




Impala简介
Impala是Cloudera公司主导开发的MPP架构的查询系统,它提供SQL语义,能够快速的查询存储在HDFS、HBASE中的数据。此外Impala使用与Hive相同的元数据、SQL语法、ODBC驱动。
创建集群
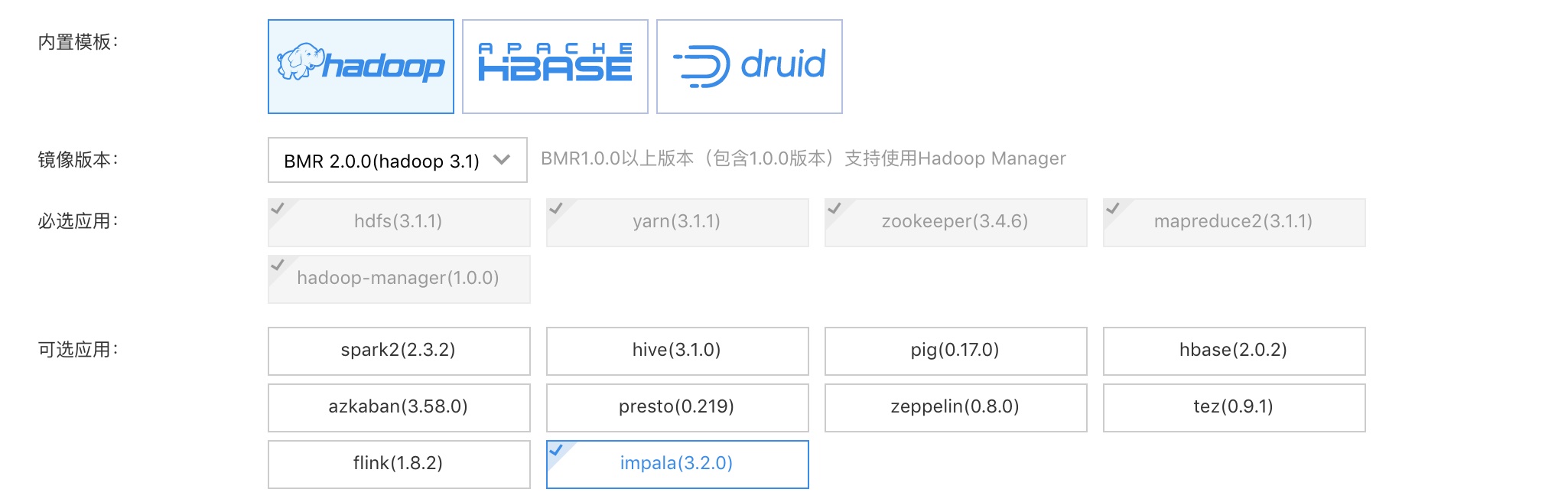
登录百度云控制台,选择“产品服务->MapReduce BMR”,点击“创建集群”,进入集群创建页。BMR2.0.0及以上版本已支持 Impala 组件集成,购置集群时勾选 Impala 组件即可, 如下图所示:
使用简介
-
远程登录到创建好的集群
ssh root@$public_ip 使用创建集群时输入的密码
-
准备数据,可以参考数据准备。上传日志文件到HDFS中。
hadoop dfs -get bos://datamart-gz/web-log-10k/accesslog-10k.log ./ hadoop dfs -put accesslog-10k.log /tmp/test
-
在impala-shell中执行命令建表
-
在shell中输入impala-shell
说明:impala-shell默认连接到localhost上impalad的21000端口。BMR集群默认只在core、task节点上安装impalad服务。
如果在master节点上执行impala-shell,需要使用-i <host:port>参数指定安装了impalad的host。更多可用参数可通过impala-shell -h查看。
-
执行如下建表语句
CREATE EXTERNAL TABLE `access_logs`( `remote_addr` string COMMENT 'client IP', `time_local` string COMMENT 'access time', `request` string COMMENT 'request URL', `status` string COMMENT 'HTTP status', `body_bytes_sent` string COMMENT 'size of response body', `http_referer` string COMMENT 'referer', `http_cookie` string COMMENT 'cookies', `remote_user` string COMMENT 'client name', `http_user_agent` string COMMENT 'client browser info', `request_time` string COMMENT 'consumed time of handling request', `host` string COMMENT 'server host', `msec` string COMMENT 'consumed time of writing logs') COMMENT 'web access logs' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LOCATION '/tmp'
-
-
建表成功后,可以使用SQL语句查询结果。如果使用提供的样例数据和建表语句,可以看到如下结果。

参考
- Apache Impala Guide
- Impala Home
