

文档简介:



简介
本文档介绍EasyEdge/EasyDL的Jetson SDK的使用方法。Jetson SDK支持的硬件包括Jetson nano,Jetson TX2,Jetson AGX Xavier和Jetson Xavier NX。您可在AI市场了解Jetson相关系列产品,同时可以在软硬一体方案了解部署方案。
模型支持:
- EasyDL图像:图像分类高精度,图像分类高性能,物体检测高精度,物体检测均衡,物体检测高性能,目标跟踪单标签模型。
-
BML:
- 公开数据集预训练模型:SSD-MobileNetV1,YOLOv3-DarkNet,YOLOv3-MobileNetV1,ResNet50,ResNet101,SE-ResNeXt50,SE-ResNeXt101,MobileNetV2,EfficientNetB0_small,EfficientNetB4,MobileNetV3_large_x1_0,ResNet18_vd,SE_ResNet18_vd,Xception71。
- 百度超大规模数据集预训练模型:YOLOv3-DarkNet,MobileNetV3_large_x1_0,ResNet50_vd,ResNet101_vd。
- EasyEdge:EasyEdge支持的模型较多,详见查看模型网络适配硬件。若模型不在此列表,可以尝试使用自定义网络生成端计算组件。
软件版本支持
使用EasyDL的Jetson系列SDK需要安装指定版本的JetPack和相关组件。所支持的JetPack版本会随着SDK版本的升级和新版本JetPack的推出而不断的更新。在使用SDK前请务必保证软件版本满足此处声明版本。目前所支持的JetPack版本包括:
- JetPack4.4
- JetPack4.2.2
安装JetPack时请务必安装对应的组件:
- 使用SDK Manager安装JetPack需要勾选TensorRT、OpenCV、CUDA、cuDNN等选项。
- 使用SD Card Image方式(仅对Jetson Nano和Jetson Xavier NX有效)则无需关心组件问题,默认会全部安装。
Release Notes
| 时间 | 版本 | 说明 |
|---|---|---|
| 2021.06.29 | 1.3.1 | 视频流支持分辨率调整;支持将预测后的视频推流,新增推流demo |
| 2021.05.13 | 1.3.0 | 新增视频流接入支持;EasyDL模型发布新增多种加速方案选择;目标追踪支持x86平台的CPU、GPU加速版;展示已发布模型性能评估报告 |
| 2021.03.09 | 1.2.1 | EasyEdge新增一系列模型的支持;性能优化 |
| 2021.01.27 | 1.1.0 |
EasyDL经典版高性能分类模型升级; EasyDL经典版检测模型新增均衡选项; EasyEdge平台新增Jetson系列端计算组件的生成; 问题修复 |
| 2020.12.18 | 1.0.0 | 接口升级和一些性能优化 |
| 2020.08.11 | 0.5.5 | 部分模型预测速度提升 |
| 2020.06.23 | 0.5.4 | 支持JetPack4.4DP,支持EasyDL专业版更多模型 |
| 2020.05.15 | 0.5.3 | 专项硬件适配SDK支持Jetson系列 |
2020-12-18: 【接口升级】 参数配置接口从1.0.0版本开始已升级为新接口,以前的方式被置为deprecated,并将在未来的版本中移除。请尽快考虑升级为新的接口方式,具体使用方式可以参考下文介绍以及demo工程示例,谢谢。
快速开始
安装依赖
本SDK适用于JetPack 4.2.2或JetPack4.4版本,请务必安装其中之一版本,并使用对应版本的SDK。 注意在安装JetPack时,需同时安装CUDA、cuDNN、OpenCV、TensorRT等组件。
如已安装JetPack需要查询相关版本信息,请参考下文中的开发板信息查询与设置。
使用序列号激活
首先请在官网获取序列号。

将获取到的序列号填写到demo文件中或以参数形式传入。 
编译并运行Demo
模型资源文件默认已经打包在开发者下载的SDK包中。Demo工程直接编译即可运行。
编译运行:
cd src mkdir build && cd build
cmake .. make # make install 为可选,也可将lib所在路径添加为环境变量 sudo make install sudo ldconfig
./easyedge_batch_inference {模型RES文件夹} {测试图片路径或仅包含图片的文件夹路径} {序列号}
demo运行示例:
