

文档简介:



Druid简介
Druid是一个高性能的实时数据分析系统,由MetaMarkets公司在2012开源,专门为OLAP场景而设计。Druid遵从Lambda架构,支持批量和实时两种方式导入数据,并提供高性能的数据查询。
集群准备
Druid模版
登录百度云控制台,选择“产品服务->百度MapReduce BMR”,点击“创建集群”,进入集群创建页。购置集群时选择Druid模版即可,另外Druid的元数据存储支持本地MySQL和云数据库RDS MySQL。如下图所示:
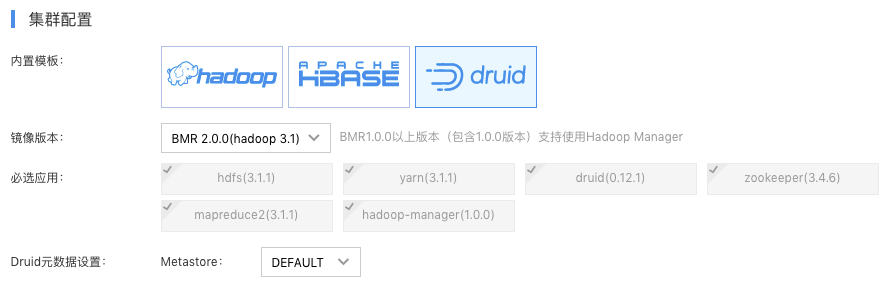
节点类型

BMR的Master节点上部署Druid的Overlord、Coordinator、Broker和Router,供提交任务、查看数据源和数据查询。


为了更容易扩展节点,BMR的Core节点部署Druid的Historical和MiddleManager, Task节点部署Druid的Broker和MiddleManager。可以按照需求变更Core和Task的节点数目。
Druid对内存的要求较高,建议使用4核16GB(或更高配置)的节点配置。在Druid集群内部,建议不要使用MapReduce跑其他开源组件的作业。
使用简介(批量索引)
Druid使用的端口如下:
| Druid节点类型 | 端口 |
|---|---|
| Broker | 8590 |
| Overlord | 8591 |
| Coordinator | 8592 |
| Router | 8593 |
| Historical | 8594 |
| MiddleManager | 8595 |
Druid提供Http访问,每个请求都会返回结果,如果使用curl命令没有任何返回,可以加上-v查看具体的响应信息。
-
远程登录到创建好的集群中
ssh root@[master节点公网ip]
使用创建集群时输入的密码 -
切换成hdfs用户,在HDFS上创建quickstart目录
hdfs dfs -mkdir /user/druid/quickstart
-
将示例数据文件wikiticker-2015-09-12-sampled.json.gz拷贝到HDFS
hdfs dfs -copyFromLocal /opt/bmr/druid/quickstart/wikiticker-2015-09-12-sampled.json.gz /user/druid/quickstart
-
向Overlord提交批量索引任务
curl -v -X POST -H 'Content-Type: application/json' -d @/opt/bmr/druid/quickstart/wikiticker-index.json http://xxx-master-instance-xxx-1(hostname):8591/druid/indexer/v1/task
成功返回结果为{"task":"index_hadoop_wikiticker_yyyy-MM-ddThh:mm:ss.xxZ"}如果使用的是高可用集群,Overlord只有一个为Active,有效的hostname可能是xxx-master-instance-xxx-2。
-
使用Web UI查看任务执行情况
使用ssh -ND [本地未使用端口] root@[公网ip] 并对浏览器做相关配置,例如Chrome浏览器通过Swichysharp配置了VPN之后(通过SSH-Tunnel访问集群),或者使用OpenVPN,可通过Master节点的内网ip加上Overlord端口(8591)查看结果,如下图所示:
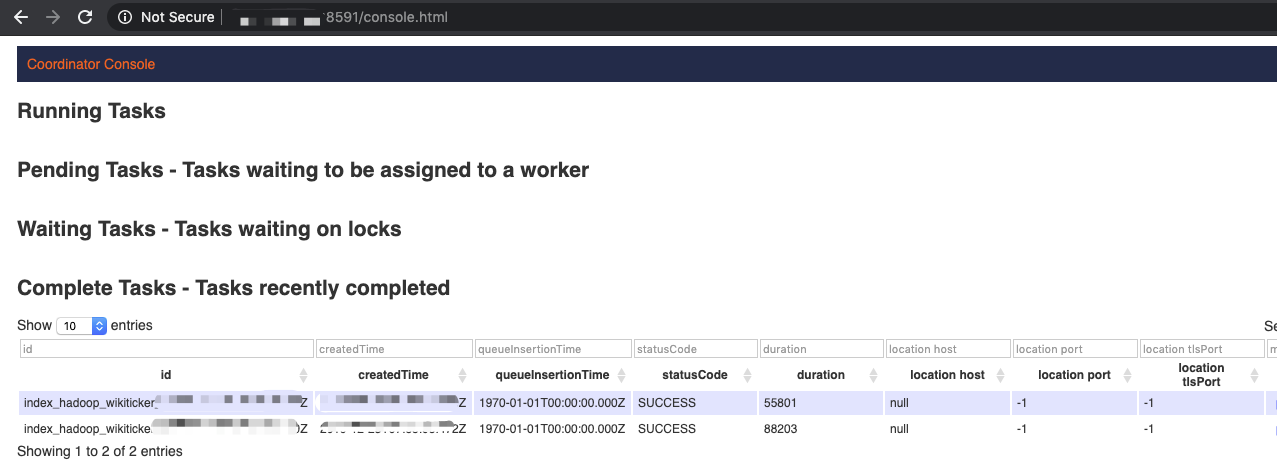
- 等到索引任务执行成功,查看数据源
使用Web UI:配置好VPN后,通过Master节点的内网ip加上Coordinator端口(8592)查看结果,如下图所示:
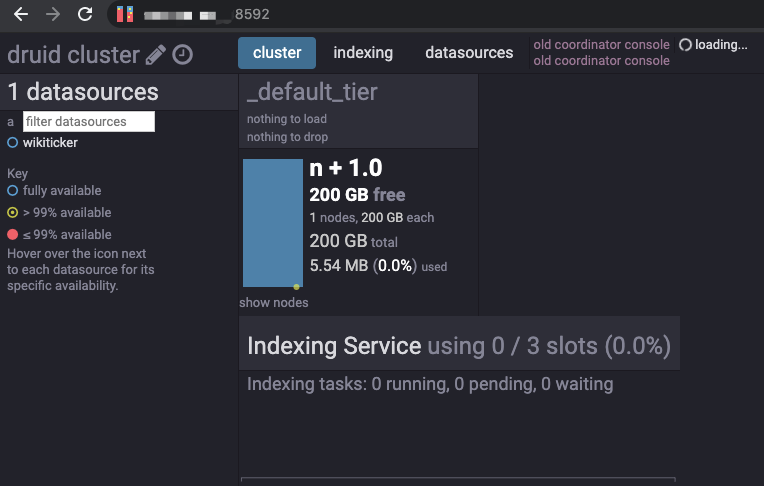
使用Http:
curl -v -X GET http://xxx-master-instance-xxx-1:8592/druid/coordinator/v1/datasources
成功返回结果为["wikiticker"]
如果使用的是高可用集群,Coordinator只有一个为Active,有效的hostname可能是xxx-master-instance-xxx-2。
-
查询数据
当Overlord Web UI显示任务成功或者查看数据源显示有wikiticker的时候,可以使用Broker查询数据:
curl -v -X 'POST' -H 'Content-Type:application/json' -d @/opt/bmr/druid/quickstart/wikiticker-top-pages.json http://[master/task hostname或ip]:8590/druid/v2?pretty
Tips: 如果需要使用自己的Druid Spec JSON,建议在~目录下编辑,并在本地做好备份。Spec的编写请参考Apache Druid官方文档。
使用Kafka Indexing Service
