

文档简介:



操作场景
操作步骤
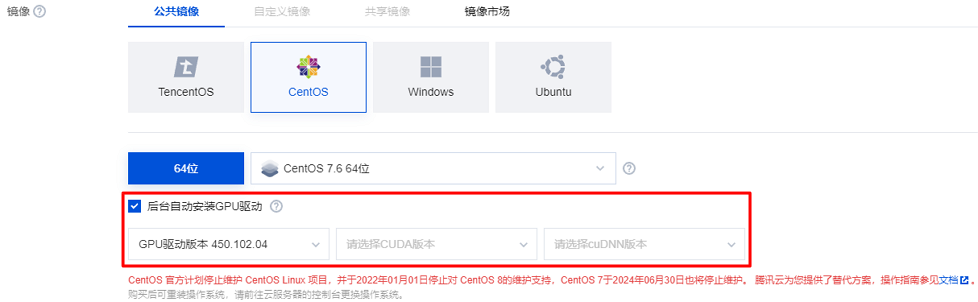
购买实例
安装 nv_peer_mem(可选)
git clone https://github.com/Mellanox/nv_peer_memory.gitcd ./nv_peer_memory/ && git checkout 1.0-9make && insmod ./nv_peer_mem.ko// 如果服务器发生了重启,nv_peer_mem驱动需要重新insmod
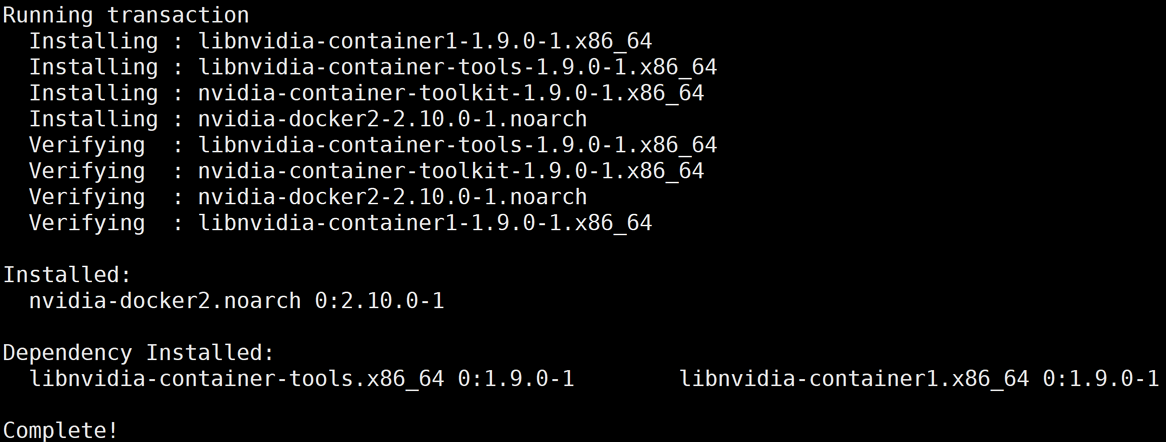
安装 docker 和 nvidia docker
curl -s -L http://mirrors.tencent.com/install/GPU/taco/get-docker.sh | sudo bash

curl -s -L http://mirrors.tencent.com/install/GPU/taco/get-nvidia-docker2.sh | sudo bash
下载 docker 镜像
docker pull ccr.ccs.tencentyun.com/qcloud/taco-train:ttf115-cu112-bm-0.4.2
启动 docker 镜像
docker run -itd --rm --gpus all --shm-size=32g --ulimit memlock=-1 --ulimit
stack=67108864 --net=host --privileged ccr.ccs.tencentyun.com/qcloud/taco-train:ttf115-cu112-bm-0.4.2
分布式训练 benchmark 测试
/usr/local/openmpi/bin/mpirun -np 1 --allow-run-as-root -bind-to none -map-by slot
-x NCCL_DEBUG=INFO -x NCCL_IB_DISABLE=0 -x NCCL_SOCKET_IFNAME=bond0 -x NCCL_IB_GID_IND
EX=3 -x NCCL_NET_GDR_LEVEL=0 -x LD_LIBRARY_PATH -x PATH -mca pml ob1 -mca btl_tcp_if_incl
ude bond0 -mca btl ^openib python3 /mnt/tensorflow_synthetic_benchmark.py --model=ResNet50 --batch-size=256
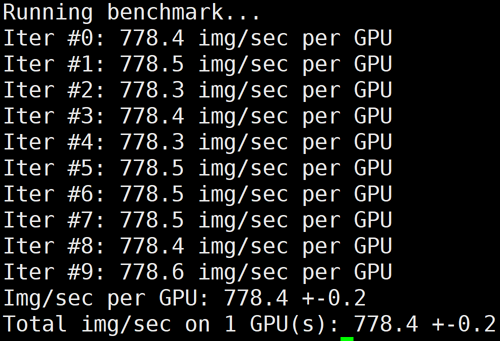
/usr/local/openmpi/bin/mpirun -np 8 --allow-run-as-root -bind-to none -map-by slot
-x NCCL_DEBUG=INFO -x NCCL_IB_DISABLE=0 -x NCCL_SOCKET_IFNAME=bond0 -x NCCL_IB_GID_
INDEX=3 -x NCCL_NET_GDR_LEVEL=0 -x LD_LIBRARY_PATH -x PATH -mca pml ob1 -mca btl_tcp
_if_include bond0 -mca btl ^openib python3 /mnt/tensorflow_synthetic_benchmark.py
--model=ResNet50 --batch-size=256

