本示例以创建一个data_survey表为例,介绍建表并上传数据。
创建表数据
- 购买集群准备好资源环境之后,在集群列表点击进入Pingo,进入相应的Pingo系统,对应的环境是根据您购买的资源为您部署的Pingo环境,包括您独享的计算资源以及存储,并为您提供方便的Web操作界面,用于作业的创建与执行。
-
进入表管理页面,先创建命名空间和数据库(也可以使用默认的数据库,直接创建数据表)。在左侧的新建下拉框中点击命名空间,在根目录下创建一个叫pingotestns的命名空间。
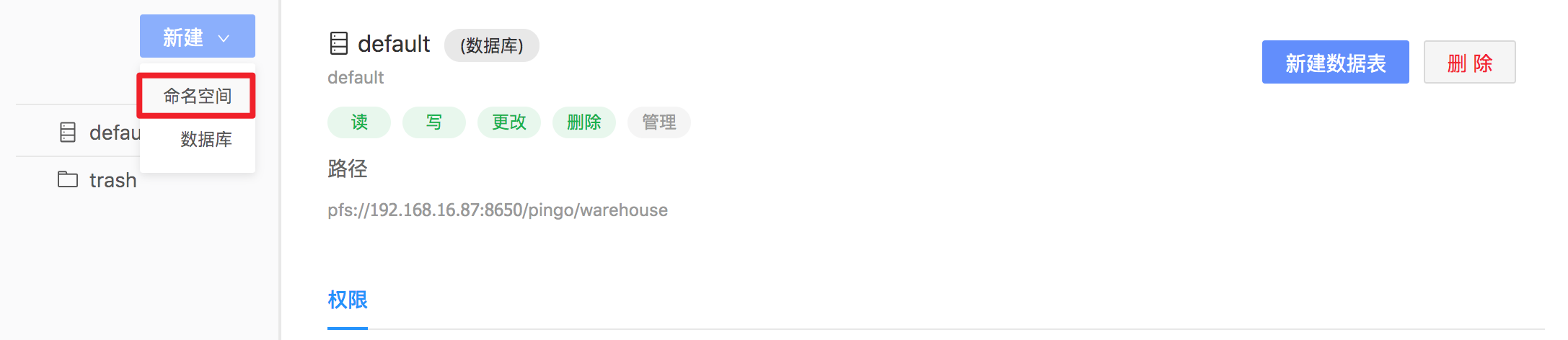
