

文档简介:



本例子通过分析Nginx访问日志,完成使用Pingo进行离线大数据处理典型场景的演示。
概览
一条Nginx日志大约长这样:
192.168.1.123 - - [21/Apr/2019:20:53:09 +0800] "POST /pingo/sql/getQueryHistoryByIds HTTP/1.1" 200 1829 "http://bigdata.baidu.com/pingo/?eqt=qh&qiid=19807852&tab=u&ut=eq" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
这个默认格式的日志有10个字段,并且格式是固定的。假如说我们已经将这样的日志文件转成了一个表nginx_log
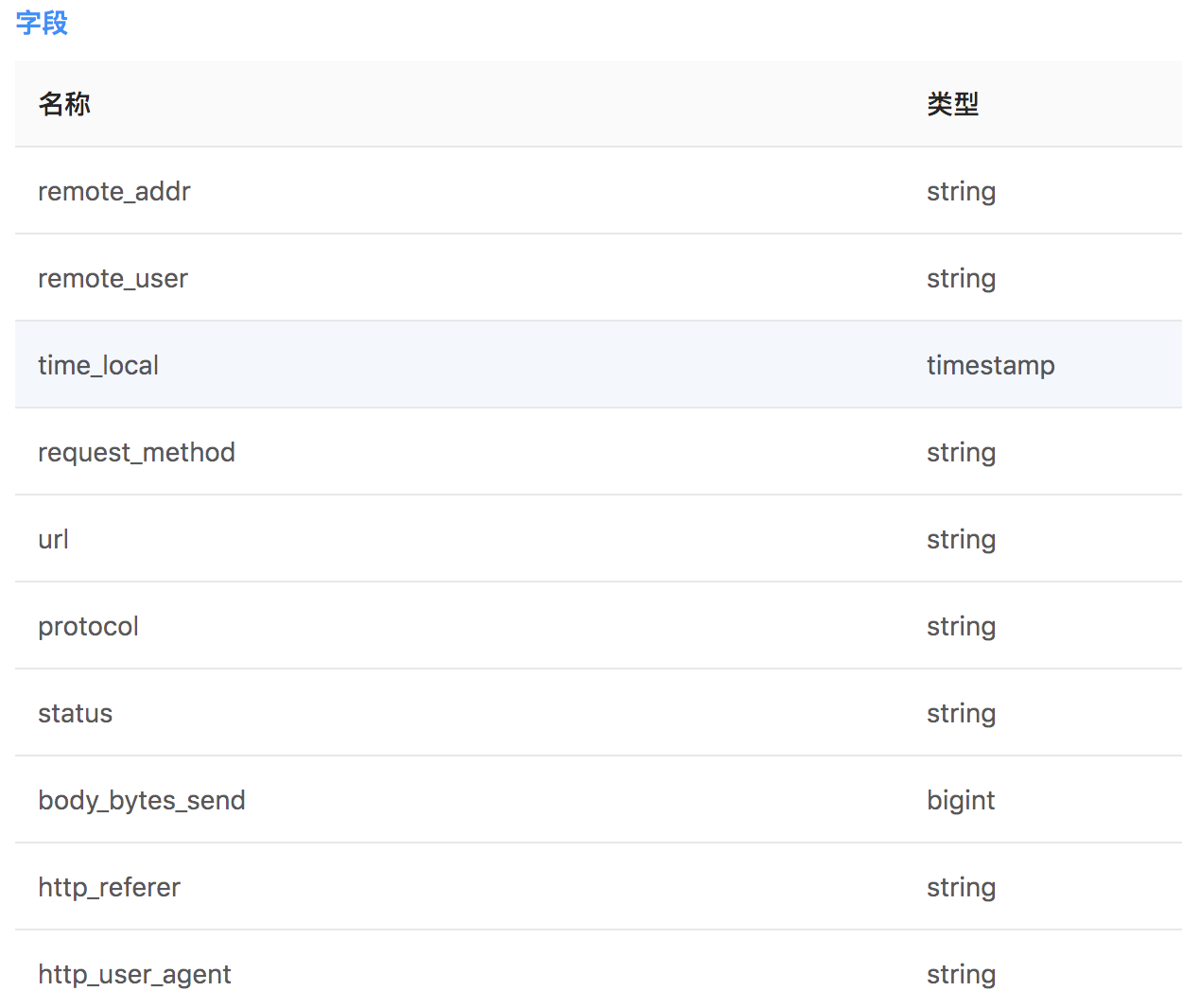
那么我们就可以对这个表进行分析。本例中我们分析来自不同ip的请求数,那么可以写成如下语句
select remote_addr, count(1) as num from nginx_log where day = "20190421" group by remote_addr order by num desc
下面就一步步讲解如何从原始日志生成这个表。以及如何对这个表进行例行查询。
建表
首先我们需要在default数据库中新建nginx_log表。建表有两种方法,
