

文档简介:



飞桨官方模型库Paddle Models是由飞桨官方开发和维护的深度学习开源算法集合,包括代码、数据集和预训练模型。目前模型库发布了超过300个工业级的深度学习前沿算法,覆盖了计算机视觉、自然语言处理、语音识别、智能推荐、强化学习等领域。通过使用官方模型库可以极大的减少开发者的工作量,加速深度学习算法的应用落地。模型库的预训练模型,在通用场景下一般可达到SOTA(State Of The Art)效果,即模型在常用的数据集上取得了当前最优的性能表现。通过使用业务数据持续训练和二次开发,可以进一步提升算法在特定场景下的效果。
飞桨官方模型库提供了丰富的模型种类,覆盖应用领域广泛,可以满足大部分深度学习应用场景的使用需求。飞桨模型库覆盖全景如 图1 所示。
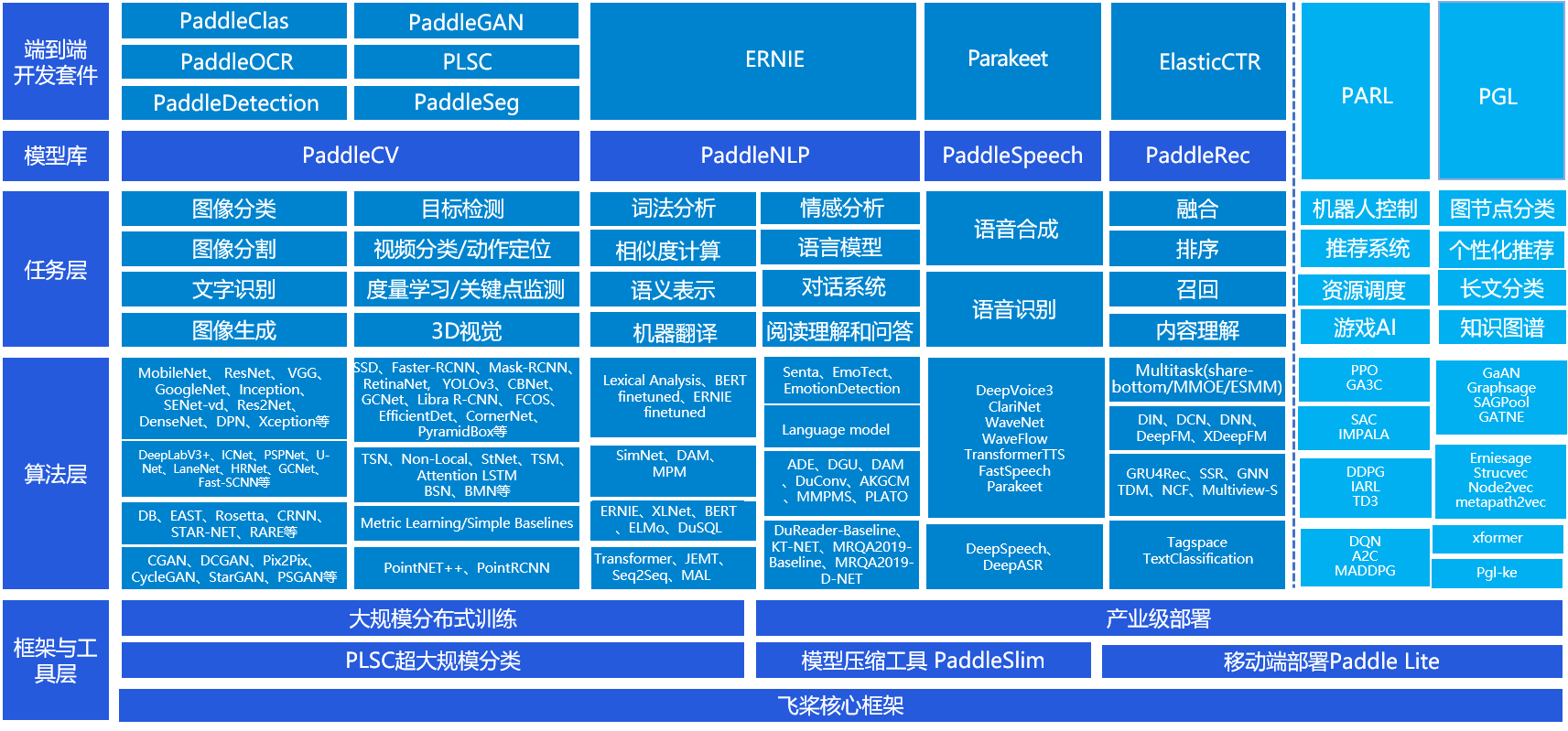
图1:飞桨模型库全景图
以上全景图可以看出飞桨官方模型库覆盖了四大核心领域:计算机视觉(PaddleCV)、自然语言处理(PaddleNLP)、语音(PaddleSpeech)、推荐(PaddleRec),并在此之上构建了丰富的开发套件,如前文提到的图像分割套件PaddleSeg,满足开发者在不同应用领域的需求。
计算机视觉(PaddleCV)
PaddleCV是基于飞桨深度学习框架的开发的智能视觉工具、算法、模型和数据的开源项目。百度在CV领域多年的深厚积淀为PaddleCV提供了强大的核心动力。PaddleCV集成了丰富的CV模型,涵盖图像分类、目标检测、图像分割、视频分类和动作定位、目标跟踪、图像生成、文字识别、度量学习、关键点检测、3D视觉等CV技术。
自然语言处理(PaddleNLP)
PaddleNLP是基于飞桨深度学习框架开发的工具、算法、模型和数据的开源项目。百度在NLP领域十几年的深厚积淀为PaddleNLP提供了强大的核心动力,使用PaddleNLP,您可以得到丰富而全面的NLP任务支持:
- 多粒度、多场景的应用支持。涵盖了从分词、词性标注、命名实体识别等NLP基础技术,到文本分类、文本相似度计算、语义表示、文本生成等NLP核心技术。同时,PaddleNLP还提供了针对常见NLP大型应用系统(如阅读理解,对话系统,机器翻译系统等)的特定核心技术和工具组件、模型和预训练参数等,让您在NLP领域畅通无阻。
- 稳定可靠的NLP模型和强大的预训练参数。
- 集成了百度内部广泛使用的NLP工具模型,为您提供了稳定可靠的NLP算法解决方案。基于百亿级数据的预训练参数和丰富的预训练模型,助您轻松提高模型效果,为您的NLP业务注入强大动力。