-
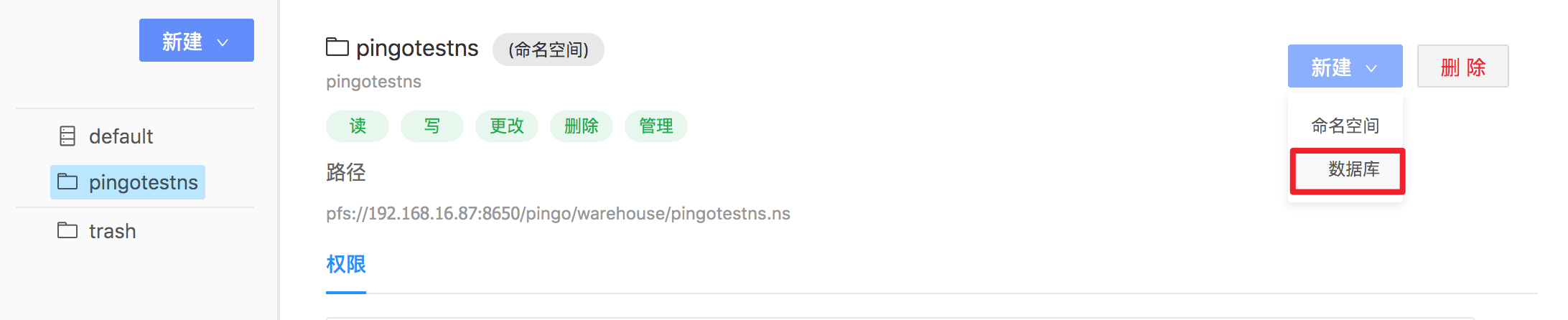
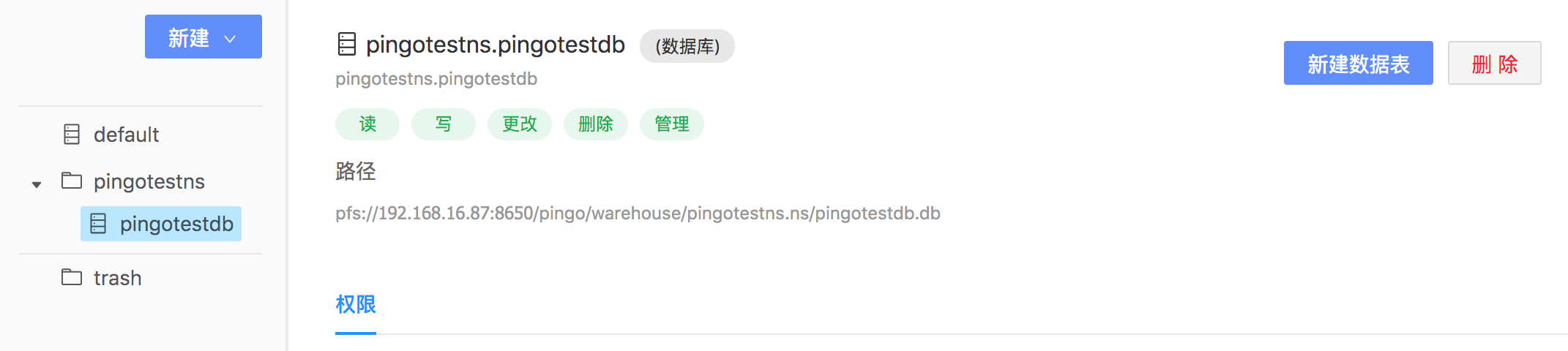
选中当前命名空间,在右侧新建下拉框中选择数据库,在命名空间pingotestns中创建一个叫pingotestdb的数据库。
注意:如果在左侧新建是创建是根目录下,要在某个特定的命名空间或数据库下面建表,需选中然后点击右侧的新建按钮操作。
输入数据库名称,点击确认。
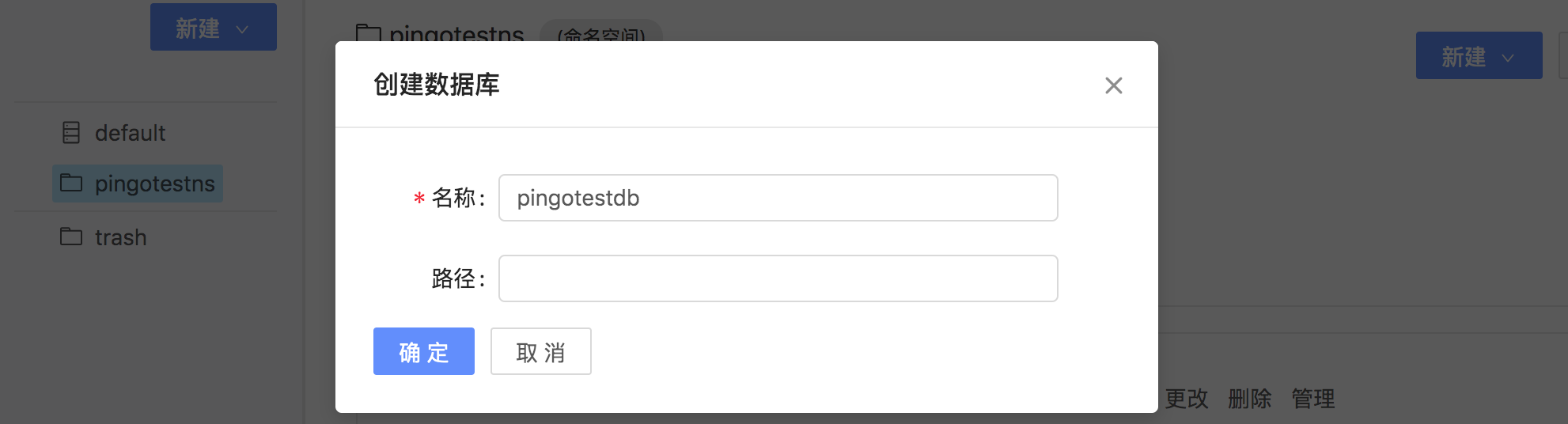
创建数据库成功。
-
