




功能简介
智能边缘BIE支持了多种边缘AI加速卡显存使用情况指标采集。针对当前未支持的AI加速卡种类,BIE提供了自定义AI加速卡算力采集的功能。
本教程提供了自定义监控应用的开发与部署规范,您可以根据文档规范,开发自定义AI加速卡算力采集应用,并将指标采集集成到BIE的指标采集系统中,在云端对AI算力进行监控。
自定义监控应用开发规范
用户可自行开发指标采集部分。完成指标采集后,需要将数据以指定的数据格式暴露在如下API。baetyl-core会从该api中拉去数据,并同步至云端。
api说明
| 方法 | api | 说明 |
|---|---|---|
| GET | /v1/collect | 暴露指标数据的api |
数据格式要求
// 采集pod 返回指标结构,nodeName可以通过环境变量KUBE_NODE_NAME获取
map[nodeName]interface{}{}
// 每个节点的指标结构
type GpuInfo struct {
DeviceNum uint `json:"deviceNum"`
Devices []DeviceInfo `json:"devices"`
UsedMemory uint64 `json:"usedMemory"` // 加速卡的显存使用量,若存在多卡,则需要累加
TotalMemory uint64 `json:"totalMemory"` // 加速卡的显存总量,若存在多卡,则需要累加
Percent float64 `json:"percent"` // 加速卡的显存使用率,若存在多卡,累加后计算
}
// 每个加速卡子卡的信息,目前只包括支持的加速卡类型指标,其中UsedMemory TotalMemory Percent为单卡的显存使用指标,为通用指标
type DeviceInfo struct {
UsedMemory uint64 `json:"usedMemory"`
TotalMemory uint64 `json:"totalMemory"`
Percent float64 `json:"percent"`
}
部署要求
负载参数要求
| 参数 | 规范要求 | 说明 |
|---|---|---|
| 负载类型 | Deployment/DaemonSet | 负载类型取决于用户边缘节点的类型是单机或集群,并且集群哪些节点存在加速卡 |
| 命名空间 | baetyl-edge-system | 边缘服务的系统应用命名空间,必须在该命名空间下创建应用 |
| 标签 | baetyl-service-name: baetyl-accelerator-metrics | 用于服务发现的系统标签,必须携带 |
| 环境变量 | KUBE_NODE_NAME:spec.nodeName | 用于组织最终指标数据的map key,即当前节点名 |
