文档简介:



对于基于Spark API编写的复杂Scala/Java/Python项目,可以将源代码打包然后直接在Pingo中调用。下面首先以Maven管理的Scala项目为例讲解。
初始化Maven项目
可以使用如下Maven命令初始化一个项目(第一次执行可能由于下载组件很多导致运行较长时间)
mvn archetype:generate -DgroupId=com.myapp -DartifactId=spark-jar-example -DarchetypeGroupId=net.alchim31.maven -DarchetypeArtifactId=scala-archetype-simple -DinteractiveMode=false
然后进入spark-jar-example目录,编辑pom.xml文件,将scala.version的值修改为2.11.8,将scala.compat.version的值修改为2.11。并且新增如下依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.2</version>
<scope>provided</scope>
</dependency>
调用Spark API
本例将实现这样的两个方法。
- copyTables:将一个数据库中的表结构复制到另一个数据库中;
- dropTables:将指定数据库中的表名符合指定命名规则的表删掉。
编辑App.scala文件,首先导入Spark相关依赖import org.apache.spark.sql.SparkSession。然后在App类中新增如下两个方法。
def dropTables(spark: SparkSession, dbName: String, tableLike: String): Unit = {
val tables = spark.sql("show tables in " + dbName).collect()
for (tableItem <- tables) {
val tableName = tableItem.get(1) + ""
if (tableName contains tableLike) {
spark.sql(s"drop table $dbName.$tableName")
}
}
}
def copyTables(spark: SparkSession, fromDB: String, toDB: String): Unit = {
val tables = spark.sql("show tables in " + fromDB).collect()
for (tableItem <- tables) {
val tableName = tableItem.get(1)
spark.sql(s"create table $toDB.$tableName like $fromDB.$tableName")
}
}
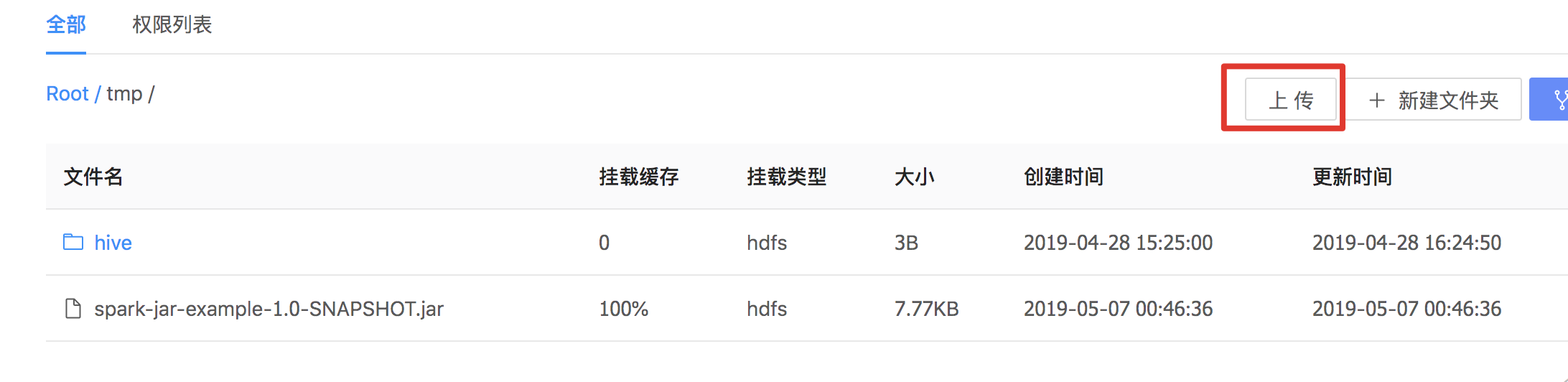
生成并上传jar
使用mvn package命令将代码编译成jar包,然后将文件上传到PFS中/tmp目录。
调用jar包中方法
先进入表管理界面新建一个名为test的数据库。
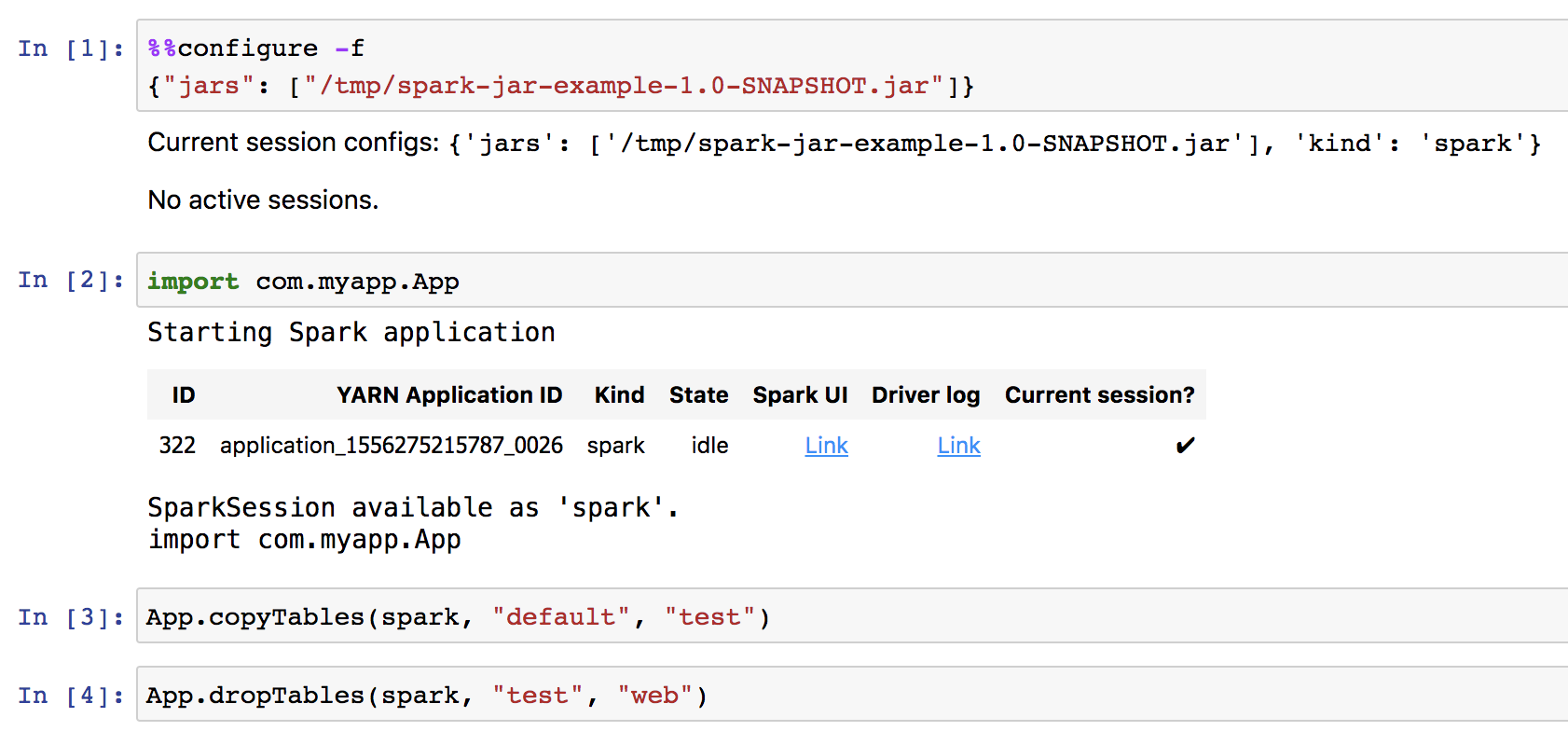
以交互分析为例,新建Scala类型的Note,然后先执行如下配置
%%configure -f
{"jars": ["/tmp/spark-jar-example-1.0-SNAPSHOT.jar"]}