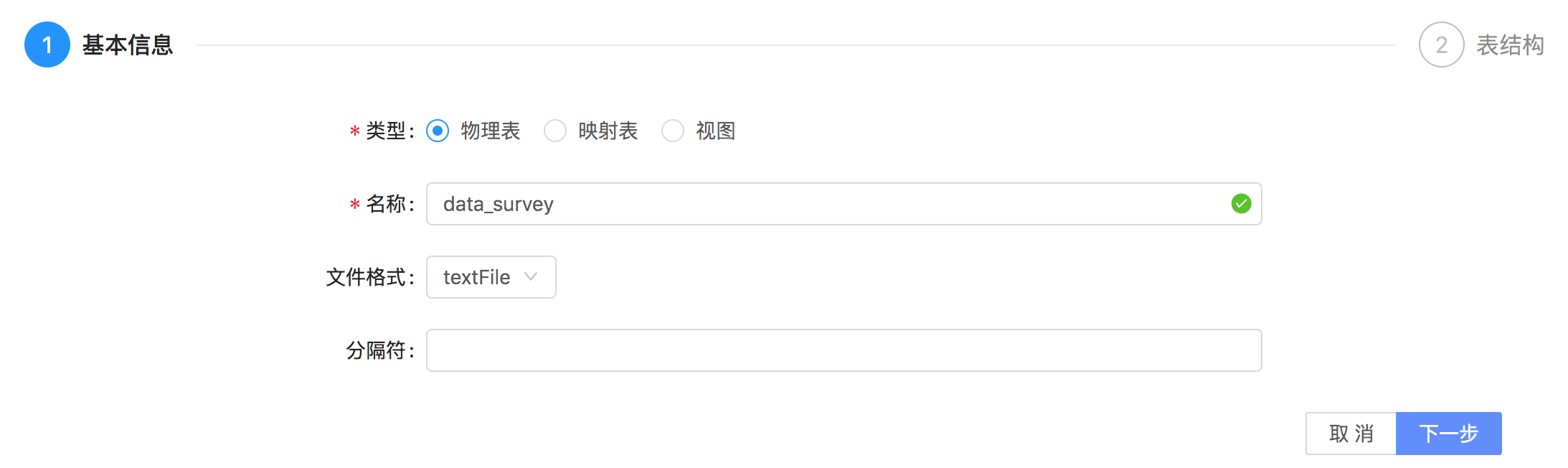
点击新建数据表,表的类型选择物理表,填写表名data_survey,文件格式和分隔符根据实际情况填写:
点击下一步,进入表结构页面,可以在界面上逐行添加字段,也可以选择从SQL语句创建
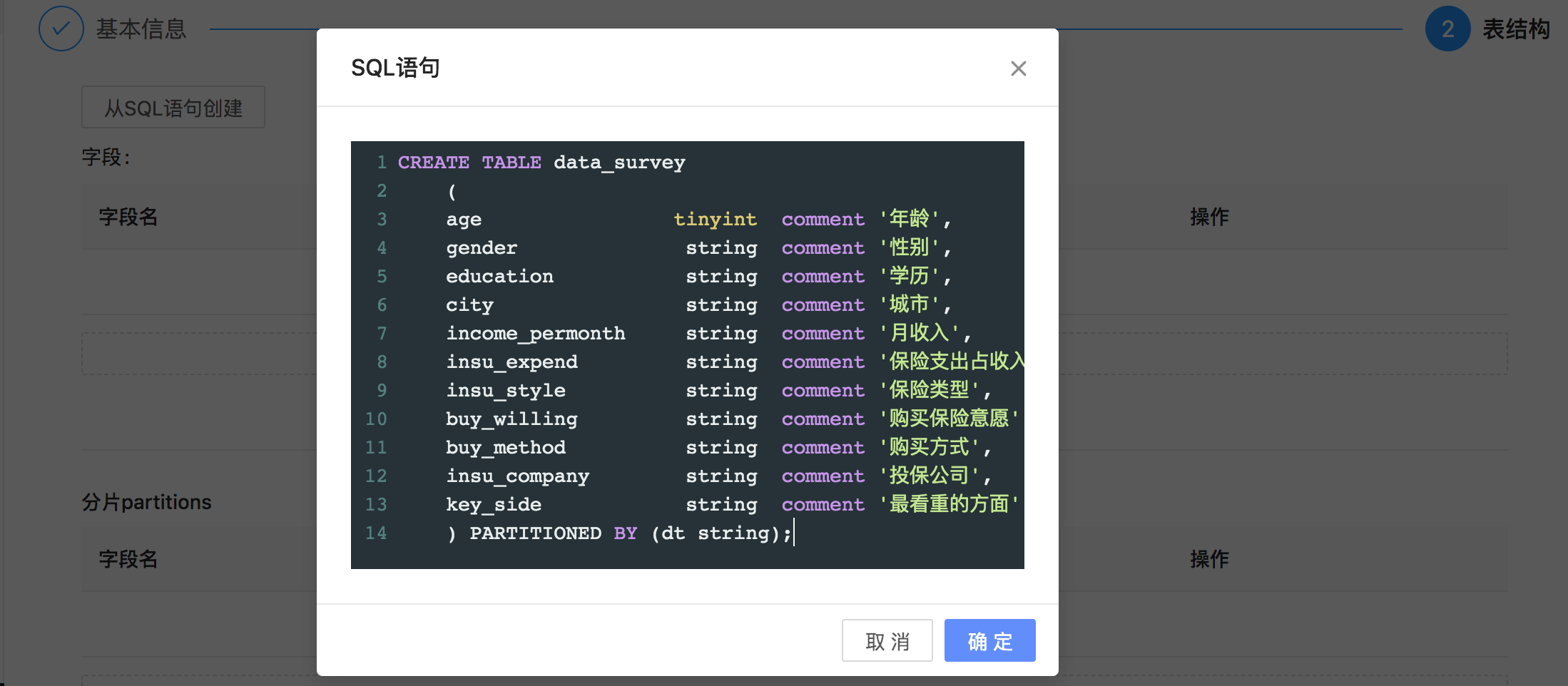
本示例建表语句如下 :
CREATE TABLE data_survey( age tinyint comment '年龄', gender string comment '性别', education