文档简介:



操作场景
操作步骤
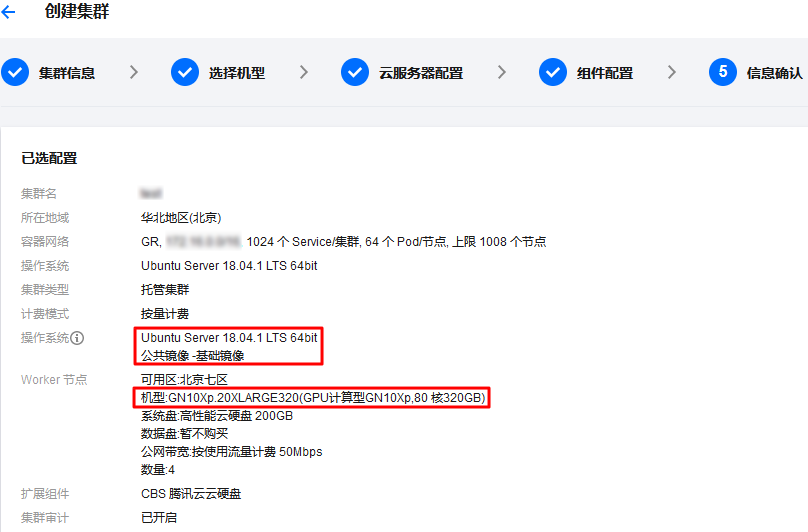
准备环境
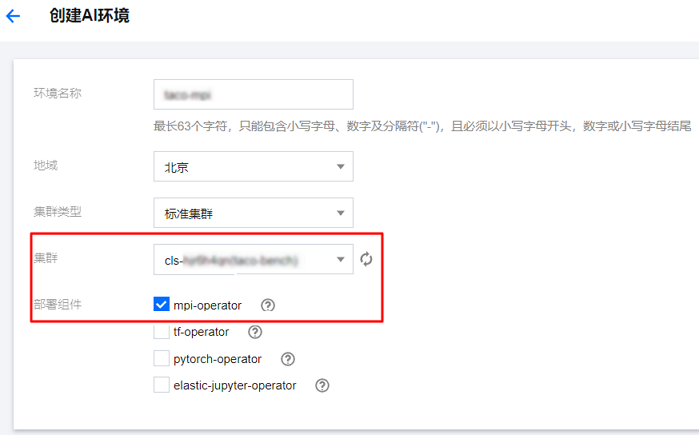
创建 Pod
apiVersion: kubeflow.org/v1kind: MPIJobmetadata:name: taco-benchspec:slotsPerWorker: 1runPolicy:cleanPodPolicy: RunningmpiReplicaSpecs:Launcher:replicas: 1template:spec:containers:- image: ccr.ccs.tencentyun.com/qcloud/taco-train:ttf115-cu112-cvm-0.4.1name: mpi-launchercommand: ["/bin/sh", "-ec", "sleep infinity"]resources:limits:cpu: 1memory: 2GiWorker:replicas: 4template:spec:containers:- image: ccr.ccs.tencentyun.com/qcloud/taco-train:ttf115-cu112-cvm-0.4.1name: mpi-workersecurityContext:privileged: truevolumeMounts:- mountPath: /sys/name: sys- mountPath: /dev/hugepagesname: dev-hge- mountPath: /usr/local/tfabric/toolsname: tfabricresources:limits:hugepages-1Gi: "50Gi"memory: "100Gi"nvidia.com/gpu: 8 # requesting 1 GPUvolumes:- name: syshostPath:path: /sys/- name: dev-hgehostPath:path: /dev/hugepages/- name: tfabrichostPath:path: /usr/local/tfabric/tools/
kubectl create -f taco.yaml
kubectl get pod
开始测试
kubectl exec -it taco-bench-launcher -- bash
/usr/local/openmpi/bin/mpirun -np 32 -H taco-bench-worker-0:8,taco-bench-worker-1:8,
taco-bench-worker-2:8,taco-bench-worker-3:8 --allow-run-as-root -bind-to none -map-by
slot -x NCCL_ALGO=RING -x NCCL_DEBUG=INFO -x HOROVOD_MPI_THREADS_DISABLE=1 -x HOROVOD_
