

文档简介:



PaddleNLP
介绍完计算机视觉的开发套件PaddleSeg后,让我们继续了解一个自然语言处理方面的开发套件PaddleNLP。PaddleNLP是基于Paddle框架开发的自然语言处理 (NLP) 开源项目,项目中包含工具、算法、模型和数据多种资源。PaddleNLP通过丰富的模型库、简洁易用的API,提供飞桨2.0的最佳实践并加速NLP领域应用产业落地效率。
GitHub链接:https://github.com/PaddlePaddle/PaddleNLP
丰富的模型库:涵盖了NLP主流应用相关的前沿模型,包括中文词向量、预训练模型、词法分析、文本分类、文本匹配、文本生成、机器翻译、通用对话、问答系统等。
简洁易用的全流程API:深度兼容飞桨2.0的高层API体系,提供更多可复用的文本建模模块,可大幅度减少数据处理、组网、训练环节的代码开发,提高开发效率。不仅可以通过全流程API高效搭建自研的网络,还可以在现有模型库上便捷的二次研发。
高性能分布式训练:通过高度优化的Transformer网络实现,结合混合精度与Fleet分布式训练API,可充分利用GPU集群资源,高效完成预训练模型的分布式训练。飞桨分布式技术已经支持千亿参数的NLP大模型训练,处于业界领先。
如上图所示,PaddleNLP在数据加载、数据处理、模型组网和模型评估方面都提供了丰富的API。以组网单元为例,即提供了常用的通用网络结构如LSTM和GRU,也提供了一些领域专用的网络如CRF。更重要的是,很多网络结构还提供了预训练模型,如基于大量中文语料数据训练的Bert和Ernie模型。使用这些预训练模型可以通过一行的API调用来完成。
在第五章自然语言处理的部分,我们已经使用飞桨框架搭建了LSTM模型来解决情感分类的问题。下面,我们将展示如何基于PaddleNLP中的预训练模型ERINE来实现另外一个文本分类的任务:对新闻标题进行分类。
基于ERNIE模型的新闻标题分类
文本分类是指人们使用计算机将文本数据进行自动化归类的任务,是自然语言处理(NLP)中的一项重要任务。在大数据、人工智能技术火热发展的今天,文本分类技术有着广泛的应用场景。比如,将文本分类应用在电商商品的评价方面,可以识别消费者对商品的态度,同时也可以从消费者的评论中提取很多有待改善的意见(第五章的情感分类案例);将文本分类应用在广告过滤、假大空新闻识别、反黄识别等等方面,可以帮助新闻平台提取更多有价值的新闻,同时用户也能得到更多有价值的推荐新闻;将文本分类应用在垃圾邮件识别上,可以防止用户被过多垃圾信息打扰,避免错过重要邮件。
本案例将基于PaddleNLP中的预训练模型ERNIE对THUCNews新闻标题数据进行文本分类,本实验一方面会带你学习ERNIE的原理,一方面将带你体验如何基于ERNIE 微调(fune-tuning)文本分类任务。不过在学习本案例之前,建议读者先了解下Transformer模型的概念。如果暂时没有精力,就可以将它当作一种比LSTM更加复杂的、适合处理序列数据的模型。
本案例的模型实现方案如 图2 所示, 模型的输入是新闻标题的文本,模型的输出就是新闻标题的类别。在建模过程中,对于输入的新闻标题文本,首先需要进行数据处理生成规整的文本序列数据,包括语句分词、将词转换为id,过长文本截断、过短文本填充等等操作;然后使用预训练模型ERNIE对文本序列进行编码,获得文本的语义向量表示;最后经过全连接层和softmax处理得到文本属于各个新闻类别的概率。方案中不仅会使用ERNIE预训练模型,还会使用大量PaddleNLP的API,更便捷的完成数据处理和模型评估等工作。
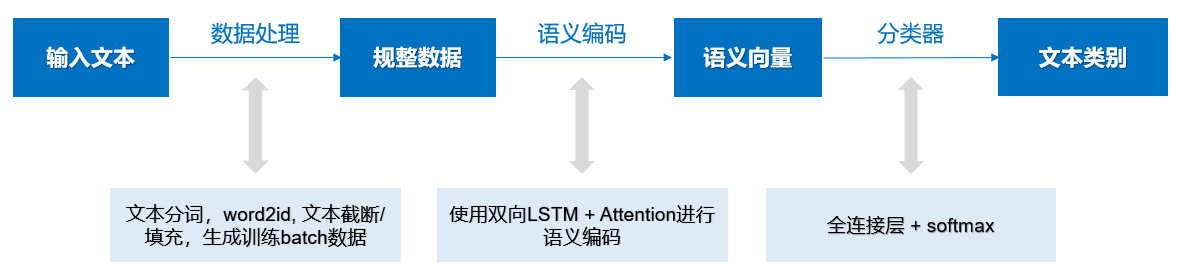
图2 基于ERNIE文本任务的实验流程
ERNIE的模型理论
本实验将默认同学们已经了解BERT或者Transformer模型内容,如有需要,请参考Attention Is All You Need。在正式地开始实验之前,我们还是先来讨论一下ERNIE到底是什么?它有哪些亮点?为什么它有这么强悍的性能,在NLP领域取得多项突破?