baidu@nano:~/ljay/easydl/sdk/demo/build$ ./easyedge_batch_inference ../../../../RES/ /ljay/images/mix008.jpeg
2020-08-06 20:56:30,665 INFO [EasyEdge] 548125646864 Compiling model for fast inference, this may take
a while (Acceleration) 2020-08-06 20:57:58,427 INFO [EasyEdge] 548125646864 Optimized model saved
to: /home/baidu/.baidu/easyedge/jetson/mcache/24110044320/m_cache, Don't remove it Results of image /ljay/images/mix008.jpeg: 2, kiwi, p:0.997594 loc: 0.352087, 0.56119, 0.625748, 0.868399 2,
kiwi, p:0.993221 loc: 0.45789, 0.0730294, 0.73641, 0.399429 2, kiwi, p:0.992884 loc: 0.156876, 0.0598725,
0.3802, 0.394706 1, tomato, p:0.992125 loc: 0.523592, 0.389156, 0.657738, 0.548069 1, tomato, p:0.991821
loc: 0.665461, 0.419503, 0.805282, 0.573558 1, tomato, p:0.989883 loc: 0.297427, 0.439999, 0.432197,
0.59325 1, tomato, p:0.981654 loc: 0.383444, 0.248203, 0.506606, 0.400926 1, tomato, p:0.971682 loc:
0.183775, 0.556587, 0.286996, 0.711361 1, tomato, p:0.968722 loc: 0.379391, 0.0386965, 0.51672, 0.209681 Done
检测结果展示:

测试Demo HTTP 服务
编译demo完成之后,会同时生成一个http服务,运行
# ./easyedge_serving {res_dir} {serial_key} {host, default 0.0.0.0} {port, default 24401}
./easyedge_serving ../../../../RES "1111-1111-1111-1111" 0.0.0.0 24401
日志中会显示
HTTP is now serving at 0.0.0.0:24401
字样,此时,开发者可以打开浏览器,http://{设备ip}:24401,选择图片来进行测试。
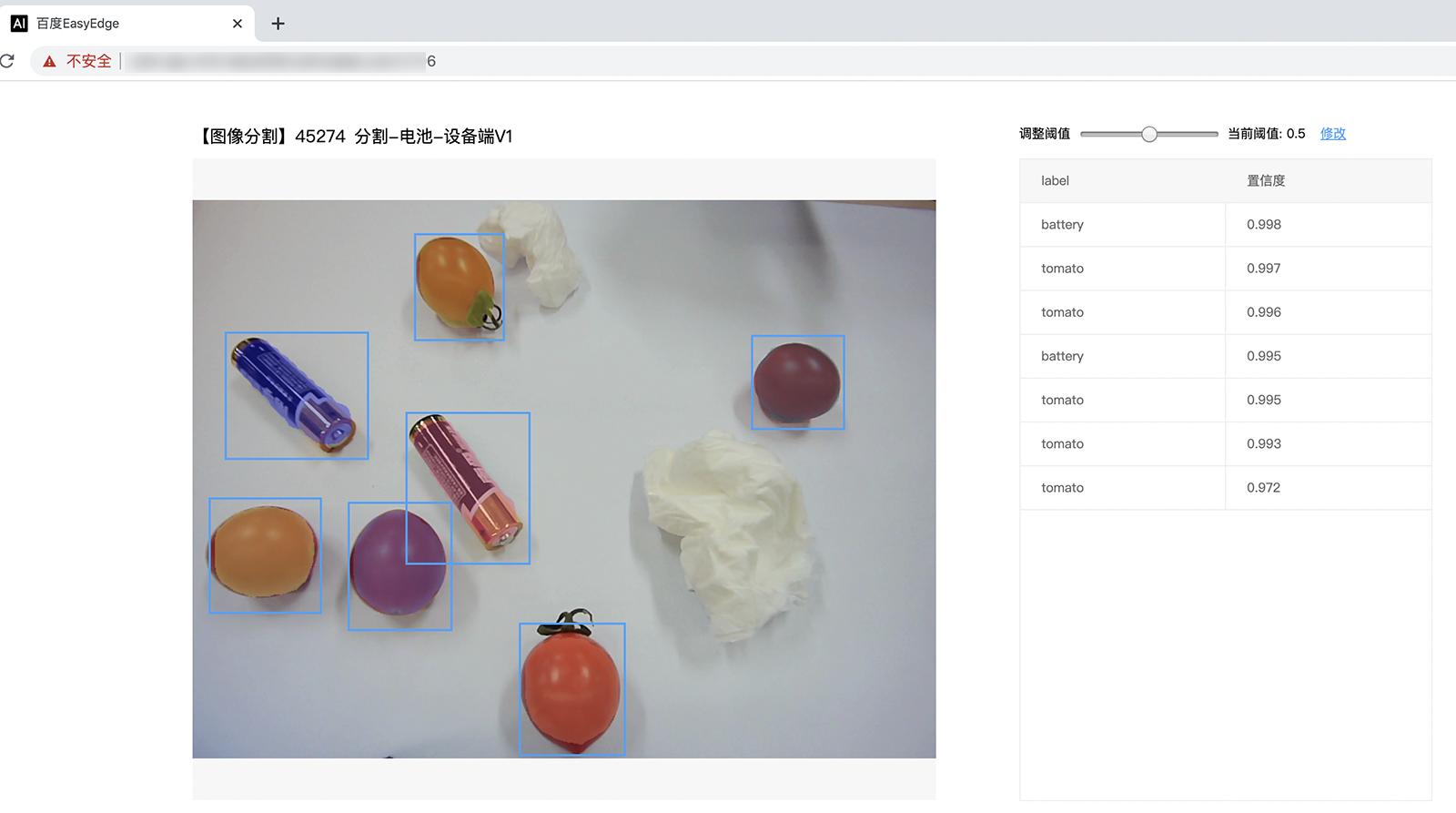
同时,可以调用HTTP接口来访问服务,具体参考下文接口说明。
使用说明
使用该方式,将运行库嵌入到开发者的程序当中。
使用流程
请优先参考Demo的使用流程。遇到错误,请优先参考文件中的注释解释,以及日志说明。
// step 1: 配置模型运行参数 EdgePredictorConfig config; config.model_dir = model_dir; config.set_config
(params::PREDICTOR_KEY_SERIAL_NUM, serial_num); config.set_config(params::PREDICTOR_KEY_GTURBO_MAX_BATCH_SIZE,
1); // 优化的模型可以支持的最大batch_size,实际单次推理的图片数不能大于此值 config.set_config(params:
:PREDICTOR_KEY_GTURBO_FP16, false); // 置true开启fp16模式推理会更快,精度会略微降低,但取决于硬件是否支持fp16,
不是所有模型都支持fp16,参阅文档 config.set_config(params::PREDICTOR_KEY_GTURBO_COMPILE_LEVEL, 1);
// 编译模型的策略,如果当前设置的max_batch_size与历史编译存储的不同,则重新编译模型
// step 2: 创建并初始化Predictor auto predictor = global_controller()->CreateEdgePredictor<EdgePredictorConfig>