- 第一种方法为在表管理中通过界面方式建表。在"操作指南"中有详细介绍。
- 另一种方法为直接执行SQL建表语句。首先需要新建一个SQL类型的note
然后运行如下建表语句
create table nginx_log ( remote_addr string, remote_user string, time_local timestamp,
request_method string, url string, protocol string, status string, body_bytes_send long, http_referer s
tring, http_user_agent string) partitioned by (day string)
- 这里建表之后需要编辑并配置分片周期,如下图所示
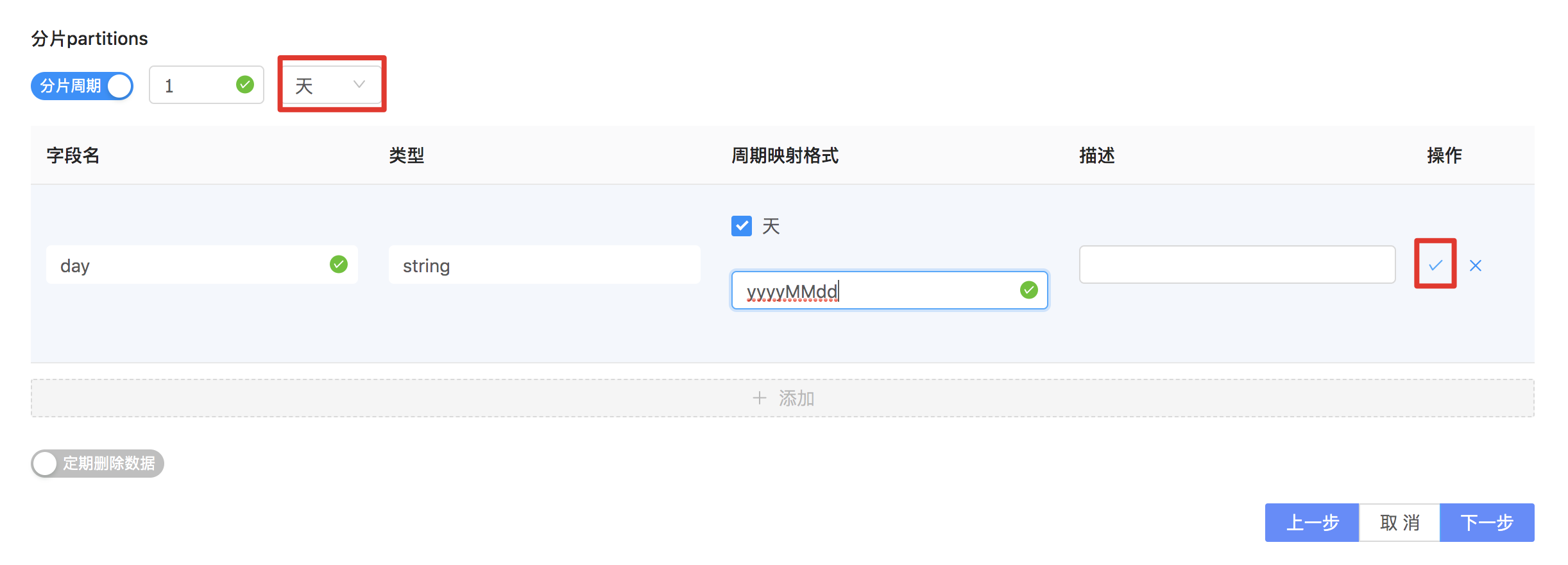
在后面讲到例行SQL语句时会用到该配置。
数据导入
这里以Scala语言为例讲解如何通过分析文本日志生成结构化表里的数据。下面的代码都要在Pingo的交互分析中执行,先按照下图新建一个Spark类型的note。
然后入下图在cell编辑框内输入Scala代码,并执行
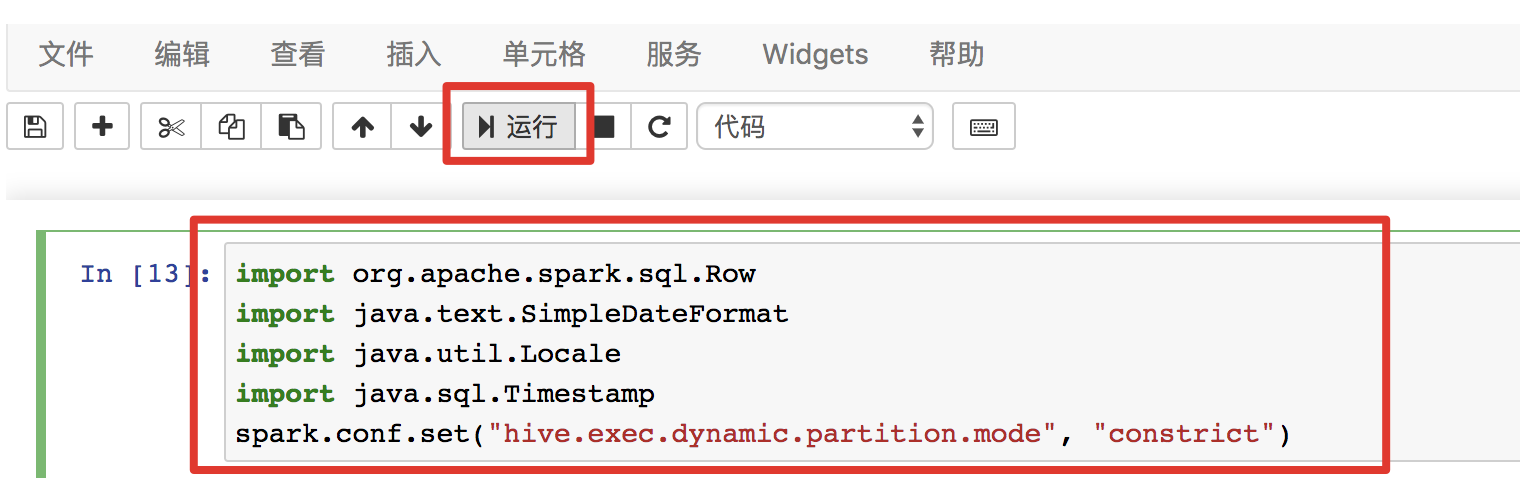
第一步我们需要import用到的类,并且开启hive的dynamic partition模式。对应的代码如下
