

文档简介:



CCE 日志管理
CCE 日志管理功能帮助用户对 kubernetes 集群中的业务日志和容器日志进行管理。用户通过日志管理可以将集群中的日志输出到外部的 Elasticsearch 服务或者百度云自己的 BOS 存储中,从而对日志进行分析或者长期保存。
创建日志规则
在左侧导航栏,点击“监控日志 > 日志管理”,进入日志规则列表页。点击日志规则列表中的新建日志规则:
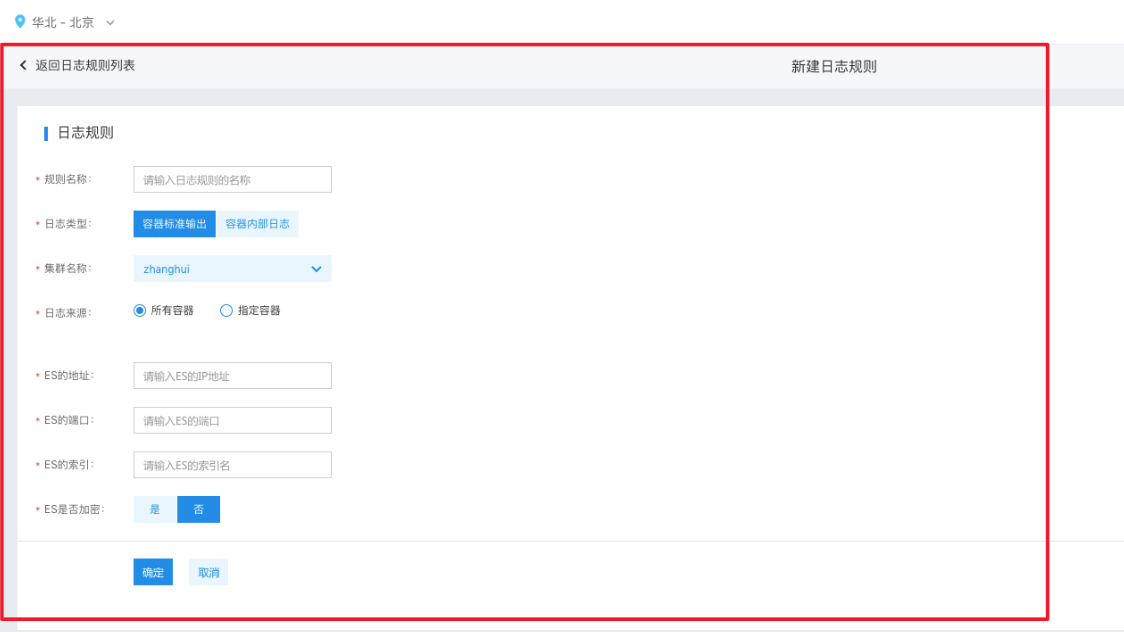
- 规则名称:用户自定义,用来对不同的日志规则进行标识和描述
- 日志类型:“容器标准输出“ 是指容器本身运行时输出的日志,可以通过 docker logs 命令查看,“容器内部日志”是指容器内运行的业务进程,存储在容器内部某个路径
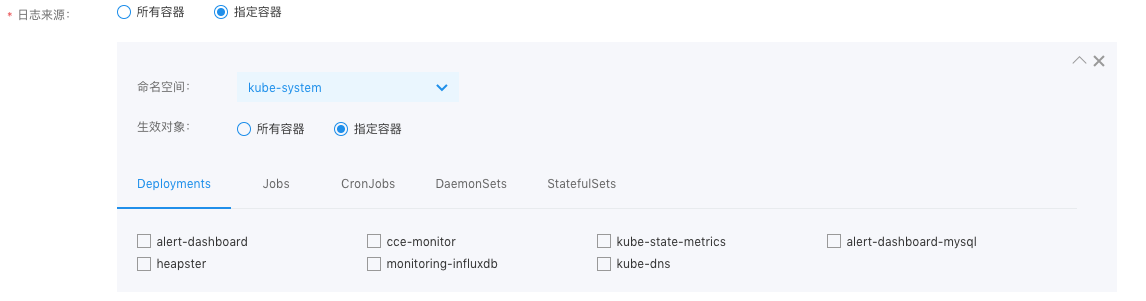
- 集群名称和日志来源定位到需要输出日志的对象,如果选择“指定容器”,则支持在Deployment、Job、CronJob、DaemonSet、StatefulSet 五种资源维度进行选择