Druid提供了Kafka Indexing Service摄入实时数据,详情参考Druid官方文档。BMR托管的Druid可支持百度消息服务BMS、BMR内部和放在同一VPC下的Kafka集群。本示例使用百度消息服务BMS演示,通过其他方式部署的Kafka集群步骤类似。
-
使用百度消息服务BMS创建主题 kafka_demo,然后下载BMS的证书,用于后续创建Kafka生产者和消费者,参考BMS文档
-
在~目录(/home/hdfs),将下载完毕的BMS证书上传并解压到此处,然后scp到其他节点
unzip -d kafka-key kafka-key.zip scp -rp kafka-key root@[节点ip或hostname]:~/
-
在~目录(/home/hdfs)下编写Druid Spec文件kafka_demo.json,BMS的主题需要带上创建后生成的前缀
查看client.properties文件,替换kafka_demo.json里的ssl.keystore.password { "type": "kafka", "dataSchema":
若使用的不是开启SSL的Kafka集群,consumerProperties只需要配置bootstrap.servers即可,例如BMR集群中的Kafka。
-
{ "dataSource": "wiki_kafka_demo", "parser": { "type": "string", "parseSpec": { "format": "json",
-
"timestampSpec": { "column": "time", "format": "auto" }, "dimensionsSpec": { "dimensions": [
-
"channel", "cityName", "comment", "countryIsoCode", "countryName", "isAnonymous", "isMinor",
-
"isNew", "isRobot", "isUnpatrolled", "metroCode", "namespace", "page", "regionIsoCode", "regionName",
-
"user", { "name": "added", "type": "long" }, { "name": "deleted", "type": "long" }, { "name": "delta",
-
"type": "long" } ] } } }, "metricsSpec" : [], "granularitySpec": { "type": "uniform", "segmentGranularity":
-
"DAY", "queryGranularity": "NONE", "rollup": false } }, "tuningConfig": { "type": "kafka",
-
"reportParseExceptions": false }, "ioConfig": { "topic": "[accountID]__kafka_demo", "replicas":
-
2, "taskDuration": "PT10M", "completionTimeout": "PT20M", "consumerProperties": { "bootstrap.servers":
-
"[kafka_address]:[kafka_port]", "security.protocol": "SSL", "ssl.truststore.password": "kafka",
-
"ssl.truststore.location": "/home/hdfs/kafka-key/client.truststore.jks", "ssl.keystore.location":
-
"/home/hdfs/kafka-key/client.keystore.jks", "ssl.keystore.password": "******" } } }
-
向Overlord提交Kafka Supervisor任务
curl -XPOST -H'Content-Type: application/json' -d @kafka_demo.json http://[overlord_ip]:8591/druid/indexer/v1/supervisor
成功返回:
{"id":"wiki_kafka_demo"},Overlord Web UI上也可以看到结果:
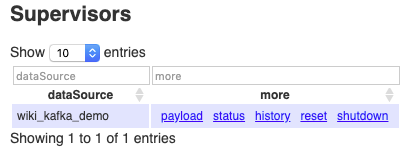
-
本地目录解压BMS证书压缩包,使用client.propertie启动Kafka生产者并发送消息
sh bin/kafka-console-producer.sh --producer.config client.properties --topic <accountID>__kafka_demo --sync --broker-list
-
[kafka_address]:[kafka_port] {"time":"2015-09-12T23:58:31.643Z","channel":"#en.wikipedia","cityName":null,"comment":"Notification: tagging for -