注意:由于监控应用必须得部署在baetyl-edge-system的命名空间下,因此当前不支持直接从BIE云端下发该应用。需要在边缘以kubectl apply的方式手动进行运行。
DemoApp示例
该demoapp仅返回固定指标,并未真实采集算力信息。
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-app
namespace: baetyl-edge-system # 命名空间
labels:
app: test-app
spec:
replicas: 1
selector:
matchLabels:
app: test-app
baetyl-service-name: baetyl-accelerator-metrics
template:
metadata:
labels:
app: test-app
baetyl-service-name: baetyl-accelerator-metrics # 标签,必带
spec:
containers:
- name: test-app
image: baetyltechtest/baetyl-metrics-test:v1.0 # demo app,打桩返回固定指标
env:
- name: KUBE_NODE_NAME # 环境变量,必带
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName # k8s节点名
demo app固定返回指标:
{
"docker-desktop": { # node name
"deviceNum": 2,
"devices": [
{
"percent": 0.1,
"totalMemory": 1000,
"usedMemory": 100
},
{
"percent": 0.1008991008991009,
"totalMemory": 1001,
"usedMemory": 101
}
],
"percent": 0.10044977511244378,
"totalMemory": 2001,
"usedMemory": 201
}
}
三、使用示例
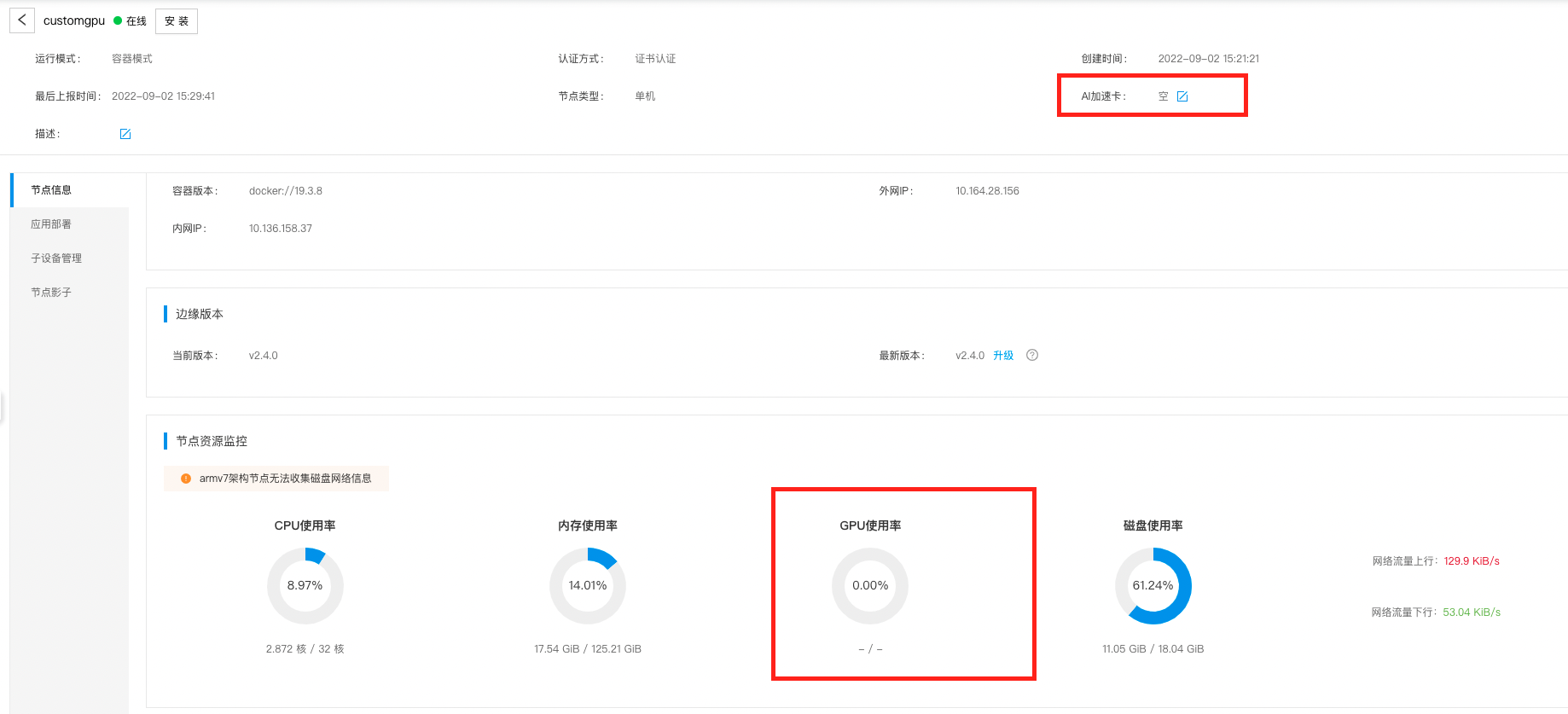
- 用户创建节点,由于加速卡是未支持类型,因此AI加速卡选择 ‘空’。可以看到当前GPU利用率为0.
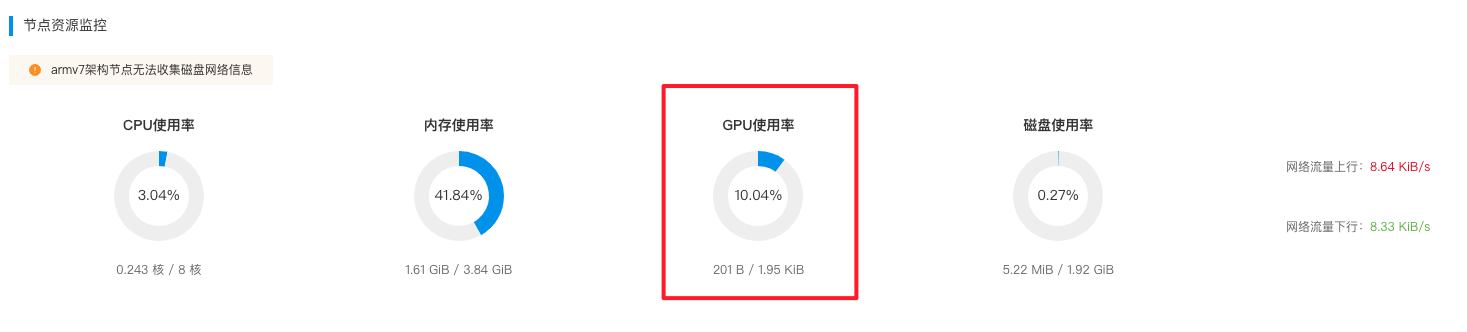
- 部署自定义采集应用,test-app即为用户的自定义加速卡采集应用示例。如demo所示,安装后效果如下:

-
按照指定规范采集指标后,可在云端“节点资源监控->GPU利用率”的位置查看加速卡的使用信息。由用户开发的自定义算力监控应用收集到的信息,会在GPU利用率这个饼图展示。
注意:自定义监控应用和系统应用baetyl-accelerator-metrics不支持同时下发。