ERNIE是什么?
ERINE是百度发布一个预训练模型,它通过引入三种级别的Knowledge Masking帮助模型学习语言知识,在多项任务上超越了BERT。在模型结构方面,它采用了Transformer的Encoder部分作为模型主干进行训练,如 图3 (图片来自网络)所示。
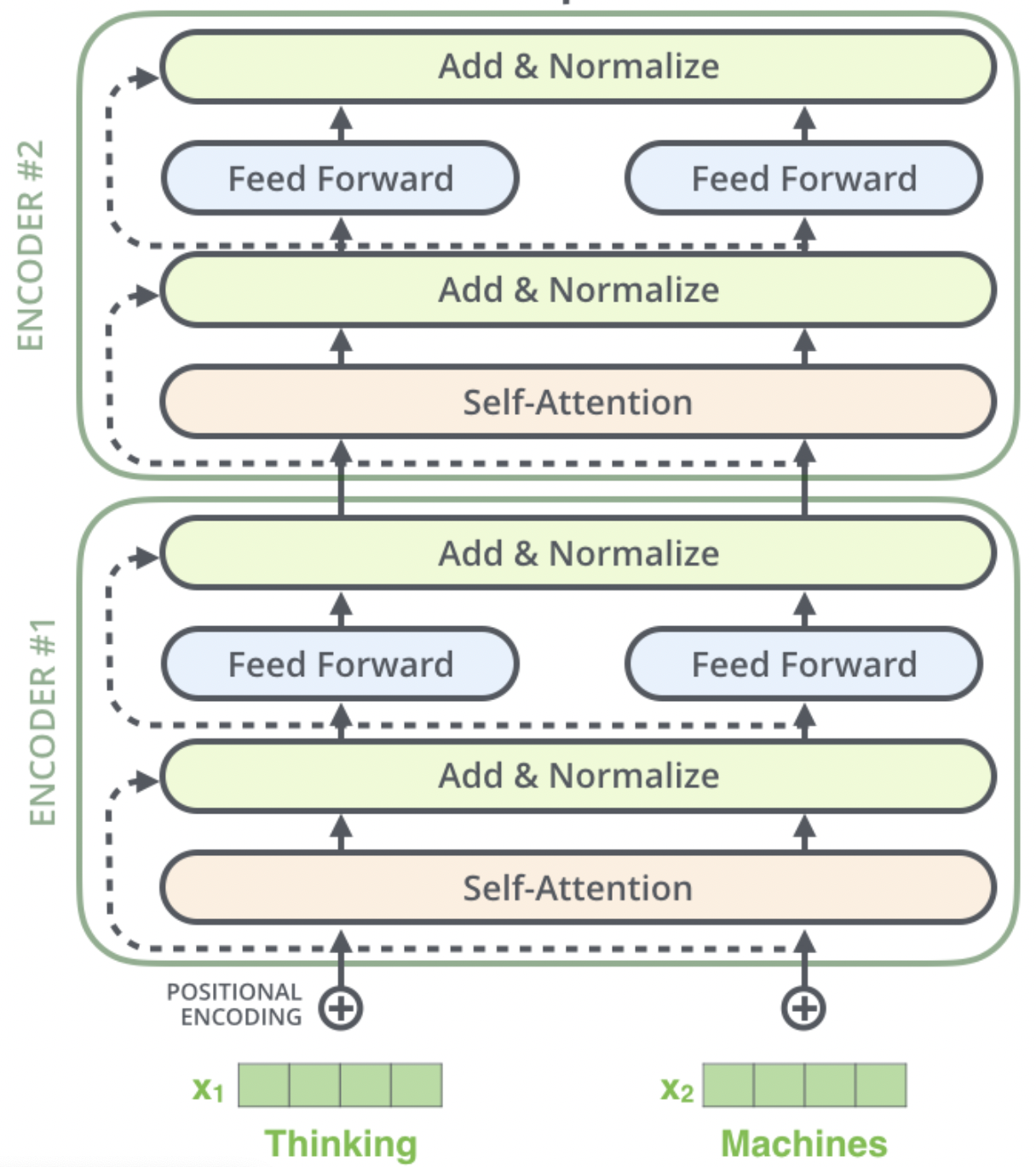
图3 Transformer的Encoder部分
关于ERNIE网络结构(Transformer Encoder)的工作原理,这里不再展开讨论。接下来,我们将聚焦在ERNIE本身的主要改进点进行讨论,即上边提到的三种Knowledge Masking策略。这三种策略都是应用在ERNIE预训练过程中的预训练任务,期望通过这三种级别的任务帮助ERNIE学到更多的语言知识。
几个概念的简单说明:
-
Seq2Seq模型: sequence to sequence模型是一类End-to-End的算法框架,也就是从序列到序列的转换模型框架,应用在机器翻译,自动应答等场景。Seq2Seq一般是通过Encoder-Decoder(编码-解码)框架实现,Encoder和Decoder部分可以是任意的文字,语音,图像,视频数据,模型可以采用CNN、RNN、LSTM、GRU、BLSTM等等。可见,Encoder-Decoder是一种模型框架或者说设计理念,我们可以据此设计出各种各样的应用算法。很多时候,我们也会将模型分为encoder和decoder两个结构分开使用,其中encoder产生的向量包括了整个输入Sequence的抽象。
-
Attention机制(注意力):注意力机制可以利用人类的认知机制直观解释。例如,我们的视觉系统倾向于关注图像中辅助判断的部分信息,并忽略掉不相关的信息。同样,在自然语言处理的问题中,输入的某些部分可能会比其他部分对决策更有帮助。例如,在翻译和总结任务中,输入序列中只有某些单词可能与预测下一个单词相关。同样,在image-caption问题中,输入图像中只有某些区域可能与生成caption的下一个单词更相关。注意力模型通过允许模型动态地关注有助于执行手头任务的输入的某些部分,而不是泛泛的关注全部信息。如果在Encoder-Decoder框架上实现Attenetion机制,相当于Encoder产生的向量并不是全部作用于每个输出,而是根据当前输出与向量的每个部分计算匹配权重(相当于是否需要投注意力的衡量),得到一个加权后的向量。这个加权后的向量相当于有选择的挑选了部分关注点。
-
Transfomer模型:很多NLP的语义学习问题涉及到大量的训练数据,而RNN类的模型内部存在计算依赖,无法高效的并行化训练。使用Self-attenion的方法,将RNN变成每个输入与其他输入部分计算匹配度来决定注意力权重的方式,使得模型引入了Attention机制的同时也具备了并行化计算的能力。以这种Self-attention结构为核心,设计Encoder-Decoder的结构形成Transformer模型。BERT和ERNIE均是将Transformer的Encoder部分结构单独取出,用多个的非标记语料(转成标记数据,如填空/判断句子连续性等)的任务训练,并将得到的Encoder向量作为词汇的基础语义表示用于多种NLP任务(如阅读理解)的模型。
2.2 Knowledge Masking Task
训练语料中蕴含着大量的语言知识,例如词法,句法,语义信息,如何让模型有效地学习这些复杂的语言知识是一件有挑战的事情。BERT使用了MLM(masked language-model)和NSP(Next Sentence Prediction)两个预训练任务来进行训练,这两个任务可能并不能让BERT学到那么多复杂的语言知识,特别是后来多个研究人士提到NSP任务是比较简单的任务,它实际的作用不大。
说明:
masked language-model(MLM)是指在训练的时候随即从输入预料上mask掉一些单词,然后通过的上下文预测该单词,该任务非常像我们在中学时期经常做的完形填空。 Next Sentence Prediction(NSP)的任务是判断句子B是否是句子A的下文。 这两种任务的训练样本都可以根据大量语料自动生成,而不用人工标注,这也是这些任务被用于训练语义表示大模型的原因。
