




监控概述
目前 CCE 的容器监控是由一系列的开源组件构成,用户可以在页面上自定义部署各个组件,并设置其公网开放策略、持久化配置等。全部部署后,用户将获得如下的监控能力:
- 基于开源的 prometheus + grafana + node-exporter + kube-state-metrics 的采集、存储、展示方案
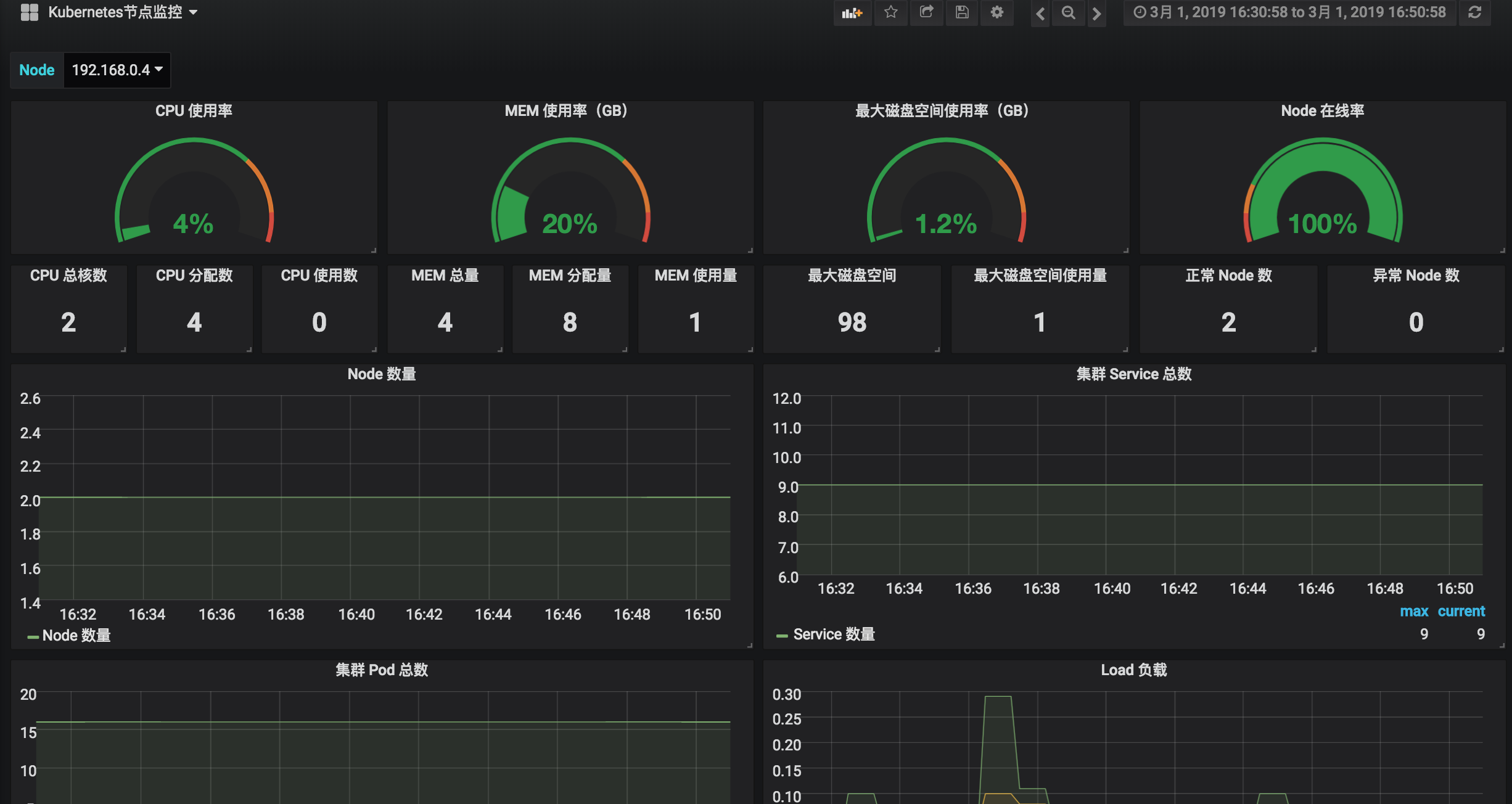
- 节点监控:提供各节点的状态、cpu、内存、磁盘等指标
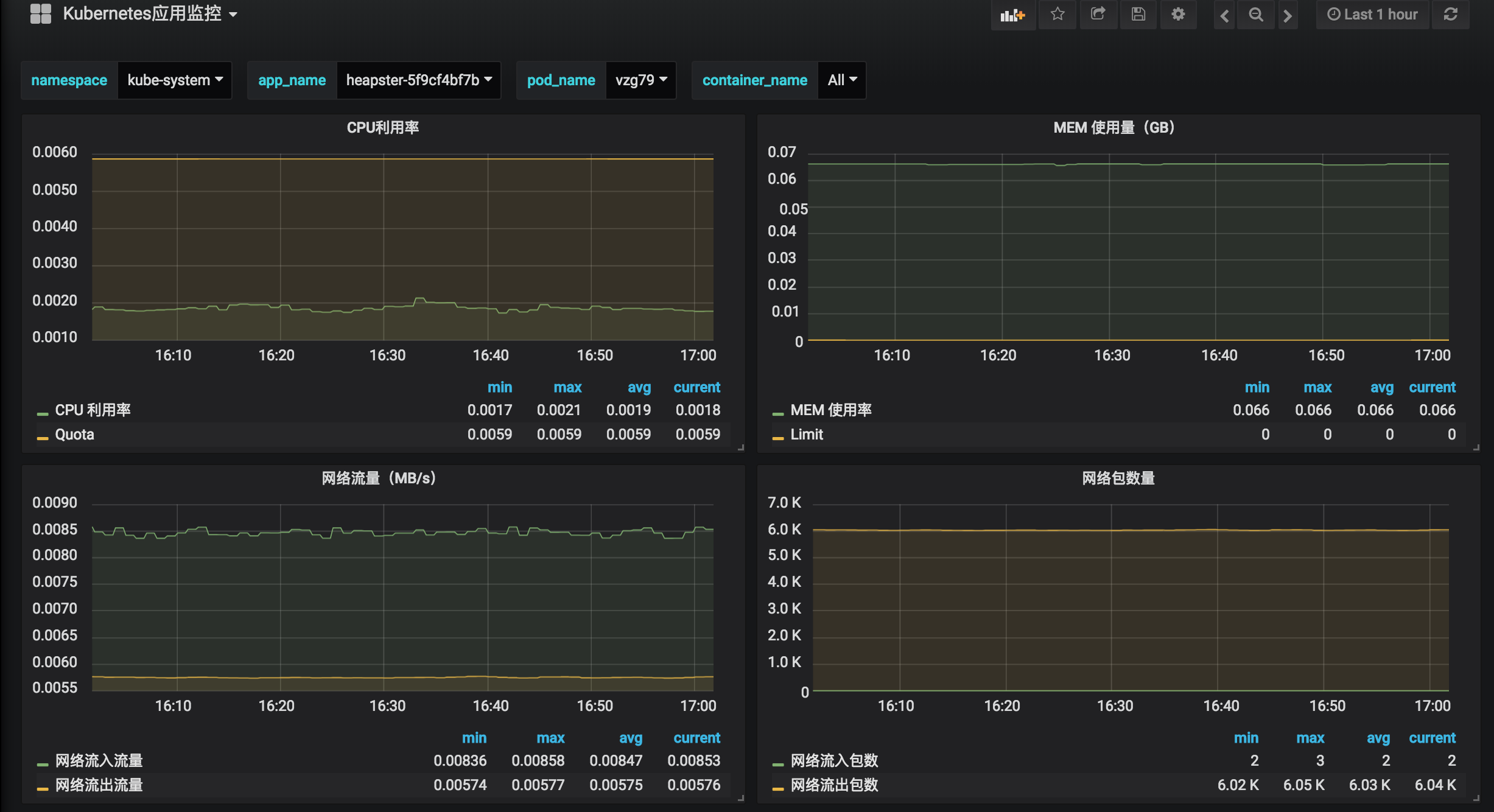
- 应用监控:提供基于 namespace/app/pod/container 多级筛选的容器指标查看,如 cpu、内存、网络流量等
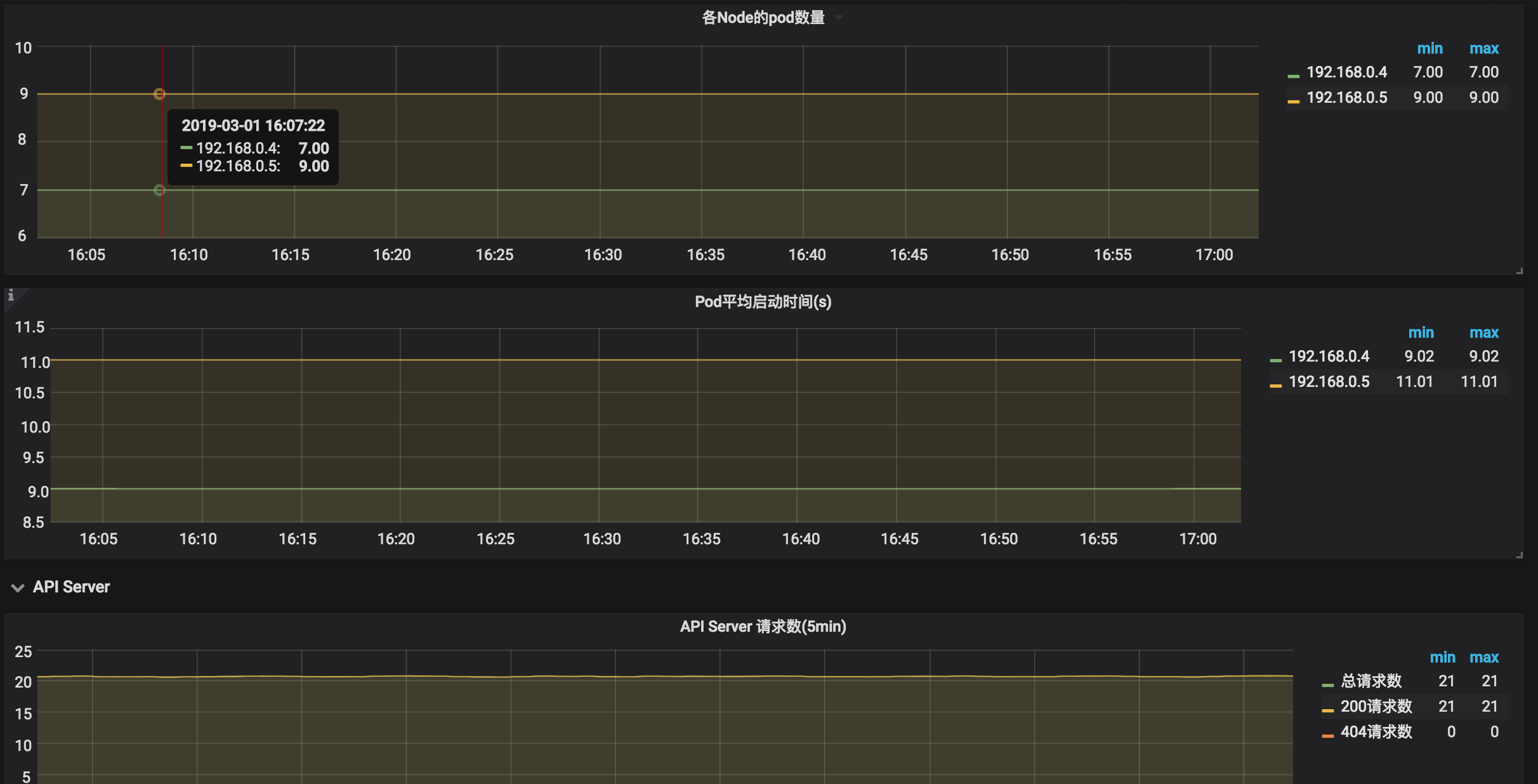
- 资源监控:提供 pod 数量、pod 启动时间、deployment、job 等资源状态以及apiserver 请求数等性能指标
