per Second的缩写,1TOPS代表处理器每秒钟可进行一万亿次操作)是在怎么样精度下, int8的算力通常会是FP16的2倍, 以此类推。
-
主频率:同样制程的芯片有机会透过升频等方式提升等效算力。
-
存储:视所需使用的模型大小而定, 通常云侧芯片会在8GB以上, 端侧会在2GB以上。模型可以通过PaddleSlim进行压缩,但通常会有精度的损失。
-
视频编解码 & ISP:带视频编辑码模块的芯片更适合处理视频信号,安防领域的芯片多已支持8路以上1080P编解码,ISP规格通常在12MPixels以上对成像品质比较有保障。
-
价格:通过1-6点的考虑就可以圈定出可采购的芯片范围,在其中选择较有性价比的产品即可。
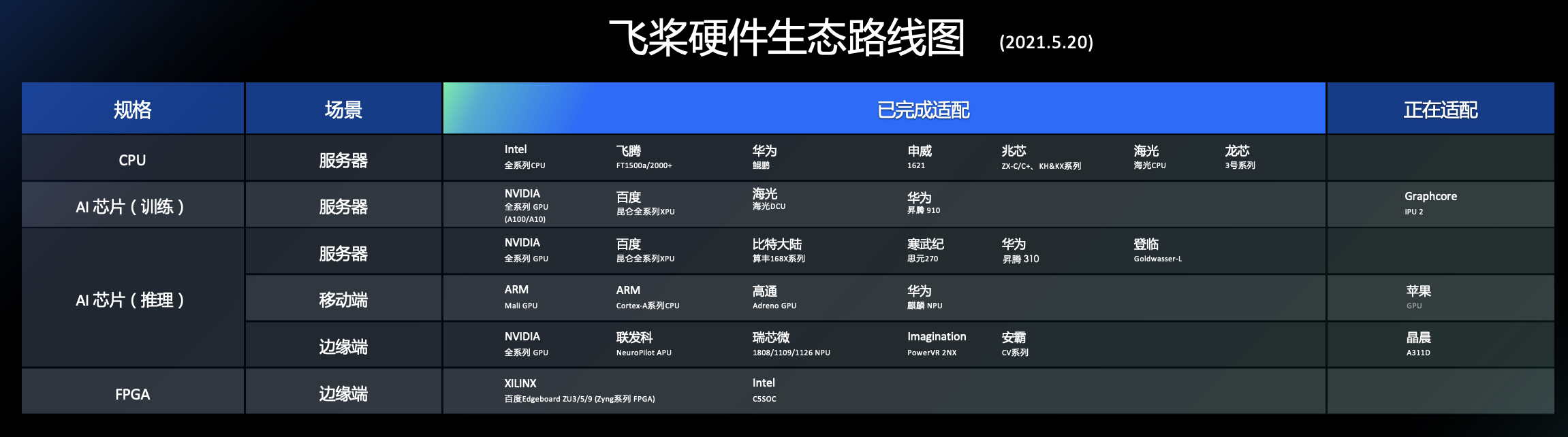
- 飞桨有着广泛的硬件芯片的支持,来满足用户在自由选择硬件芯片上的体验。作为国产领先的深度学习平台,飞桨深刻理解到软硬整合才能发挥人工智能的最大优势,因此也积极的与国内外领先的人工智能硬件厂商合作优化,截至2021.5已经完成超过22家及31种芯片/IP的硬件打通,以下请参考飞桨最新的硬件生态适配路径图(需注意每种不同的硬件并非所有模型支持,最新的模型支持状况请参考Paddle Lite: https://paddle-lite.readthedocs.io/zh/latest/demo_guides/intel_fpga.html , 及 Paddle inference的硬件支持文档: https://paddle-inference.readthedocs.io/en/latest/user_guides/source_compile.html)