(config); if (predictor->init() != EDGE_OK) { exit(-1); } // step 3-1: 预测图像
auto img = cv::imread({图片路径}); std::vector<EdgeResultData> results; predictor->infer(img, results);
// step 3-2: 预测视频 std::vector<EdgeResultData> results; FrameTensor frame_tensor; VideoConfig video_config;
video_config.source_type = static_cast<SourceType>(video_type); // source_type 定义参考头文件
easyedge_video.h video_config.source_value = video_src; /*
... more video_configs, 根据需要配置video_config的各选项 */ auto video_decoding = CreateVideoDecoding(video_config); while (video_decoding->next(frame_tensor)
== EDGE_OK) { results.clear(); if (frame_tensor.is_needed) { predictor->infer(frame_tensor.frame, results);
render(frame_tensor.frame, results, predictor->model_info().kind); } //video_decoding->display
(frame_tensor); // 显示当前frame,需在video_config中开启配置 //video_decoding->save(frame_tensor);
// 存储当前frame到视频,需在video_config中开启配置 }
初始化接口
auto predictor = global_controller()->CreateEdgePredictor<EdgePredictorConfig>(config);
if (predictor->init() != EDGE_OK) { exit(-1); }
若返回非0,请查看输出日志排查错误原因。
预测接口
/** * @brief * 单图预测接口 * @param image: must be BGR , HWC format (opencv default) * @param result * @return */ virtual int infer( cv::Mat& image, std::vector<EdgeResultData>& result ) = 0; /** * @brief * 批量图片预测接口 * @param image: must be BGR , HWC format (opencv default) * @param result * @return */ virtual int infer( std::vector<cv::Mat>& image, std::vector<std::vector<EdgeResultData>>& results ) = 0; /** * @brief * 批量图片预测接口,带阈值 * @related infer(cv::Mat & image, EdgeColorFormat origin_color_format, std::vector
&result, float threshold) */ virtual int infer( std::vector<cv::Mat> &images, EdgeColorFormat origin_color_format, std::vector<std:
:vector<EdgeResultData>> &results, float threshold ) = 0;
图片的格式务必为opencv默认的BGR, HWC格式。
批量图片的预测接口的使用要求在调用 init 接口的时候设置一个有效的 max_batch_size,其含义见下方参数配置接口的介绍。
参数配置接口
参数配置通过结构体EdgePredictorConfig完成。
struct EdgePredictorConfig {
/**
* @brief 模型资源文件夹路径
*/
std::string model_dir;