import org.apache.spark.sql.Row
import java.text.SimpleDateFormat
import java.util.Locale
import java.sql.Timestamp
spark.conf.set("hive.exec.dynamic.partition.mode", "constrict")
接下来我们需要使用Nginx日志文件创建一个RDD
val logRdd = sc.textFile("/tmp/nginx-access.log")
这里的路径可以是Pingo文件系统中的一个路径,也可以是一个hdfs路径(如果您已经在自己的hdfs中上传了日志文件的话)。如果您还没有这样的日志文件,概览中给出的那行日志保存为nginx-access.log文件,并通过Pingo的"文件管理"上传到/tmp目录即可。
然后我们要创建一个正则表达式来匹配日志中的各个字段。并且新建一个DateFormat来分析时间字段。这个正则表达式和前面的nginx_log表的字段是一一对应的。
val pattern = """(\S+) - (\S+) \[([\w:/]+\s[+\-]\d{4})\] "(\S+) (\S+) (\S+)" (\d{3}) (\S+) "(\S+)" "([^"]*)"""".r
val dateFormat = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss Z", Locale.ENGLISH)
下面通过解析每一行原始日志,生成一个元素类型为Row的RDD
val rdd = logRdd.map{line =>
val regRes = pattern.findFirstMatchIn(line)
if (regRes.isEmpty) {
Row()
} else {
Row(regRes.get.group(1),
regRes.get.group(2),
new Timestamp(dateFormat.parse(regRes.get.group(3)).getTime),
regRes.get.group(4),
regRes.get.group(5),
regRes.get.group(6),
regRes.get.group(7),
regRes.get.group(8).toLong,
regRes.get.group(9),
regRes.get.group(10),
"20190421")
}
}.filter(row => row.size > 0)
通过关联前面创建的nginx_log表的schema,生成一个Dataframe,并且将Dataframe的数据写入到nginx_log表里即可。
val df = spark.createDataFrame(rdd, spark.table("default.nginx_log").schema)