接下来就可以调用jar包中方法了。
import com.myapp.App
App.copyTables(spark, "default", "test")
App.dropTables(spark, "test", "tbl")
例行调度jar包
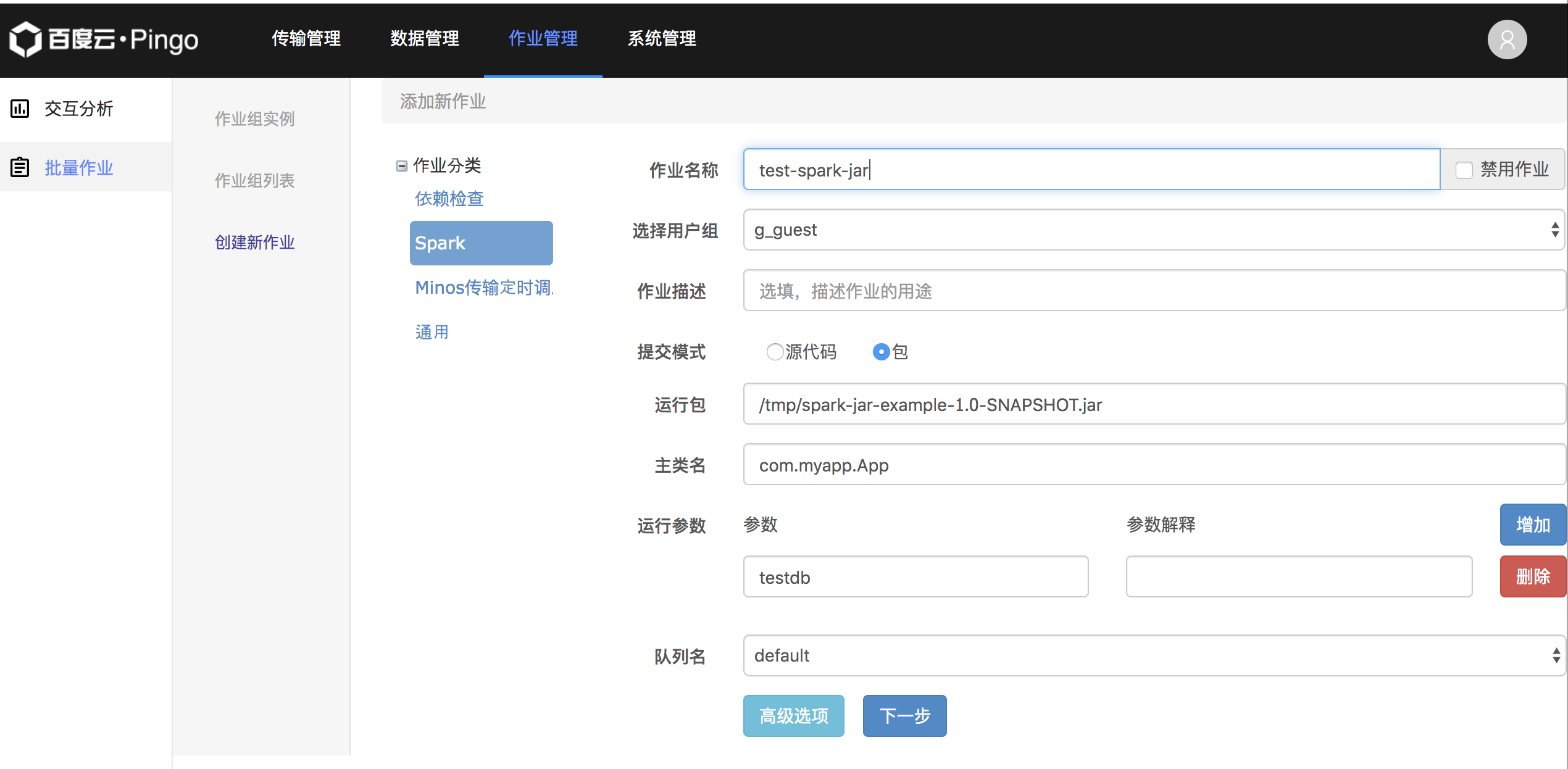
首先将前述App类中的main方法修改为如下内容
val spark = SparkSession .builder .appName("Spark Jar Example") .enableHiveSupport() .getOrCreate() dropTables(spark, args(0), "")
编译打包并上传jar到PFS中/tmp目录。然后使用如下参数创建一个Spark例行任务即可。
调用Python代码
和调用jar包代码类似,新建如下Python文件example.py
!/usr/bin/env python -*- coding: utf-8 -*- """ @brief The pyspark example of copying tables and drop tables """ class PingoExampleApp(object): def __init__(self, sparkSession): self._spark
= sparkSession def dropTables(self, dbName, tableLike): tables = self._spark.sql("show
tables in " + dbName).collect() for item in tables: if tableLike in item.tableName: self.