std::map conf;
EdgePredictorConfig();
templateT get_config(const std::string &key, const T &default_value);
templateT get_config(const std::string &key);
templateconst T *get_config(const std::string &key, const T *default_value);
templatevoid set_config(const std::string &key, const T &value);
templatevoid set_config(const std::string &key, const T *value);
static EdgePredictorConfig default_config();
};
运行参数选项的配置以key、value的方式存储在类型为std::map的conf中,并且键值对的设置和获取可以通过EdgePredictorConfig的set_config和get_config函数完成。同时也支持以环境变量的方式设置键值对。 EdgePredictorConfig的具体使用方法可以参考开发工具包中的demo工程。
针对Jetson开发工具包,目前EdgePredictorConfig的运行参数所支持的Key包括如下项:
/** * @brief 当有同类型的多个设备的时候,使用哪一个设备,如: * GPU: 使用哪张GPU卡 * EdgeBoard(VMX),Movidius NCS :使用哪一张加速卡 * 值类型:int * 默认值:0 */ static constexpr auto PREDICTOR_KEY_DEVICE_ID = "PREDICTOR_KEY_DEVICE_ID"; /** * @brief 生成最大 batch_size 为 max_batch_size 的优化模型,单次预测图片数量可以小于或等于此值 * 值类型: int * 默认值:4 */ static constexpr auto PREDICTOR_KEY_GTURBO_MAX_BATCH_SIZE = "PREDICTOR_KEY_GTURBO_MAX_BATCH_SIZE"; /** * @brief 设置device对应的GPU卡可以支持的最大并发量 * 实际预测的时候对应GPU卡的最大并发量不超过这里设置的范围,否则预测请求会排队等待预测执行 * 值类型: int * 默认值:1 */ static constexpr auto PREDICTOR_KEY_GTURBO_MAX_CONCURRENCY = "PREDICTOR_KEY_GTURBO_MAX_CONCURRENCY"; /** * @brief 是否开启fp16模式预测,开启后预测速度会更快,但精度会略有降低。并且需要硬件支持fp16 * 值类型: bool * 默认值:false */ static constexpr auto PREDICTOR_KEY_GTURBO_FP16 = "PREDICTOR_KEY_GTURBO_FP16"; /** * @brief 模型编译等级 * 1:如果当前max_batch_size与历史编译产出的max_batch_size不相等时,则重新编译模型(推荐) * 2:无论历史编译产出的max_batch_size为多少,均根据当前max_batch_size重新编译模型 * 值类型: int * 默认值:1 */ static constexpr auto PREDICTOR_KEY_GTURBO_COMPILE_LEVEL = "PREDICTOR_KEY_GTURBO_COMPILE_LEVEL"; /** * @brief GPU工作空间大小设置 * workspace_size = workspace_prefix * (1 << workspace_offset) * workspace_offset: 10 = KB, 20 = MB, 30 = GB
* 值类型: int * 默认值:WORKSPACE_PREFIX: 100, WORKSPACE_OFFSET: 20,即100MB */ static constexpr auto
PREDICTOR_KEY_GTURBO_WORKSPACE_PREFIX = "PREDICTOR_KEY_GTURBO_WORKSPACE_PREFIX";