deletion of [[File:Axintele team.gif]]. ([[WP:TW|TW]])","countryIsoCode":null,"countryName":null,"isAnonymous"
-
:false,"isMinor":false,"isNew":false,"isRobot":false,"isUnpatrolled":false,"metroCode":null,"namespace":"User
-
talk","page":"User talk:AlexGeorge33","regionIsoCode":null,"regionName":null,"user":"Sir Sputnik","delta":1921,
-
"added":1921,"deleted":0} {"time":"2015-09-12T23:58:33.743Z","channel":"#vi.wikipedia","cityName":null,"comment":"clean up using [[Pro -
ject:AWB|AWB]]","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,
-
"isRobot":true,"isUnpatrolled":false,"metroCode":null,"namespace":"Main","page":"Codiaeum finisterrae","
-
regionIsoCode":null,"regionName":null,"user":"ThitxongkhoiAWB","delta":18,"added":18,"deleted":0} {"time":"2015-09-12T23:58:35.732Z","channel":"#en.wikipedia","cityName":null,"comment":"Put info into infobox, -
succession box, split sections a bit","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor
-
":false,"isNew":false,"isRobot":false,"isUnpatrolled":false,"metroCode":null,"namespace":"Main","page":"Jamel
-
Holley","regionIsoCode":null,"regionName":null,"user":"Mr. Matté","delta":3427,"added":3427,"deleted":0} {"time":"2015-09-12T23:58:38.531Z","channel":"#uz.wikipedia","cityName":null,"comment":"clean up, replaced: -
ozbekcha → oʻzbekcha, olchami → oʻlchami (3) using [[Project:AWB|AWB]]","countryIsoCode":null,"countryName
-
":null,"isAnonymous":false,"isMinor":true,"isNew":false,"isRobot":true,"isUnpatrolled":false,"metroCode"
-
:null,"namespace":"Main","page":"Chambors","regionIsoCode":null,"regionName":null,"user":"Ximik1991Bot"
-
,"delta":8,"added":8,"deleted":0} {"time":"2015-09-12T23:58:41.619Z","channel":"#it.wikipedia","cityName":null,"comment":"/* Gruppo Discovery -
Italia */","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"
-
isRobot":false,"isUnpatrolled":true,"metroCode":null,"namespace":"Main","page":"Deejay TV","regionIsoCode"
-
:null,"regionName":null,"user":"Ciosl","delta":4,"added":4,"deleted":0} {"time":"2015-09-12T23:58:43.304Z","channel":"#en.wikipedia","cityName":null,"comment":"/* Plot */"," -
countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":false,
-
