

文档简介:



Sqoop简介
本样例场景是:通过Sqoop将RDS上的数据导入Hive,Hive中的数据表的location为BOS路径,Hive数据表的partition为dt(string),根据dt指定日期,区分每一天的导入数据。
Sqoop是用来将Hadoop和关系型数据库中的数据相互转移的工具,可通过Hadoop的MapReduce将关系型数据库(MySQL、Oracle、Postgres等)中的数据导入到HDFS中,也可以将HDFS的数据导进到关系型数据库中。实现过程如下:
- 读取要导入数据的表结构,生成运行类,默认是QueryResult,打成jar包,然后提交给Hadoop。
-
Hadoop根据作业要求通过MapReduce来执行Import命令:
- 切分数据,即DataSplit。
- 写入范围,以便读取。
- 读取写入的范围。
- 创建RecordReader从数据库中读取数据。
- 创建Map。
- RecordReader一行一行从关系型数据库中读取数据,设置好Map的Key和Value,交给Map。
- 运行map。最后生成的Key是行数据。
Sqoop导入数据
您可通过sqoop把关系型数据库RDS中的数据导入到BOS、HDFS、HBase或Hive中。具体操作如下:
从RDS关系型数据库导入数据至BOS中
- 通过SSH连接到主节点,请参考SSH连接到集群。
- 输入命令:su hdfs。切换到HDFS用户。
-
执行以下格式的命令:sqoop import --connect jdbc:mysql://address:port/db_name --table table_name --username XX --password XX --target-dir XX
示例:sqoop import --connect jdbc:mysql://mysql56.rdsmiy5q77jfaqp.rds.bj.baidubce.com:3306/sqoop --table test --username sqoop --password sqoop_123 --target-dir bos://abc/sqooptest
- 执行后,可至bos中查看执行结果。BOS上查看执行结果的示例如下:
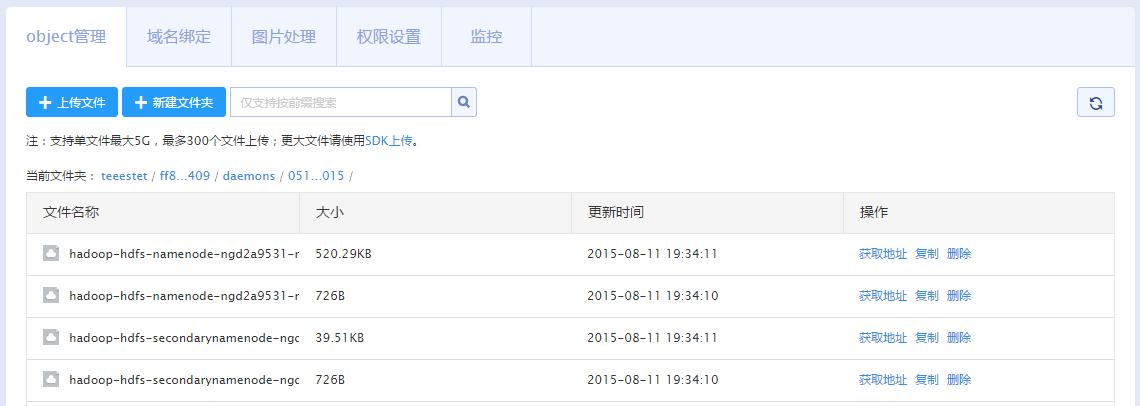
从RDS关系型数据库导入数据至HDFS中
- 执行从RDS关系型数据库导入数据至BOS中的步骤1至2。
-
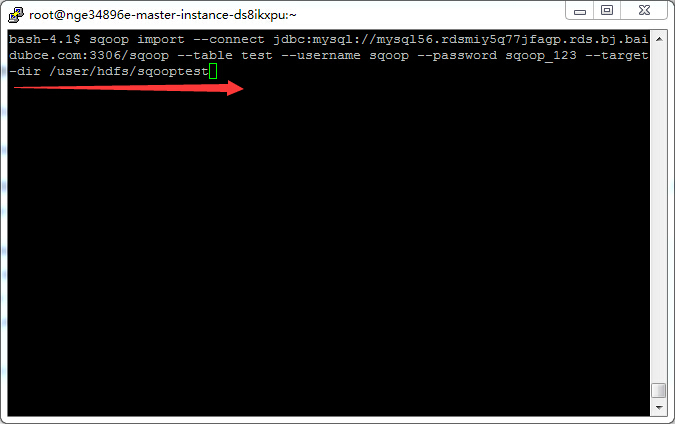
执行以下格式的命令:sqoop import --connect jdbc:mysql://address:port/db_name --table table_name --username XX --password XX --target-dir XX
示例:sqoop import --connect jdbc:mysql://mysql56.rdsmiy5q77jfaqp.rds.bj.baidubce.com:3306/sqoop --table test --username sqoop --password sqoop_123 --target-dir /user/hdfs/sqooptest
- 执行后,可至HDFS中查看执行结果。
| 参数 | 参数说明 |
|---|---|
| address和port | RDS数据库实例的地址和端口号。请至RDS实例的基本信息中获取,可参考连接RDS实例。 |
| db_name | 需导入数据所在数据库的名称。如需创建关系型数据库RDS实例,请参考创建数据库。 |
| table_name | 需导入数据的数据表的名称。如需创建数据表,请先登录到关系型数据库RDS实例中创建,请参考连接RDS实例。 |
| --username和--password | 需导入数据所在数据库的账号和密码。请至RDS实例中获取信息,请参考创建账号。 |
| --target-dir |
