




报警概述
CCE 基于 Prometheus + Alertmanager 的方案为用户提供快速可视化的报警配置,用户可根据需求配置节点,应用等维度的报警规则,告警将以邮件或短信发送给指定用户或用户组
前提条件
- 已通过 CCE 部署一个 Kubernetes 集群
- 已在容器监控页面部署容器监控核心服务 Prometheus (含 Alertmanager )
配置报警规则
规则配置分为两步:规则配置和全局配置
- 规则配置:报警规则配置,即什么情况下触发报警
- 全局配置:用于路由报警规则到不同的用户或用户组,即报警发给谁,什么样的报警频率
配置入口
进入 “产品服务>容器引擎 CCE”,点击左侧导航栏“监控日志>容器监控“,进入容器监控页;点击配置报警规则模块的配置或者组件列表中 Alertmanager 所在行的配置报警。

规则配置
进入“规则配置“ Tab 页,如下图:

规则列表页可以查看所有的报警规则,添加规则、删除或修改现有规则。
单击“新建报警规则“,弹出报警规则配置页面,如下图:
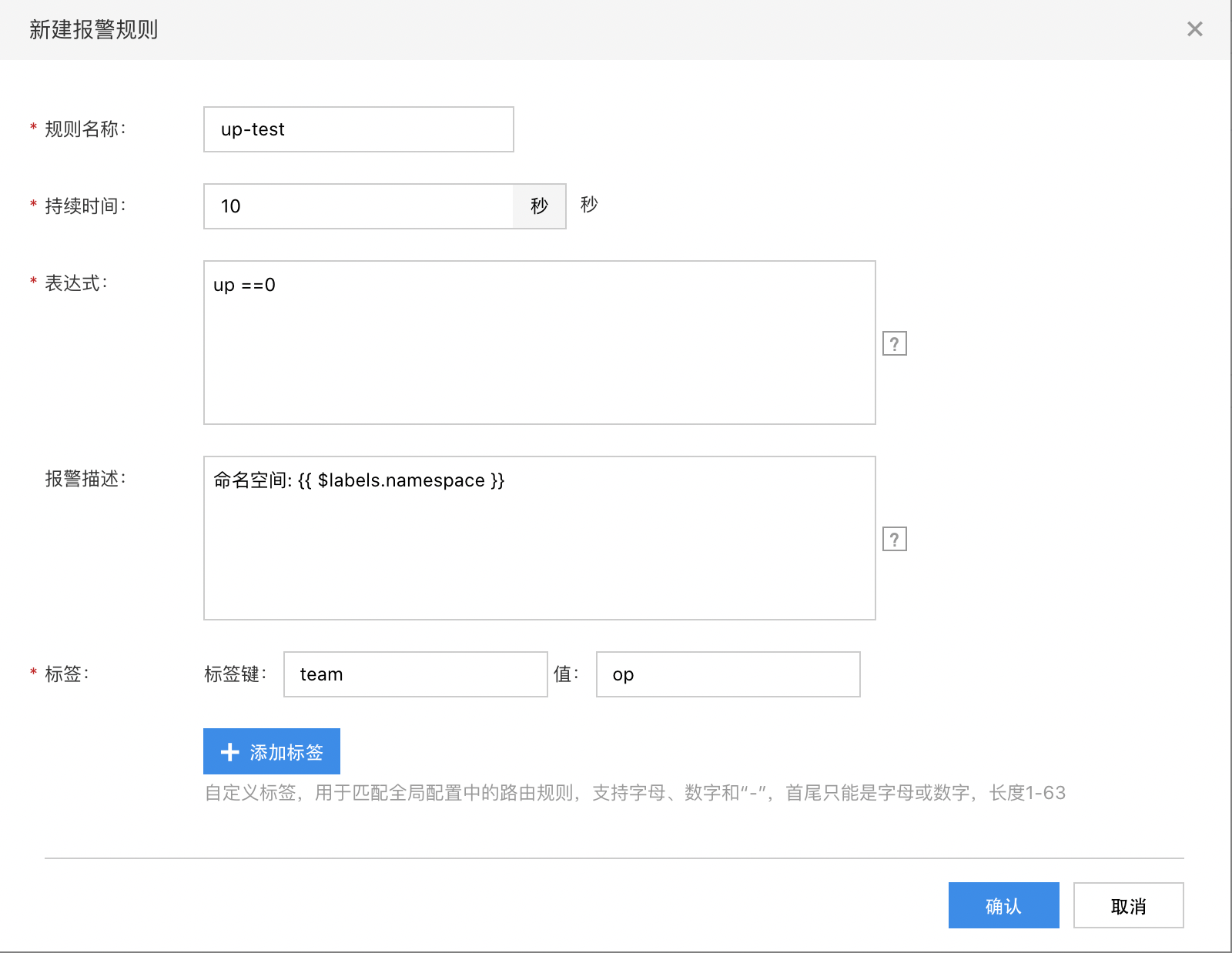
根据需求配置规则,参数解释如下:
- 规则名称:报警规则的名称,也是报警邮件中的标题
- 持续时间:只有当触发条件一段时间后才发送告警,单位为秒