考虑到这一点,ERNIE提出了Knowledge Masking的策略,其包含三个级别:ERNIE将Knowledge分成了三个类别:token级别(Basic-Level)、短语级别(Phrase-Level) 和 实体级别(Entity-Level)。通过对这三个级别的对象进行Masking,提高模型对字词、短语的知识理解。
图4展示了这三个级别的Masking策略和BERT Masking的对比,显然,Basic-Level Masking 同BERT的Masking一样,随机地对某些单词(如 written)进行Masking,在预训练过程中,让模型去预测这些被Mask后的单词;Phrase-Level Masking 是对语句中的短语进行masking,如 a series of;Entity-Level Masking是对语句中的实体词进行Masking,如人名 J. K. Rowling。
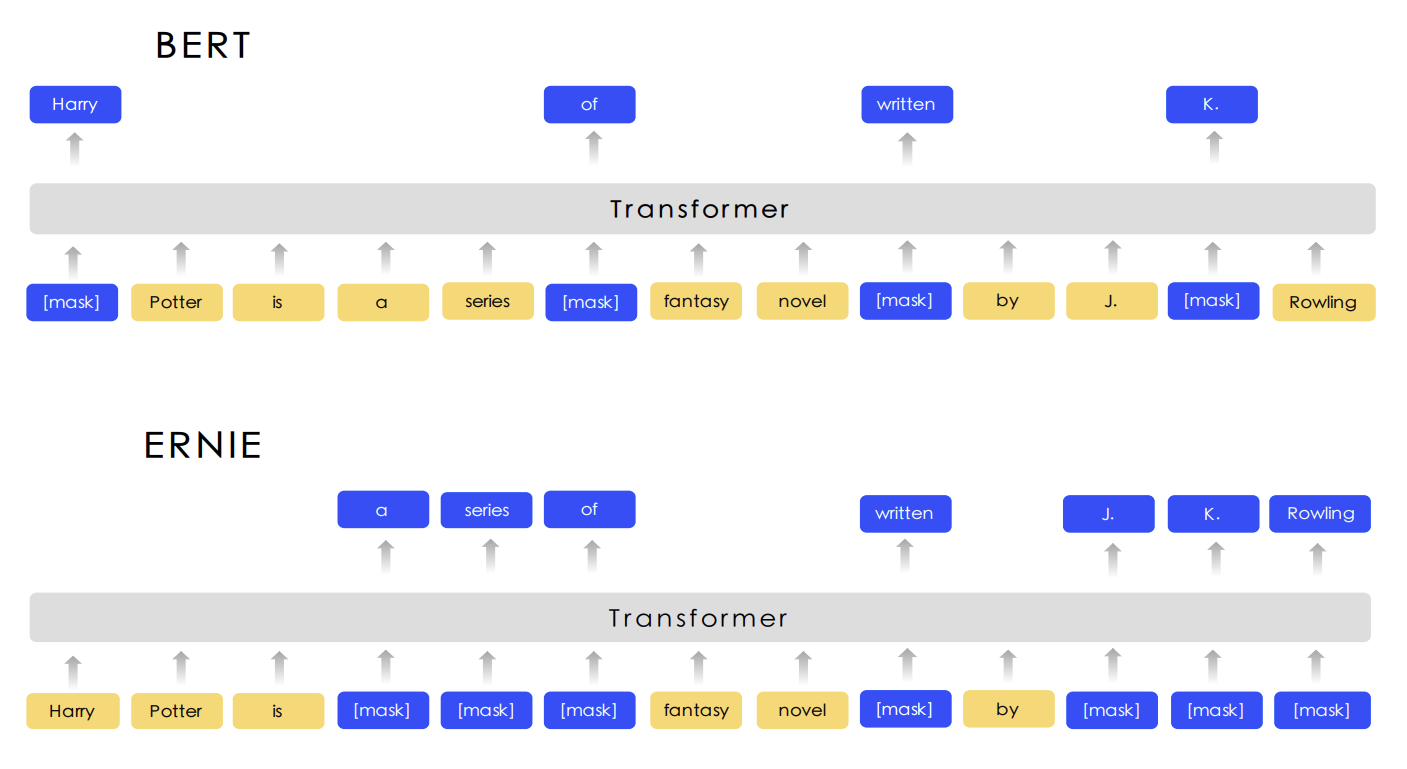
图4 ERNIE和BERT的Masking策略对比
除了上边的Knowledge Masking外,ERNIE还采用多个异源语料帮助模型训练,例如对话数据,新闻数据,百科数据等等。通过这些改进以保证模型在字词、语句和语义方面更深入地学习到语言知识。当ERINE通过这些预训练任务学习之后,就会变成一个更懂语言知识的预训练模型,接下来,就可以应用ERINE在不同的下游任务进行微调,提高下游任务的效果。例如,用于文本分类任务:新闻标题的主题分类。
异源语料 :来自不同源头的数据,比如百度贴吧,百度新闻,维基百科等等
基于ERINE详细实现
THUCNews新闻文本分类实验流程如 图5 所示,包含如下6个步骤:
- 数据处理:根据网络接收的数据格式,完成相应的预处理操作,保证模型正常读取;
- 模型构建:设计新闻主题分类模型,判断标题所属的主题类别;
- 训练配置:实例化模型,选择模型计算资源(CPU或者GPU),指定模型迭代的优化算法;
- 模型训练与评估:执行多轮训练不断调整参数,以达到较好的效果;
- 模型保存:将模型参数保存到指定位置,便于后续推理或继续训练使用;
- 模型预测:对训练好的模型进行推理测试;
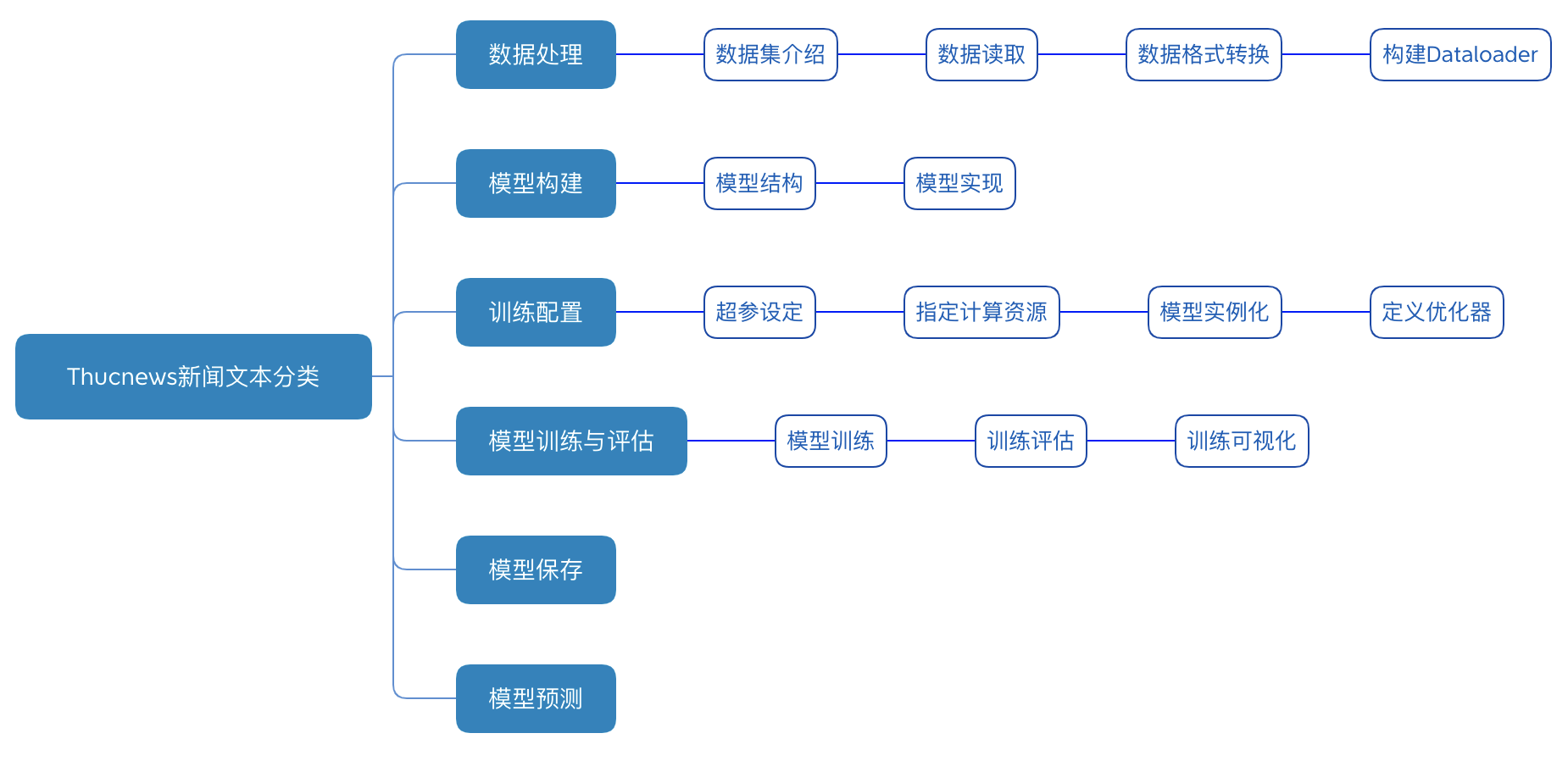
图5 THUCNews文本分类的实验流程
数据处理
首先,将基于paddleNLP套件中的ERNIE模型进行微调文本分类任务,因此在数据处理阶段,需要将数据按照paddleNLP规定的格式进行处理。但总体上数据处理的步骤基本是:读取数据至内存、分词并转换数据形式、构造DataLoader以组装数据为mini-batch形式,以便模型处理。虽然流程较长,但绝大多数自然语言处理任务均会如此处理,有过一次的经验就不陌生了。同时,paddleNLP对数据处理过程进行了高级API的封装,使得整个数据构造过程变得简洁了。
数据集介绍
THUCNews是根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成,包含74万篇新闻文档,均为UTF-8纯文本格式。在原始新浪新闻分类体系的基础上,重新整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐。
本案例使用的数据集是从THUCNews新闻数据中根据新闻类别按照一定的比例提取了新闻标题,处理后的数据可以点此下载,其中训练集数据约27.1w,测试集约6.7w条。另外,我们已经根据新闻类别整理出了一份记录标签的词表 label_dict.txt。
数据读取
这里我们将构造一个数据集类THUCDataSet类,该类将完成数据读取,和数据获取的功能,即将训练集或者测试集通过该类进行加载,这会让处理数据的代码更加简洁、优雅。
import numpy as np from functools import partial import paddle import paddle.nn as nn
from paddle.io import Dataset import paddle.nn.functional as F import paddlenlp from
paddlenlp.datasets import MapDataset from paddlenlp.data import Stack, Tuple, Pad from