"isUnpatrolled":false,"metroCode":null,"namespace":"Main","page":"Paper Moon (film)","regionIsoCode":null,
-
"regionName":null,"user":"Siddharth Mehrotra","delta":0,"added":0,"deleted":0} {"time":"2015-09-12T23:58:46.732Z","channel":"#en.wikipedia","cityName":null,"comment":"/* Jeez */ delete -
(also fixed Si Trew's syntax error, as I think he meant to make a link there)","countryIsoCode":null,"
-
countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":false,"isUnpatrolled":false,
-
"metroCode":null,"namespace":"Wikipedia","page":"Wikipedia:Redirects for discussion/Log/2015 September 12",
-
"regionIsoCode":null,"regionName":null,"user":"JaykeBird","delta":293,"added":293,"deleted":0} {"time":"2015-09-12T23:58:48.729Z","channel":"#fr.wikipedia","cityName":null,"comment":"MàJ","countryIsoCode" -
:null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":false,"isUnpatrolled":
-
false,"metroCode":null,"namespace":"Wikipédia","page":"Wikipédia:Bons articles/Nouveau","regionIsoCode":null
-
,"regionName":null,"user":"Gemini1980","delta":76,"added":76,"deleted":0} {"time":"2015-09-12T23:58:51.785Z","channel":"#vi.wikipedia","cityName":null,"comment":"clean up using -
[[Project:AWB|AWB]]","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,
-
"isNew":false,"isRobot":true,"isUnpatrolled":false,"metroCode":null,"namespace":"Main","page":"Amata yezonis",
-
"regionIsoCode":null,"regionName":null,"user":"ThitxongkhoiAWB","delta":10,"added":10,"deleted":0} {"time":"2015-09-12T23:58:53.898Z","channel":"#vi.wikipedia","cityName":null,"comment":"clean up using -
[[Project:AWB|AWB]]","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew"
-
:false,"isRobot":true,"isUnpatrolled":false,"metroCode":null,"namespace":"Main","page":"Codia triverticillata",
-
"regionIsoCode":null,"regionName":null,"user":"ThitxongkhoiAWB","delta":36,"added":36,"deleted":0}
-
通过Coordinator Web UI查看实时数据源
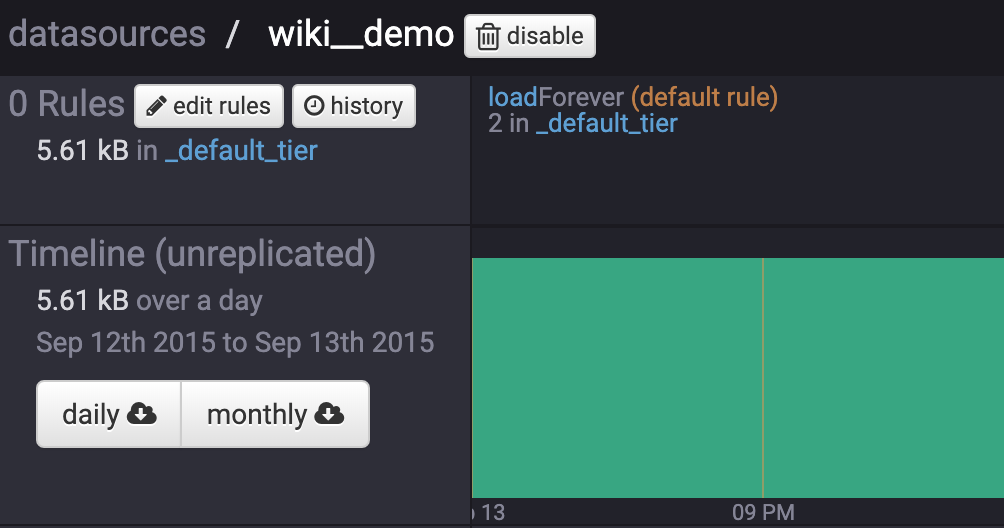
跨集群使用Druid
Druid支持通过跨集群和其他Hadoop组件联合使用,如Hadoop、Hive、Spark等。在集群创建页将多个集群创建在同一个私有网络(VPC)之下,curl命令或者Http客户端就可以指定IP和端口向Druid各组件发送跨集群的请求。

目前只支持通过IP地址访问同一个VPC下的另一个集群的主机。
使用Hive简化Druid操作
在Hive中可以通过指定IP地址和端口访问Druid节点。
本节提供一个能够运行的示例,更多使用详情可参考Apache Hive官方文档https://cwiki.apache.org/confluence/display/Hive/Druid+Integration
示例一:查询
推荐使用Hive查询Druid数据,可以简化Druid常用的查询,不用为了简单的查询而去编写复杂的JSON文件。