- 持续改进和技术支持,零基础搭建NLP应用。
语音(PaddleSpeech)
PaddleSpeech涵盖语音识别、语音合成任务领域。
- 自动语音识别(Automatic Speech Recognition, ASR)是将人类声音中的词汇内容转录成计算机可输入的文字的技术。语音识别的相关研究经历了漫长的探索过程,在HMM/GMM模型之后其发展一直较为缓慢,随着深度学习的兴起,其迎来了春天。在多种语言识别任务中,将深度神经网络 (DNN) 作为声学模型,取得了比 GMM 更好的性能,使得 ASR 成为深度学习应用非常成功的领域之一。而由于识别准确率的不断提高,有越来越多的语言技术产品得以落地,例如语言输入法、以智能音箱为代表的智能家居设备等基于语言的交互方式正在深刻的改变人类的生活。
- 语音合成 (Speech Synthesis) 技术是指用人工方法合成可辨识的语音。文本转语音 (Text-To-Speech) 系统是对语音合成技术的具体应用,其任务是给定某种语言的文本,合成对应的语音。语音合成技术是基于语音的人机交互,实时语音翻译等技术的基础。传统的文本转语音模型分为文本到音位,音位到频谱,频谱到波形等几个阶段分别进行优化,而随着深度学习技术在语音技术的应用的发展,端到端的文本转语音模型正在取得快速发展。
推荐系统(PaddleRec)
推荐系统在当前的互联网服务中正在发挥越来越大的作用,目前大部分电子商务系统、社交网络、广告推荐、搜索引擎、信息流都不同程度的使用了各种形式的个性化推荐技术,帮助用户快速找到他们想要的信息。
在工业可用的推荐系统中,推荐策略一般会被划分为多个模块串联执行。以新闻推荐系统为例,存在多个可以使用深度学习技术的环节,例如新闻的内容理解–标签标注、个性化新闻召回、个性化匹配与排序、融合等。飞桨对推荐算法的训练提供了完整的支持,并提供了多种模型配置供用户选择。
看到这里,有些读者可能会有困惑,飞桨模型库和之前的各领域开发套件究竟是什么关系?其实各领域的开发套件是基于飞桨模型库实现的,再次基础上进行了比较好的工具化封装。但飞桨模型库提供了更广泛的模型,同时也开源了模型实现的源代码,不仅支持用户的快速使用,也可以直接在源代码上进行模型的二次研发,优化出全新的模型。
如果在开发套件中没有找到自己需要的领域工具,或者感觉开发套件提供的配置项无法满足模型优化的需求,需要进一步修改模型源代码,就可以到飞桨模型库中寻找。
从模型库中筛选自己需要的模型
上面已经介绍到飞桨模型库中包含了丰富的模型资源,但是如何合理的选择和使用这些资源呢?