df.write.insertInto("default.nginx_log")
这里将数据写入nginx_log表中以后,就可以通过SQL语句进行查询了。
例行SQL查询
前面讲到的SQL或者Scala代码,都是运行在交互分析里的。其实这是符合大数据开发的典型场景的,我们一开始只是有个大体的方案甚至只是一个简单的想法,需要在一个交互式分析环境中不断修改、验证我们的想法。前面查询不同ip请求数量的SQL例子比较短,但是生产环境中的SQL动辄上百行甚至上千行,必须有一个交互式环境不断调试才能完成。
而上面查询不同ip请求量的例子是按天执行的,这是符合实际场景的。因为每天都有新的日志产生,那么每天都有需求来查看这个SQL的执行结果,所以我们需要让这个SQL语句例行起来。
Pingo为此场景提供了非常简单的支持。如下图,选择调试完成的note,点击例行就可以在批量作业中生成一个例行任务。
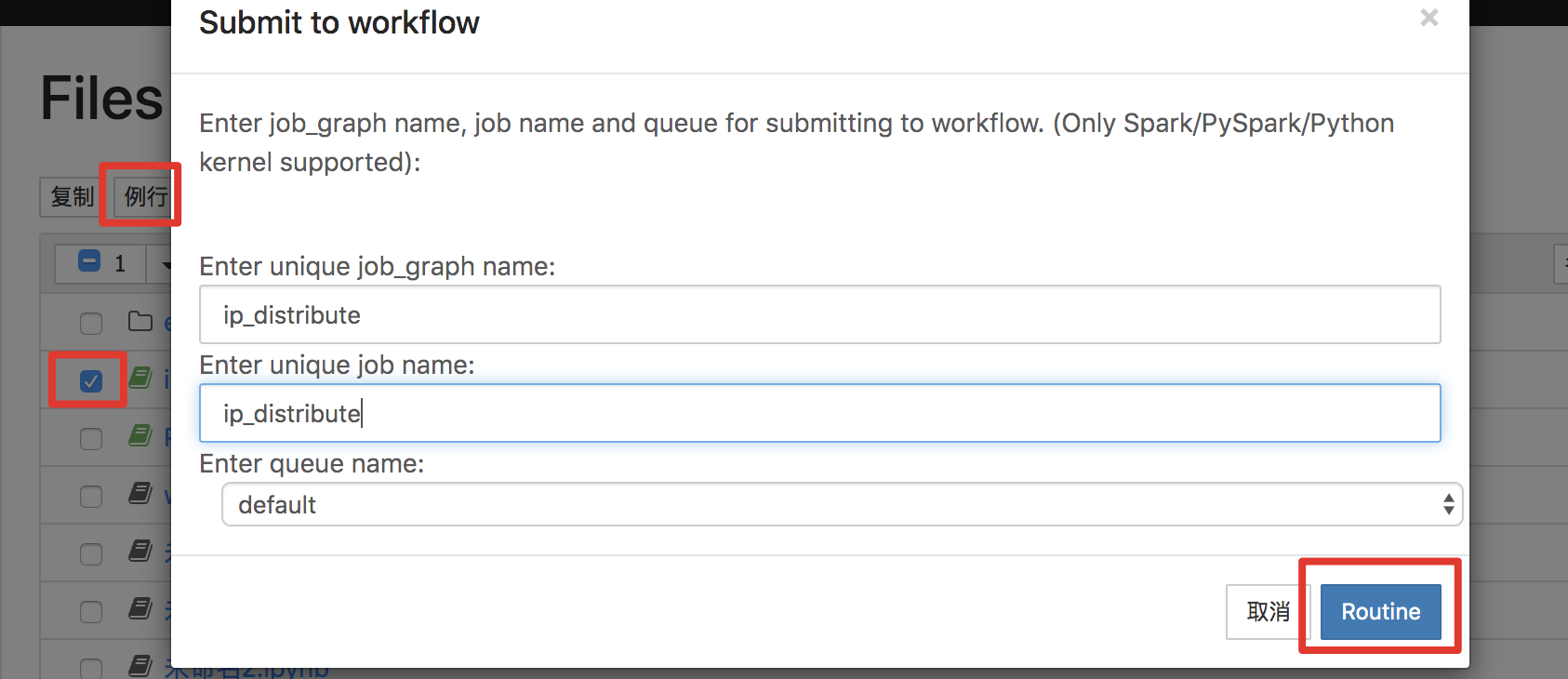
在批量作业中编辑新生成的ip_distribute作业
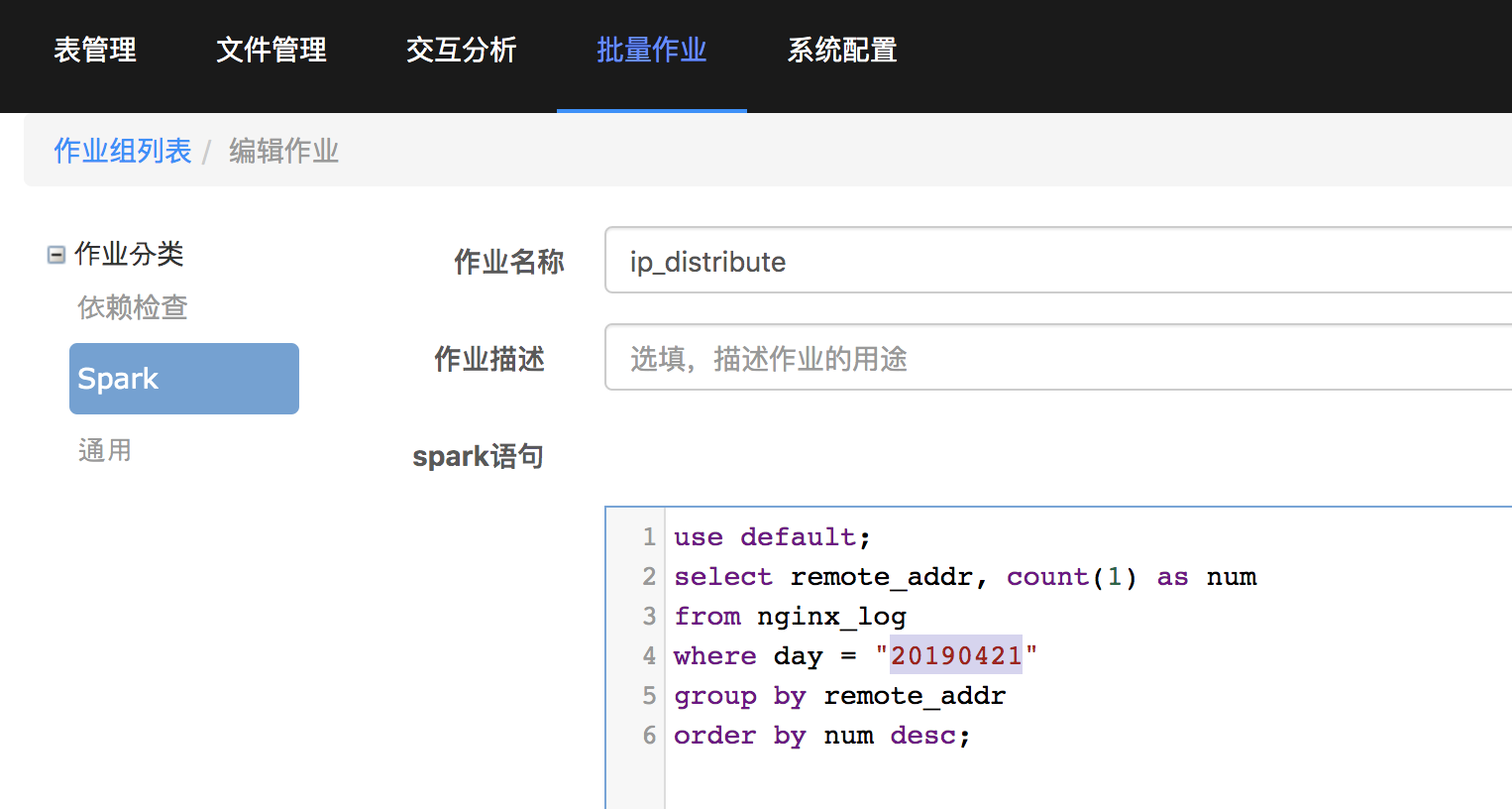
可以看到这里的day的判断条件是写死的,这里要将20190412改为宏{DATE},操作指南里有批量作业支持的所有宏的介绍。
