

文档简介:



Alluxio简介
1.什么是Alluxio
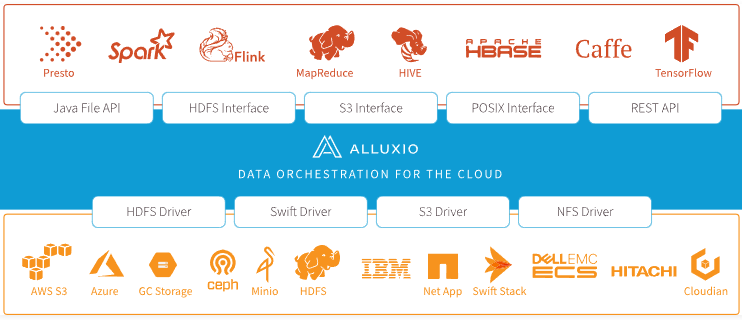
Alluxio 是世界上第一个面向基于云的数据分析和人工智能的开源的数据编排技术。 它为数据驱动型应用和存储系统构建了桥梁, 将数据从存 储层移动到距离数据驱动型应用更近的位置从而能够更容易被访问。 这还使得应用程序能够通过一个公共接口连接到许多存储系统。 Alluxio内 存至上的层次化架构使得数据的访问速度能比现有方案快几个数量级。 在大数据生态系统中,Alluxio 位于数据驱动框架或应用(如 Apache Spark、Presto、Tensorflow、Apache HBase、Apache Hive 或 Apache Flink)和各种持久化存储系统(如 Amazon S3、Google Cloud Storage、OpenStack Swift、HDFS、GlusterFS、IBM Cleversafe、EMC ECS、Ceph、NFS 、Minio和Baidu BOS)之间。 Alluxio 统一了存储在这些不同存储系统中的数据,为其上层数据驱动型应用提供统一的客户端 API 和全局命名空间。 Alluxio 项目源自 UC Berkeley 的 AMPLab,在伯克利数据分析栈 (Berkeley Data Analytics Stack, BDAS) 中扮演数据访问层的角色。 它以 Apache License 2.0 协议的方式开源。 Alluxio 是发展最快的开源大数据项目之一,已经吸引了超过 300 个组织机构的1000多名贡献者参与到 Alluxio 的开发中,包括 阿里巴巴、 Alluxio、 百度、 CMU、 Google、 IBM、 Intel、 南京大学、 Red Hat、 腾讯、 UC Berkeley、 和 Yahoo。


-
优势
通过简化应用程序访问其数据的方式(无论数据是什么格式或位置),Alluxio 能够帮助克服从数据中提取信息所面临的困难。Alluxio 的优势包括:
- 内存速度 I/O:Alluxio 能够用作分布式共享缓存服务,这样与 Alluxio 通信的计算应用程序可以透明地缓存频繁访问的数据(尤其是从远程位置),以提供内存级 I/O 吞吐率。此外,Alluxio的层次化存储机制能够充分利用内存、固态硬盘或者磁盘,降低具有弹性扩张特性的数据驱动型应用的成本开销。
- 简化云存储和对象存储接入:与传统文件系统相比,云存储系统和对象存储系统使用不同的语义,这些语义对性能的影响也不同于传统文件系统。在云存储和对象存储系统上进行常见的文件系统操作(如列出目录和重命名)通常会导致显著的性能开销。当访问云存储中的数据时,应用程序没有节点级数据本地性或跨应用程序缓存。将 Alluxio 与云存储或对象存储一起部署可以缓解这些问题,因为这样将从 Alluxio 中检索读取数据,而不是从底层云存储或对象存储中检索读取。
- 简化数据管理:Alluxio 提供对多数据源的单点访问。除了连接不同类型的数据源之外,Alluxio 还允许用户同时连接同一存储系统的不同版本,如多个版本的 HDFS,并且无需复杂的系统配置和管理。
- 应用程序部署简易:Alluxio 管理应用程序和文件或对象存储之间的通信,将应用程序的数据访问请求转换为底层存储接口的请求。Alluxio 与 Hadoop 生态系统兼容,现有的数据分析应用程序,如 Spark 和 MapReduce 程序,无需更改任何代码就能在 Alluxio 上运行。
- 技术创新
- 全局命名空间:Alluxio 能够对多个独立存储系统提供单点访问,无论这些存储系统的物理位置在何处。这提供了所有数据源的统一视图和应用程序的标准接口。有关详细信息,请参阅统一命名空间文档。
- 智能多层级缓存:Alluxio 集群能够充当底层存储系统中数据的读写缓存。可配置自动优化数据放置策略,以实现跨内存和磁盘(SSD/HDD)的性能和可靠性。缓存对用户是透明的,使用缓冲来保持与持久存储的一致性。有关详细信息,请参阅 缓存功能文档。
- 服务器端 API 翻译转换:Alluxio支持工业界场景的API接口,例如HDFS API, S3 API, FUSE API, REST API。它能够透明地从标准客户端接口转换到任何存储接口。Alluxio 负责管理应用程序和文件或对象存储之间的通信,从而消除了对复杂系统进行配置和管理的需求。文件数据可以看起来像对象数据,反之亦然。
创建集群
- 准备数据,请参考数据准备。
- 准备百度智能云环境。
-
登录控制台,选择“产品服务->MapReduce BMR”,点击“创建集群”,进入集群创建页,并做如下配置:
- 设置集群名称
- 设置管理员密码
- 选择镜像版本“BMR 2.2.0(hadoop 3.1)”
- 选择内置模板“hadoop”。
- 选择组件时勾选alluxio、spark、hive、hbase等组件。
- 请保持集群的其他默认配置不变,点击“完成”可在集群列表页可查看已创建的集群,当集群状态由“初始化中”变为“空闲中”时,集群创建成功。
使用Alluxio
-
首先将你需要通过alluxio访问的bos路径挂载到集群内的alluxio上,具体操作如下:
- 登录集群虚机
- 在虚机上执行:alluxio fs mount /bos_path1 bos://testbucket/produce/,挂载所需的bos路径
- 通过alluxio查看:alluxio fs ls /bos_path1
-
通过alluxio对挂载路径的bos文件进行改动
i) alluxio fs rm /bos_path1/a.txt ii) alluxio fs copyFromLocal b.txt /bos_path1/
-
MR作业支持alluxio schema
hadoop jar /opt/bmr/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar wordcount alluxio:///bos_path1/b.txt alluxio:///wordcount_output
-
spark支持alluxio schema
val sc1 = sc.textFile("alluxio:///bos_path1/b.txt") val d1 = sc1.map(line => line + line) d1.saveAsTextFile("alluxio:///output") - hive支持alluxio schema
- 创建表
CREATE TABLE `default.table_alluxio_t`(
`message` string)
PARTITIONED BY (
`dt` string,
`ip` string,
`inode` string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\u0001'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'alluxio:///table_alluxio_t/'
TBLPROPERTIES (
'transient_lastDdlTime'='1590749263');
- hive支持sql查询location是alluxio schema的表/partition
Alluxio官网手册
Alluxio概览
快速上手指南