paddlenlp.transformers import LinearDecayWithWarmup class THUCDataSet(Dataset): def
__init__(self, data_path, label_path): # 加载标签词典 self.label2id = self._load_label_
dict(label_path) # 加载数据集 self.data = self._load_data(data_path)
self.label_list = list(self.label2id.keys()) # 加载数据集 def _load_data(self,
data_path): data_set = [] with open(data_path, "r", encoding="utf-8") as f: for line in f.readlines():
label, text = line.strip().split("\t", maxsplit=1)
example = {"text":text, "label": self.label2id[label]}
data_set.append(example) return data_set # 加载标签词典 def _load_label_
dict(self, label_path): with open(label_path, "r", encoding="utf-8") as f:
lines = [line.strip().split() for line in f.readlines()]
lines = [(line[0], int(line[1])) for line in lines]
label_dict = dict(lines) return label_dict def __getitem__(self, idx):
return self.data[idx] def __len__(self): return len(self.data)
转换数据格式
上边完成了数据集类THUCDataSet的定义,当我们加载数据后,通过索引获取其中的某条数据时,数据的格式如图6所示。每条数据都被封装为了一个字典,每条数据包含文本内容和对应的标签label。

图6 THUCDataSet中的一个样本
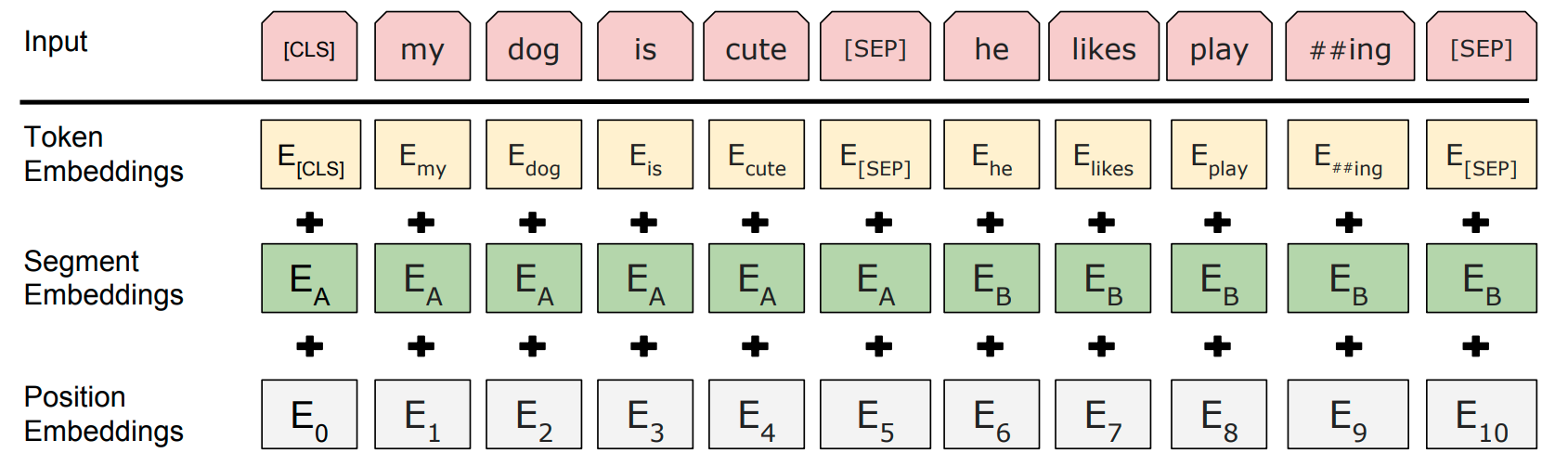
但是ERNIE模型希望的语料数据输入格式同BERT,如图7所示,只有这样ERNIE才更方便将新的语料样本用于多种类型训练任务,如masked language-model、Next Sentence Prediction以及本案例需要完成的文本分类任务等。
图7 ERNIE的数据输入格式
因此,需要将以上生成数据转换成这样的输入格式,输入包括token ids 和 segment ids (通常也被称为token type ids),position ids无需自己生成,模型内部可以自动生成, 转换之后如图8所示。

图8 ERNIE数据输入样例
这里在转换数据格式的时候,可以调用paddleNLP封装好的tokenizer,它可以帮助我们一行代码将原始数据转换成模型输入的格式。最后数据转换之后,如果有label,也需要返回做一个完整的样本。相关的代码如下,example[“text”]指定样本的文本,tokenizer指定我们期望使用的转换器。例如ERINE和BERT这样常用的模型,PaddleNLP均提供了线程的转换器。最后,通过转换结果encoded_inputs变量的不同字段,即可以得到不同的输出序列。
def convert_example(example, tokenizer, max_seq_length=128, is_test=False): encoded_inputs
= tokenizer(text=example["text"], max_seq_len=max_seq_length)
input_ids = encoded_inputs["input_ids"]
token_type_ids = encoded_inputs["token_type_ids"] if not is_test:
label = np.array([example["label"]], dtype="int64") return input_ids, token_type_ids,