-
创建一个Hive集群,登录Hive集群
ssh root@[hive集群公网ip]
使用创建hive集群时输入的密码 -
指定Druid集群Broker的IP地址和端口
hive> SET hive.druid.broker.address.default=x.x.x.x:8590;
-
创建外表(确保按照之前的示例,创建了wikiticker数据源)
hive> CREATE EXTERNAL TABLE druid_hive_demo_01 STORED BY 'org.apache.hadoop.hive.druid.DruidStorageHandler' TBLPROPERTIES ("druid.datasource" = "wikiticker");
-
查看元信息
hive> DESCRIBE FORMATTED druid_hive_demo_01;
其中维度列是string类型,指标列是bigint类型,时间戳字段__time是timestamp with local time zone类型 -
查询数据
hive> SELECT `__time`, count, page, `user`, added FROM druid_hive_demo_01 LIMIT 10;
注意:使用Hive无法扫描Druid全表,如上面的例子不使用limit会报错
__time是Druid表(数据源)的时间戳字段,在Hive中需要用反引号转义,返回结果如下:
2015-09-12 08:46:58.771 Asia/Shanghai 1 36 Talk:Oswald Tilghman GELongstreet 2015-09-12 08:47:00.496 Asia/Shanghai 1 17 Rallicula PereBot 2015-09-12 08:47:05.474 Asia/Shanghai 1 0 Peremptory norm 60.225.66.142 2015-09-12 08:47:08.77 Asia/Shanghai 1 18 Apamea abruzzorum Cheers!-bot 2015-09-12 08:47:11.862 Asia/Shanghai 1 18 Atractus flammigerus ThitxongkhoiAWB 2015-09-12 08:47:13.987 Asia/Shanghai 1 18 Agama mossambica ThitxongkhoiAWB 2015-09-12 08:47:17.009 Asia/Shanghai 1 0 Campanya dels Balcans (1914-1918) Jaumellecha 2015-09-12 08:47:19.591 Asia/Shanghai 1 345 Talk:Dani Ploeger New Media Theorist 2015-09-12 08:47:21.578 Asia/Shanghai 1 121 User:WP 1.0 bot/Tables/Project/Pubs WP 1.0 bot 2015-09-12 08:47:25.821 Asia/Shanghai 1 18 Agama persimilis ThitxongkhoiAWB
示例二:导入历史数据
可以使用已有的Hive表,通过建外表将HDFS数据导入到Druid中,不必编写复杂的Druid Ingestion Spec文件。注意,必须指定时间戳字段__time,且时间戳类型为timestamp with local time zone。
-
进入~目录,下载示例数据文件,创建示例Hive表
wget http://files.grouplens.org/datasets/movielens/ml-100k.zip unzip ml-100k.zip hive> CREATE TABLE u_data ( userid INT, movieid INT, rating INT, unixtime STRING) ROW FORMAT DELIMITED FIELDS
-
TERMINATED BY '\t' STORED AS TEXTFILE; LOAD DATA LOCAL INPATH 'ml-100k/u.data' OVERWRITE INTO TABLE u_data;
-
设置Hive属性,关联Druid
// 获取druid集群的元数据库信息:ssh root@public_ip 'cat /etc/druid/conf/_common/common.runtime.properties -
| grep "druid.metadata.storage.connector"' // 跨集群访问druid集群的mysql,需要使用ip地址,
-
若使用hostname需要更新hive集群的hosts文件 // 需要删除外表时开启,可以清空Druid数据: SET external.table.purge=true;
-
SET hive.druid.metadata.uri=jdbc:mysql://[druid_mysql_ip]:3306/druid?characterEncoding=UTF-8; SET hive.