Paddle Models的文档提供了两层索引:
- 第一层索引以展示任务输入和输出的形式,供用户确定他的任务属于哪一类问题。
- 第二层索引详细列出了在该类问题中存在的诸多模型究竟有什么区别,通常用户可以从模型精度、训练和预测速度、模型体积和适用于特定场景来决策使用哪个模型,对于历史上的经典模型也从学习的视角提供了实现。
以第一节桃子分类为例,输入的数据是桃子图像,希望得到的结果图像中的桃子是哪一种类别,是个头大且成熟的类别还是个头中等的类别。通过查阅文档中的第一层索引,形式如 图2 所示。桃子分类属于图像分类任务,得到图像所属类别。因此,可以选择模型库中分类的算法模型。
图2:选择合适的深度学习任务
之后,我们需决策解决该类问题需使用哪一个模型,飞桨图像分类库中包含了丰富的模型,如下表所示。
| 模型名称 | 模型简介 |
|---|---|
| AlexNet | 首次在 CNN 中成功的应用了 ReLU, Dropout 和 LRN,并使用 GPU 进行运算加速。 |
| VGG19 | 在 AlexNet 的基础上使用 3*3 小卷积核,增加网络深度,具有很好的泛化能力。 |
| GoogLeNet | 在不增加计算负载的前提下增加了网络的深度和宽度,性能更加优越。 |
| ResNet50 | Residual Network,引入了新的残差结构,解决了随着网络加深,准确率下降的问题。 |
| ResNetvd | 服务器端应用实用模型。融合多种对 ResNet 改进策略,ResNet50vd的top1准确率达到79.1%,相比标准版本提升2.6%。在V100上预测一张图像的时间3ms左右。进一步采用SSLD蒸馏方案,其top1准确率可以达到82.39%。 |
| Inceptionv4 | 将 Inception 模块与 Residual Connection 进行结合,通过ResNet的结构极大地加速训练并获得性能的提升。 |
| MobileNetV1 | 将传统的卷积结构改造成两层卷积结构的网络,在基本不影响准确率的前提下大大减少计算时间,更适合移动端和嵌入式视觉应用。 |
| MobileNetV2 | MobileNet结构的微调,直接在 thinner 的 bottleneck层上进行 skip learning 连接以及对 bottleneck layer 不进行 ReLu 非线性处理可取得更好的结果。 |