- 表达式:填写合法的 promsql 语句,如 node_cpu >90 等。表达式语法可以参考:语法规则
- 报警描述:可以自定义报警描述,描述信息会在邮件正文中体现,详见语法参考,为空表示无特定描述
- 标签:可以对每条规则配置多个自定义标签,用于在全局配置中筛选路由,以匹配不同的报警收件人
配置完成后,点击“确认“提交即可
提醒: 每次新建、修改、删除操作,都需要 60s 左右生效
全局配置
进入“全局配置“ Tab 页,如下图:
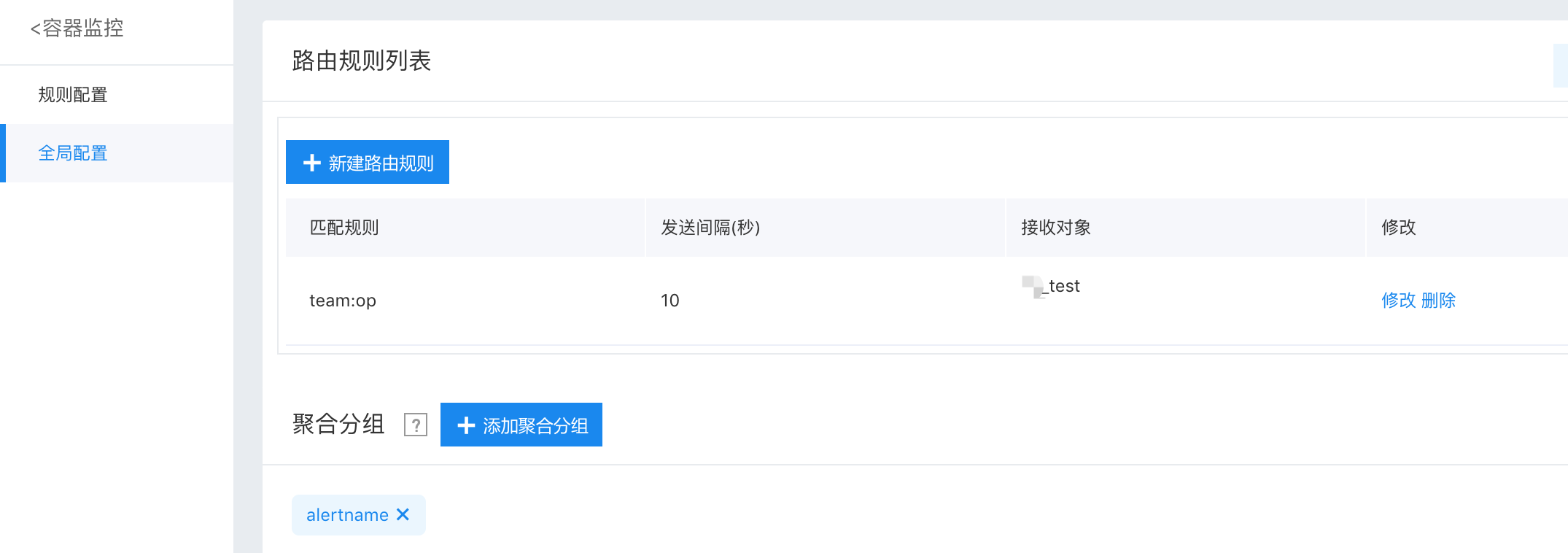
全局配置中可以查看或配置路由规则、聚合分组。
单击“新建路由规则“,弹出路由规则配置页面,如下图 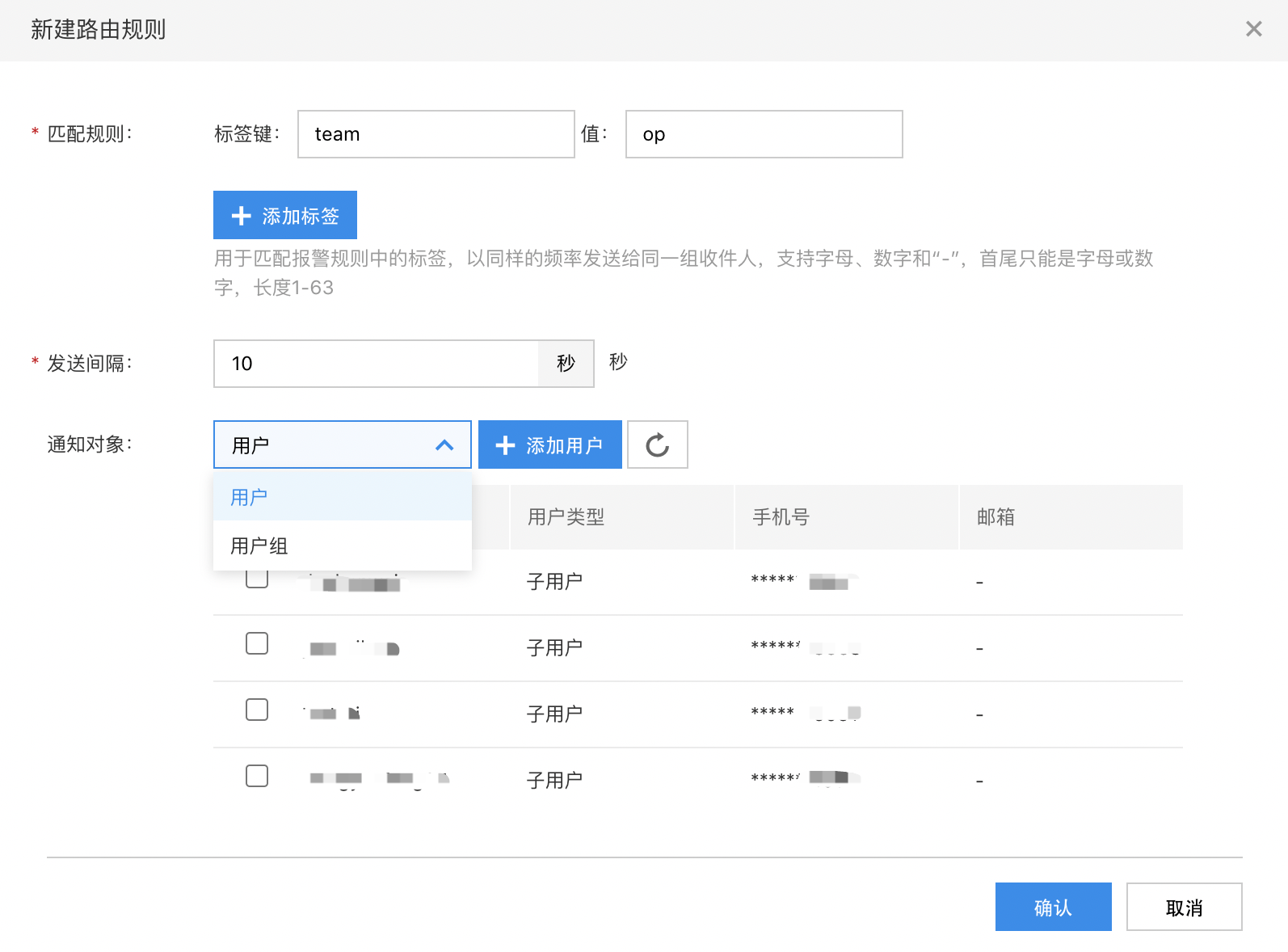
路由规则:指当报警被触发后( FIRE 状态),会匹配到的报警收件人、发送间隔等。
根据需求配置规则,参数解释如下:
- 匹配规则:对应每条报警规则中的标签,可以通过标签匹配多个报警规则,以同样的发送频率发送给同一组收件人
- 发送间隔:报警的发送间隔,单位为秒。
- 通知类型:目前支持邮件报警、短信报警
- 通知对象:可以勾选用户和用户组,用户分为普通子用户和消息接收人,两种类型都可以在多用户访问控制中认证手机号和邮箱地址,用户或组添加后,必须认证才能接到报警。