string comment '学历', city string comment '城市', income_permonth string comment '月收入', insu_expend string comment '保险支出占收入', insu_style string comment '保险类型', buy_willing string comment '购买保险意愿', buy_method string comment '购买方式', insu_company string comment '投保公司', key_side string comment '最看重的方面' ) PARTITIONED BY (dt string);
-
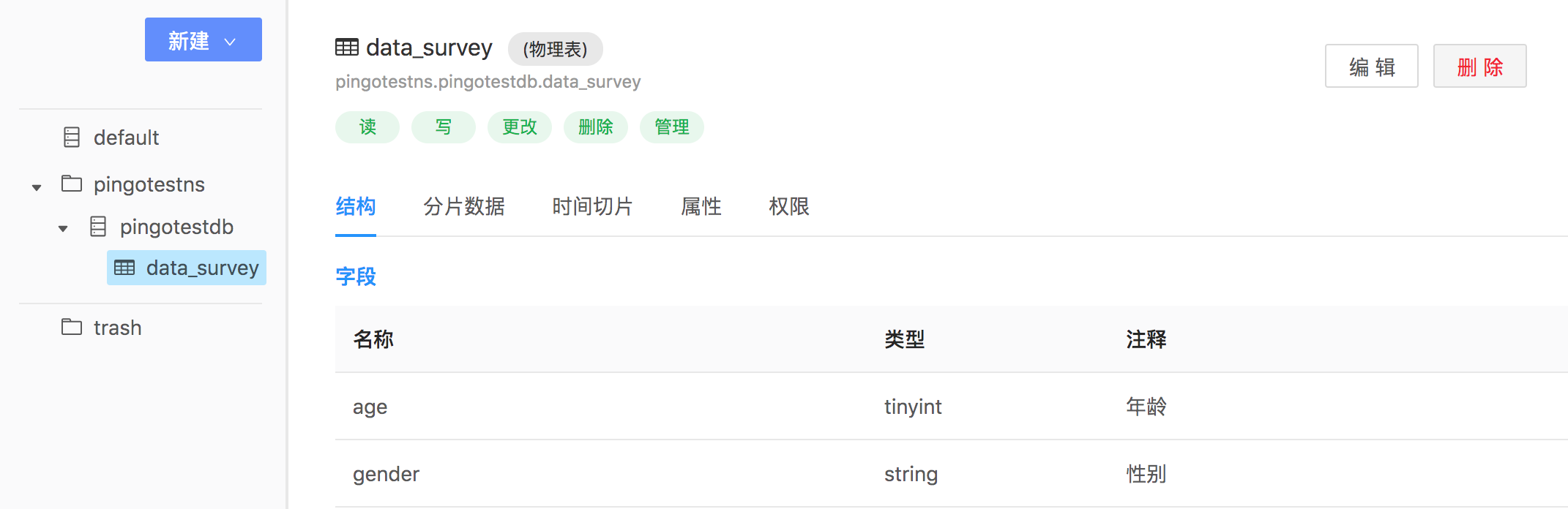
点击确定之后,可以在建表页面预览字段。确认无误之后,点击提交,建表完成。
创建表分区
-
打开作业管理-交互分析,新建一个Spark-SQL Notebook。
-
依次键入查询语句,可以查看到所创建的数据库及表。
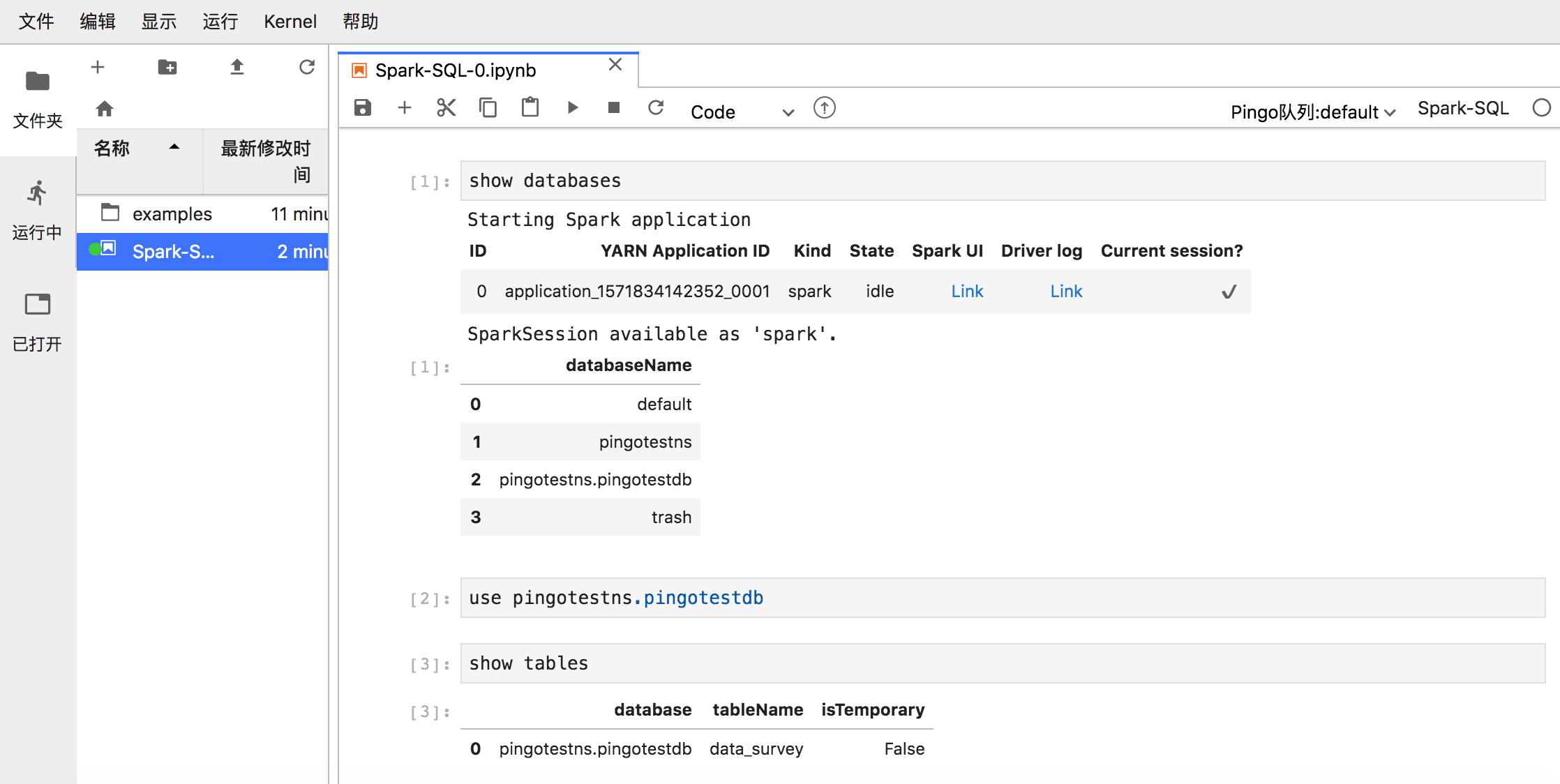
-