label else: return input_ids, token_type_ids
构建DataLoader
最后,我们需要构建一个DataLoader,帮我们将数据组装成规整的mini-batch的形式,以便传入模型进行处理。
整个处理流程是这样的:首先使用convert_example处理数据为期望的格式,然后将调用paddle.io.DataLoader来构建DataLoader,在这个DataLoader生成mini-batch数据的过程中,会通过使用batchify_fn函数进行同一文本序列长度,处理lable等操作,以保证返回的数据适合输入模型中。
相关代码如下,这里有两个比较重要的操作:
- dataset.map(trans_fn):它会使用trans_fn( 即convert_example函数)处理每个样本成我们我们期待的数据格式。
- batchify_fn:在DataLoader提取出mini-batch数据后,这些数据是长短不一的,所以我们借助batchify_fn这个操作去规整化mini-batch数据为模型期望的样式,我们可以看到它的处理函数fn中包含3个操作,前两个是padding操作分别对应这token ids和segment ids,最后一个是stack操作处理的是label数据。
def create_dataloader(dataset,
mode='train',
batch_size=1,
batchify_fn=None,
trans_fn=None): # trans_fn对应前边的covert_example函数,使用该函数处理每个样本为期望的格式 if trans_fn:
dataset = dataset.map(trans_fn)
shuffle = True if mode == 'train' else False if mode == 'train':
batch_sampler = paddle.io.DistributedBatchSampler(
dataset, batch_size=batch_size, shuffle=shuffle) else:
batch_sampler = paddle.io.BatchSampler(
dataset, batch_size=batch_size, shuffle=shuffle) # 调用paddle.io.DataLoader
来构建DataLoader return paddle.io.DataLoader(
dataset=dataset,
batch_sampler=batch_sampler,
collate_fn=batchify_fn,
return_list=True)
MODEL_NAME = "ernie-1.0" tokenizer = paddlenlp.transformers.ErnieTokenizer.from_pretrained(MODEL_NAME)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input Pad(axis=0, pad_val=tokenizer
.pad_token_type_id), # segment Stack(dtype="int64")
): [data for data in fn(samples)]
[2022-05-06 11:28:27,457] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/ernie-1.0/vocab.txt
在将数据组成批次的函数batchify_fn中使用了几个便捷的小工具:Stack, Pad, Tuple。读者可通过以下小示例清晰理解这几个函数的作用,分别用于将多个样本打包成一个批次、打包的过程中顺便做样本长度的补齐、特征集合与标签集合的映射三项操作。
from paddlenlp.data import Stack, Tuple, Pad
a = [1, 2, 3, 4]
b = [3, 4, 5, 6]
c = [5, 6, 7, 8]
result = Stack()([a, b, c]) print("Stacked Data: \n", result) print()
a = [1, 2, 3, 4]
b = [5, 6, 7]