| MobileNetV3 | 移动端应用实用模型。MobileNetV3是对MobileNet系列模型的又一次升级,MobileNetV3largex10的top1准确率达到75.3%,在骁龙855上预测一张图像的时间只有19.3ms。进一步采用SSLD蒸馏方案,其top1准确率可以达到79%。 |
| SENet154vd | 在ResNeXt基础、上加入了 SE(Sequeeze-and-Excitation) 模块,提高了识别准确率,在 ILSVRC 2017 的分类项目中取得了第一名。 |
| ShuffleNetV2 | ECCV2018,轻量级 CNN 网络,在速度和准确度之间做了很好地平衡。在同等复杂度下,比 ShuffleNet 和 MobileNetv2 更准确,更适合移动端以及无人车领域。 |
| efficientNet | 同时对模型的分辨率,通道数和深度。进行缩放,用极少的参数就可以达到SOTA的精度。 |
| xception71 | 对inception-v3的改进,用深度可分离卷积代替普通卷积,降低参数量的同时提高了精度。 |
| dpn107 | 融合了densenet和resnext的特点。 |
| mobilenetV3smallx10 | 在v2的基础上增加了se模块,并且使用hard-swish激活函数。在分类、检测、分割等视觉任务上都有不错表现。 |
| DarkNet53 | 检测框架yolov3使用的backbone,在分类和检测任务上都有不错表现。 |
| DenseNet161 | 提出了密集连接的网络结构,更加有利于信息流的传递。 |
| ResNeXt152vd64x4d | 提出了cardinatity的概念,用于作为模型复杂度的另外一个度量,并依据该概念有效地提升了模型精度。 |
| SqueezeNet11 | 提出了新的网络架构Fire Module,通过减少参数来进行模型压缩。 |
除了参考每个模型的基本注解外,用户还可以根据各类算法的推理时间和推理精度选择合适的模型。在服务器硬件环境(较强的计算性能)和移动端硬件环境(较弱的计算性能),各类模型的精度和速度表现如 图3 和 图4 所示。
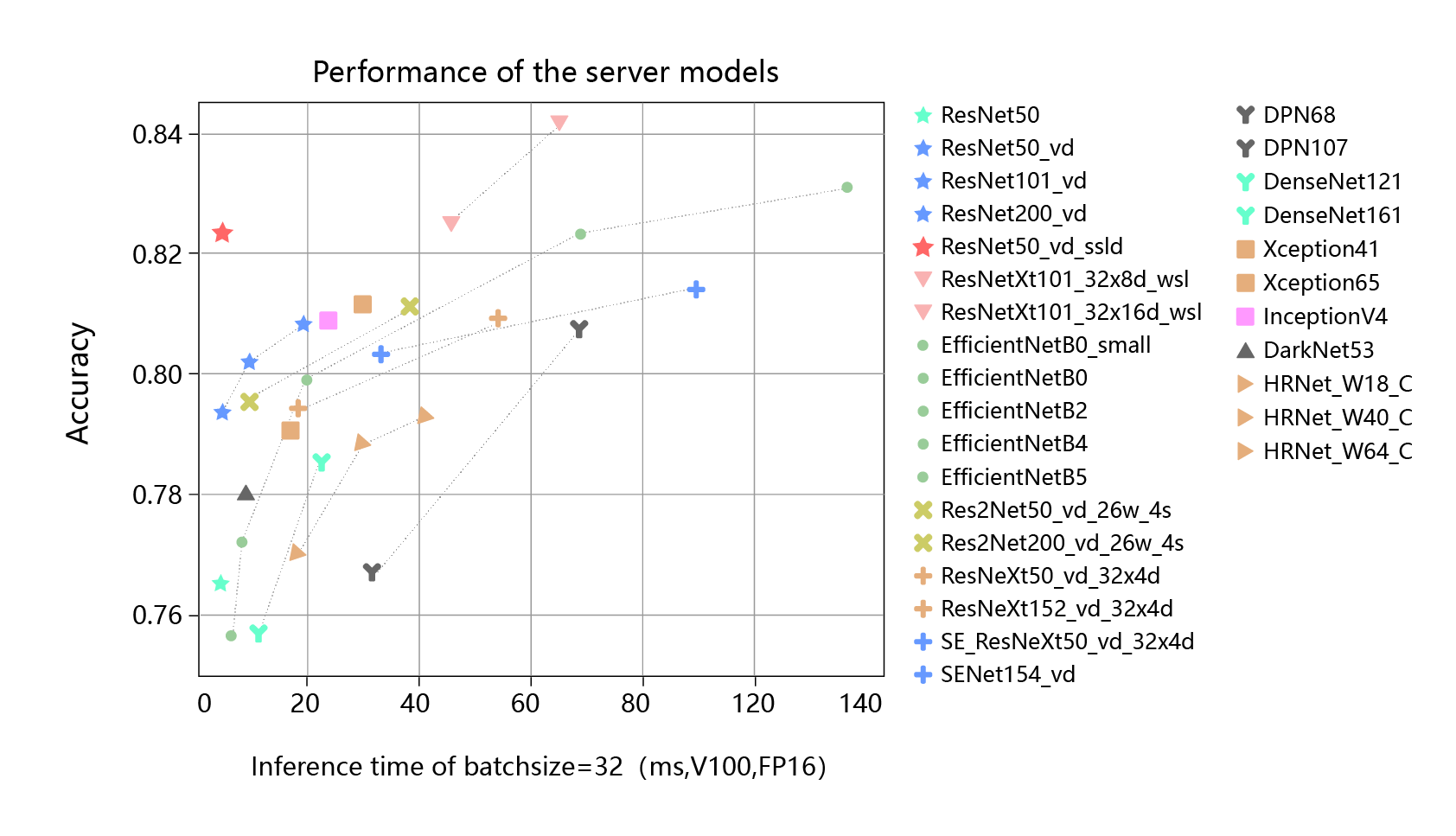
图3:各类模型精度与速度(服务器部署)
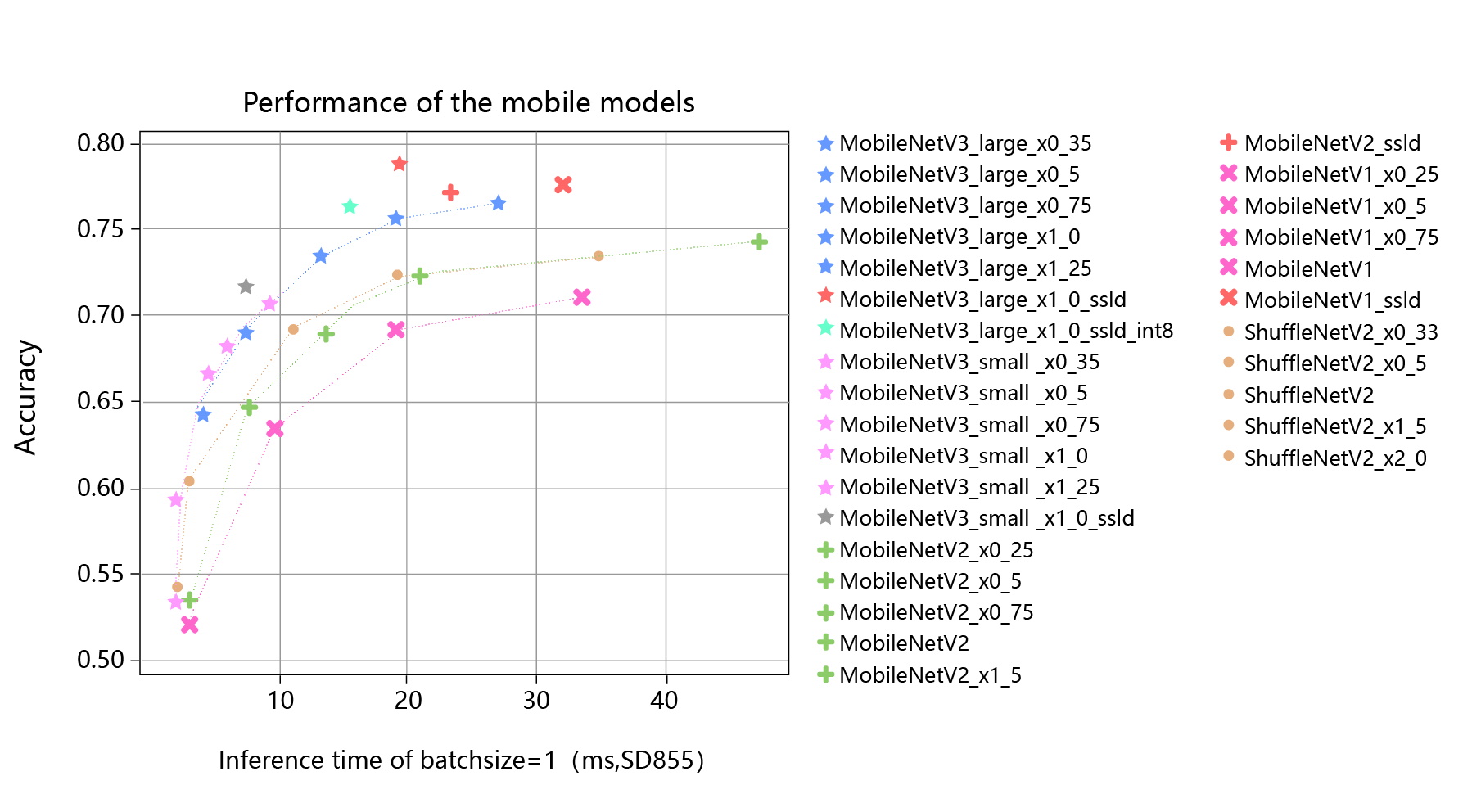
图4:各类模型精度与速度(移动端部署)
通过对桃子分类需求场景和硬件环境的分析,我们希望模型的精度超过0.7,但是模型的推理速度不能超过10ms。以此为条件筛选上述模型,我们可以选择MobileNetV3_small_x1_0.25 或者MobileNetV3_small_x1_0_ssld。