由于表创建了分区字段,数据需要在分区路径下,表和数据才可以自动关联。于是执行以下SQL语句,创建分区dt=20191020,无需指定分区路径,将会在表路径下自动创建分区。

上传数据文件
-
先进入表管理,选中表名,点击表数据的属性栏Location一栏进行查看,记住这个路径。
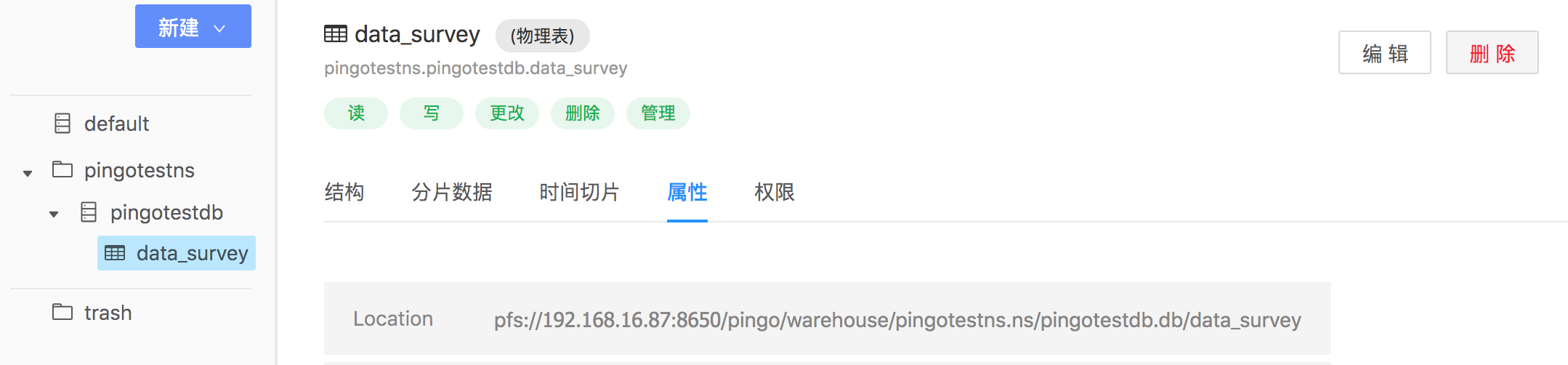
-
在表创建的时候,我们选择的表类型为物理表,物理表创建的时候,会在文件管理中的/pingo/warehouse自动创建该表的路径文件夹。

-
点击表名文件夹进入,可以看到,还有一个 dt=20191020文件夹,这是由我们创建的分区表生成的分区路径。
