本示例以读取一个BOS中的TXT文件为例,介绍创建Spark作业并执行的过程。
-
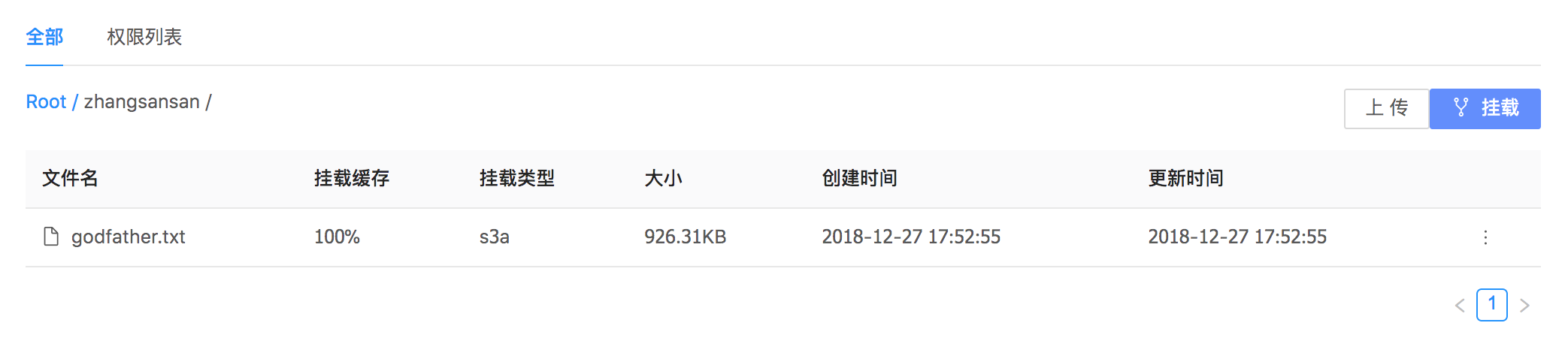
将BOS数据挂载到文件管理。
-
进入“批量作业>创建新作业”,选择创建Spark作业,语言类型选择Scala,您也可以根据自己的习惯选择自己熟悉的语言,目前支持SQL、Scala、Python。
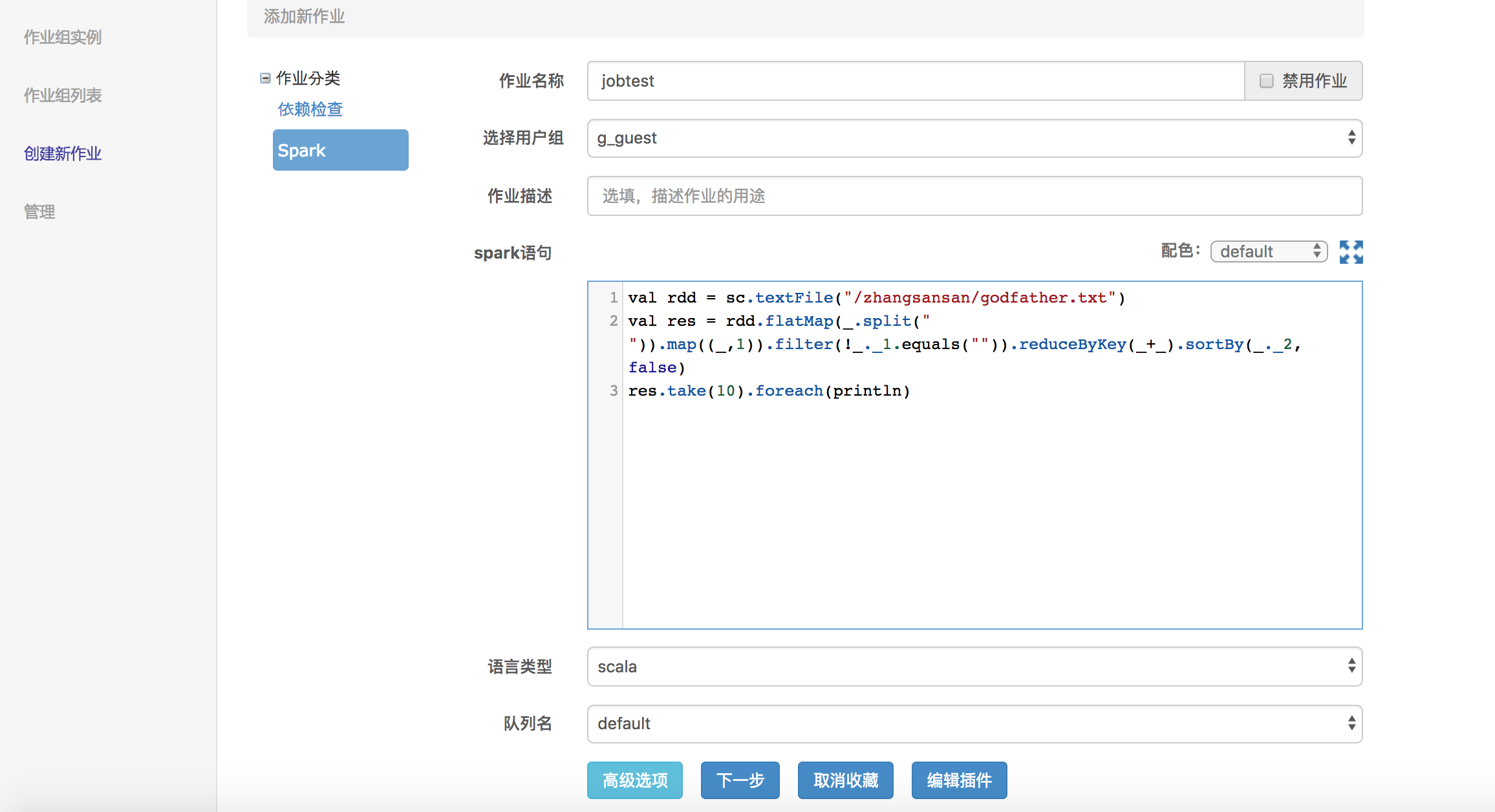
参考代码
val rdd = sc.textFile("/zhangsansan/godfather.txt") val res = rdd.flatMap(_.split(" ")).map((_,1)).filter(!_._1.equals("")).reduceByKey(_+_).sortBy(_._2, false) res.take(10).foreach(println) -
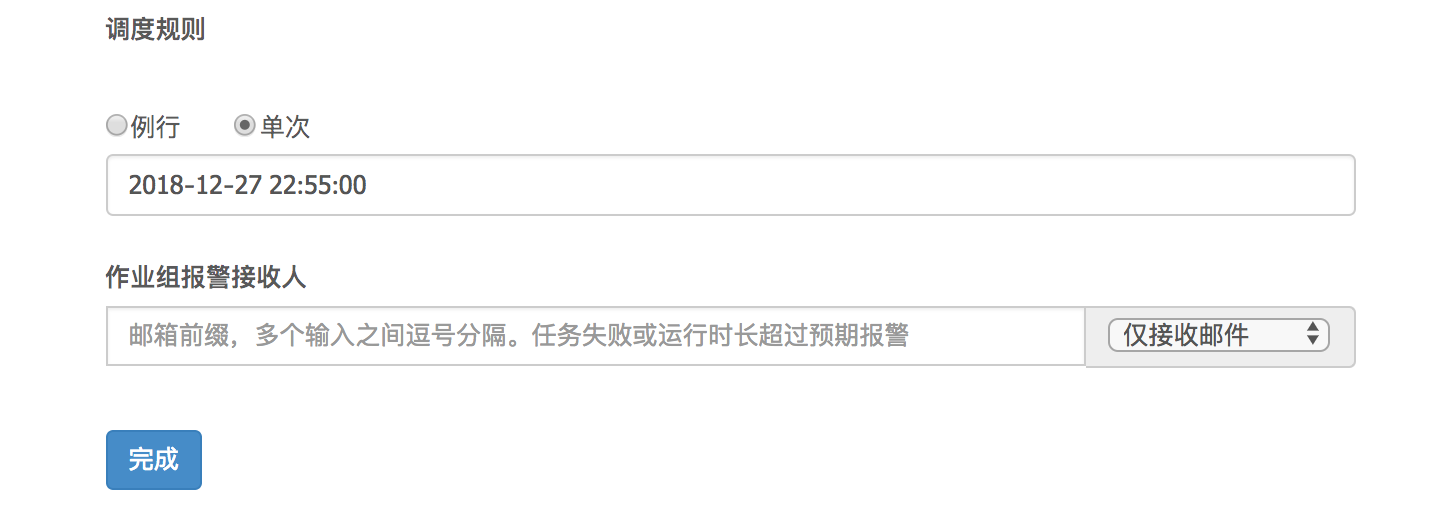
调度规则可以是例行或者单次,按使用需求设定。
-
设定完成之后,点击完成。此时作业在等待执行中,可以更改调度或进行其他设置。
-
待到达设定的执行时间,作业会启动执行,并生成一个作业实例。

-
点击查看可以查看执行状态和日志信息。