-
druid.metadata.username=[druid_user]; SET hive.druid.metadata.password=[druid_passwd]; SET hive.druid.broker
-
.address.default=[druid_broker_ip]:8590; SET hive.druid.overlord.address.default=[druid_overlord_ip]:8591;
-
SET hive.druid.coordinator.address.default=[druid_coordinator_ip]:8592; SET hive.druid.storage.storageDirec
-
tory=hdfs://[hive_hdfs_ip]:8020/user/druid/warehouses;
-
方法一:先建表再导入数据
CREATE EXTERNAL TABLE druid_hive_demo_02 (`__time` TIMESTAMP WITH LOCAL TIME ZONE, userid STRING, moveid
方法二,使用CTAS语句创建Druid表并导入数据
// 首先打开Hive外表的CTAS开关 SET hive.ctas.external.tables=true; CREATE EXTERNAL TABLE druid_hive_demo_02 STORED BY 'org.apache.hadoop.hive.druid.DruidStorageHandler' TBLPROPERTIES ( "druid.segment.granularity"
如果CTAS语句执行失败,创建的表仍然存在,可以继续使用INSERT语句插入数据,或者删除该表并重新执行。
-
= "MONTH", "druid.query.granularity" = "DAY") AS SELECT cast (from_unixtime(cast(unixtime as int)) as
-
timestamp with local time zone) as `__time`, cast(userid as STRING) userid, cast(movieid as STRING) moveid,
-
cast(rating as INT) rating FROM u_data;
-
STRING, rating INT) STORED BY 'org.apache.hadoop.hive.druid.DruidStorageHandler' TBLPROPERTIES
-
( "druid.segment.granularity" = "MONTH", "druid.query.granularity" = "DAY" ); INSERT INTO druid_hive_demo_02
-
SELECT cast (from_unixtime(cast(unixtime as int)) as timestamp with local time zone) as `__time`, cast(userid
-
as STRING) userid, cast(movieid as STRING) moveid, cast(rating as INT) rating FROM u_data;
-
查询结果
hive> SELECT * FROM druid_hive_demo_02 LIMIT 10; OK 1997-09-19 08:00:00.0 Asia/Shanghai 259 1074
-
3 1997-09-19 08:00:00.0 Asia/Shanghai 259 108 4 1997-09-19 08:00:00.0 Asia/Shanghai 259 117
-
4 1997-09-19 08:00:00.0 Asia/Shanghai 259 173 4 1997-09-19 08:00:00.0 Asia/Shanghai 259 176 4
-
1997-09-19 08:00:00.0 Asia/Shanghai 259 185 4 1997-09-19 08:00:00.0 Asia/Shanghai 259 200 4
-
1997-09-19 08:00:00.0 Asia/Shanghai 259 210 4 1997-09-19 08:00:00.0 Asia/Shanghai 259 255
-
4 1997-09-19 08:00:00.0 Asia/Shanghai 259 286 4
示例三:导入Kafka实时数据
-
使用百度消息服务BMS创建主题 kafka_demo,并下载证书scp到druid集群各节点,参考BMS文档。
scp -rp kafka-key root@[druid集群的节点ip或hostname]:~/
-
创建Hive表,通过属性关联BMS Kafka
// 获取druid集群的元数据库信息:ssh hdfs@public_ip 'cat /etc/druid/conf/_common/common.runtime.如果使用的不是开启了SSL的Kafka,可移除ssl相关配置,例如BMR集群里的Kafka
-
properties | grep "druid.metadata.storage.connector"' // 跨集群访问druid集群的mysql,
-
需要使用ip地址,若使用hostname需要更新hive集群的hosts文件 SET hive.druid.metadata.uri=jdbc:mysql
-
://[druid_mysql_ip]:3306/druid?characterEncoding=UTF-8; SET hive.druid.metadata.username=[druid_user];
-
SET hive.druid.metadata.password=[druid_passwd]; SET hive.druid.broker.address.default=[druid_broker_ip]:
-
8590; SET hive.druid.overlord.address.default=[druid_overlord_ip]:8591; SET hive.druid.coordinator.address.