使用飞桨模型库或在其基础上二次研发的优势
飞桨官方模型库中的模型使用了大量在国际竞赛中夺冠的领先算法,确保了模型的精度水平。另一方面,飞桨官方模型库依托百度丰富中文的互联网数据资源和大数据处理能力,在中文自然语言处理领域具有更明显的领先优势,例如中文分词算法LAC、中文情感分类模型、中文语义表示预训练模型ERNIE等,均保持业界领先的水平。
| 获奖模型 | 国际竞赛 | 名次 |
|---|---|---|
| PyramidBox模型 | WIDER FACE三项测试子集 | 第一 |
| Attention Clusters网络模型 | ActivityNet Kinetics Challenge 2017 | 第一 |
| StNet模型 | ActivityNet Kinetics Challenge 2018 | 第一 |
| 基于Faster R-CNN的多模型 | Google AI Open Images-Object Detection Track | 第一 |
| C-TCN动作定位模型 | ActivityNet Challenge 2018 | 第一 |
| Multi-Perspective 模型 | SemEval 2019 Task 9 SubTask A | 第一 |
| 增强学习框架PARL | NIPS AI for Prosthetics Challenge | 第一 |
除了提供高精度算法外,官方模型库提供的算法在性能上也处于领先地位。例如自然语言处理领域的基础模型transformer,飞桨做了包括算子融合、量化等优化,与业界同类模型相比推理速度可提高4倍,可以极大地节省计算资源。
飞桨官方模型库提供的算法在经过了大量实际应用场景验证后,具有很高的稳定性。例如图像检测YOLOv3算法应用于南方电网,实现巡检机器人指针类表计自动读取;Faster R-CNN算法应用于中科院遥感所实现地块智能分割;MobileNet算法应用于大恒图像电池隔膜缺陷检测等等。
讲到这里,大家是否已经迫不及待了呢? 接下来,我们以经典序列召回模型GRU4REC为例,介绍Models库中模型的使用方法。
一个案例掌握Models的使用方法
本章以Models中的GRU4REC为例,讲解Models中的模型使用方法。 在飞桨官方的Models中包含了许多模型,同时包含模型使用的readme文档,每个模型按照类别分别存放在PaddleCV、PaddleNLP、PaddleSpeech、PaddleRec等目录下。