- 自定义监控:提供用户自定义 exporter 的接入
用户可以在页面上部署、卸载、更新各组件,开放或关闭公网服务,并提供 grafana 模板的增量更新功能。
注意事项:cce 部署的 prometheus + grafana 可以选择 cds 作为持久化存储,但不是高可用模式,只是帮助用户快速安装套件,如果有其他需求可以修改资源 yaml。
使用方式
CCE 容器监控产品基于开源组件,各组件作用为:
- prometheus: 监控核心服务,负责数据聚合及存储
- node-exporter: 采集组件,提供主机维度的指标采集,如 node 节点的 cpu 使用率
- kube-state-metrics: 采集组件,提供资源维度的指标采集,如 pod 数量、pod 启动时间
- grafana: 展示组件,提供监控数据的可视化展示,预置了 3 个 dashboard 面板
点击集群-监控日志-容器监控,可以看到如下页面:
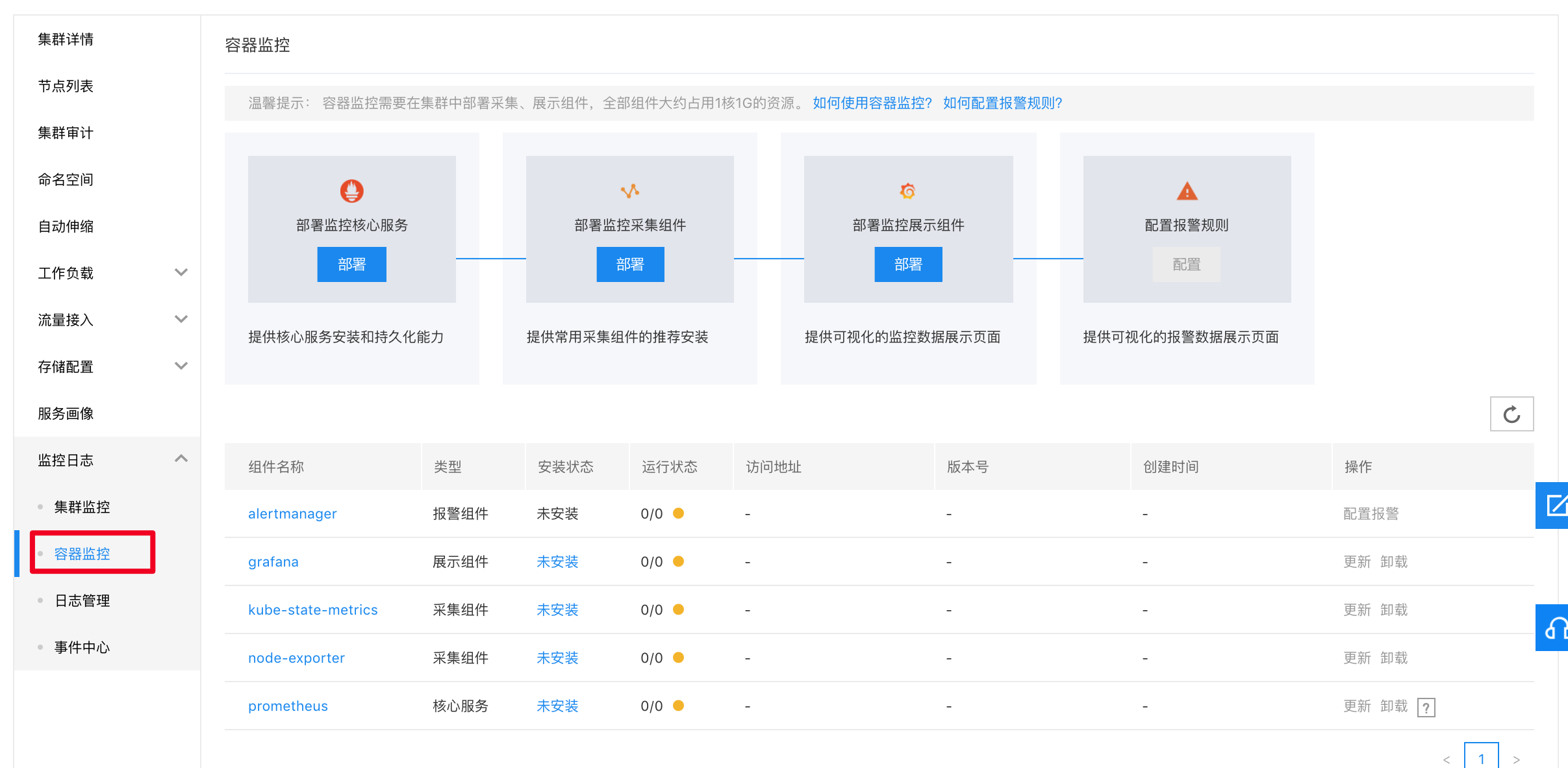
选择对应的集群后,会发现新集群的各组件均为“未安装”状态,这时可以点击上方的三个部署按钮进行初始化部署。
部署监控核心服务
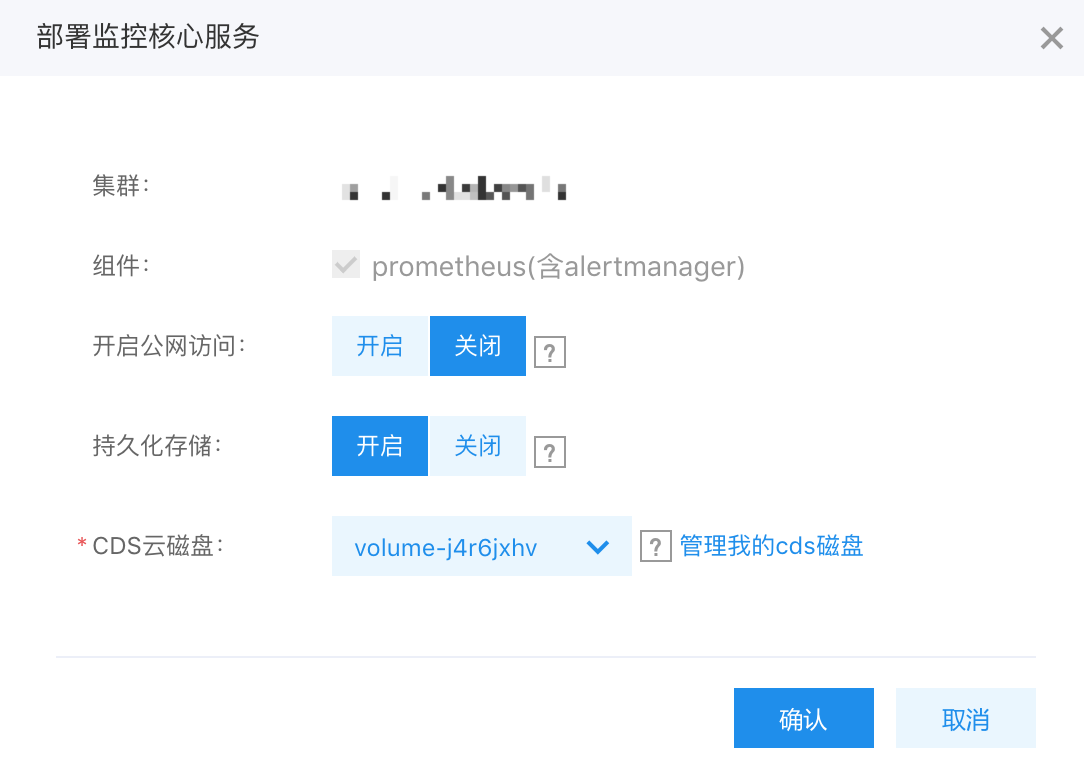
部署流程:
- 组件 prometheus 为默认选中,含 alertmanager,用于后续的报警功能
- 开启公网访问: prometheus 的默认 web 服务没有权限校验,此处默认为关闭,可以点击开启,部署后也可以在列表页对公网服务进行关闭或开启
- 持久化存储:用户可以选择将 prometheus 的数据持久化到 cds 云磁盘上,需要选择自己未挂载的云磁盘,节点或 pod 越多,cds 磁盘应该越大,一般是 100G 以上的磁盘
- 提交:提交后将一键部署 prometheus 的 deployment、service 等资源,pod 启动需要时间,可以在下方的列表页查看服务和 pod 的运行状态