static constexpr auto PREDICTOR_KEY_GTURBO_WORKSPACE_OFFSET = "PREDICTOR_KEY_GTURBO_WORKSPACE_OFFSET"; /** * @brief 需要使用的dla core * 值类型: int * 默认值:-1(不使用) */ static constexpr auto PREDICTOR_KEY_GTURBO_DLA_CORE = "PREDICTOR_KEY_GTURBO_DLA_CORE"; /** * @brief 自定义缓存文件命名,默认即可 * 值类型: string * 默认值: 根据配置自动生成 */ static constexpr auto PREDICTOR_KEY_GTURBO_CACHE_NAME = "PREDICTOR_KEY_GTURBO_CACHE_NAME"; /** * @brief 序列号设置;序列号不设置留空时,SDK将会自动尝试使用本地已经激活成功的有效期内的序列号 * 值类型:string * 默认值:空 */ static constexpr auto PREDICTOR_KEY_SERIAL_NUM = "PREDICTOR_KEY_SERIAL_NUM";
PREDICTOR_KEY_GTURBO_CACHE_NAME:首次加载模型会先对模型进行编译优化,通过此值可以设置优化后的产出文件名。
PREDICTOR_KEY_GTURBO_WORKSPACE_PREFIX、PREDICTOR_KEY_GTURBO_WORKSPACE_OFFSET:设置运行时可以被用来使用的最大临时显存。
PREDICTOR_KEY_GTURBO_MAX_BATCH_SIZE:此值用来控制批量图片预测可以支持的最大图片数,实际预测的时候单次预测图片数不可大于此值,但可以是不大于此值的任意图片数。
PREDICTOR_KEY_DEVICE_ID:设置需要使用的 GPU 卡号,对于Jetson,此值无需更改。
PREDICTOR_KEY_GTURBO_COMPILE_LEVEL:模型编译等级。通常模型的编译会比较慢,但编译产出是可以复用的。可以在第一次加载模型的时候设置合理的 max_batch_size 并在之后加载模型的时候直接使用历史编译产出。是否使用历史编译产出可以通过此值 compile_level 来控制,当此值为 0 时,表示忽略当前设置的 max_batch_size 而仅使用历史产出(无历史产出时则编译模型);当此值为 1 时,会比较历史产出和当前设置的 max_batch_size 是否相等,如不等,则重新编译;当此值为 2 时,无论如何都会重新编译模型。
PREDICTOR_KEY_GTURBO_MAX_CONCURRENCY:通过此值设置单张 GPU 卡上可以支持的最大 infer 并发量,其上限取决于硬件限制。init 接口会根据此值预分配 GPU 资源,建议结合实际使用控制此值,使用多少则设置多少。注意:此值的增加会降低单次 infer 的速度,建议优先考虑 batch inference。
PREDICTOR_KEY_GTURBO_FP16:默认是 fp32 模式,置 true 可以开启 fp16 模式预测,预测速度会有所提升,但精度也会略微下降,权衡使用。注意:不是所有模型都支持 fp16 模式,也不是所有硬件都支持 fp16 模式。已知不支持fp16的模型包括:EasyDL图像分类高精度模型。
预测视频接口
SDK 提供了支持摄像头读取、视频文件和网络视频流的解析工具类VideoDecoding,此类提供了获取视频帧数据的便利函数。通过VideoConfig结构体可以控制视频/摄像头的解析策略、抽帧策略、分辨率调整、结果视频存储等功能。对于抽取到的视频帧可以直接作为SDK infer 接口的参数进行预测。
classVideoDecoding:
/**
* @brief 获取输入源的下一帧
* @param frame_tensor
* @return
*/
virtual int next(FrameTensor &frame_tensor) = 0;
/**
* @brief 显示当前frame_tensor中的视频帧
* @param frame_tensor
* @return
*/
virtual int display(const FrameTensor &frame_tensor) = 0;
/**
* @brief 将当前frame_tensor中的视频帧写为本地视频文件
* @param frame_tensor
* @return
*/
virtual int save(FrameTensor &frame_tensor) = 0;
/**
* @brief 获取视频的fps属性
* @return
*/
virtual int get_fps() = 0;
/**