数据导入的目的地址,即BOS或HDFS的路径。 注意:若指定BOS路径,则路径中所指定的目录不能在bos上存在,例如,导入路径bos://test/sqooptest中的sqooptest目录在bos上必须不存在。 |
从RDS关系型数据库导入数据至HBase中
- 通过SSH连接到主节点,请参考SSH连接到集群。
- 输入命令:su hdfs。切换到HDFS用户。
-
Sqoop导入数据到HBase有两种情况:
- 导入数据到HBase已经存在的表中,执行以下格式的命令:sqoop import --connect jdbc:mysql://address:port/db_name --table table_name --username XX --password XX --hbase-table hbase_table_name --column-family hbase_column_family --hbase-row-key row_key。示例:sqoop import --connect jdbc:mysql://mysql56.rdsmiy5q77jfaqp.rds.bj.baidubce.com:3306/sqoop --table test --username sqoop --password sqoop_123 --hbase-table sqoop_hbase -- column-family message1 --habse-row-key id。
- 导入数据到HBase中不存在的表中,执行以下格式的命令:sqoop import --connect jdbc:mysql://address:port/db_name --table table_name --username XX --password XX --hbase-table hbase_table_name --column-family hbase_column_family --hbase-row-key row_key --hbase-create-table。示例:sqoop import --connect jdbc:mysql://mysql56.rdsmiy5q77jfaqp.rds.bj.baidubce.com:3306/sqoop --table test --username sqoop --password sqoop_123 --hbase-table sqoop_hbase -- column-family message1 --habse-row-key id --hbase-create-table。
-
执行后,可至HBase中查看执行结果,执行结果示例如下:
hbase(main):003:0>scan "sqoop_hbase" ROW COLUMN+CELL 1 column=message1:address,timestamp=1439794756361,value=shanghai 1 column=message1:favor,timestamp=1439794756361,value=lanqiu 1 column=message1:name,timestamp=1439794756361,value=xiaoming 1 column=message1:sex,timestamp=1439794756361,value=1 1 column=message1:address,timestamp=1439794756361,value=beijing 1 column=message1:favor,timestamp=1439794756361,value=pingpong 1 column=message1:name,timestamp=1439794756361,value=xiaohong 1 column=message1:sex,timestamp=1439794756361,value=2
| 参数 | 参数说明 |
|---|---|
| address和port | RDS数据库实例的地址和端口号。请至RDS实例的基本信息中获取,可参考连接RDS实例。 |