GRU4REC模型简介
GRU4REC模型的介绍可以参阅论文Session-based Recommendations with Recurrent Neural Networks 。论文的贡献在于首次将RNN(GRU)运用于Session-Based推荐,相比传统的KNN和矩阵分解,效果有明显的提升。
模型的核心思想是在一个Session中,同一个用户点击一系列Item的行为看做一个序列,这个序列可以看作一条数据。这样的数据组成的数据集将被用来训练召回模型,例如Session为{A1A1A1,A2A2A2,A3A3A3},可以转变成A1A1A1->A2A2A2(以A1A1A1为输入,预测A2A2A2),A2A2A2->A3A3A3两条训练样本。
如下图所示,将用户访问商品的序列作为训练数据集进行训练,如图中的用户A、用户B、用户C点击的数据。模型使用这些数据进行训练的过程如下所示:
- 用户的点击Item序列数据作为输入,这个Item在经过模型的Embedding层处理后会转化为词向量,词向量间的欧式距离代表着两个Item的相近程度,例如连衣裙和女鞋对应的向量间的距离就会近一些,篮球和女鞋之间的距离就会远一些。
- 这些词向量将会依照点击顺序形成成对的输入格式,以用户A的数据为例,连衣裙对应的词向量A1A1A1是第一时刻的输入,其对应的推理输出就是女鞋对应的词向量A2A2A2,依次类推。
- 用户A的数据将被输入到GRU层进行处理,GRU层会选择性的保留数据中重要信息,忽略不重要的信息,并输出两次推理的深层表达信息A2′A2'A2′和A3′A3'A3′。GRU的具体实现过程可参考后面的具体实现过程。
- 深层表达信息A2′A2'A2′和A3′A3'A3′以及对应的真实输出A2A2A2和A3A3A3一起输入到前向反馈层中,并由其中的损失函数处理计算出损失(LOSS)。
- 在不断训练过程中,模型会根据LOSS不断反向调整模型参数。当完成训练后,用户可以根据模型的评估指标选出训练成功的模型,用于推理。
推理过程与训练过程基本相似,主要差异在于深层表达信息在前向反馈层中将交由词表维度矩阵进行映射,从而生成所有商品成为用户下一次点击对象的概率。概率最高的前20名的Item里如果包含真实结果,则表示推理成功。
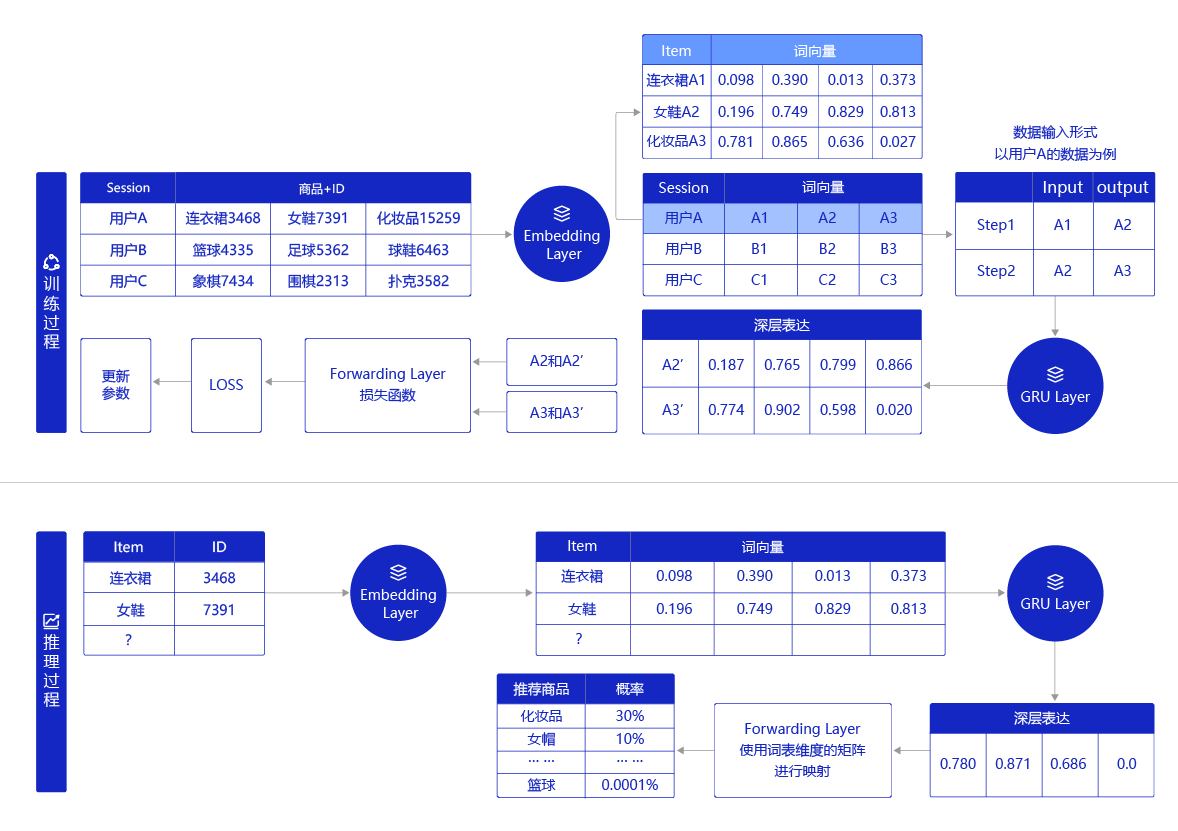
图5 召回模型示例图