/usr/local/openmpi/bin/mpirun -np 16 -H gpu1:8,gpu2:8 --allow-run-as-root -bind-to none
-map-by slot -x NCCL_DEBUG=INFO -x NCCL_IB_DISABLE=0 -x NCCL_SOCKET_IFNAME=bond0 -x NCCL
_IB_GID_INDEX=3 -x NCCL_NET_GDR_LEVEL=0 -x HOROVOD_FUSION_THRESHOLD=0 -x HOROVOD_CYCLE_TIME=
0 -x LIGHT_INTRA_SIZE=8 -x LIGHT_2D_ALLREDUCE=1 -x LIGHT_TOPK_ALLREDUCE=1 -x LIGHT_TOPK_THRE
SHOLD=2097152 -x LD_LIBRARY_PATH -x PATH -mca pml ob1 -mca btl_tcp_if_include bond0 -mca btl
^openib python3 /mnt/tensorflow_synthetic_benchmark.py --model=ResNet50 --batch-size=256

|
环境变量
|
默认值
|
说明
|
|
LIGHT_2D_ALLREDUCE
|
0
|
是否使用2D-Allreduce 算法
|
|
LIGHT_INTRA_SIZE
|
8
|
2D-Allreduce 组内 GPU 数
|
|
LIGHT_HIERARCHICAL_THRESHOLD
|
1073741824
|
2D-Allreduce 的阈值,单位是字节,小于等于该阈值的数据才使用2D-Allreduce
|
|
LIGHT_TOPK_ALLREDUCE
|
0
|
是否使用 TOPK 压缩通信
|
|
LIGHT_TOPK_RATIO
|
0.01
|
使用 TOPK 压缩的比例
|
|
LIGHT_TOPK_THRESHOLD
|
1048576
|
TOPK 压缩的阈值,单位是字节,大于等于该阈值的数据才使用 TOPK 压缩通信
|
|
LIGHT_TOPK_FP16
|
0
|
压缩通信的 value 是否转成 FP16
|
# 去掉LIGHT_xx的环境变量,即可使用Horovod进行多机Allreduce/usr/local/openmpi/bin/mpirun -np 16 -H gpu1:8,gpu2:8 --allow-run-as-root -bind-to none -map
-by slot -x NCCL_DEBUG=INFO -x NCCL_IB_DISABLE=0 -x NCCL_SOCKET_IFNAME=bond0 -x NCCL_IB_GID_IND
EX=3 -x NCCL_NET_GDR_LEVEL=0 -x LD_LIBRARY_PATH -x PATH -mca pml ob1 -mca btl_tcp_if_include
bond0 -mca btl ^openib python3 /mnt/tensorflow_synthetic_benchmark.py --model=ResNet50 --batch-size=256
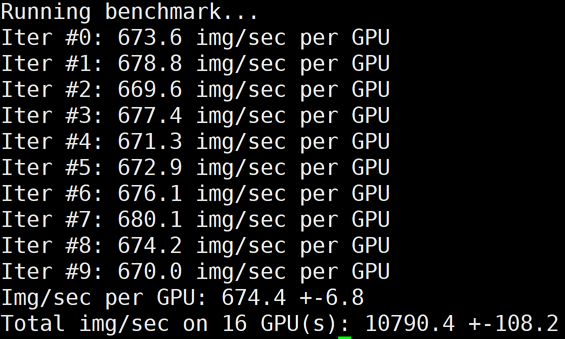
/usr/local/openmpi/bin/mpirun -np 16 -H gpu1:8,gpu2:8 --allow-run-as-root -bind-to none
-map-by slot -x NCCL_DEBUG=INFO -x NCCL_IB_DISABLE=0 -x NCCL_SOCKET_IFNAME=bond0 -x NCCL_IB
_GID_INDEX=3 -x NCCL_NET_GDR_LEVEL=2 -x HOROVOD_FUSION_THRESHOLD=0 -x HOROVOD_CYCLE_TIME=0 -x
LIGHT_INTRA_SIZE=8 -x LIGHT_2D_ALLREDUCE=1 -x LIGHT_TOPK_ALLREDUCE=1 -x LIGHT_TOPK_THRESHO
LD=2097152 -x LD_LIBRARY_PATH -x PATH -mca pml ob1 -mca btl_tcp_if_include bond0 -mca btl ^
openib python3 /mnt/tensorflow_synthetic_benchmark.py --model=ResNet50 --batch-size=256

总结
|
机器:HCCPNV4h(A100 * 8)+ 100G RDMA + 25G VPC
容器:ccr.ccs.tencentyun.com/qcloud/taco-train:ttf115-cu112-bm-0.4.2
网络模型:ResNet50Batch:256
数据:synthetic data
|
|
|
|
|
|
|
机型
|
#GPUs
|
Horovod+RDMA
|
|
LightCC+RDMA
|
|
|
|
|
性能(img/sec)
|
线性加速比
|
性能(img/sec)
|
线性加速比
|
|
HCCPNV4h A100
|
1
|
778
|
-
|
778
|
-
|
|
|
8
|
6104
|
98.07%
|
6104
|
98.07%
|
|
|
16
|
10790
|
86.68%
|
11779
|
94.63%
|