部署监控采集组件
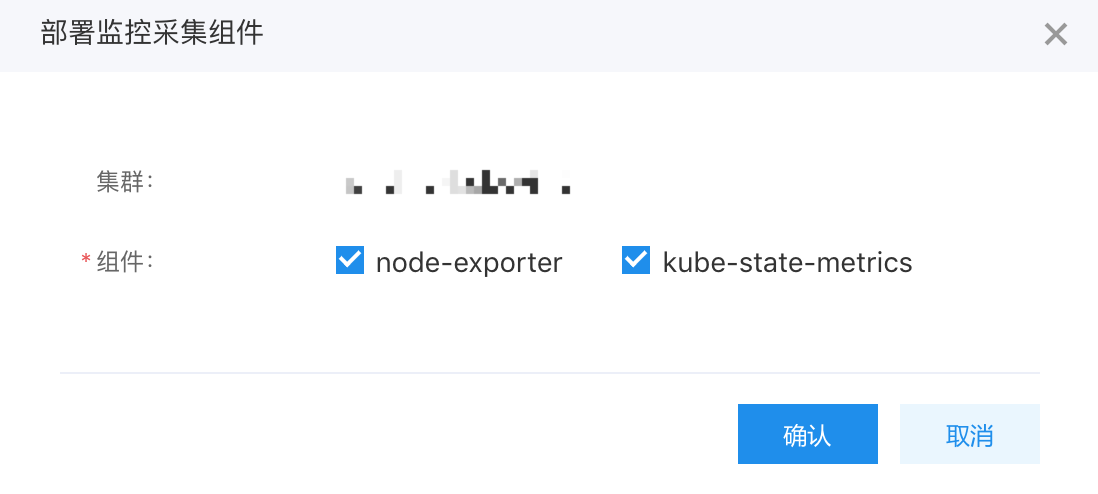
选择需要部署的采集组件,grafana 的默认模板使用了这两个组件采集的数据,可以全部部署,也可以后面再单独部署
部署监控展示组件
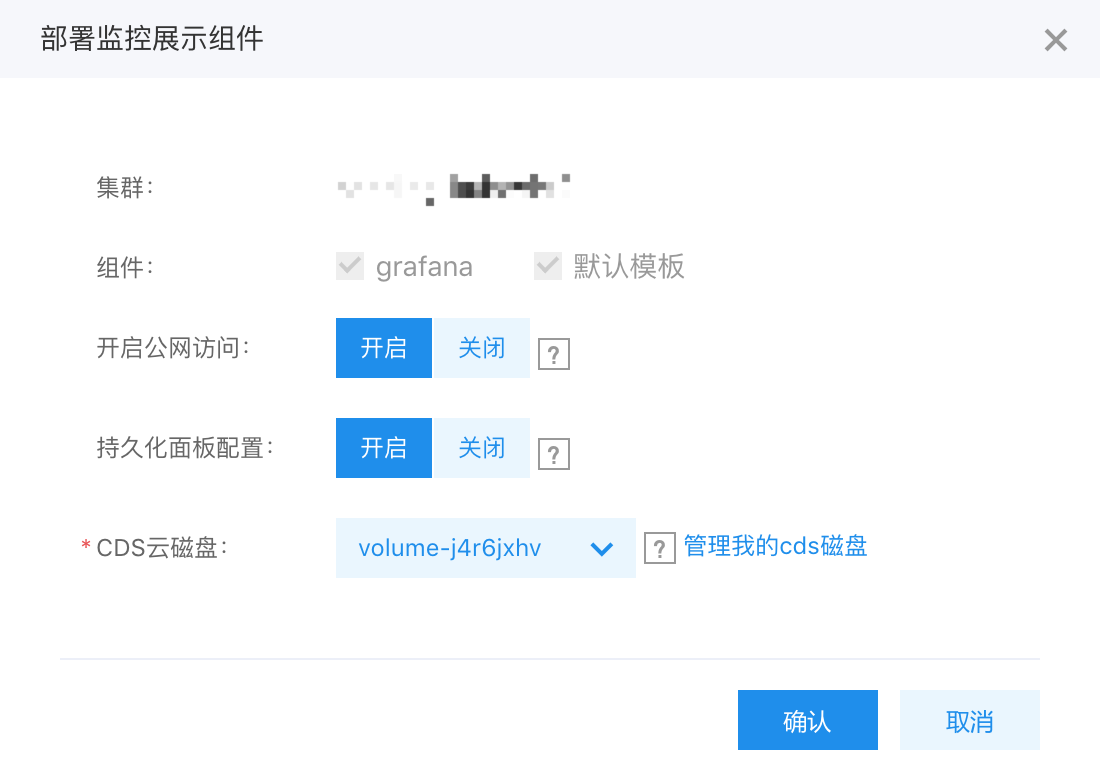
部署流程:
- grafana 默认选中,将自带 3 套监控模板:节点监控、应用监控、资源监控
- 开启公网访问: grafana 一般需要暴露服务,建议打开公网访问,默认账户为 admin,密码为集群 ID,登录后请尽快修改密码
- 持久化存储: 用户可以选择将 grafana 的面板配置数据持久化到 cds 云磁盘上,防止pod 漂移、模板升级时丢失模板数据,因为模板数据很小,cds 磁盘可以小于 5G
- 提交: 将一键部署 grafana 的 deployment、service 等资源,并自动挂载用户选择的 cds 磁盘
查看组件列表
