文档简介:



Ranger简介
Apache Ranger 提供集中式的权限管理框架,可以对Hadoop生态中的HDFS/Hive/YARN 等组件提供细粒度的权限访问控制,并且提供了Web UI页面方便管理员进行操作。
创建集群
BMR1.2.0及以上版本已支持 Ranger 组件集成,购置集群时勾选 Ranger 组件即可, 如下图所示:

访问集群的Ranger Web页面
通过SSH Tunnel访问Ranger Web页面
- 在创建集群中设置软件配置时,添加Ranger应用。
- 建立SSH Tunnel并配置浏览器,具体操作请参考[准备](BMR/操作指南/访问集群服务页面.md#通过SSH Tunnel访问集群的环境准备)中的所有步骤。
- 代理设置完后,在Master结点上执行 hostname 命令获取主机名。
- 通过访问链接http://hostname:6080 可登录 Ranger UI登录界面,默认的用户名/密码是admin/admin,如下图:
修改密码
初次登录后台后,管理员需要修改admin账户的密码,如下图所示:
权限配置
BMR Ranger 组件默认已启动了 hdfs/yarn/hive 插件,登录Ranger 管理后台可以看到默认已创建的 HDFS service/YARN service以及 HIVE service。
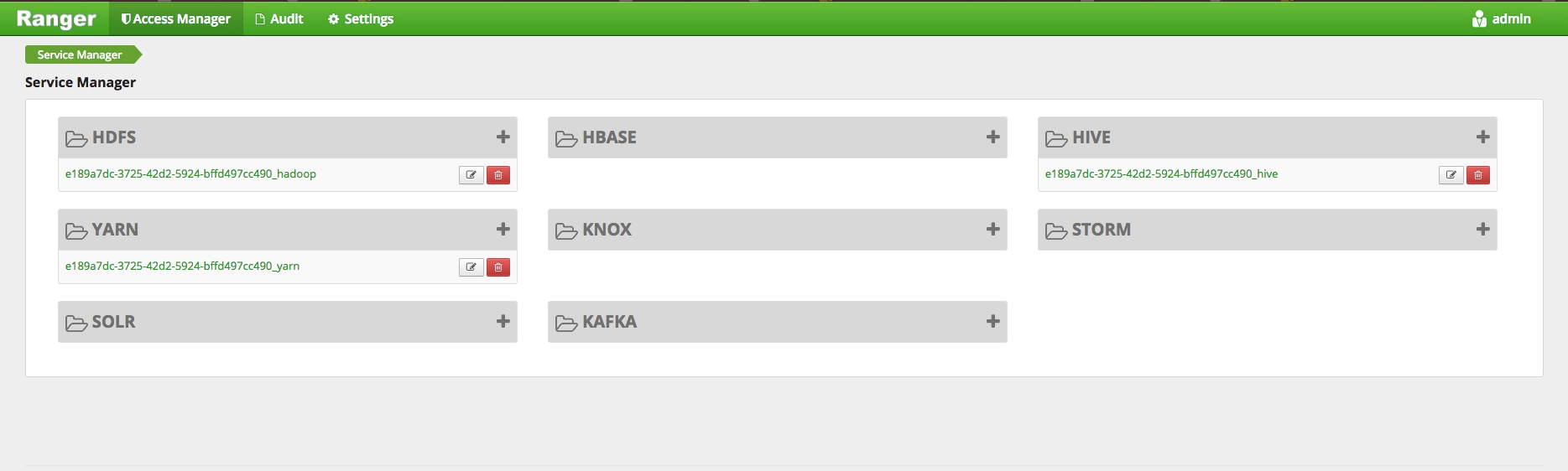
进入Access Manger页面,即可为HDFS、YARN、HIVE 等组件 service 配置相关的权限。
HDFS 配置
如下图所示,点击默认创建的 HDFS service,进入 policy 配置管理页,即可配置相关策略。
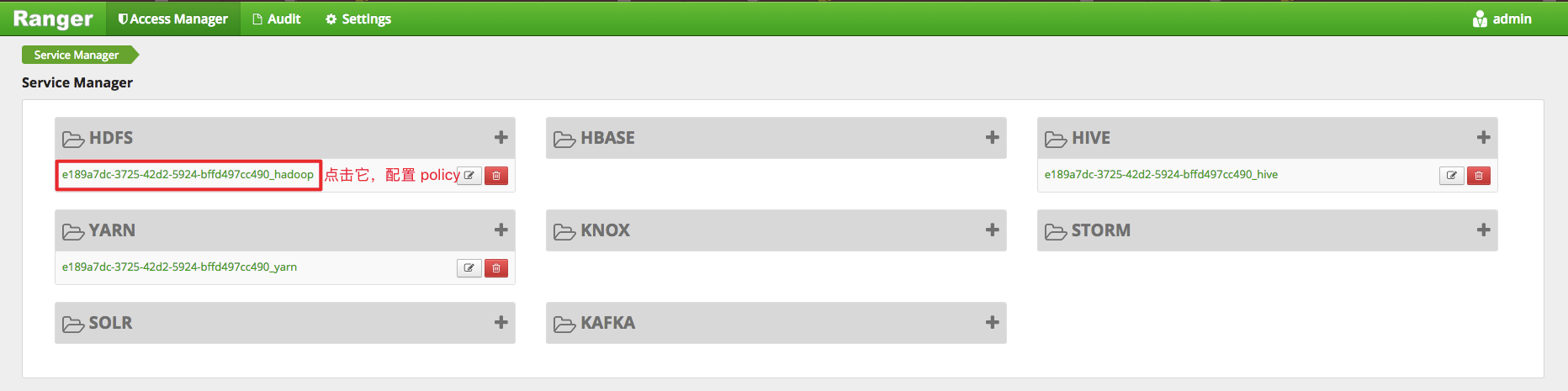
例如,给bls用户授予/user/foo;/user/log 路径的读/执行权限:
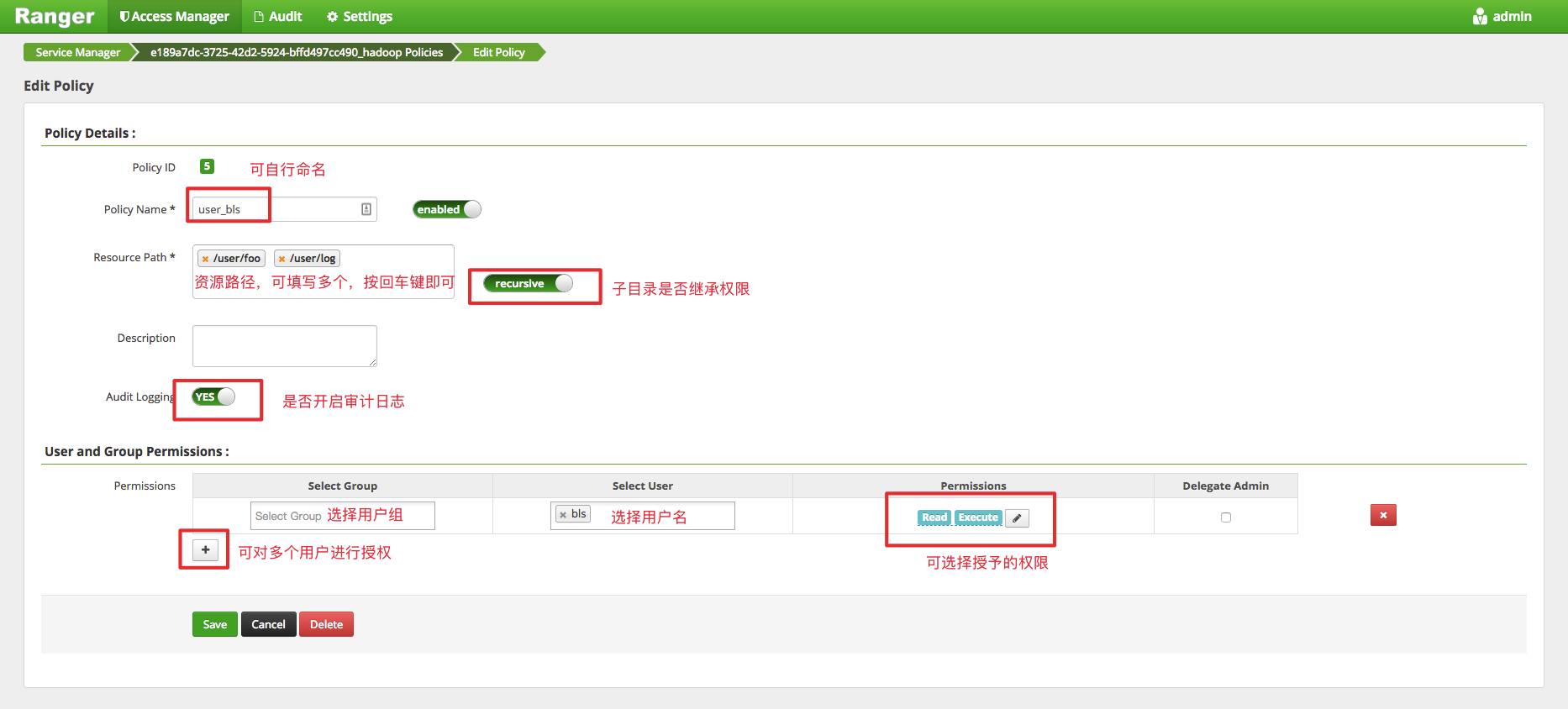