提醒:
- 为了报警的安全性考虑,单集群单用户每分钟的报警发送量不超过100封
- 如果未收到邮件或短信报警,可以先检查下是否设置了拦截规则,如短信屏蔽之类
- 老用户配置的特定邮箱报警仍然生效,如有问题请联系管理员
聚合分组
聚合分组决定了产生的告警怎么分组,分组条件一致的告警会合并为一组发送,当大型故障发生时(如网络故障),会导致报警条数过多,无法快速定位问题,分组可以达到降噪的效果。默认的聚合分组为报警名称( alertname ),即默认不分组。用户可以根据需求添加或删除聚合分组。
单击“添加聚合分组“,在弹出的输入框中配置。

示例:
将某一类环境的所有应用异常告警做聚合,如果网络故障或者其他故障导致大批应用异常,那么所有告警会合并为一条告警发送。 配置步骤:
- 在test环境中的所有应用异常告警规则配置中添加标签:env: test alert_type: app_down
- 在dev环境中的所有应用异常告警规则配置中添加标签:env: dev alert_type: app_down
- 添加聚合分组标签:env和alert_type
告警发送:
标签为 env=test 且 alerttype=app_down 的所有告警被聚合,即 test 环境中所有应用异常告警在一条信息发送。同理,dev 环境中所有应用异常告警在一条信息发送。