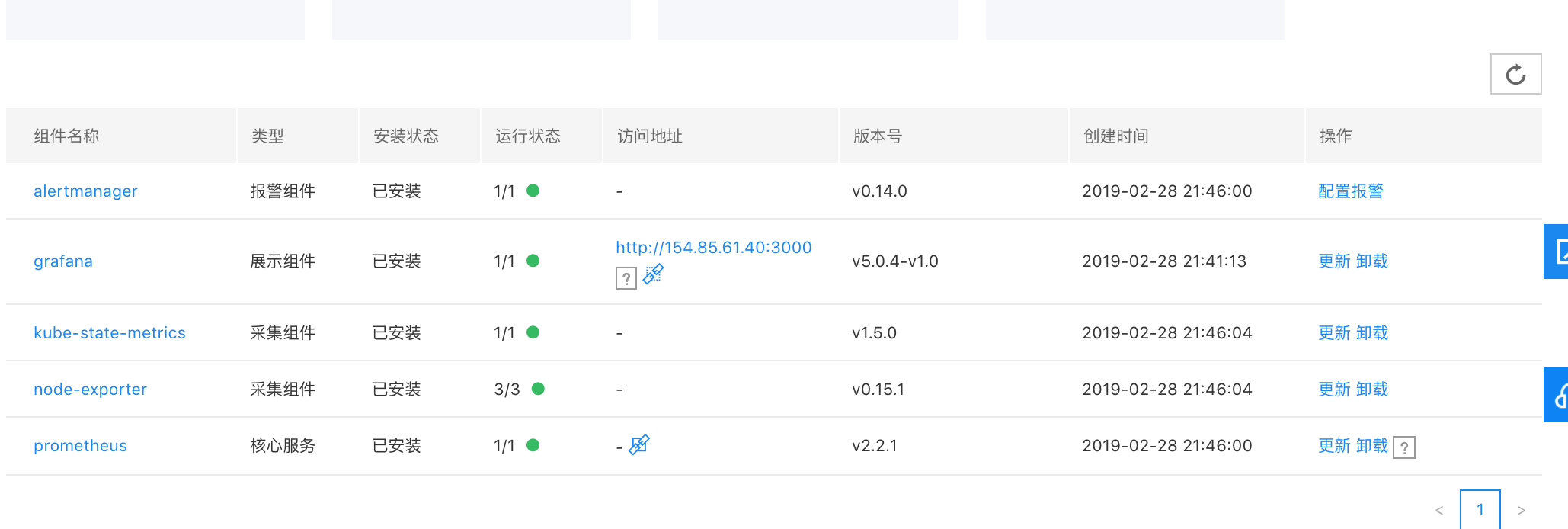
用户部署后可以在下方的列表页查看组件情况,每一列的含义分别为:
- 组件名称:点击可以进入到组件对应的 deployment 或 daemonset 页面
- 类型:分为展示组件、采集组件、核心服务
- 安装状态:已安装、未安装
- 运行状态:展示 pod 的实际值/期望数,如果实际值不等于期望值,将显示黄色标记,正常为绿色
- 访问地址:对于 prometheus 和 grafana,会展示其公网地址,同时可以点击按钮一键关闭或者开放外网服务
- 版本号:各组件均为开源项目,这里会展示其使用的开源版本号,方面用户查看文档,grafana 的版本号会加入 -v1.0 标记,用于标识当前的模板的版本,用于升级监控模板
- 创建时间:组件的创建时间
用户可以勾选某个组件,进行更新、卸载操作,或者点击最上方的部署按钮重新部署
- 卸载:将勾选的组件完整卸载
- 更新:将现有组件卸载并重新安装,如果之前挂载了 cds 持久化,将复用之前的 cds