按照上述步骤设置添加一个Policy后,就实现了对bls的授权,如上图设置,bls用户对/user/foo的HDFS路径只有读和执行的权限。如果该用户上传文件则会报权限不足的错误。效果如截图所示:

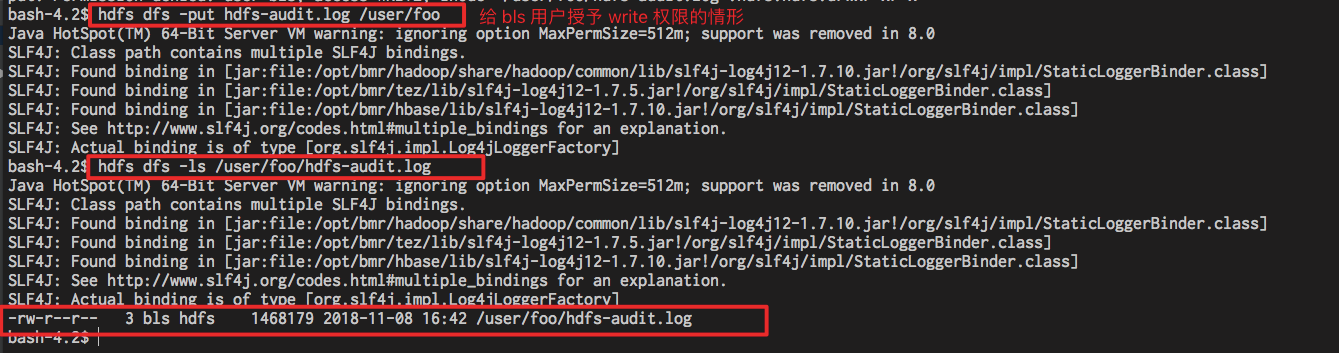
当对 bls 用户授予 write 权限后, bls 用户才可以向该路径 put 文件。例如:
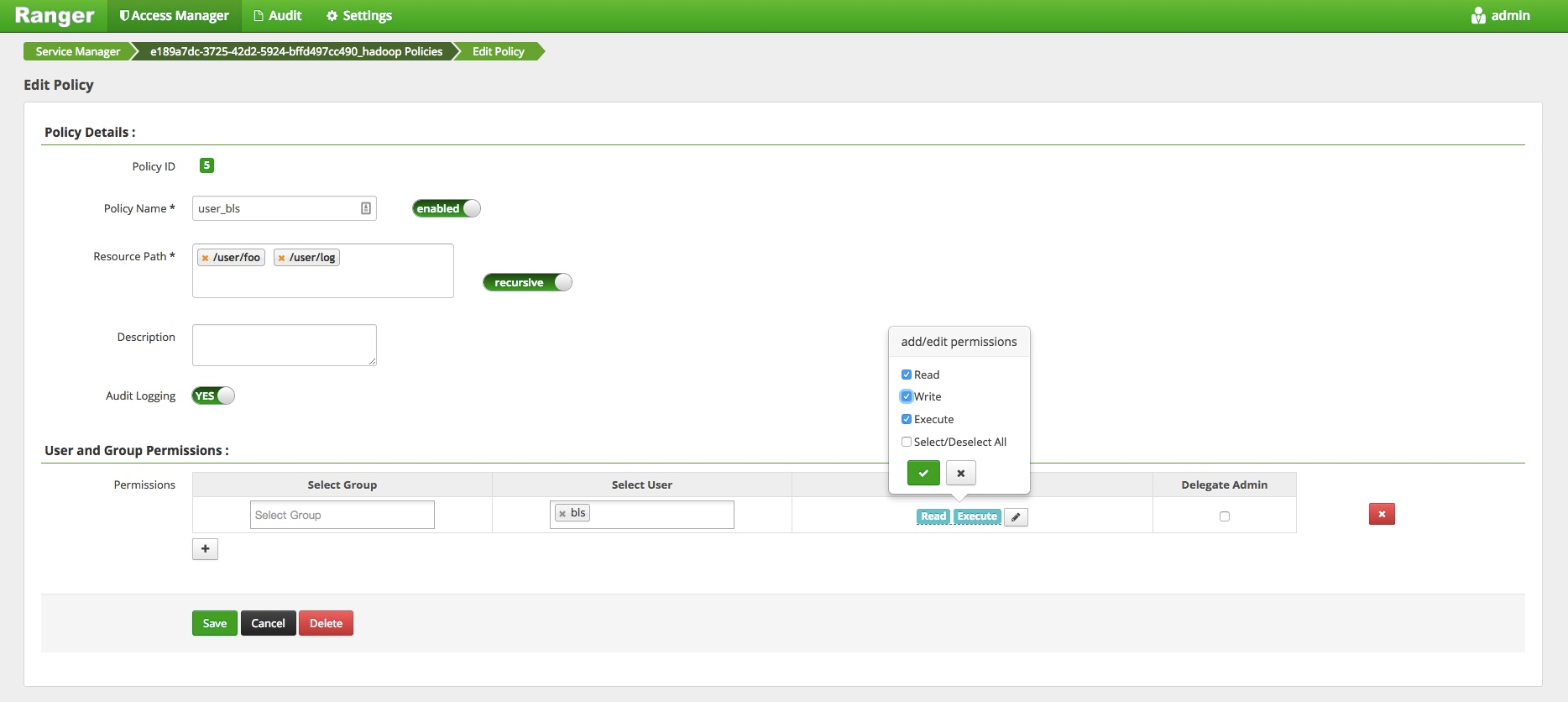
效果如截图所示:
HIVE 配置
用户可以通过三种方式访问Hive数据,包括HiveServer2、Hive Client和HDFS,所以我们需要对三种方式做访问权限控制。