_spark.sql("drop table %s.%s" % (dbName, item.tableName)) def copyTables(self, fromDB,
toDB): tables = self._spark.sql("show tables in " + fromDB).collect() for item in tables
: self._spark.sql("create table %s.%s like %s.%s" % (toDB, item.tableName, fromDB, item.tableName))
然后压缩成zip文件:zip pyspark-example.zip example.py,并且将该文件上传到PFS的tmp目录。然后在交互分析中新建Python类型的Note,先执行如下配置
%%configure -f
{"pyFiles": ["/tmp/pyspark-example.zip"]}
然后就可以使用如下方法调用Python代码了
from example import PingoExampleApp
app = PingoExampleApp(spark) app.copyTables('default', 'test') app.dropTables('test', '')
执行过程截图如下。
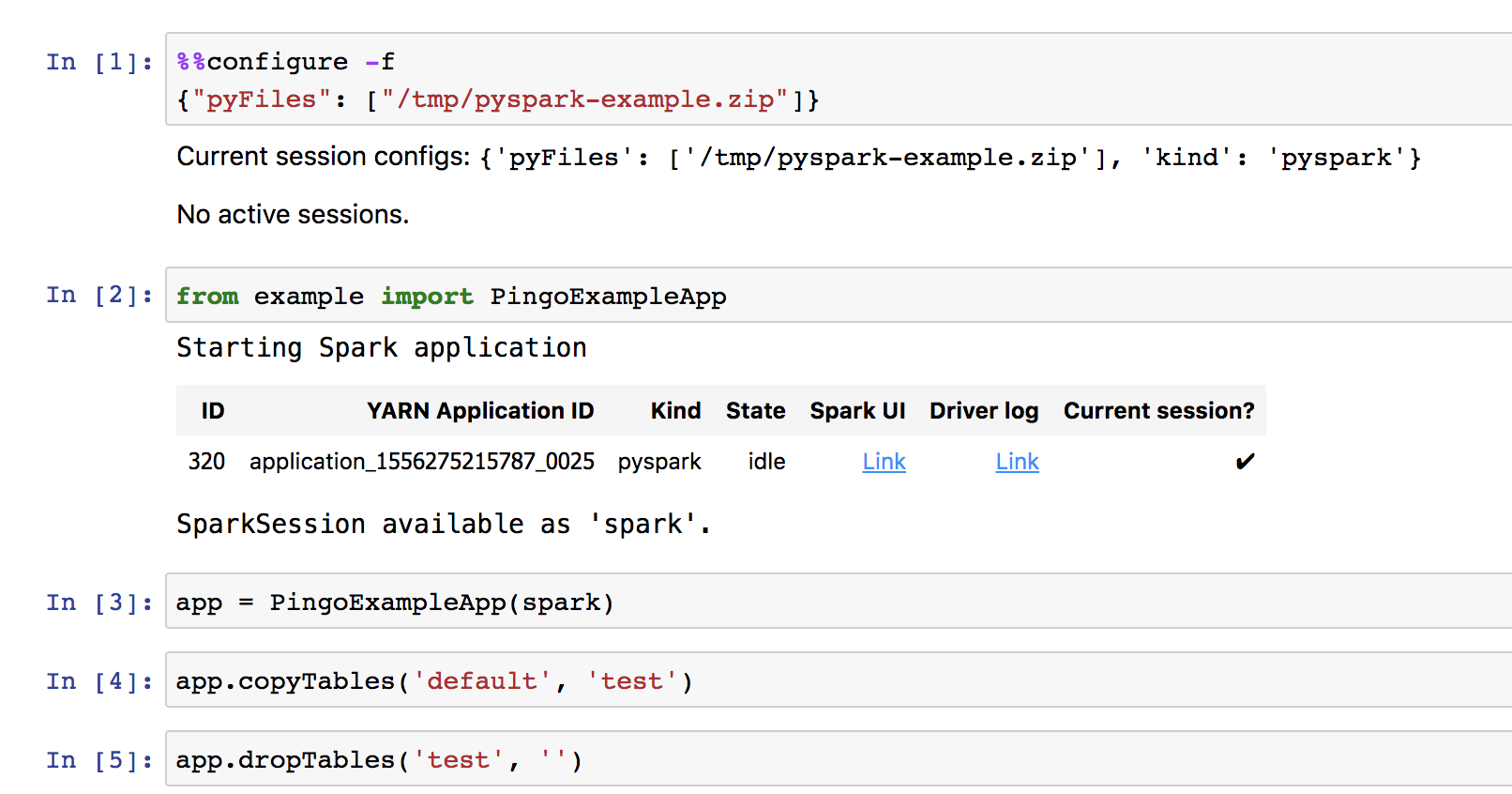