编辑ip_distribute作业组,点击"更改调度",可以看到该作业组将在每天的零点跑前一天的数据(关于基准时间请参考操作指南),也就是4.23零点启动的任务,{DATE}将被修改为20190422。
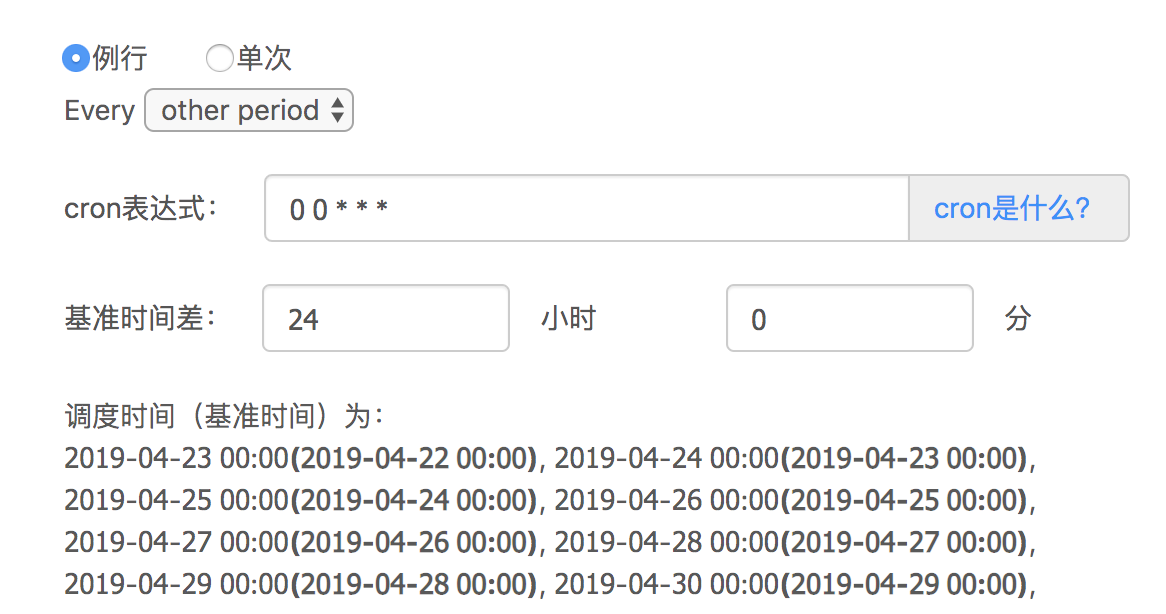
这里有个问题,就是4.23零点无法准时生成4.22一整天的全量数据。并且无法给出任务任务应该启动的确切时间。这里Pingo给出的解决方案是依赖检查作业。在ip_distribute的编辑页面点击"添加依赖作业",如下图所示
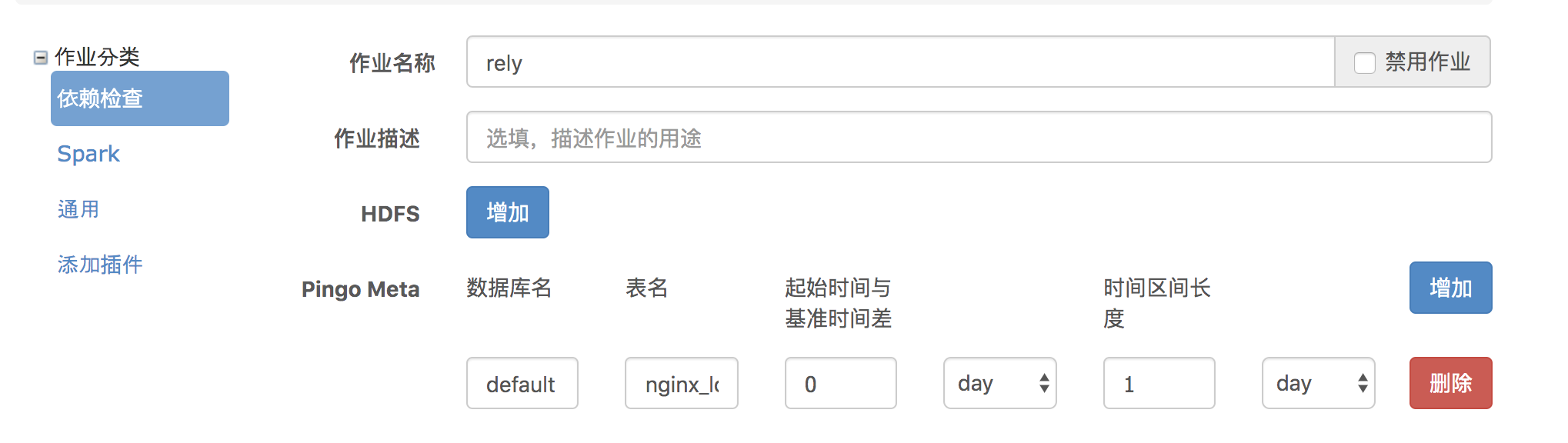
依赖作业添加之后,如下图所示配置作业的依赖关系。这样在rely任务执行成功之后才会启动ip_distribute任务。
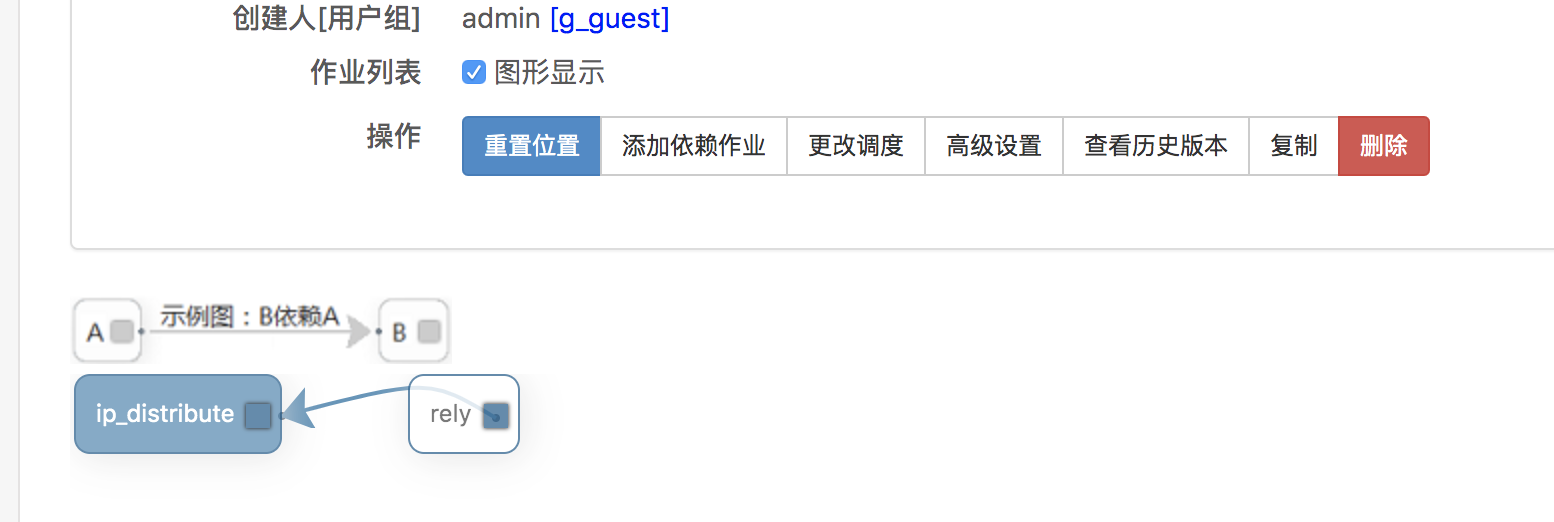
到这里一个完整的例行任务就配置完成了。
分片周期
回顾建表部分,讲到了需要配置分片周期,所谓周期,必然是数据周期性生成的表才需要配置,如果数据不是周期性的,那就干脆不需要这个配置。
它的作用主要是在对表数据进行依赖检查使用的。如前所述,4.23零点启动的任务,要检查4.22一整天的数据是否已经全部就绪。比较直观的想法是直接检查day=20190422这个数据分片是否生成即可。
这里的一个问题是,表是用户建的,可能会有多个分片字段,Pingo无法知道到底哪个分片字段是天级别分片字段。在知道天级别分片字段是那个以后,还有一个问题是时间格式也是可变的,比如可以写成20190422,也可以写成4.22-2019等。所以这个配置相当于告诉Pingo周期性的分片字段到底是哪个,时间格式到底是什么。