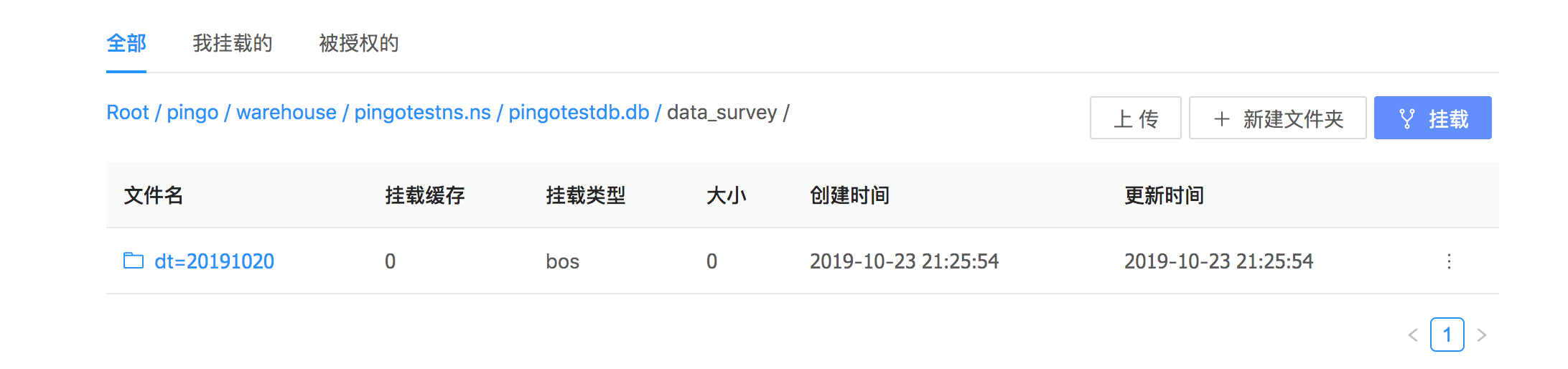
-
进入分区文件夹,在分区文件夹内点击上传按钮,将我们想要访问的文件数据进行上传。
本地文件上传有以下限制:
文件类型:支持.txt、.csv 格式
文件大小:不超过10M
文件名称不能包含特殊字符:比如空格, 问号
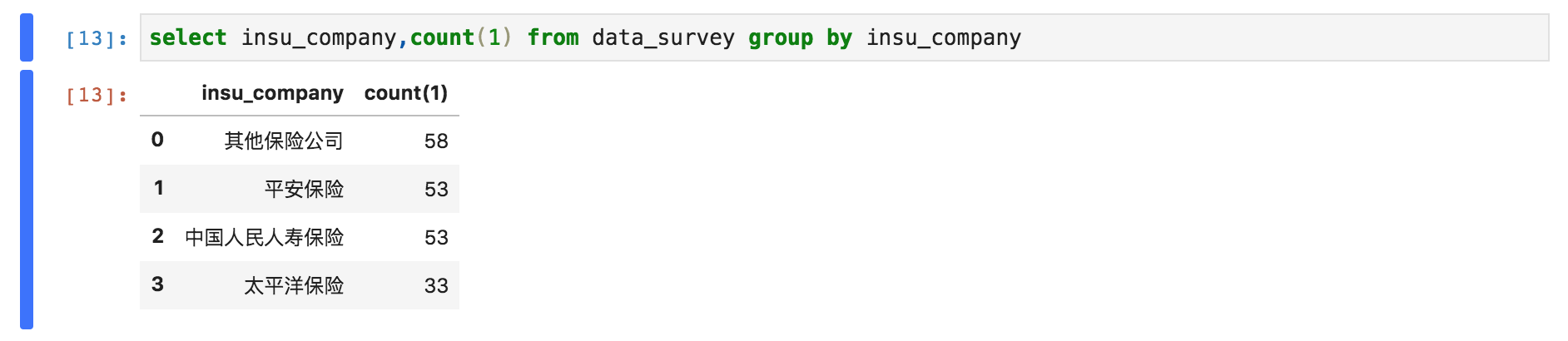
##执行SQL查询数据
-
回到交互分析,进入之前的Notebook,执行查询语句,可以看到表与我们上传的数据已经关联成功。

-
继续执行SQL查询语句,获取我们想要的查询结果。