* @brief 获取视频的width属性
* @return
*/
virtual int get_width() = 0;
/**
* @brief 获取视频的height属性
* @return
*/
virtual int get_height() = 0;
struct VideoConfig
/**
* @brief 视频源、抽帧策略、存储策略的设置选项
*/
struct VideoConfig {
SourceType source_type; // 输入源类型
std::string source_value; // 输入源地址,如视频文件路径、摄像头index、网络流地址
int skip_frames{0}; // 设置跳帧,每隔skip_frames帧抽取一帧,并把该抽取帧的is_needed置为true
int retrieve_all{false}; // 是否抽取所有frame以便于作为显示和存储,对于不满足skip_frames策略的frame,
把所抽取帧的is_needed置为false
int input_fps{0}; // 在采取抽帧之前设置视频的fps
Resolution resolution{Resolution::kAuto}; // 采样分辨率,只对camera有效
bool enable_display{false};
std::string window_name{"EasyEdge"};
bool display_all{false}; // 是否显示所有frame,若为false,仅显示根据skip_frames抽取的frame
bool enable_save{false};
std::string save_path; // frame存储为视频文件的路径
bool save_all{false}; // 是否存储所有frame,若为false,仅存储根据skip_frames抽取的frame
std::map conf;
};
source_type:输入源类型,支持视频文件、摄像头、网络视频流三种,值分别为1、2、3。 source_value: 若source_type为视频文件,该值为指向视频文件的完整路径;若source_type为摄像头,该值为摄像头的index,如对于/dev/video0的摄像头,则index为0;若source_type为网络视频流,则为该视频流的完整地址。 skip_frames:设置跳帧,每隔skip_frames帧抽取一帧,并把该抽取帧的is_needed置为true,标记为is_needed的帧是用来做预测的帧。反之,直接跳过该帧,不经过预测。 retrieve_all:若置该项为true,则无论是否设置跳帧,所有的帧都会被抽取返回,以作为显示或存储用。 input_fps:用于抽帧前设置fps。 resolution:设置摄像头采样的分辨率,其值请参考easyedge_video.h中的定义,注意该分辨率调整仅对输入源为摄像头时有效。 conf:高级选项。部分配置会通过该map来设置。
注意:
- 如果使用VideoConfig的display功能,需要自行编译带有GTK选项的opencv,默认打包的opencv不包含此项。
- 使用摄像头抽帧时,如果通过resolution设置了分辨率调整,但是不起作用,请添加如下选项:
video_config.conf["backend"] = "2";
3.部分设备上的CSI摄像头尚未兼容,如遇到问题,可以通过工单、QQ交流群或微信交流群反馈。
具体接口调用流程,可以参考SDK中的demo_video_inference。
日志配置
设置 EdgeLogConfig 的相关参数。具体含义参考文件中的注释说明。
EdgeLogConfig log_config; log_config.enable_debug = true; global_controller()->set_log_config(log_config);
返回格式
预测成功后,从 EdgeResultData中可以获取对应的分类信息、位置信息。
struct EdgeResultData { int index; // 分类结果的index std::string label; // 分类结果的label float prob;
// 置信度 // 物体检测或图像分割时才有 float x1, y1, x2, y2; // (x1, y1): 左上角, (x2, y2): 右下角;
均为0~1的长宽比例值。 // 图像分割时才有 cv::Mat mask; // 0, 1 的mask std::string mask_rle
; // Run Length Encoding,游程编码的mask };