进一步,对周期为天级的数据,可能有月级的例行任务,甚至小时级的数据也有月级的例行任务。并且可能有天级分片和非周期(比如province)分片并存的情况。如果依赖检查只检查分片,那么是不可行的。所以Pingo引入了时间切片的概念
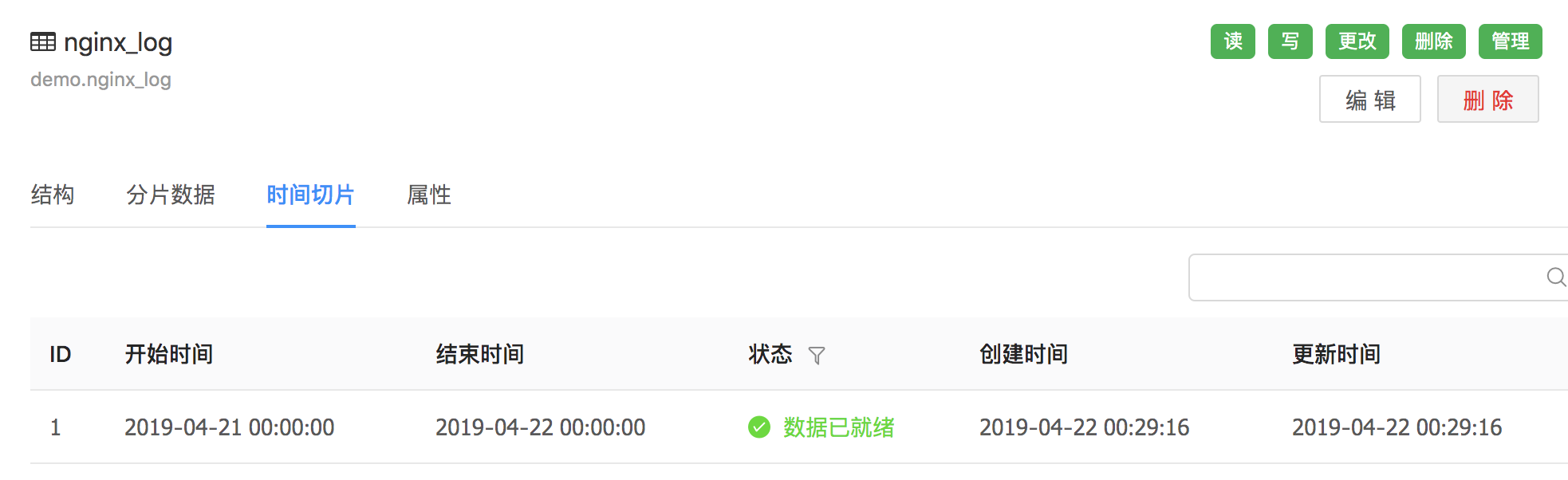
可以认为就是一个时间区间,如果这个时间切片存在,就认为这个时间区间的数据已经全部就绪。比如day=20190421的分片生成以后,Pingo就会自动生成一个区间为2019.4.21零点到2019.4.22零点的时间切片。依赖检查任务检查的其实是时间切片。
查询原始日志
前面讲的是将原始日志导入到Pingo表中,对表进行查询的方案。细心的用户可能会发现,原始日志到表就需要跑一遍Spark任务,如果只想对原始数据做一次调研性的查询,根本没有理性的需求的话,这样就太麻烦了。Spark的API是支持直接查询原始日志的。接着数据导入的例子,需要先定义一个类用来映射日志结构
case class NginxLog(ip: String, user: String, time_local: java.sql.Timestamp, method:
String, url: String, protocol: String, satus: String, bytes: Long, referer: String, user_agent: String)
然后参照前面的例子生成一个Dataframe
val logDF = logRdd.map{line => val regRes = pattern.findFirstMatchIn(line)
if (!regRes.isEmpty) { NginxLog(regRes.get.group(1), regRes.get.group(2),
new Timestamp(dateFormat.parse(regRes.get.group(3)).getTime), regRes.get.group(4),
regRes.get.group(5), regRes.get.group(6), regRes.get.group(7), regRes.get.group(8).
toLong, regRes.get.group(9), regRes.get.group(10)) } }.filter(row => row.isInstanceOf
[NginxLog]).map(row => row.asInstanceOf[NginxLog]).toDF
然后就可以直接对该Dataframe进行查询了
logDF.groupBy("ip").count().orderBy(desc("count")).limit(10).show()
