

文档简介:



Presto简介
Presto是一个分布式SQL查询引擎,用于查询分布在一个或多个不同数据源中的大数据集。Presto通过使用分布式查询,可以快速高效的完成海量数据的查询,并提供了Web UI页面方便用户查看任务查询详情与服务运行状态。
创建集群
登录百度云控制台,选择“产品服务->MapReduce BMR”,点击“创建集群”,进入集群创建页,BMR2.0.0及以上版本已支持 Presto 组件集成,购置集群时勾选 Presto 组件即可, 如下图所示:

使用简介
Presto支持本地和远程两种操作方式。
本地连接presto
登录集群机器
输入命令,进入presto终端交互页面:presto --catalog XXX --schema XXX ,示例如下: (参数含义:--catalog 是使用的数据源配置;--schema 用户选择查询的schema)
presto --catalog hive --schema test
presto:test>
执行查询命令,示例如下:
presto:test> select * from t2;
id
---------
1
(1 row)
Query 20190517_075918_00019_hs9fa, FINISHED, 1 node
Splits: 17 total, 17 done (100.00%)
0:01 [1 rows, 208B] [1 rows/s, 324B/s]
远程连接presto
将集群机器/opt/bmr/presto/bin目录下的presto-cli-0.219-executable.jar拷贝到本地 配置OpenVPN 执行连接命令:./presto-cli-0.219-executable.jar --server internal_ip:8089 --catalog XXX --schema XXX 即可连接到presto服务
Presto UI界面
访问步骤:
- 配置OpenVPN
- 在Master节点上执行 hostname 命令获取主机名
-
访问http://hostname:port (master_hostname:8089) 即可查看presto的监控页面,提供服务监控与查询详情等信息:
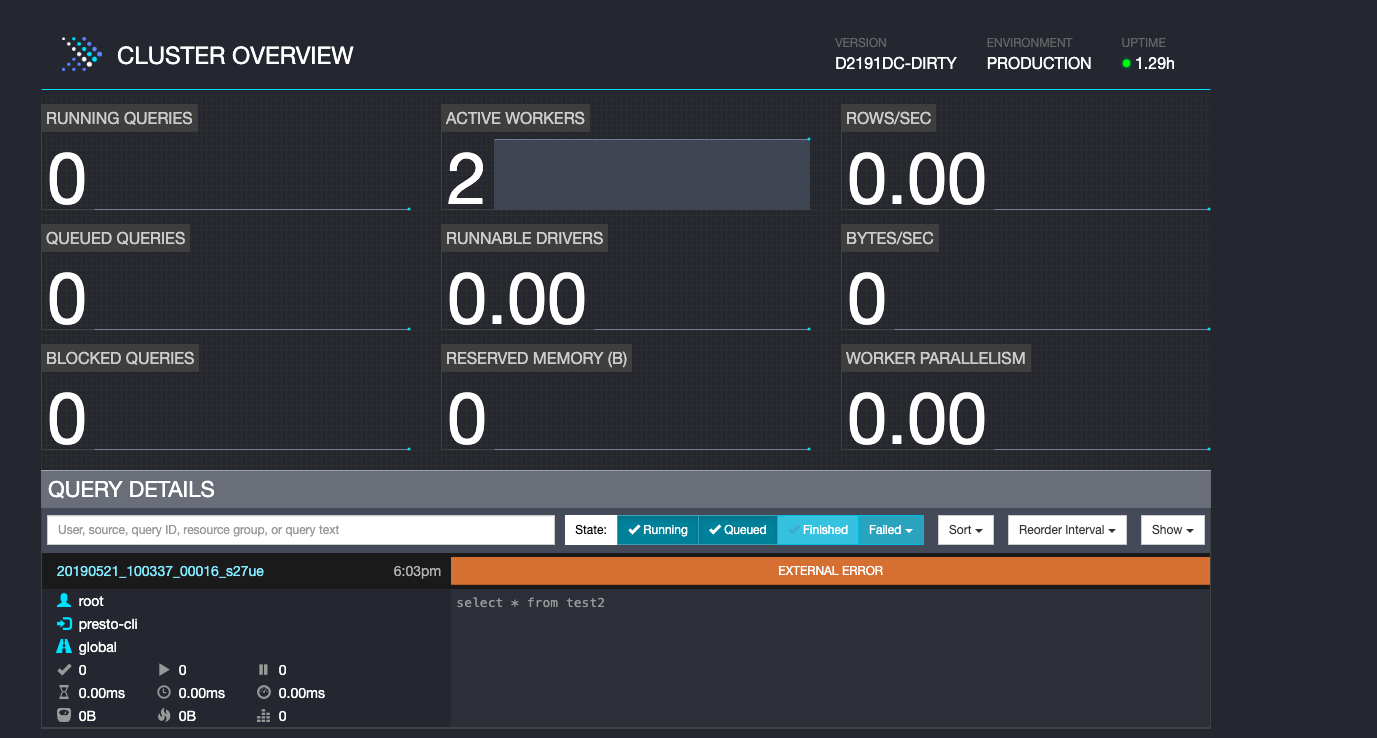
-
可以通过页面的state选项可以对查询任务进行筛选:
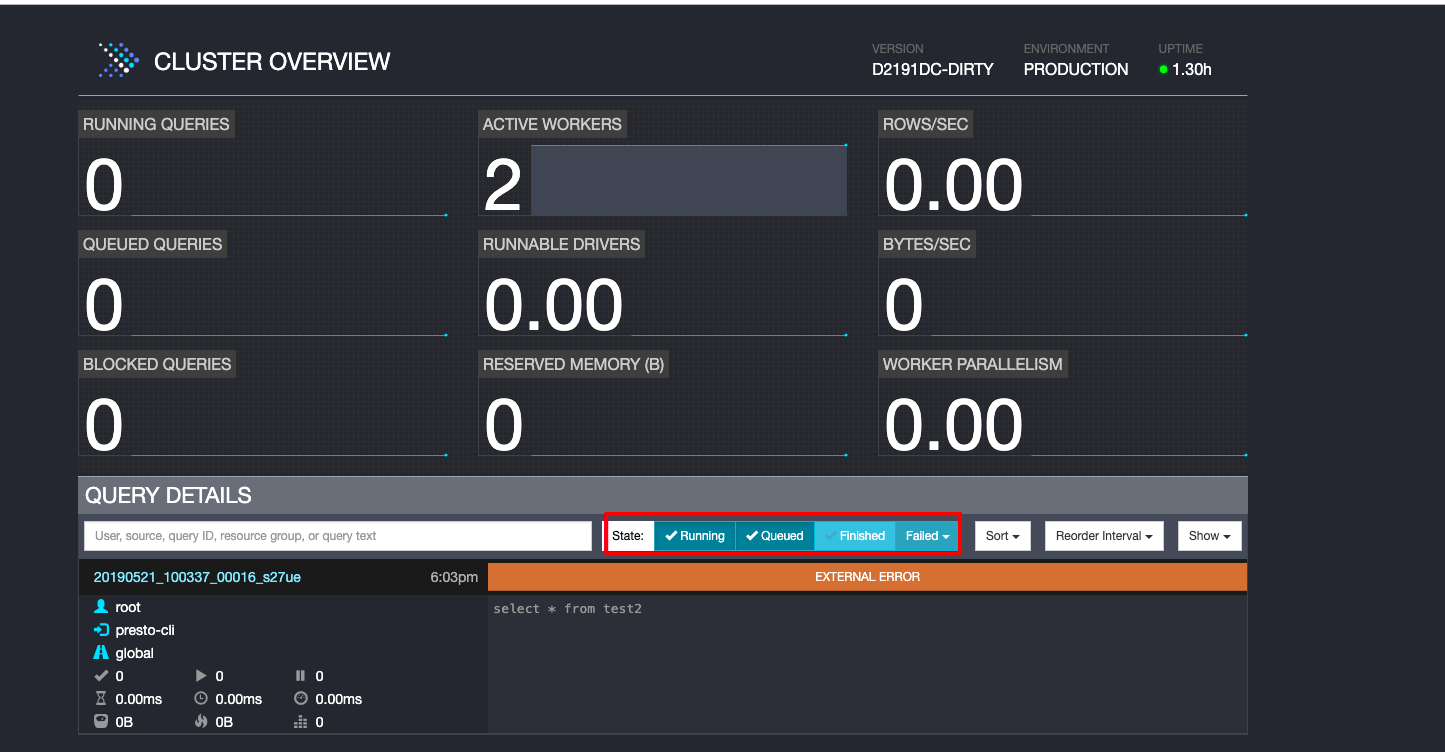
-
点击查询编号,可以进一步查看查询详情;对于失败的任务,也可以在查询详情页面查看相关日志:
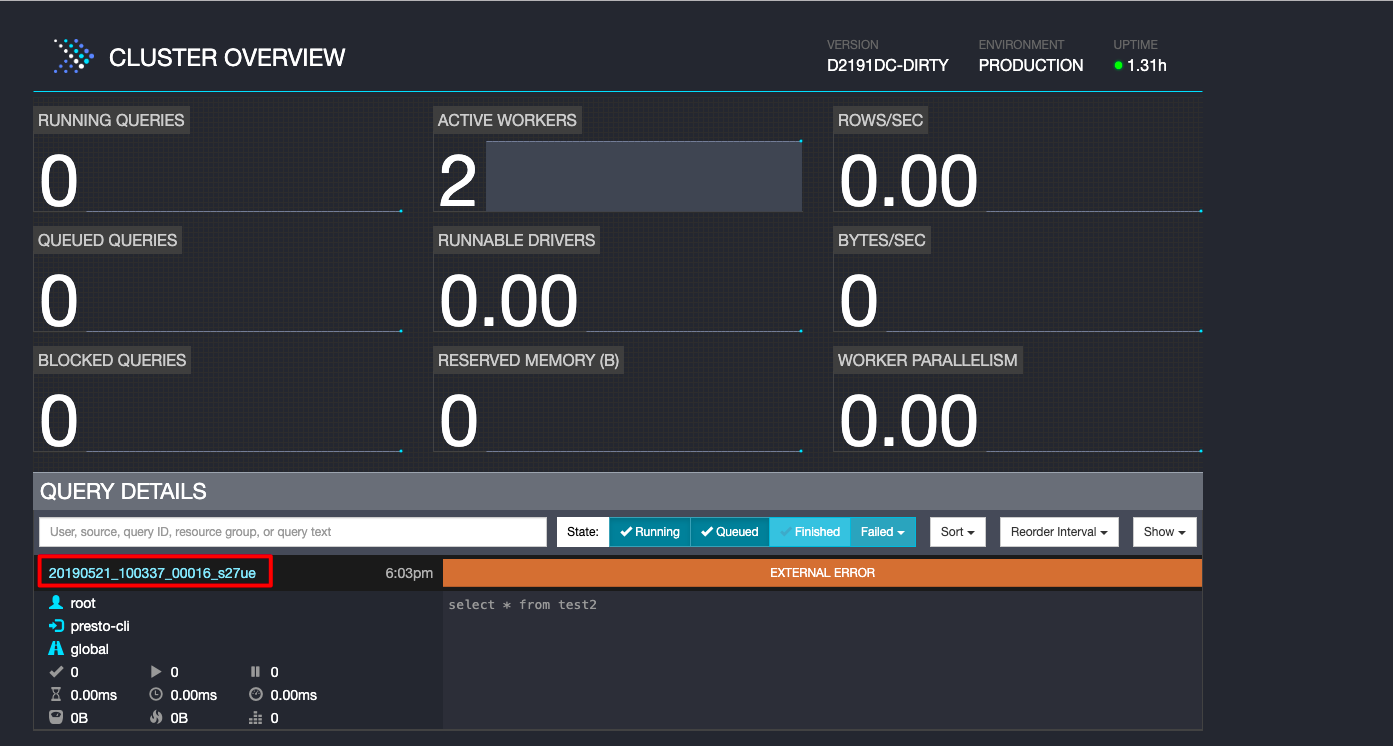
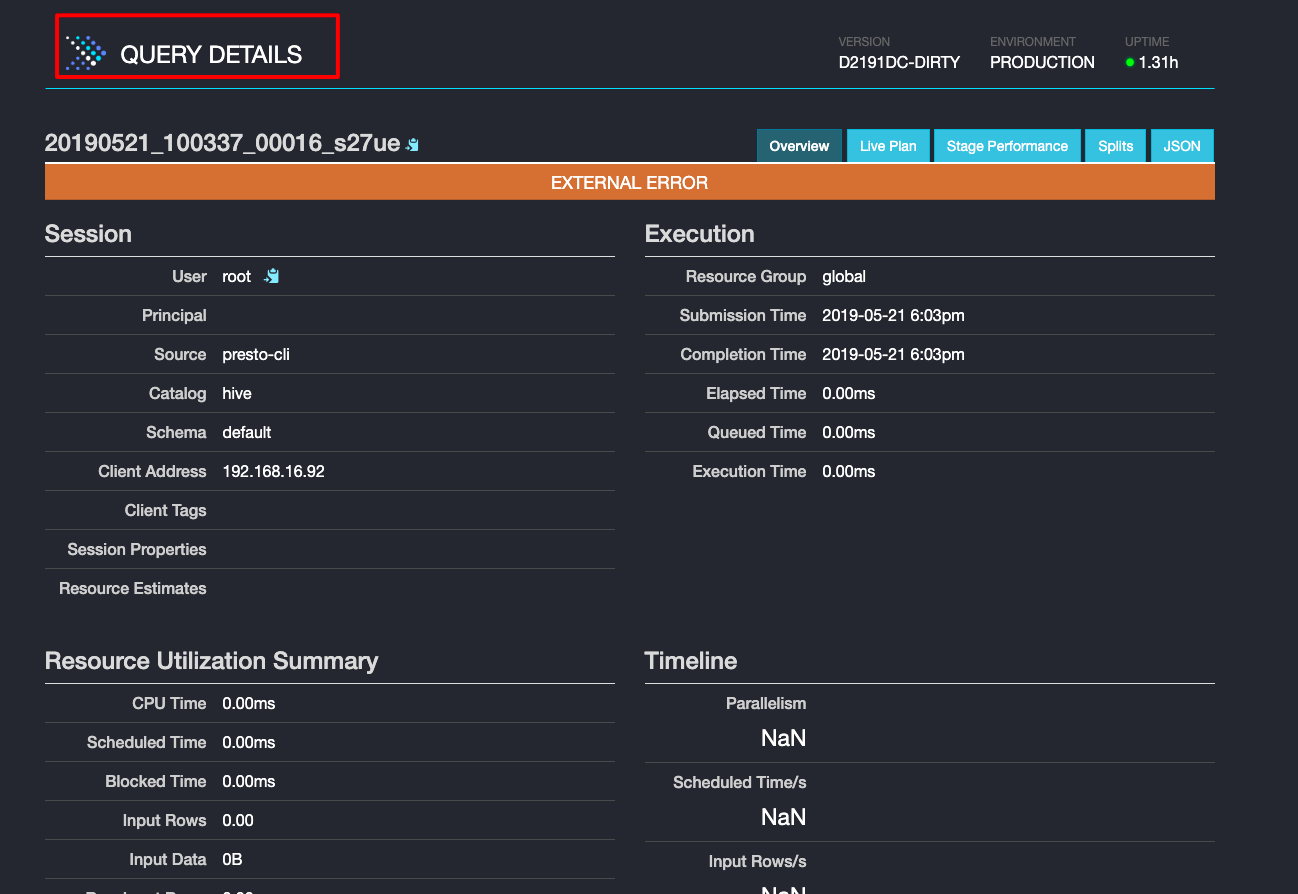

注意事项
由于Hive3 对managed tables实现了全控制,所以Persto不支持Hive的managed table查询、更改等操作;若需要通过Presto对Hive table进行查询等操作,请通过Hive创建External tables。 https://github.com/prestodb/presto/issues/12484 示例如下: 通过hive创建external tables,通过presto进行查询,查询成功:
# 连接hive,创建外表
hive> create external table test1 (id bigint) stored as textfile;
hive> insert into test1 values(123);
# 连接Presto,查询
presto:test> select * from test1;
id
-----
123
(1 row)
通过hive创建managed tables,通过presto进行查询,查询失败:
# 连接hive,创建managed table
hive> create table test2(id bigint) stored as textfile;
# 连接Presto,查询
presto:test> select * from test2;
Query XXX failed: XXX