- HiveServer2 方式:Ranger Hive 插件支持对 Hive 表/列级别的权限控制仅限于对 HiveServer2的使用场景(比如通过 beeline、jdbc 方式)
- Hive Client 方式:Hive 官方自带的 (Storage Based Authorization)就是针对 Hive Client使用场景进行的权限控制。本质上会根据SQL中表的HDFS路径的读写权限来决定该用户是否可以进行相关的DDL/DML操作。
- HDFS 方式:可以通过Ranger对Hive表底层的HDFS路径增加对HDFS文件的权限控制。
针对 HiveServer2 使用场景,ranger 可以实现对Hive表/列的权限设置,如下图所示,点击默认创建好的 Hive Service,进入 policy 配置管理页,即可配置相关策略。

例如:给用户 bls 授予表 bmr.user_info 的 name 字段的 select 权限。
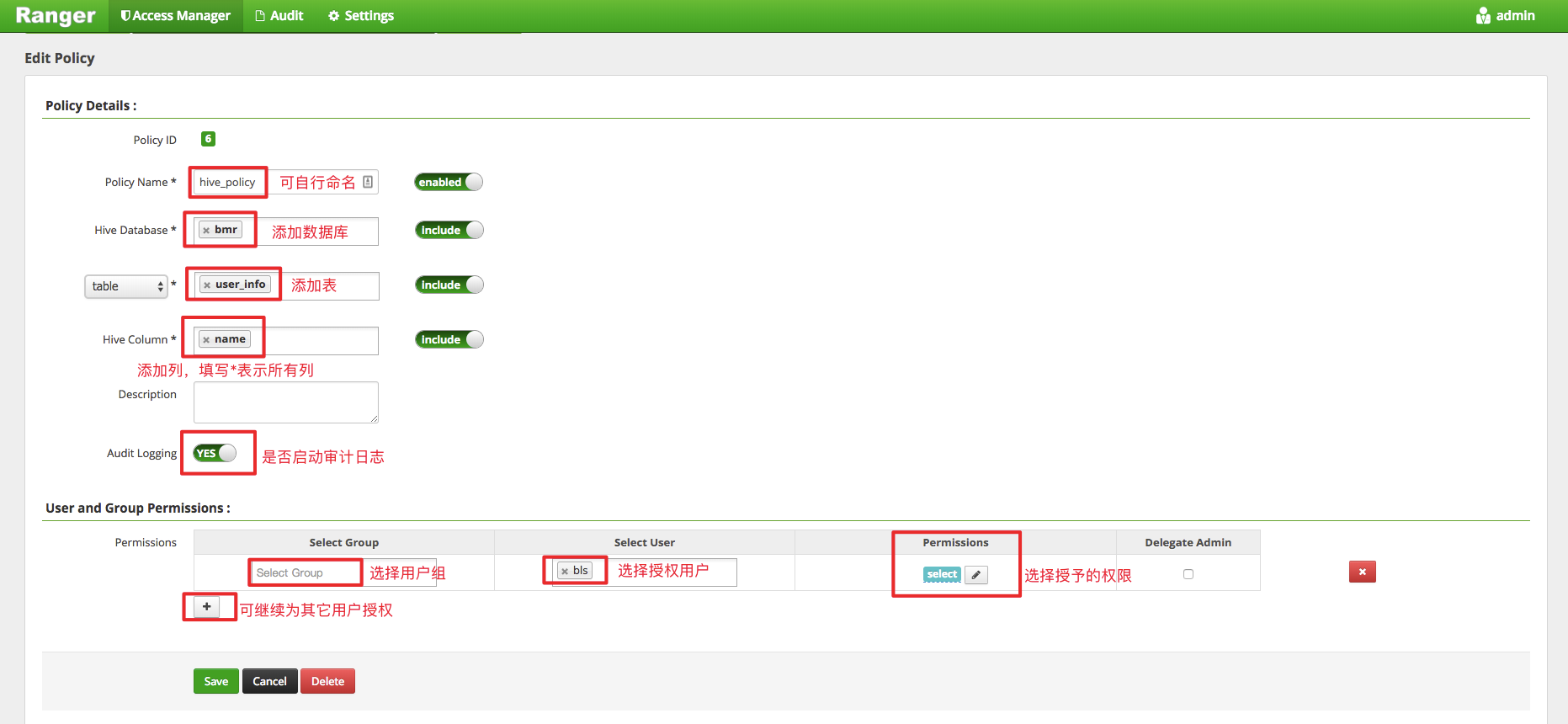
由于ranger只对 hiveServer2 权限控制生效,下面将通过 beeline 工具访问 hiveServer2为例进行说明,首先以如下方式连接 hiveServer(如果开启安全模式,还要配置相应的 principal)