-
default=[druid_coordinator_ip]:8592; SET hive.druid.storage.storageDirectory=hdfs://[hive_hdfs_ip]:8020/
-
user/druid/warehouses; // Kafka Supervisor配置前缀是druid.kafka.ingestion CREATE EXTERNAL TABLE druid_
-
kafka_demo ( `__time` TIMESTAMP WITH LOCAL TIME ZONE, `channel` STRING, `cityName` STRING, `comment` STRING,
-
`countryIsoCode` STRING, `isAnonymous` STRING, `isMinor` STRING, `isNew` STRING, `isRobot` STRING, `isUnpatrolled`
-
STRING, `metroCode` STRING, `namespace` STRING, `page` STRING, `regionIsoCode` STRING, `regionName` STRING,
-
`added` INT, `user` STRING, `deleted` INT, `delta` INT ) STORED BY 'org.apache.hadoop.hive.druid.
-
DruidStorageHandler' TBLPROPERTIES ( "kafka.bootstrap.servers" = "[kafka_address]:[kafka_port]",
-
"kafka.security.protocol" = "SSL", "kafka.ssl.truststore.password" = "kafka", "kafka.ssl.truststore.
-
location" = "/home/hdfs/kafka-key/client.truststore.jks", "kafka.ssl.keystore.location" =
-
"/home/hdfs/kafka-key/client.keystore.jks", "kafka.ssl.keystore.password" = "******",
-
"kafka.topic" = "[account_id]__kafka_demo", "druid.kafka.ingestion.useEarliestOffset" = "true",
-
"druid.kafka.ingestion.maxRowsInMemory" = "5", "druid.kafka.ingestion.startDelay" = "PT1S",
-
"druid.kafka.ingestion.period" = "PT1S", "druid.kafka.ingestion.taskDuration" = "PT10M",
-
"druid.kafka.ingestion.completionTimeout" = "PT20M", "druid.kafka.ingestion.consumer.retries" = "2" );
-
启动Kafka生产者发送数据
sh bin/kafka-console-producer.sh --producer.config client.properties --topic druid_kafka_demo --sync
-
--broker-list [kafka_address]:[kafka_port] {"__time":"2015-09-12T23:58:31.643Z","channel":"#en.wikipedia","cityName":null,"comment":"Notification: -
tagging for deletion of [[File:Axintele team.gif]]. ([[WP:TW|TW]])","countryIsoCode":null,"countryName"
-
:null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":false,"isUnpatrolled":false,"metroCode"
-
:null,"namespace":"User talk","page":"User talk:AlexGeorge33","regionIsoCode":null,"regionName":null,"user"
-
:"Sir Sputnik","delta":1921,"added":1921,"deleted":0} {"__time":"2015-09-12T23:58:33.743Z","channel":"#vi.wikipedia","cityName":null,"comment":"clean up using -
[[Project:AWB|AWB]]","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew"
-
:false,"isRobot":true,"isUnpatrolled":false,"metroCode":null,"namespace":"Main","page":"Codiaeum finisterrae
-
","regionIsoCode":null,"regionName":null,"user":"ThitxongkhoiAWB","delta":18,"added":18,"deleted":0} {"__time":"2015-09-12T23:58:35.732Z","channel":"#en.wikipedia","cityName":null,"comment":"Put info into -
infobox, succession box, split sections a bit","countryIsoCode":null,"countryName":null,"isAnonymous":
-
false,"isMinor":false,"isNew":false,"isRobot":false,"isUnpatrolled":false,"metroCode":null,"namespace":
-
"Main","page":"Jamel Holley","regionIsoCode":null,"regionName":null,"user":"Mr. Matté","delta":3427,"added":3427,"deleted":0} {"__time":"2015-09-12T23:58:38.531Z","channel":"#uz.wikipedia","cityName":null,"comment":"clean up, re -
placed: ozbekcha → oʻzbekcha, olchami → oʻlchami (3) using [[Project:AWB|AWB]]","countryIsoCode":null,"