对于单个Python文件,不用zip压缩直接上传也可以。这里主要为了展示多个Python文件的情况可以压缩成一个zip包一起上传使用。
例行调度Python代码
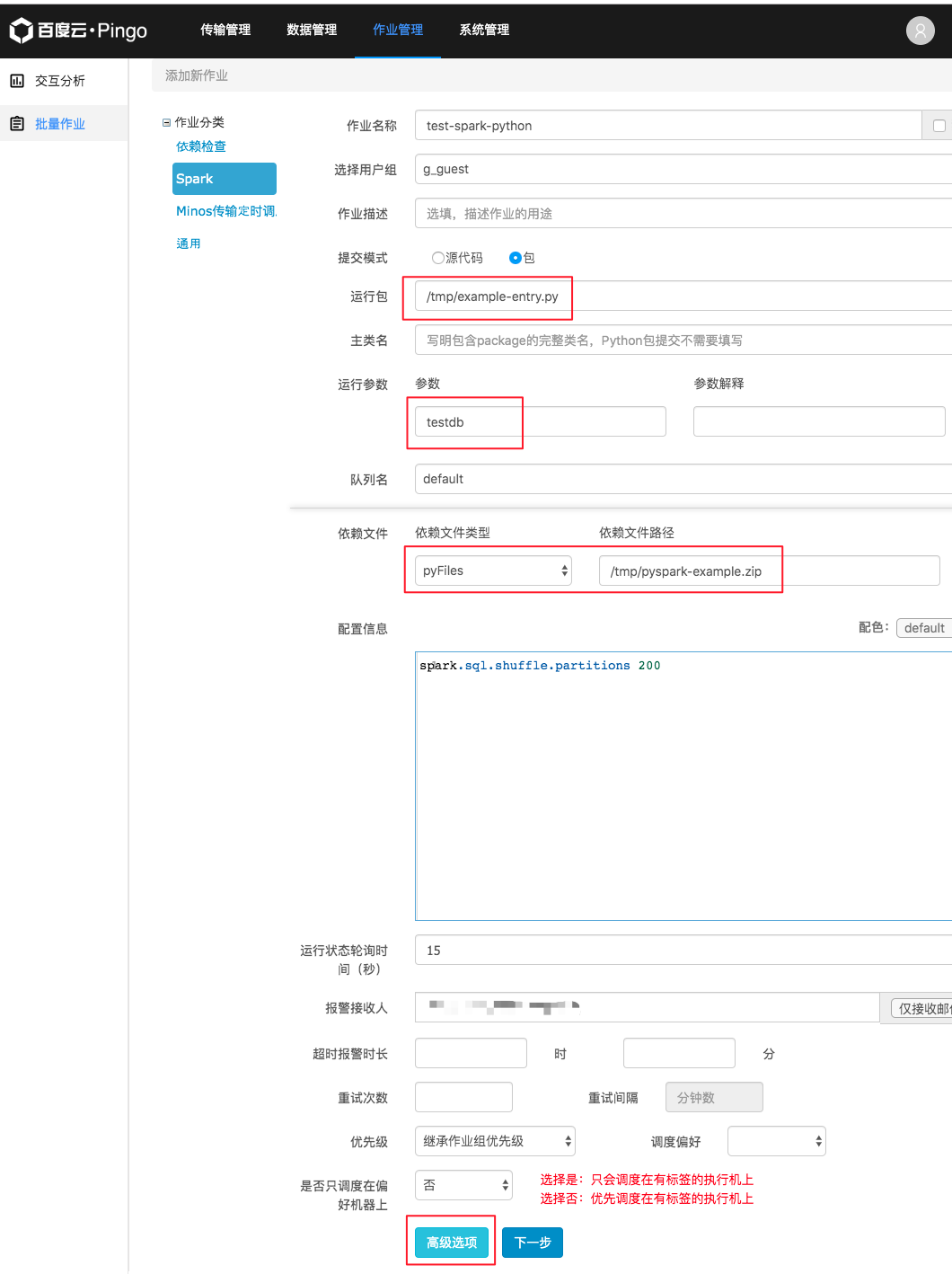
将如下Python代码保存成文件example-entry.py并上传到PFS的/tmp目录。
!/usr/bin/env python
-*- coding: utf-8 -*-
import sys
from example import PingoExampleApp
from pyspark.sql import SparkSession
"""
@brief The pyspark example entry
"""
if __name__ == "__main__":
"""
Usage: pi [partitions]
"""
spark = SparkSession.builder.enableHiveSupport().appName("PyPackage Example").getOrCreate()
app = PingoExampleApp(spark)
app.dropTables(sys.argv[1], "")
然后使用如下参数创建一个Spark例行任务即可。可以看到使用了上面的pyspark-example.zip文件。