/opt/bmr/hive/bin/beeline -u "jdbc:hive2://localhost:10000/default;principal=yarn/ng6c79765-master-instance-fh2qdy0g.novalocal@BAIDU.COM"
当一个没有授予Hive 操作权限的 bls 用户创建数据库时会报如下异常信息:

当对 bls 用户授予 bmr.user_info 的 name 字段的 select 权限时,查询如下:

如果执行 select * 时则会报如下异常信息:
![]()
YARN 配置
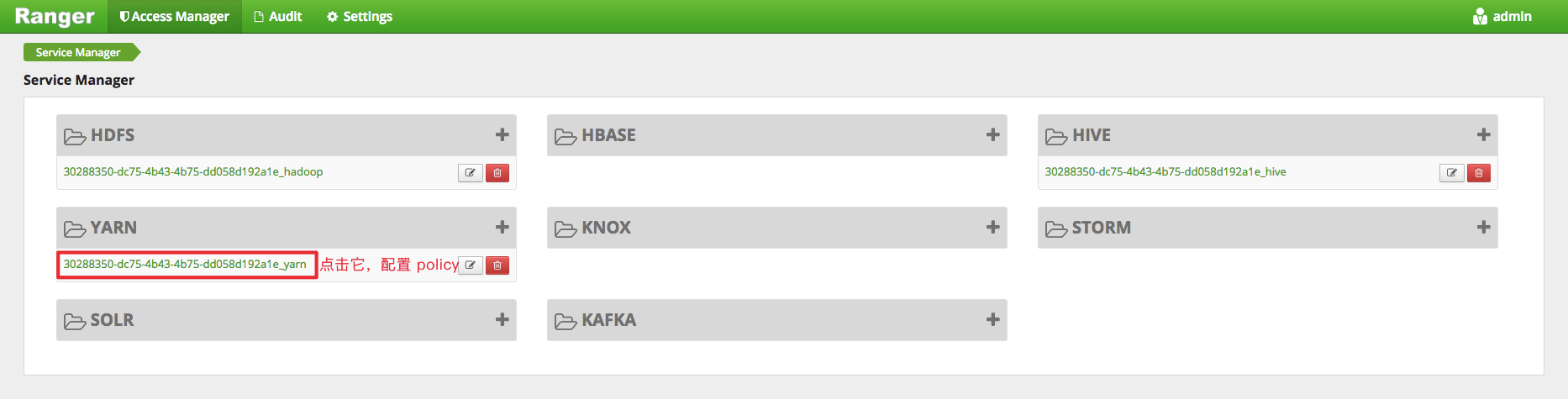