session-based推荐应用场景非常广泛,例如用户的商品浏览、新闻点击、地点签到等序列数据。召回模型需要对全局商品库进行筛选,所以不会拥有像排序模型那样复杂的特征和网络结构,而session-based的数据是用户与商品交互中最简单的一种形式。
GRU4REC模型属于个性化推荐类模型,动态图实现的代码放置在models库中的PaddleRec/gru4rec/dy_graph中。
代码目录结构如下: 召回模型库包括如下文件:
. ├── args.py # 主要是设置默认参数的文件 ├── gru4rec_dy.py # 主程序脚本,包含了包括组网在内的全部训练和预测代码 ├── model_check.py # 飞桨版本校准,主要是验证使用的飞桨版本 ├── reader.py # 数据迭代器文件,用来将原始数据转为程序可以使用的数据 ├── run_gru.sh # 程序启动脚本,用来启动训练和预测 └── data # 数据集文件夹,训练和预测的训练地址,由程序启动脚本指定这里为数据的地址
# 下载数据集 !wget https://paddlerec.bj.bcebos.com/gru4rec/dy_graph/ai_studio_18.tar
!tar xvf ai_studio_18.tar
--2022-05-06 14:23:34-- https://paddlerec.bj.bcebos.com/gru4rec/dy_graph/ai_studio_18.tar Resolving paddlerec.bj.bcebos.com (paddlerec.bj.bcebos.com)... 182.61.200.195, 182.61.200.229, 2409:8c04:1001:1002:0:ff:b001:368a Connecting to paddlerec.bj.bcebos.com (paddlerec.bj.bcebos.com)|182.61.200.195|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 148264960 (141M) [application/x-tar] Saving to: ‘ai_studio_18.tar’ ai_studio_18.tar 100%[===================>] 141.40M 44.0MB/s in 3.3s 2022-05-06 14:23:37 (43.2 MB/s) - ‘ai_studio_18.tar’ saved [148264960/148264960] args.py data/ data/ptb.valid.txt data/ptb.train.txt data/ptb.test.txt gru4rec_dy.py model_check.py reader.py README.md run_gru.sh
