

文档简介:



操作场景
操作步骤
购买实例
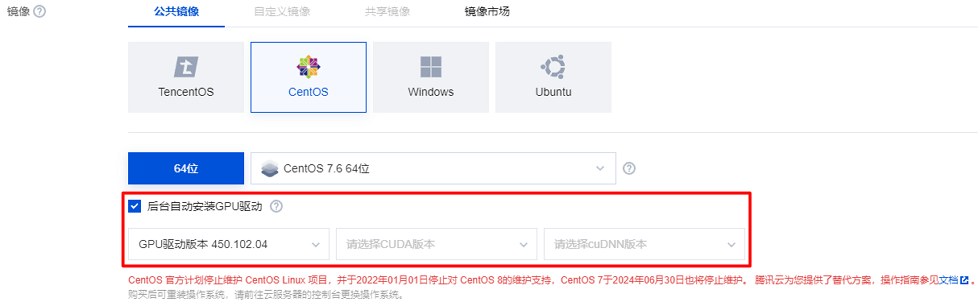
配置实例环境
验证 GPU 驱动
nvidia-smi
配置 HARP 分布式训练环境
ls /usr/local/tfabric/tools/config/ztcp*.conf
安装 docker 和 nvidia docker
curl -s -L http://mirrors.tencent.com/install/GPU/taco/get-docker.sh | sudo bash
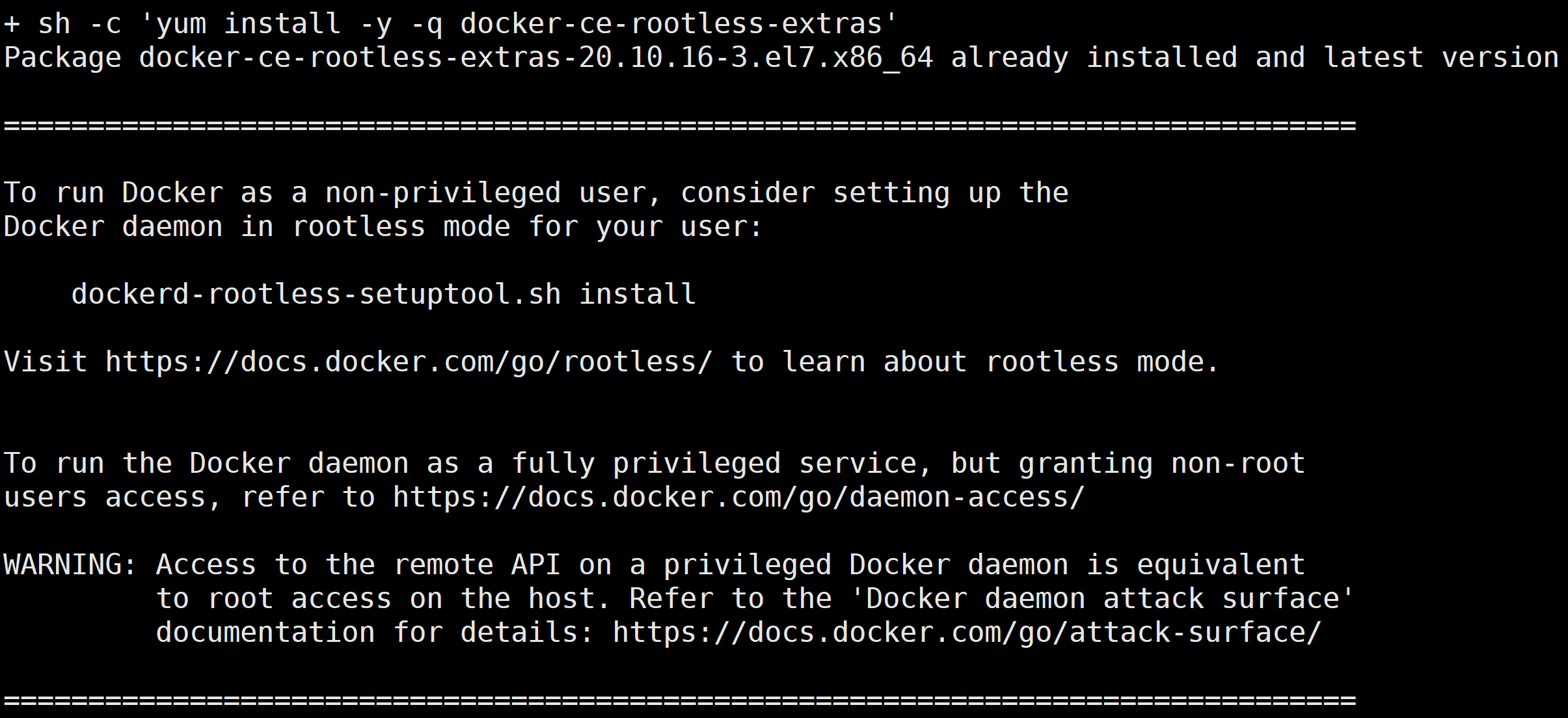
curl -s -L http://mirrors.tencent.com/install/GPU/taco/get-nvidia-docker2.sh | sudo bash
下载 docker 镜像
docker pull ccr.ccs.tencentyun.com/qcloud/taco-train:ttf115-cu112-cvm-0.4.1
启动 docker 镜像
docker run -it --rm --gpus all --privileged --net=host -v /sys:/sys -v
/dev/hugepages:/dev/hugepages -v /usr/local/tfabric/tools:/usr/local
/tfabric/tools ccr.ccs.tencentyun.com/qcloud/taco-train:ttf115-cu112-cvm-0.4.1
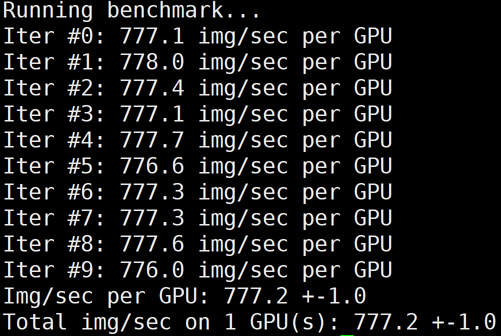
分布式训练 benchmark 测试
/usr/local/openmpi/bin/mpirun -np 1 --allow-run-as-root -bind-to none -map-by
slot -x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH -mca btl_tcp_if_include eth0
python3 /mnt/tensorflow_synthetic_benchmark.py --model=ResNet50 --batch-size=256
/usr/local/openmpi/bin/mpirun -np 8 --allow-run-as-root -bind-to none -map-by slot