关于矩形坐标
x1 图片宽度 = 检测框的左上角的横坐标 y1 图片高度 = 检测框的左上角的纵坐标 x2 图片宽度 = 检测框的右下角的横坐标 y2 图片高度 = 检测框的右下角的纵坐标
以上字段可以参考demo文件中使用opencv绘制的逻辑进行解析
http服务
1. 开启http服务
http服务的启动参考demo_serving.cpp文件。
/** * @brief 开启一个简单的demo http服务。 * 该方法会block直到收到sigint/sigterm。 * http服务里,图片的解码运行在cpu之上,可能会降低推理速度。 * @tparam ConfigT * @param config * @param host * @param port * @param service_id service_id user parameter, uri '/get/service_id' will respond this value with 'text/plain' * @param instance_num 实例数量,根据内存/显存/时延要求调整 * @return */ template<typename ConfigT> int start_http_server( const ConfigT &config,
const std::string &host, int port, const std::string &service_id, int instance_num = 1);
2. 请求http服务
开发者可以打开浏览器,http://{设备ip}:24401,选择图片来进行测试。
URL中的get参数:
| 参数 | 说明 | 默认值 |
|---|---|---|
| threshold | 阈值过滤, 0~1 | 如不提供,则会使用模型的推荐阈值 |
HTTP POST Body即为图片的二进制内容(无需base64, 无需json)
Python请求示例
import requests with open('./1.jpg', 'rb') as f: img = f.read() result = requests.post
( 'http://127.0.0.1:24401/', params={'threshold': 0.1}, data=img).json()
Java请求示例参考这里
http 返回数据
| 字段 | 类型说明 | 其他 |
|---|---|---|
| error_code | Number | 0为成功,非0参考message获得具体错误信息 |
| results | Array | 内容为具体的识别结果。其中字段的具体含义请参考接口使用-返回格式一节 |
| cost_ms | Number | 预测耗时ms,不含网络交互时间 |
返回示例
{ "cost_ms": 52, "error_code": 0, "results": [ { "confidence": 0.94482421875, "index": 1, "label":
"IronMan", "x1": 0.059185408055782318, "x2": 0.18795496225357056, "y1": 0.14762254059314728,
"y2": 0.52510076761245728 }, { "confidence": 0.94091796875, "index": 1, "label": "IronMan",
"x1": 0.79151463508605957, "x2": 0.92310667037963867, "y1": 0.045728668570518494, "y2": 0.42920106649398804 } ] }
多线程预测
Jetson 系列 SDK 支持多线程预测,创建一个 predictor,并通过 PREDICTOR_KEY_GTURBO_MAX_CONCURRENCY 控制所支持的最大并发量,只需要 init 一次,多线程调用 infer 接口。需要注意的是多线程的启用会随着线程数的增加而降低单次 infer 的推理速度,建议优先使用 batch inference 或权衡考虑使用。
已知问题
1. 多线程时图片按线程分配不均 或 不同batch size的图片交叉调用infer接口时,部分结果错误
A:EasyDL图像分类高精度模型在有些显卡上可能存在此问题,可以考虑填充假图片数据到图片比较少的线程或batch以使得infer间的图片绝对平均。
2. 显存持续增长或遇到 terminate called after throwing an instance of 'std::runtime_error' what(): Failed to create object
