

百度智能云MapReduce开源组件介绍 - ClickHouse
文档简介:
ClickHouse简介:
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。它是由俄罗斯搜索引擎公司Yandex开发,并于2016年6月发布的开源DBMS,与Hadoop,Spark相比,ClickHouse轻量很多。



ClickHouse简介
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。它是由俄罗斯搜索引擎公司Yandex开发,并于2016年6月发布的开源DBMS,与Hadoop,Spark相比,ClickHouse轻量很多。
创建集群
登录百度智能云控制台,选择“产品服务->百度MapReduce BMR”,点击“创建集群”,进入集群创建页。购置集群时勾选 ClickHouse 组件即可, 如下图所示:
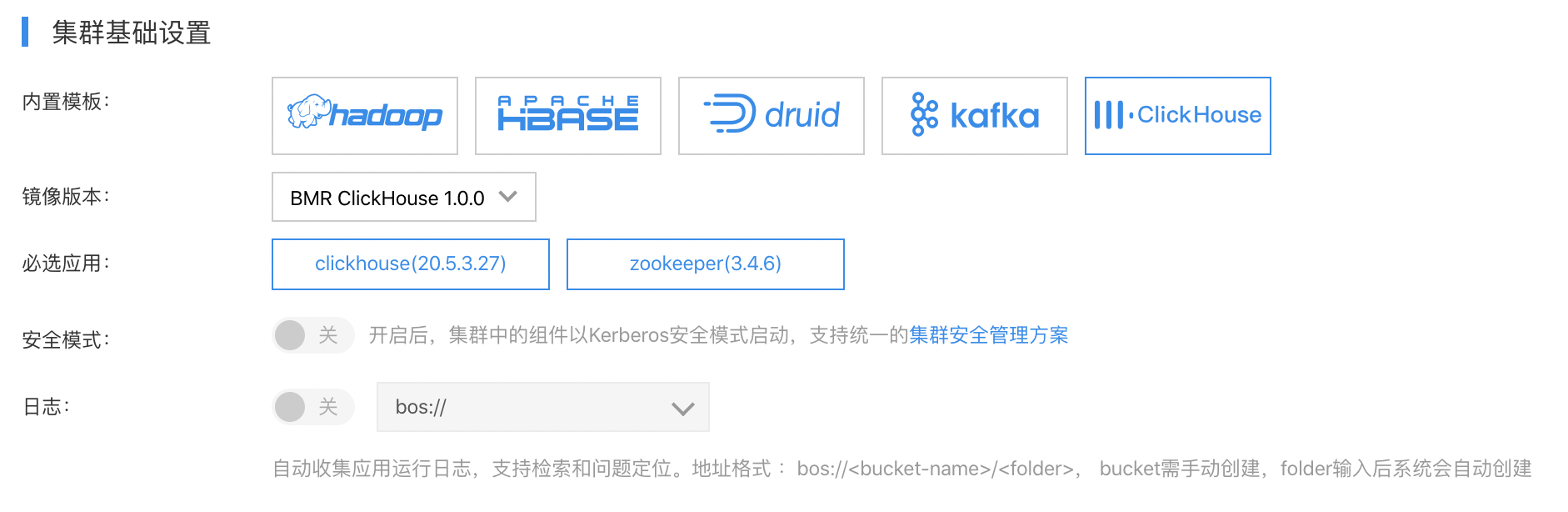
使用简介
-
远程登录到创建好的集群
ssh root@$public_ip
使用创建集群时输入的密码
-
登录ClickHouse客户端
su - clickhouse clickhouse-client -m -u admin --password 集群密码
clickhouse-client常用参数:
- -h 主机名
- -d 数据库名
- -m 客户端支持多行SQL输入以分号结尾,不指定该参数默认以回车作为SQL结尾
- -u 账户,默认admin
- --password 默认创建集群时的密码
其他client参数可以执行以下命令进行查看
clickhouse-client --help
-
本地表使用示例
- 创建本地表:
CREATE TABLE `check_local` (
`Id` UInt16,
`Name` String,
`CreateDate` Date)
ENGINE = MergeTree()
PARTITION BY CreateDate
ORDER BY Id;
- 本地表插入数据:
insert into check_local (Id, Name, CreateDate) values (1, 'aa', '2020-01-01');
- 本地表查询数据:
select * from check_local;
-
分布式表使用示例
- 在默认集群上批量建立本地表:
CREATE TABLE `check_local2` ON CLUSTER default_cluster (
`Id` UInt16,
`Name` String,
`CreateDate` Date)
ENGINE = MergeTree()
PARTITION BY CreateDate
ORDER BY Id;
备注:ClickHouse集群支持分布式DDL语句,即在DDL语句上加上ON CLUSTER <cluster_neme>的语法,使得该DDL语句执行一次便可在所有实例上创建该表。默认集群名字为default_cluster。
- 创建分布式表:
CREATE TABLE dis_check_all ON CLUSTER default_cluster
AS check_local2
ENGINE = Distributed(default_cluster, default, check_local2, rand());
- 分布式表插入语法同本地表:
insert into dis_check_all (Id, Name, CreateDate)values (1,'aa','2020-01-01');
或者
insert into dis_check_all values (1,'aa','2020-01-01');
- 分布式表查询:
select * from dis_check_all;
参考
- ClickHouse官网参考文档
- ClickHouse官网文档SQL语法参考
- ClickHouse官网基准测试数据