c = [8, 9]
result = Pad(pad_val=0)([a, b, c]) print("Padded Data: \n", result) print()
data = [ [[1, 2, 3, 4], [1]], [[5, 6, 7], [0]], [[8, 9], [1]],
]
batchify_fn = Tuple(Pad(pad_val=0), Stack())
ids, labels = batchify_fn(data) print("ids: \n", ids) print() print("labels: \n", labels) print()
输出结果:
Stacked Data: [[1 2 3 4]
[3 4 5 6]
[5 6 7 8]] Padded Data: [[1 2 3 4]
[5 6 7 0]
[8 9 0 0]] ids: [[1 2 3 4]
[5 6 7 0]
[8 9 0 0]] labels: [[1]
[0]
[1]]
模型构建
这里我们通过使用paddleNLP直接加载预训练好的ERNIE模型,在使用ERNIE对文本序列编码之后,如图6所示,在每个token的是指都可以获得一个编码向量,同时还可以获得和两个token对应的向量,其中对应的向量可以视为代表文本序列的语义向量。将这个语义向量传入线性层便可以获得一个该文本串对应的类别向量。
我们不妨称后边接入的适用文本分类的网络为微调网络,网络的定义如下,可以看到在这个定义中,我们使用paddleNLP加载了预训练好的erinie模型,后边定义了用于文本分类的线性层。同时,程序中也设置了使用Dropout的网络优化策略,在每批样本训练的时候会隐藏一部分网络来增加训练结果的鲁棒性。
class ErnieForSequenceClassification(paddle.nn.Layer): def __init__(self, MODEL_NAME,
num_class=14, dropout=None): super(ErnieForSequenceClassification, self).__init__()
# 加载预训练好的ernie,只需要指定一个名字就可以 self.ernie = paddlenlp.
transformers.ErnieModel.from_pretrained(MODEL_NAME)
self.dropout = nn.Dropout(ropout if dropout is not None else
self.ernie.config["hidden_dropout_prob"])
self.classifier = nn.Linear(self.ernie.config["hidden_size"], num_class)
def forward(self, input_ids, token_type_ids=None, position_ids=None, attention_mask=None):
_, pooled_output = self.ernie(
input_ids,
token_type_ids=token_type_ids,
position_ids=position_ids,
attention_mask=attention_mask)
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output) return logits
训练配置
在训练之前,我们定义模型训练时用到的一些组件和资源,包括定义模型的实例化对象,选择模型训练和或评估时需要使用的计算资源(CPU或者GPU),指定模型训练迭代的优化算法。 其中,文本分类的训练时间较久,我们将默认使用GPU进行训练,通过调用 paddle.device.get_device() 来查看当前实验环境是否有GPU可用,优先使用GPU进行训练。
另外,本实验将使用 paddle.optimizer.AdamW() 算法进行模型迭代优化,学习率的变化采用LinearDecayWithWarmup的策略曲线。
最后,我们可以使用paddleNLP一键式加载训练好的ERNIE模型,这里读者可以通"ernie-1.0"加载base版的ERNIE,也可以通过"ernie-tiny"加载瘦身版的ERNIE,"ernie-tiny"较"ernie-1.0"会有更快的训练和推理速度。