FUSION_THRESHOLD=0 -x HOROVOD_CYCLE_TIME=0 -x LIGHT_2D_ALLREDUCE=1 -x LIGHT_TOPK_ALLR
EDUCE=1 -x LIGHT_TOPK_THRESHOLD=2097152 -x LIGHT_INTRA_SIZE=8 -x LD_LIBRARY_PATH -x PATH
-mca btl_tcp_if_include eth0 python3 /mnt/tensorflow_synthetic_benchmark.py --model=VGG16
--batch-size=128
// 卸载HARP加速库for i in `kubectl get pods | grep worker | awk '{print $1}'`; do kubectl exec $i -- bash -c
'mv /usr/lib/x86_64-linux-gnu/libnccl-net.so /mnt/'; done
// 卸载LightCCfor i in `kubectl get pods | grep worker | awk '{print $1}'`; do kubectl exec $i
-- bash -c 'pip uninstall -y light-horovod;echo'; done
// 安装horovod(耗时8分钟左右)for i in `kubectl get pods | grep worker | awk '{print $1}'`; do kubectl exec $i
-- bash -c 'export PATH=/usr/local/openmpi/bin:$PATH;HOROVOD_WITH_MPI=1 HOROVOD_GPU
_OPERATIONS=NCCL HOROVOD_WITH_TENSORFLOW=1 HOROVOD_NCCL_LINK=SHARED pip3 install --no-cache-dir horovod==0.21.3'; done
// 检查确认所有的worker都已经成功horovodfor i in `kubectl get pods | grep worker | awk '{print $1}'`; do kubectl exec $i -- bash -c 'pip show horovod;echo'; done
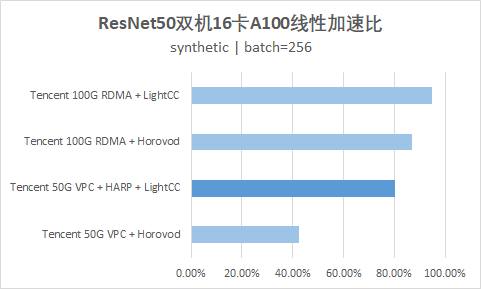
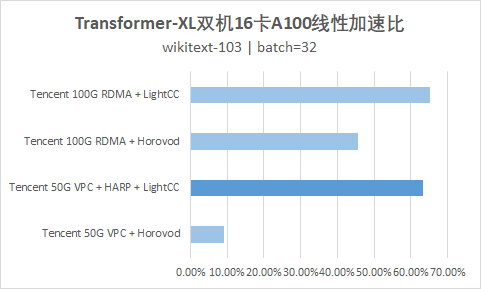
测试结果
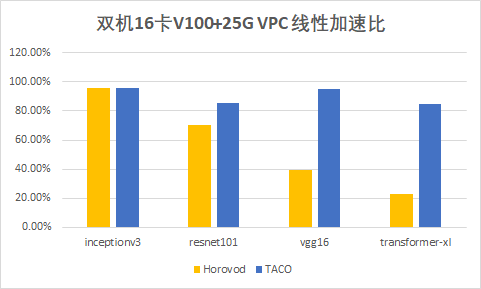
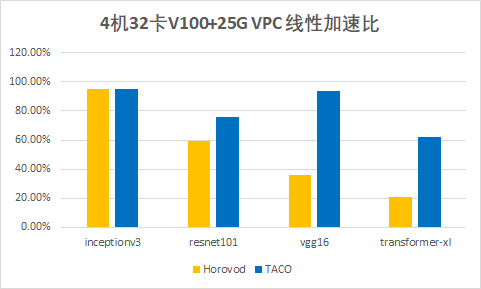 参数值如下:
参数值如下:
|
network
|
参数量(millions)
|
|
inceptionv3
|
25
|
|
resnet101
|
44
|
|
vgg16
|
138
|
|
transformer-xl
|
257
|