-x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH -mca btl_tcp_if_include eth0 python3
/mnt/tensorflow_synthetic_benchmark.py --model=ResNet50 --batch-size=256
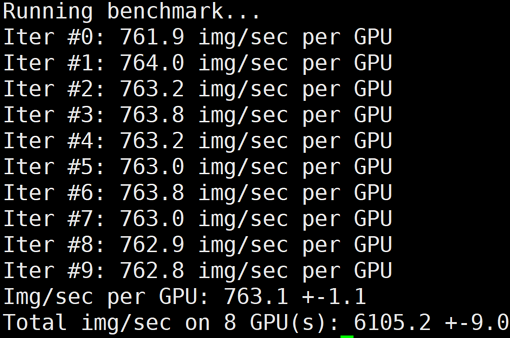
/usr/local/openmpi/bin/mpirun -np 8 --allow-run-as-root -bind-to none -map-by slot
-x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH -mca btl_tcp_if_include eth0 python3
/mnt/tensorflow_synthetic_benchmark.py --model=ResNet50 --batch-size=256
|
环境变量
|
默认值
|
说明
|
|
LIGHT_2D_ALLREDUCE
|
0
|
是否使用2D-Allreduce 算法
|
|
LIGHT_INTRA_SIZE
|
8
|
2D-Allreduce 组内 GPU 数
|
|
LIGHT_HIERARCHICAL_THRESHOLD
|
1073741824
|
2D-Allreduce 的阈值,单位是字节,小于等于该阈值的数据才使用2D-Allreduce
|
|
LIGHT_TOPK_ALLREDUCE
|
0
|
是否使用 TOPK 压缩通信
|
|
LIGHT_TOPK_RATIO
|
0.01
|
使用 TOPK 压缩的比例
|
|
LIGHT_TOPK_THRESHOLD
|
1048576
|
TOPK 压缩的阈值,单位是字节,大于等于该阈值的数据才使用 TOPK 压缩通信
|
|
LIGHT_TOPK_FP16
|
0
|
压缩通信的 value 是否转成 FP16
|
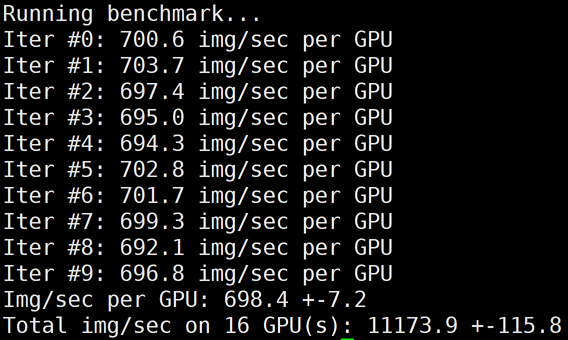
# 修改环境变量,使用Horovod进行多机Allreduce/usr/local/openmpi/bin/mpirun -np 16 -H gpu1:8,gpu2:8 --allow-run-as-root -bind-to none
-map-by slot -x NCCL_ALGO=RING -x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH -mca