训练配置的代码如下:
# 超参设置 n_epochs = 1 batch_size = 128 max_seq_length = 128 n_classes=14 dropout_rate
= None learning_rate = 5e-5 warmup_proportion = 0.1 weight_decay = 0.01 MODEL_NAME = "
ernie-1.0" # 加载数据集,构造DataLoader train_set = THUCDataSet("./train.txt", "label_dict.txt")
test_set = THUCDataSet("./test.txt", "label_dict.txt")
label2id = train_set.label2id
train_set = MapDataset(train_set)
test_set = MapDataset(test_set)
trans_func = partial(convert_example, tokenizer=tokenizer, max_seq_length=max_seq_length)
train_data_loader = create_dataloader(train_set, mode="train", batch_size=batch_size,
batchify_fn=batchify_fn, trans_fn=trans_func)
test_data_loader = create_dataloader(test_set, mode="test", batch_size=batch_size, batchify_
fn=batchify_fn, trans_fn=trans_func) # 检测是否可以使用GPU,如果可以优先使用GPU use_gpu = True
if paddle.get_device().startswith("gpu") else False if use_gpu:
paddle.set_device('gpu:0') # 加载预训练模型ERNIE # 加载用于文本分类的fune-tuning网络 model =
ErnieForSequenceClassification(MODEL_NAME, num_class=n_classes, dropout=dropout_rate)
# 设置优化器 num_training_steps = len(train_data_loader) * n_epochs
lr_scheduler = LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_proportion)
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in [
p.name for n, p in model.named_parameters() if not any(nd in n for nd in ["bias", "norm"])
])
[2022-05-06 11:30:20,200] [ INFO] - Already cached /home/aistudio/.paddlenlp/models
/ernie-1.0/ernie_v1_chn_base.pdparams W0506 11:30:20.204093 534 gpu_context.cc:244] Please NOTE: device: 0, GPU Compute Capability:
7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0506 11:30:20.209379 534 gpu_context.cc:272] device: 0, cuDNN Version: 7.6. [2022-05-06 11:30:28,707] [ INFO] - Weights from pretrained model not used in ErnieModel:
['cls.predictions.layer_norm.weight', 'cls.predictions.decoder_bias', 'cls.predictions.