- 重新部署:可以点击最上方的部署按钮,将会彻底删除现有组件重新部署,如果之前挂载了 cds,新组件也将不再加载原有数据
监控模板展示
grafana 的默认模板包括三种:节点监控、应用监控、资源监控
节点监控:
应用监控:
资源监控:

重要说明
注意事项
- grafana 服务的默认账号为 admin,密码为集群 ID,登录后请及时修改密码
- 如果选择了挂载 cds 磁盘,请不要在其他页面删除该磁盘,否则会导致数据异常
- prometheus 的默认 web 服务没有权限校验,如果是为了临时调试开放,建议使用后及时关闭公网访问, prometheus 并不是高可用部署,数据默认保留时间为 1 天
- 如果组件的运行状态异常,可以点击进入组件详情页,查看对应 pod 的事件和日志
参考文档
cce 部署的均为开源组件,组件对应的开源项目或官方文档为:
- prometheus: https://prometheus.io/
- grafana: https://grafana.com/
- node-exporter: https://github.com/prometheus/node_exporter
- kube-state-metrics: https://github.com/kubernetes/kube-state-metrics
如何自定义监控
如果想在集群中部署自定义的 exporter,暴露自定义的监控指标,有以下两种选择:
1.选择 prometheus 推荐的 exporter:https://prometheus.io/docs/instrumenting/exporters/
2.自主开发 exporter 组件:https://prometheus.io/docs/instrumenting/writing_exporters/
准备好 exporter 后,按照官方文档部署在集群内,并创建对应的 service 资源,同时在 service 的 annotation 中添加:
prometheus.io/scrape: "true"
prometheus 将自动采集新的监控指标,确认指标无误后,用户可以在 grafana 上定制自己的监控图表。
资源占用
以上组件均设置了 limit 和request,如果全部安装,默认资源限制为:
| 组件名称 | request | limit |
|---|---|---|
| prometheus | cpu: 200m mem: 200Mi | cpu: 2048m mem: 4096Mi |
| node-exporter | cpu: 100m mem: 100Mi | cpu: 1024m mem: 1024Mi |
| kube-state-metrics | cpu: 100m mem: 100Mi | cpu: 1024m mem: 1024Mi |
| grafana | cpu: 100m mem: 100Mi | cpu: 1024m mem: 2048Mi |