-
countryName":null,"isAnonymous":false,"isMinor":true,"isNew":false,"isRobot":true,"isUnpatrolled":false,"
-
metroCode":null,"namespace":"Main","page":"Chambors","regionIsoCode":null,"regionName":null,"user":"Ximik
-
1991Bot","delta":8,"added":8,"deleted":0} {"__time":"2015-09-12T23:58:41.619Z","channel":"#it.wikipedia","cityName":null,"comment":"/* Gruppo Disc -
overy Italia */","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false
-
,"isRobot":false,"isUnpatrolled":true,"metroCode":null,"namespace":"Main","page":"Deejay TV","regionIsoCode
-
":null,"regionName":null,"user":"Ciosl","delta":4,"added":4,"deleted":0} {"__time":"2015-09-12T23:58:43.304Z","channel":"#en.wikipedia","cityName":null,"comment":"/* Plot */","coun -
tryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":false,"isUn
-
patrolled":false,"metroCode":null,"namespace":"Main","page":"Paper Moon (film)","regionIsoCode":null,"region
-
Name":null,"user":"Siddharth Mehrotra","delta":0,"added":0,"deleted":0} {"__time":"2015-09-12T23:58:46.732Z","channel":"#en.wikipedia","cityName":null,"comment":"/* Jeez */ delete -
(also fixed Si Trew's syntax error, as I think he meant to make a link there)","countryIsoCode":null,"coun
-
tryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":false,"isUnpatrolled":false,"metro
-
Code":null,"namespace":"Wikipedia","page":"Wikipedia:Redirects for discussion/Log/2015 September 12","regio
-
nIsoCode":null,"regionName":null,"user":"JaykeBird","delta":293,"added":293,"deleted":0} {"__time":"2015-09-12T23:58:48.729Z","channel":"#fr.wikipedia","cityName":null,"comment":"MàJ","countryIsoCo -
de":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":false,"isUnpatrolled
-
":false,"metroCode":null,"namespace":"Wikipédia","page":"Wikipédia:Bons articles/Nouveau","regionIsoCode":
-
null,"regionName":null,"user":"Gemini1980","delta":76,"added":76,"deleted":0} {"__time":"2015-09-12T23:58:51.785Z","channel":"#vi.wikipedia","cityName":null,"comment":"clean up using -
[[Project:AWB|AWB]]","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew
-
":false,"isRobot":true,"isUnpatrolled":false,"metroCode":null,"namespace":"Main","page":"Amata yezonis",
-
"regionIsoCode":null,"regionName":null,"user":"ThitxongkhoiAWB","delta":10,"added":10,"deleted":0} {"__time":"2015-09-12T23:58:53.898Z","channel":"#vi.wikipedia","cityName":null,"comment":"clean up using -
[[Project:AWB|AWB]]","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew"
-
:false,"isRobot":true,"isUnpatrolled":false,"metroCode":null,"namespace":"Main","page":"Codia triverticillata"
-
,"regionIsoCode":null,"regionName":null,"user":"ThitxongkhoiAWB","delta":36,"added":36,"deleted":0}
-
可以通过DDL控制Kafka导入数据的启停
// 只有druid.kafka.ingestion为START,Hive才能够提交实时任务到Druid ALTER TABLE druid_kafka_demo
-
SET TBLPROPERTIES('druid.kafka.ingestion' = 'START'); ALTER TABLE druid_kafka_demo SET TBLPROPERTIES
-
('druid.kafka.ingestion' = 'STOP'); ALTER TABLE druid_kafka_demo SET
-
TBLPROPERTIES('druid.kafka.ingestion' = 'RESET');
- 当第一个Segment上传成功,Coordinator显示出数据源后即可使用Hive查询数据,见示例一