transform.bias', 'cls.predictions.transform.weight', 'cls.predictions.layer_norm.bias']
# 定义统计指标 metric = paddle.metric.Accuracy() def evaluate(model, metric, data_loader):
model.eval() # 每次使用测试集进行评估时,先重置掉之前的metric的累计数据,保证只是针对本次评估。 metric.reset()
losses = [] for batch in data_loader: # 获取数据 input_ids, segment_ids, labels = batch #
执行前向计算 logits = model(input_ids, segment_ids) # 计算损失 loss = F.cross_entropy(input=logits, label=labels)
loss= paddle.mean(loss)
losses.append(loss.numpy()) # 统计准确率指标 correct = metric.compute(logits, labels)
metric.update(correct)
accu = metric.accumulate()
print("eval loss: %.5f, accu: %.5f" % (np.mean(losses), accu))
metric.reset() def train(model): global_step=0 for epoch in range(1, n_epochs+1):
model.train() for step, batch in enumerate(train_data_loader, start=1): #
获取数据 input_ids, segment_ids, labels = batch # 模型前向计算 logits = model(input_ids, segment_ids)
loss = F.cross_entropy(input=logits, label=labels)
loss = paddle.mean(loss) # 统计指标 probs = F.softmax(logits, axis=1)
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate() # 打印中间训练结果 global_step += 1 if global_step % 10 == 0 :
print("global step %d, epoch: %d, batch: %d, loss: %.5f, acc: %.5f" % (global_step,
epoch, step, loss, acc)) # 参数更新 loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad() # 模型评估 evaluate(model, metric, test_data_loader)
train(model)
# 模型保存的名称 model_name = "ernie_for_sequence_classification" paddle.save(model.state_dict(),
"{}.pdparams".format(model_name))
paddle.save(optimizer.state_dict(), "{}.optparams".format(model_name))
tokenizer.save_pretrained('./tokenizer')
def predict(data, id2label, batch_size=1): examples = [] # 数据处理 for text in data:
input_ids, segment_ids = convert_example(
text,
tokenizer,
max_seq_length=128,
is_test=True)
examples.append((input_ids, segment_ids))
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input id Pad(axis=0, pad_val=tokenizer.pad_token_id),
# segment id ): fn(samples) # 将数据按照batch_size进行切分 batches = []
one_batch = [] for example in examples:
one_batch.append(example) if len(one_batch) == batch_size:
batches.append(one_batch)
one_batch = [] if one_batch:
batches.append(one_batch) # 使用模型预测数据,并返回结果 results = []
model.eval() for batch in batches:
input_ids, segment_ids = batchify_fn(batch)
input_ids = paddle.to_tensor(input_ids)
segment_ids = paddle.to_tensor(segment_ids)
logits = model(input_ids, segment_ids)
probs = F.softmax(logits, axis=1)
idx = paddle.argmax(probs, axis=1).numpy()
idx = idx.tolist()
labels = [id2label[i] for i in idx]
results.extend(labels) return results
data = [{"text":"白羊座今天的运势很好"}]
id2label = dict([(items[1], items[0]) for items in label2id.items()])
results = predict(data, id2label)
print(results)
本节内容总结
在第五章中我们介绍过类似的文本分类任务:情感分类,但当时更多是讲述如何使用飞桨框架搭建模型。本案例则基于预训练模型ERNIE对THUCNews新闻标题进行了文本分类,更多是介绍如何在NLP领域应用飞桨提供的各种预训练模型资源。在本案例中,我们探讨了ERNIE自身的改进点,主要是Knowledge Masing策略保证模型更深入的学习语言知识。另外,我们探讨了使用paddleNLP套件如何转换数据格式,如何一键式加载预训练模型,以及如何使用预训练模型在下游任务上进行微调(fune-tuning)。需要注意,自然语言处理任务与计算机视觉任务不同,需要有较为复杂的样本数据处理流程,这个差别也体现在飞桨的开发套件上。CV开发套件的数据处理部分是统一的,不会根据模型的不同而调整;而NLP开发套件的数据处理部分则与具体模型绑定,不同的模型会有自己的数据格式要求。
最后,在本案例主要使用ERNIE 1.0模型,百度后来发布了ERNIE 2.0,它引入了更多了预训练任务学习,并且提出了一种有效的持续多任务式地学习方式保证ERNIE更有效的学习语言知识,感兴趣的读者可以查阅相关论文进行学习。