| db_name | 数据源所在数据库的名称。如需创建关系型数据库RDS实例,请参考创建数据库。 |
| table_name | 数据源在所数据表的名称。如需创建数据表,请先登录到关系型数据库RDS实例中创建,请参考连接RDS实例。 |
| --username和--password | 数据源所在数据库的账号和密码。请至RDS实例中获取信息,请参考创建账号。 |
| --hbase-table | 数据导入的目的数据表的表名,即HBase中数据表的表名。 |
| --column-family |
目的数据表的列簇,即HBase中数据表的列簇。 注意:sqoop一次只能指定一个列簇。 |
| --hbase-row-key | 数据源所在RDS数据表中作为hbase row key的字段。 |
从RDS关系型数据库导入数据至Hive中
- 通过SSH连接到主节点,请参考SSH连接到集群。
- 输入命令:su hdfs。切换到HDFS用户。
-
Sqoop导入数据到Hive有三种情况:
- Hive中不存在与关系型数据库RDS同名的数据表,执行以下格式的命令:sqoop import --connect jdbc:mysql://address:port/db_name --table table_name --username XX --password XX --hive-import。示例:示例:sqoop import --connect jdbc:mysql://mysql56.rdsmiy5q77jfaqp.rds.bj.baidubce.com:3306/sqoop --table test --username sqoop --password sqoop_123 --hive-import。
- 默认情况下,sqoop会将hive中的表名设定为导入数据的数据表名,如不想使用默认表名,使用--hive-table指定新数据表,执行以下格式的命令:sqoop import --connect jdbc:mysql://address:port/db_name --table table_name --username XX --password XX --hive-import --hive-table XX。示例:sqoop import --connect jdbc:mysql://mysql56.rdsmiy5q77jfaqp.rds.bj.baidubce.com:3306/sqoop --table test --username sqoop --password sqoop_123 --hive-import --hive-table sqoop_hive。
- Hive中存在与关系型数据库RDS同名的数据表,需要通过--hive-table指定数据表,并且加上--hive-overwrite参数,执行以下格式的命令:sqoop import --connect jdbc:mysql://address:port/db_name --table table_name --username XX --password XX --hive-import --hive-table XX --hive-overwrite。使用RDS数据库中的另一张表test_export,指定hive中已经存在的表sqoop_hive。示例:sqoop import --connect jdbc:mysql://mysql56.rdsmiy5q77jfaqp.rds.bj.baidubce.com:3306/sqoop --table test --username sqoop --password sqoop_123 --hive-import --hive-table sqoop_hive -- hive-overwirte。
-
执行后,可至Hive中查看执行结果,执行结果示例如下:
hive>select * from test; OK 1 xiaoming 1 shanghai lanqiu 2 xiaohong 2 beijing pingpong