模型的输入数据一行表示一个Item的ID序列,这些ID可以是用户网站中的页面ID,也可以是网站中的商品ID,还可以是其它代表用户兴趣和选择的编号。ID之间按照空格切分,如 图6 所示,这些训练的数据保存在data目录下,数据处理的代码实现在reader.py文件中。
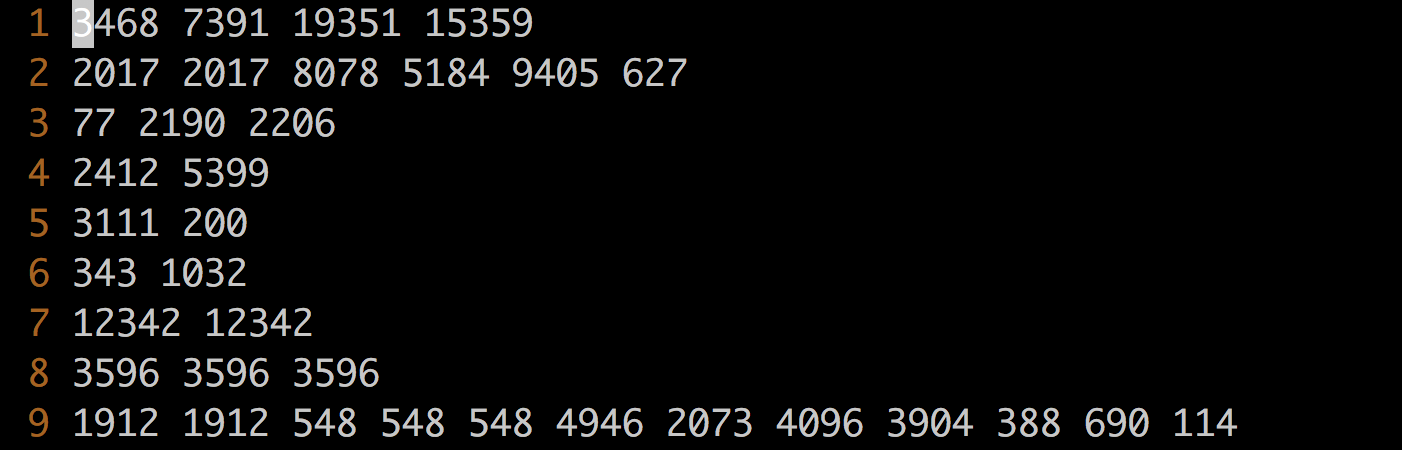
图6 数据格式
2. 模型定义
模型的结构如 图7 所示,主要包括Embedding layer、GRU 序列层 (GRU layer)、前向回馈层几个部分。
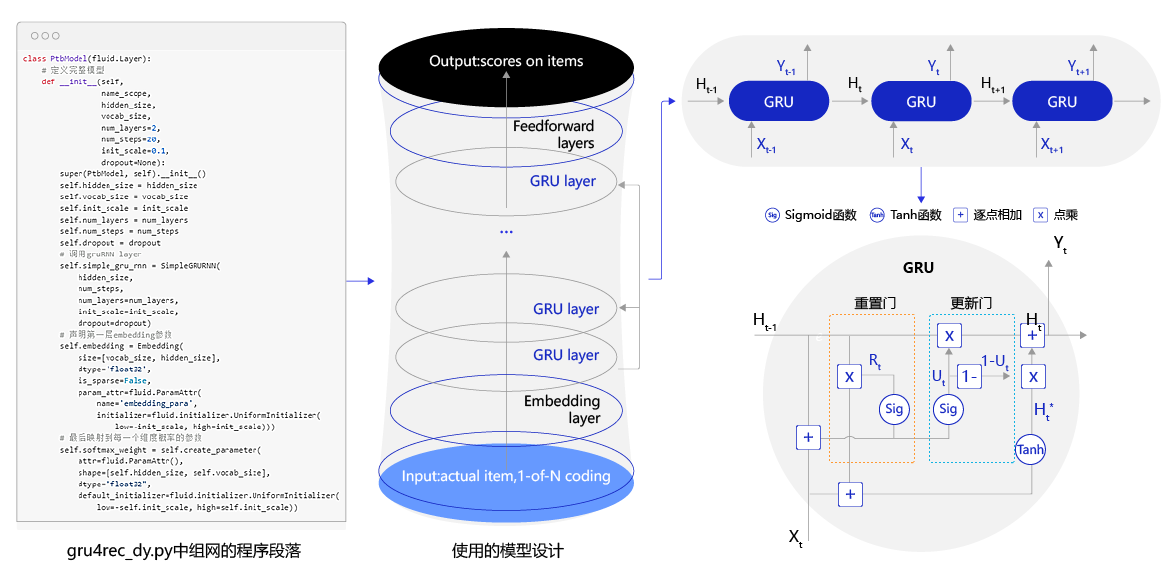 >图7 召回模型结构图
>图7 召回模型结构图模型定义的文件在gru4rec_dy.py文件中,大家可以参考模型的理论对模型源代码做出任何需要的改进,包括网络结构的每个细节。
3. 启动训练
训练代码定义在gru4rec_dy.py脚本的train_ptb_lm()函数中,启动运行可以使用命令行:
python -u gru4rec_dy.py --data_path data/ --model_type gru4rec
也可以直接使用提供的脚本运行,如下:
sh run_gru.sh
训练的过程中,会打印如下信息:
- epoch 表示训练的第几轮;
- Batch 表示训练的当前batch数目;
- ppl 表示Perplexity,即模型收敛的程度,越小说明收敛越好;
- acc表示recall@20的值;
- lr表示当前学习率;

模型每训练一个epoch都会评估一次模型,评估会打印出最终的recall@20的值,表示预测的前20个中是否预测正确,recall@20值越大表示预测效果越好。训练一个epoch的评估结果如下:
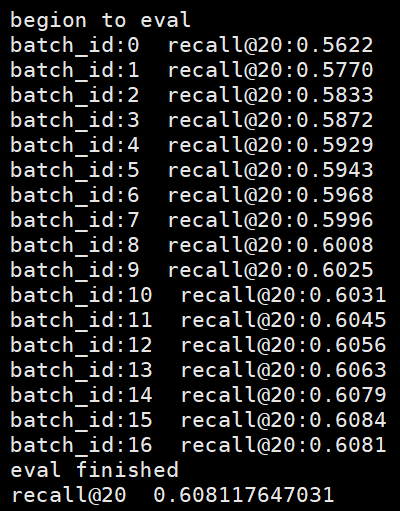
飞桨官方模型库中每个模型的代码结构和文档说明均是类似的,大家均可以参考GRU4REC的案例去使用任何模型。
- 如果期望模型不变,只是训练数据换成自己业务场景中的数据:只要将新数据放到data/目录下,修改数据处理程序 reader.py即可;
- 如果还希望进一步的优化模型:在主程序中gru4rec_dy.py中找到组网的段落,可以优化每一个细节。