A:如果遇到此问题,请确认没有频繁调用 init 接口,通常调用 infer 接口即可满足需求。
3. 开启 fp16 后,预测结果错误
A:不是所有模型都支持 fp16 模式。目前已知的不支持fp16的模型包括:EasyDL图像分类高精度模型。目前不支持的将会在后面的版本陆续支持。
4. 部分模型不支持序列化
A:针对JetPack4.4版本,部分模型无法使用序列化,如已知的BML的MobileNetV1-SSD和物体检测高性能模型。需要每次加载模型的时候编译模型,过程会比较慢。此问题将在后续JetPack版本中修复。
开发板信息查询与设置
查询L4T或JetPack版本
查询JetPack版本信息,可以通过下面这条命令先查询L4T的版本。
# 在终端输入如下命令并回车 $ head -n 1 /etc/nv_tegra_release # 就会输出类似如下结果 $ # # R32 (release),
REVISION: 4.3, GCID: 21589087, BOARD: t210ref, EABI: aarch64, DATE: Fri Jun 26 04:38:25 UTC 2020
从输出的结果来看,板子当前的L4T版本为R32.4.3,对应JetPack4.4。 注意,L4T的版本不是JetPack的版本,一般可以从L4T的版本唯一对应到JetPack的版本,下面列出了最近几个版本的对应关系:
L4T R32.4.3 --> JetPack4.4
L4T R32.4.2 --> JetPack4.4DP
L4T R32.2.1 --> JetPack4.2.2
L4T R32.2.0 --> JetPack4.2.1
功率模式设置与查询
不同的功率模式下,执行AI推理的速度是不一样的,如果对速度需求很高,可以把功率开到最大,但记得加上小风扇散热~
# 1. 运行下面这条命令可以查询开发板当前的运行功率模式 $ sudo nvpmodel -q verbose # $ NV Power Mode: MAXN
# $ 0 # 如果输出为MAXN代表是最大功率模式 # 2. 若需要把功率调到最大,运行下面这条命令 $ sudo nvpmodel -m 0
# 如果你进入了桌面系统,也可以在桌面右上角有个按钮可以切换模式 # 3. 查询资源利用率 $ sudo tegrastats
FAQ
1. EasyDL SDK与云服务效果不一致,如何处理?
后续我们会消除这部分差异,如果开发者发现差异较大,可联系我们协助处理。
2. 运行SDK报错 Authorization failed
日志显示 Http perform failed: null respond 在新的硬件上首次运行,必须联网激活。
SDK 能够接受HTTP_PROXY 的环境变量通过代理处理自己的网络请求。如
export HTTP_PROXY="http://192.168.1.100:8888" ./easyedge_demo ...
3. 使用libcurl请求http服务时,速度明显变慢
这是因为libcurl请求continue导致server等待数据的问题,添加空的header即可
headers = curl_slist_append(headers, "Expect:");
4. 运行demo时报找不到libeasyedge_extension.so
需要export libeasyedge_extension.so所在的路径,如路径为/home/work/baidu/cpp/lib,则需执行:
export LD_LIBRARY_PATH=/home/work/baidu/cpp/lib:${LD_LIBRARY_PATH}
或者在编译完后执行如下命令将lib文件安装到系统路径:
sudo make install
如不能安装,也可手动复制lib下的文件到/usr/local/lib下。
5. 运行demo时报如下之一错误
2020-12-17 16:15:07,924 INFO [EasyEdge] 547633188880 Compiling model for fast inference, this may take
a while (Acceleration) Killed # 或 2020-12-17 16:15:07,924 INFO [EasyEdge] 547633188880 Build graph failed
请适当降低PREDICTOR_KEY_GTURBO_MAX_BATCH_SIZE和PREDICTOR_KEY_GTURBO_MAX_CONCURRENCY的值后尝试。