| 参数 | 参数说明 |
|---|---|
| address和port | RDS数据库实例的地址和端口号。请至RDS实例的基本信息中获取,可参考连接RDS实例。 |
| db_name | 数据源所在数据库的名称。如需创建关系型数据库RDS实例,请参考创建数据库。 |
| table_name | 数据源在所数据表的名称。如需创建数据表,请先登录到关系型数据库RDS实例中创建,请参考连接RDS实例。 |
| --username和--password | 数据源所在数据库的账号和密码。请至RDS实例中获取信息,请参考创建账号。 |
| --hive-import | 导入数据至hive中。 |
| --hive-table | 数据导入的目的数据表的表名,即Hive中数据表的表名。 |
| --hive-overwrite | 覆盖Hive中与关系型数据库RDS同名的数据表。注意:如果将非INT类型转换为INT类型,导入数据可能不正确。 |
Sqoop导出数据
您可通过Sqoop把BOS或HDFS的数据导出至关系型数据库RDS中。具体操作如下:
从BOS中导出数据至RDS关系型数据库
1.在关系型数据库RDS中创建相应的数据表,请注意数据表字段类型与导出数据需要一致,否则在导出过程中可能出现异常。数据需要连接到RDS数据库进行创建,请参考连接RDS实例。
- 通过SSH连接到主节点,请参考SSH连接到集群。
- 输入命令:su hdfs。切换到HDFS用户。
- 执行命令:sqoop export --connect jdbc:mysql://address:port/db_name --table export_table_name --username XX --password XX --export-dir XX
示例:sqoop export --connect jdbc:mysql://mysql56.rdsmiy5q77jfaqp.rds.bj.baidubce.com:3306/sqoop --table test --username sqoop --password sqoop_123 --export-dir bos://abc/sqooptest
5.执行后,在RDS关系数据库PHP Admin界面可以看到执行结果,如下图所示:
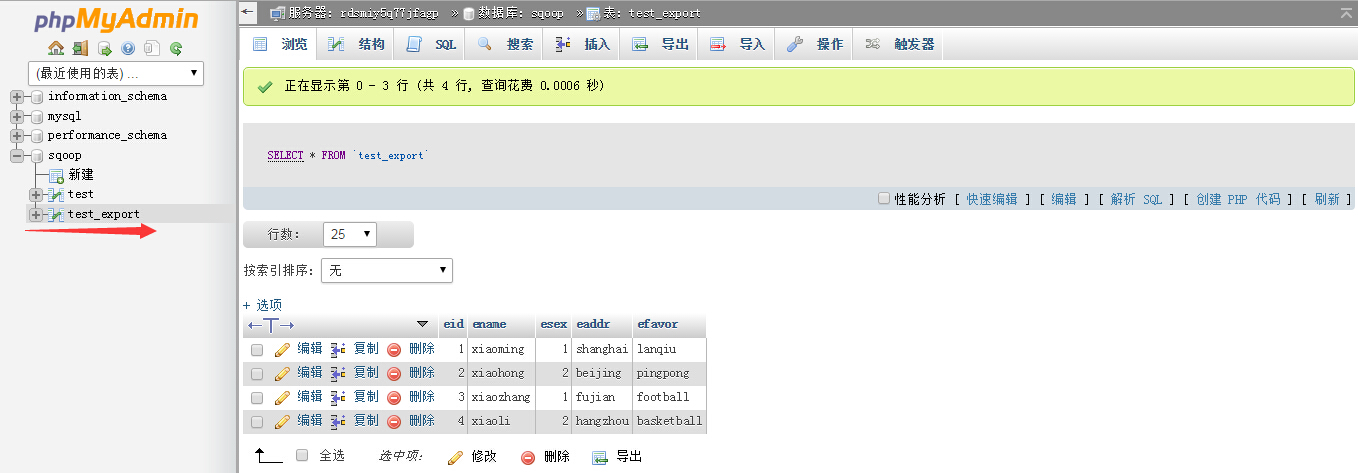
从HDFS中导出数据至RDS关系型数据库
1.执行从BOS中导出数据至RDS关系型数据库的步骤1至3。 2.执行命令:sqoop export --connect jdbc:mysql://address:port/db_name --table export_table_name --username XX --password XX --export-dir XX
示例:sqoop import --connect jdbc:mysql://mysql56.rdsmiy5q77jfaqp.rds.bj.baidubce.com:3306/sqoop --table test --username sqoop --password sqoop_123 --export-dir /user/hdfs/sqooptest
3.执行从BOS中导出数据至RDS关系型数据库的步骤5。
| 参数 | 参数说明 |
|---|---|
| address和port | RDS数据库实例的地址和端口号。请至RDS实例的基本信息中获取,可参考连接RDS实例。 |
| db_name | 需导出数据所在数据库的名称。如需创建关系型数据库RDS实例,请参考创建数据库。 |
| table_name | 需导出数据的数据表的名称。如需创建数据表,请先登录到关系型数据库RDS实例中创建,请参考连接RDS实例。 |
| --username和--password | 需导出数据所在数据库的账号和密码。请至RDS实例中获取信息,请参考创建账号。 |
| --export-dir | 数据导出的目的地址,即BOS或HDFS的路径。 |