btl_tcp_if_include eth0 python3 /mnt/tensorflow_synthetic_benchmark.py --model=ResNet50 --batch-size=256
# 将HARP加速库rename为bak.libnccl-net.so即可关闭HARP加速。/usr/local/openmpi/bin/mpirun -np 2 -H gpu1:1,gpu2:1 --allow-run-as-root -bind-to none
-map-by slot mv /usr/lib/x86_64-linux-gnu/libnccl-net.so /usr/lib/x86_64-linux-gnu/bak.libnccl-net.so
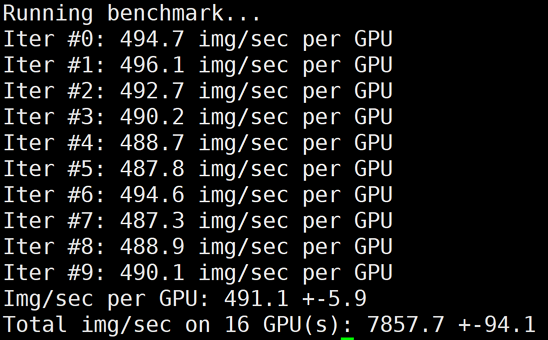
# 修改环境变量,使用Horovod进行多机Allreduce/usr/local/openmpi/bin/mpirun -np 16 -H gpu1:8,gpu2:8 --allow-run-as-root -bind-to none
-map-by slot -x NCCL_ALGO=RING -x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH -mca btl_tcp_i
f_include eth0 python3 /mnt/tensorflow_synthetic_benchmark.py --model=ResNet50 --batch-size=256
总结
|
机器:GT4(A100 * 8)+ 50G VPC
容器:ccr.ccs.tencentyun.com/qcloud/taco-train:ttf115-cu112-cvm-0.4.1
网络模型:ResNet50Batch:256
数据:synthetic data
|
|
|
|
|
|
|
|
|
机型
|
#GPUs
|
Horovod+TCP
|
|
Horovod+HARP
|
|
LightCC+HARP
|
|
|
|
|
性能(img/sec)
|
线性加速比
|
性能(img/sec)
|
线性加速比
|
性能(img/sec)
|
线性加速比
|
|
GT4/A100
|
1
|
777
|
-
|
777
|
-
|
777
|
-
|
|
|
8
|
6105
|
98.21%
|
6105
|
98.21%
|
6105
|
98.21%
|
|
|
16
|
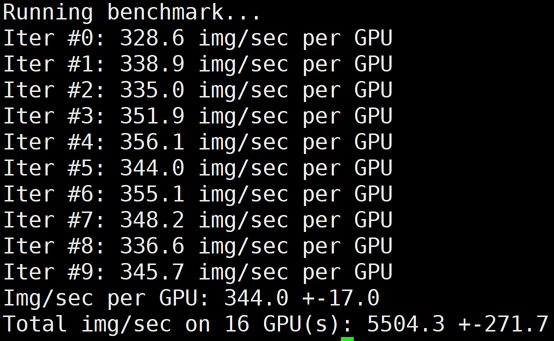
5504
|
44.27%
|
7857
|
63.20%
|
11173
|
89.87%
|