登录 Ranger 管理界面,如下图所示,点击默认创建好的 yarn service,进入 policy 配置管理页,即可配置相关策略。
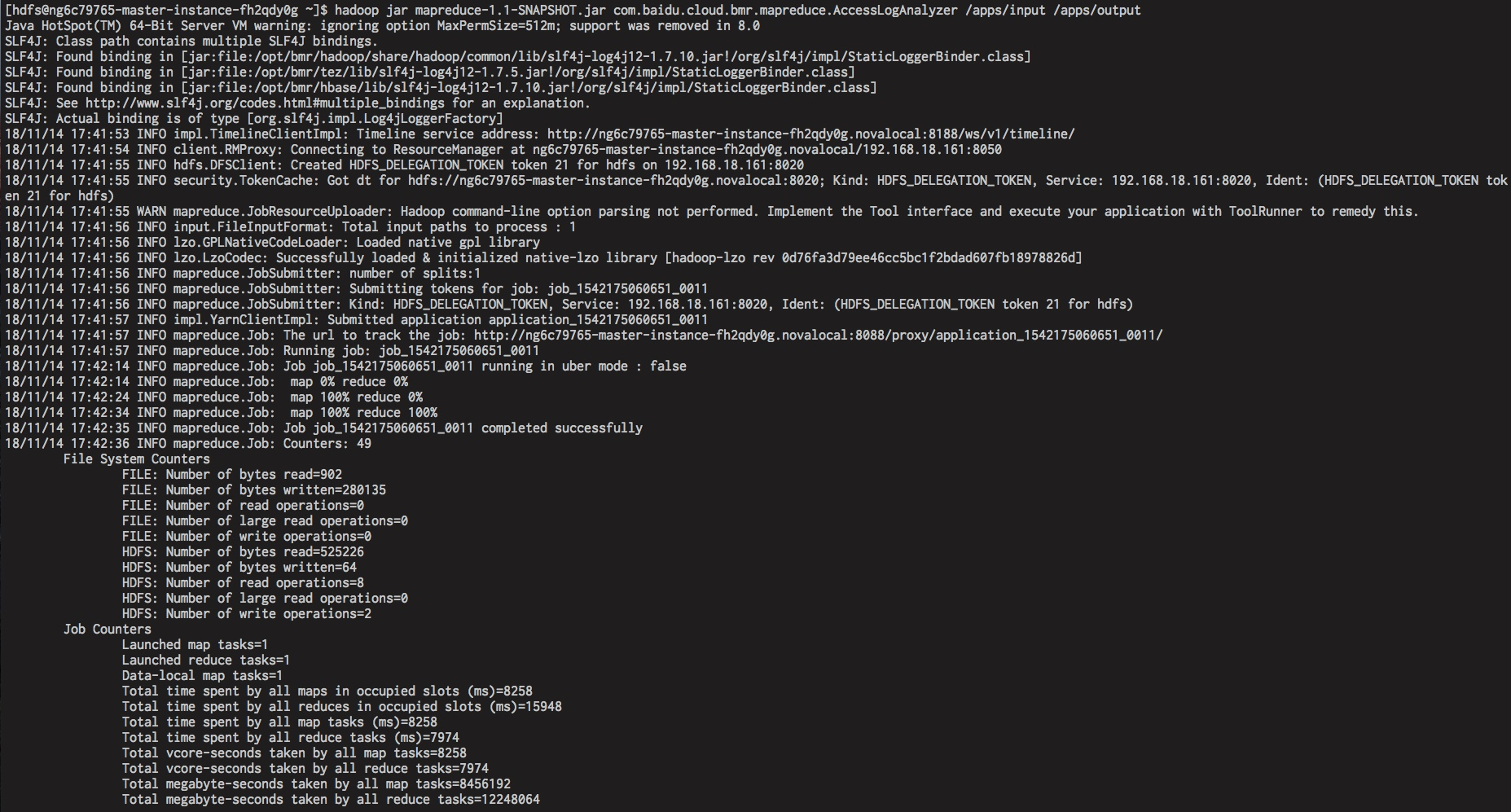
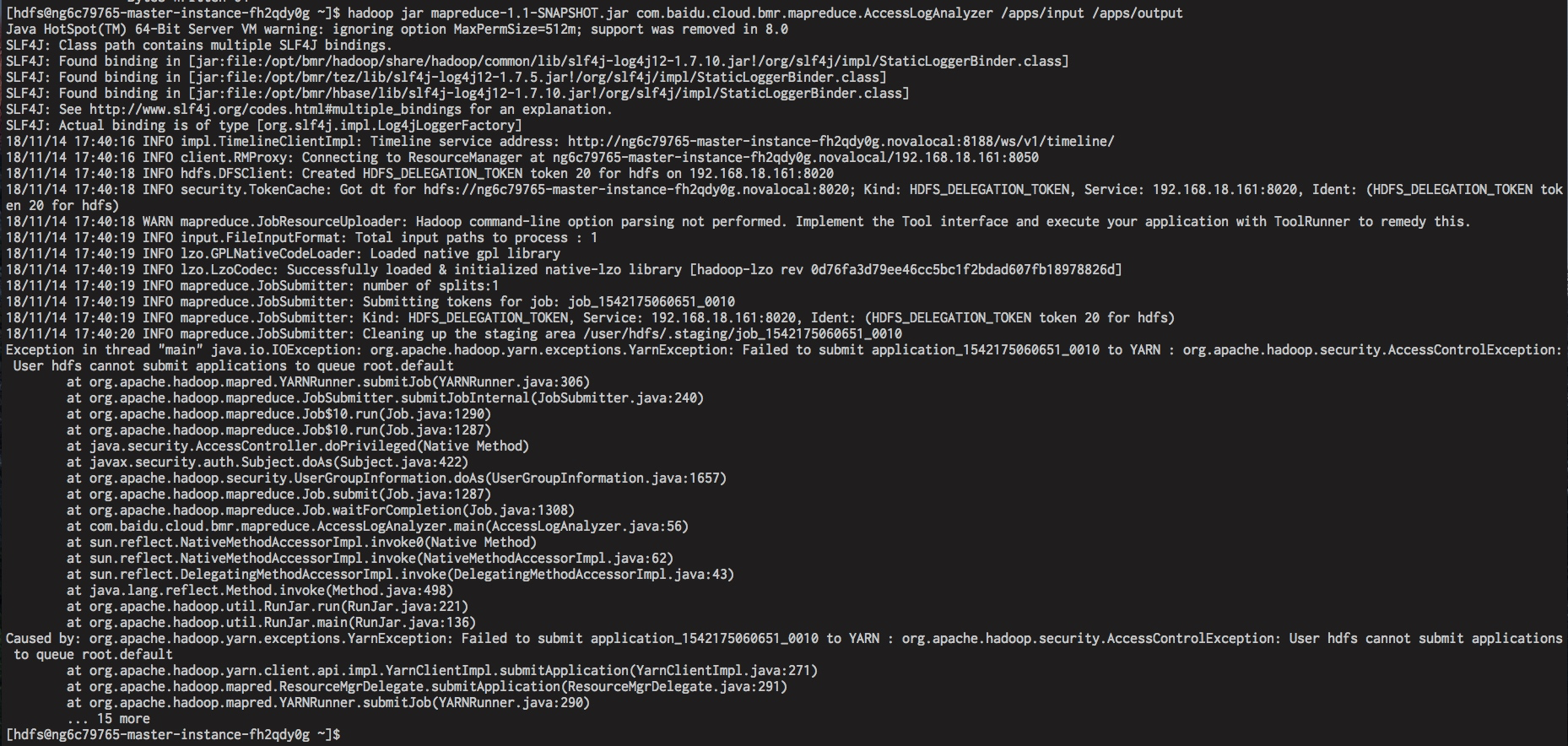
默认只有 yarn 服务账户可以提交作业到队列中,其他用户则无权限。例如 hdfs 提交作业时会出现以下异常:
下图演示了如何给 hdfs、bls 等账户授予 yarn 的 root.default 队列资源提交作业的权限。

当 hdfs 账户被授予权限后,等待片刻,就可以成功提交作业了,如下图所示: