
17 倍加速:PyTorch 模型的 GPU 优化剖析
|
IFX 是滴滴自研的 AI 推理引擎框架,针对云、端、边提供 AI 部署解决方案。目前,滴滴内部有很多 PyTorch 模型已经接入到 IFX 云端框架,并且通过 Serving 方式上线。 在模型从接入到上线的整个流程中,有一个必需的环节:在相同环境下评测 IFX 相比 PyTorch(1.3.1) 带来的性能收益。 下面这个图就是最近接入的几个模型的性能实测结果: 
这些模型大概分为两类:resnet 和 mobilenet。从上面结果可以看到 resnet 系列的(A、B、C、D)模型在适配到 IFX 框架之后性能提升大概在3-4倍,mobilenet 系列的(E、F)模型大概是17倍。 针对用户接入的E、F模型,IFX 相比 PyTorch 提升了 17 倍左右,为什么有这么大的优化空间呢,本文就来一步一步分析下。 ▎ 基础分析 E、F模型网络结构是 mobilenet-v3,这里是 mobilenet-v3模型介绍,可以看下模型主要的结构以及用途。从 PyTorch 导出的 onnx 模型中粗略估算了下,mobilenet-v3 包含约460个算子; 首先我们先分析一下 PyTorch 的实现,利用 nvprof 看到 PyTorch 的模型执行过程中调用了500+的算子,比460多的原因是 PyTorch 的 conv 算子实现中会额外调用一个数据处理算子。
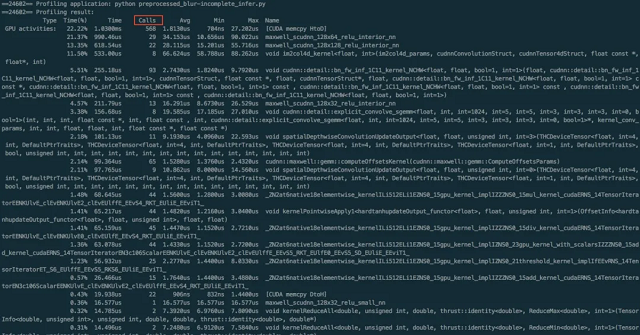
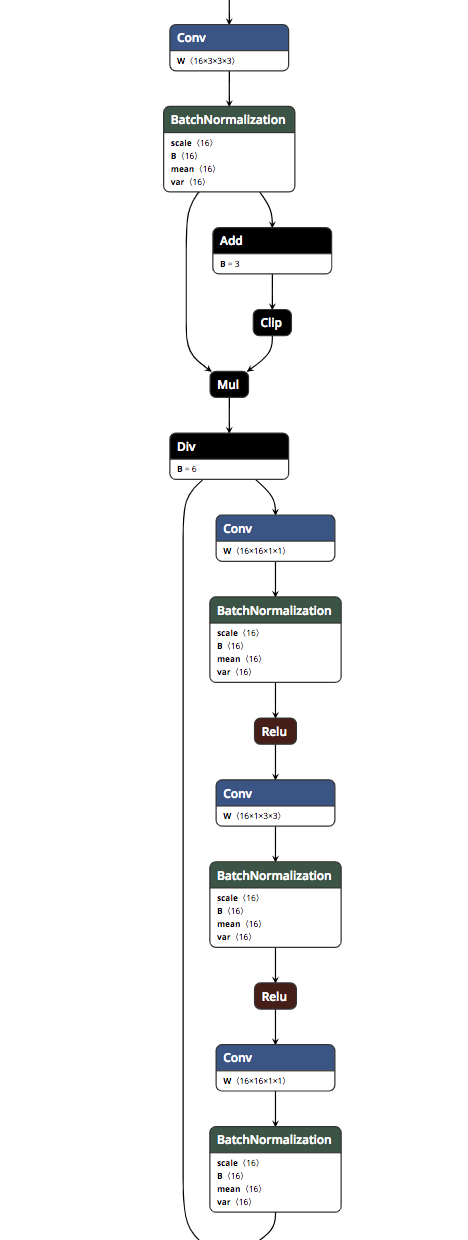
其 python 代码如下: class hswish(nn.Module): def forward(self, x): out = x * F.relu6(x + 3, inplace=True) / 6 return out class hsigmoid(nn.Module): def forward(self, x): out = F.relu6(x + 3, inplace=True) / 6 return out 在整个 mobilenet-v3 网络中,hswish 调用了31次,hsigmoid 调用了13次,这样相关的算子总数是31*4+13*3=163个,在模型中占比还是比较大的,而 PyTorch 的计算中没有对这部分做单独的优化实现,只是依次进行基础运算。 nvprof 测试结果如下:
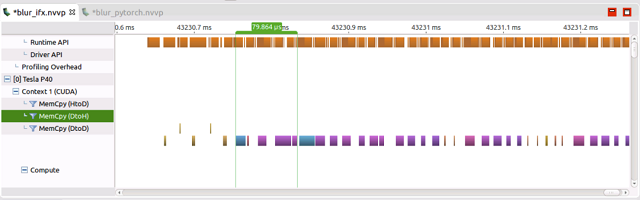
下面说一下 IFX 针对此模型的一个优化方法,由于 hswish、hsigmoid 这两个算子具有通用性,所以 IFX 将 hswish、hsigmoid 两个函数整合成了2个单独的算子,这样的融合操作降低了算子个数,同时优化过的算子相比原来性能更好。 具体看下测试结果:
其实这个 hswish 的融合操作只是 IFX fusion 策略中的一个,像 conv+elementwise、conv+bn+relu 这种常见的结构是可以 fusion 成一个 conv 的。 在所有 fusion 策略应用到 mobilenet-v3 之后,模型算子个数由原来的460降低为160,数量降低的同时算子性能还有提升。 下面展示 IFX 针对模型优化,带来的性能提升:
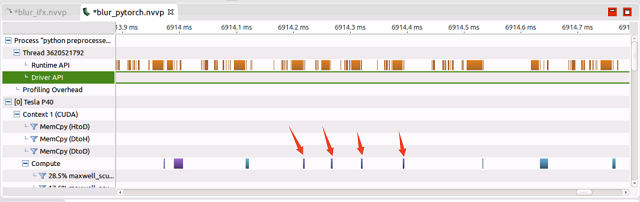
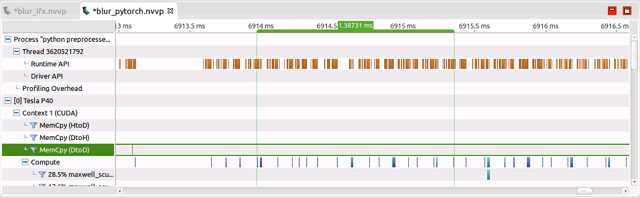
可以看到在只做了两个算子的融合+基础算子(Conv、Bn、Fc等)优化之后模型性能已经提升8倍左右,当把所有优化策略应用到模型之后,又有1倍+的性能提升。 算子数量优化掉这么多,为什么会产生这么大影响呢,需要理解的是所有的算子调用都需要从cpu 上 launch 到 GPU 上计算,这部分开销在 PyTorch 的实现里是很大的。 下面是针对子网络部分 nvprof 得到的结果:
再来看看 IFX 框架的算子调用:
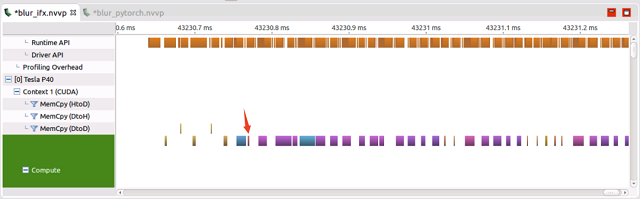
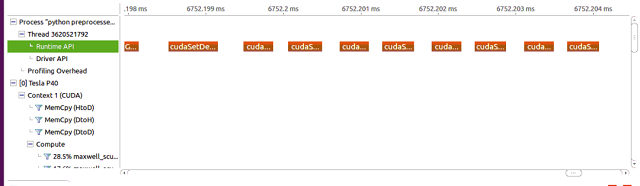
可以看到实现相同的子网络,IFX 5个算子大概的耗时是80us,其中计算的耗时在53ms,相比 PyTorch 计算效率更高。 这样测下来,针对典型子网络结构,IFX 快了 17 倍左右,和整体性能提升保持一致。测试过程和结果表明,PyTorch 慢是有道理的。 ▎拓展分析 接下来我们继续研究下 PyTorch 为什么在 kernel 执行之间调用那么多的 Cuda Runtime API,首先先看下调用的 API 究竟有哪些:
CudaGetDevice() 这两个 API。基于这个信息,我们可以查看下 PyTorch 源码中这两个 API 的调用点,最终定位到c10/cuda目录。 c10 目录是 PyTorch 最重要的源代码文件夹,也就是几乎所有的源代码都与这里的代码有关系,比如我们的类型定义,PyTorch Tensor 的内存分配方式等等,都在这个文件夹中。 cuda 子目录里面则实现了 GPU 相关的 Device、Stream、Tensor 的调度和管理。 通过查看该目录下的源码,看到 CudaSetDevice(),CudaGetDevice()这两个 api 在这些类中有调用:
有下面几种情况:
CudaSet/GetDevice API calls: import torch from torch.autograd import Variable x = Variable(torch.randn(100000).cuda()) for i in range(20): z = torch.sigmoid(x) ▎总结 PyTorch 的实现里确实是有一些 cuda 调用机制会直接或间接的带来很大开销。 除了这点之外,我们还可以从 nvprof 中看到在模型推理过程中 PyTorch 除了算子计算耗时、额外的 Runtime API 耗时之外还有很多空白的地方,这些其实是在执行 cpu 上的指令。那这个地方有没有优化空间呢?有的,大家可以分析下这部分耗时的原因。
▎推荐
滴滴云 GPU 云服务器 优惠:https://i.didiyun.com/296GrFzdE4H 阿里云 GPU 云服务器 优惠:https://www.shangyun51.com/productdetail?id=32 腾讯云 GPU 云服务器 优惠:https://www.shangyun51.com/productdetail?id=25 |




全部评论
暂无评论

有话要说