- Elasticsearch 的地址、端口、索引、以及加密等配置,用来帮助 CCE 日志关联服务将日志输出到对应的 Elasticsearch 服务中。请填写 Elasticsearch 服务信息,需要确保 CCE 集群可以与该 Elasticsearch 服务正确建立连接。生产环境建议直接使用 BES (百度 Elasticsearch)服务。
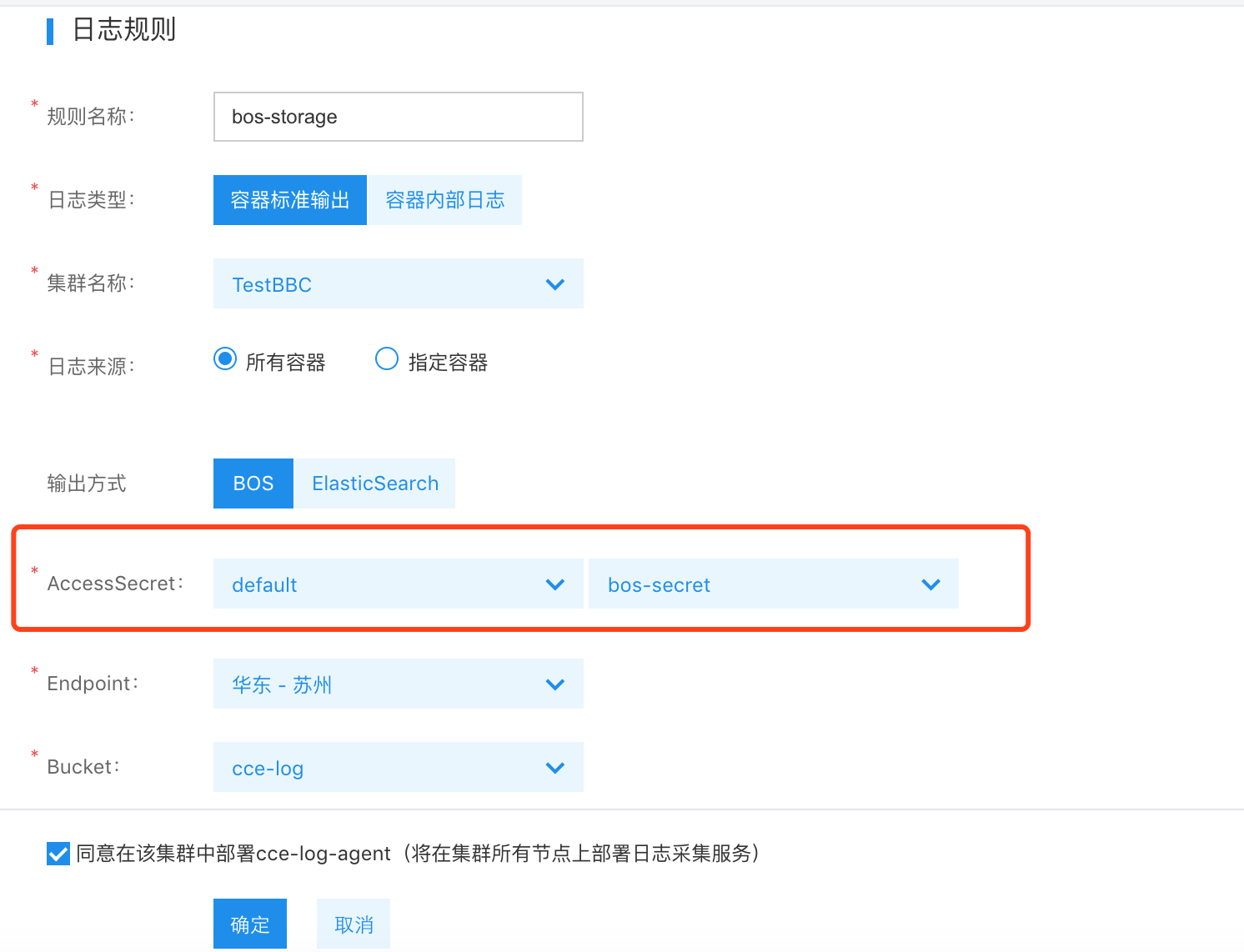
- 若要推送到 BOS 存储中需要创建一个可以连接 BOS 存储的 Secret 资源,按以下格式创建,然后在选择 BOS 存储的时候,选定该 Secret 所在的命名空间以及名字。如果机器可以连接外网,那么 BOS 的 Endpoint 可以选择任意地域,如果不能连接外网,则只能选择跟 CCE 集群一样的地域。
- 创建 BOS 的 Secret 因为权限限制的问题,目前必须使用主账户的 AK/SK,否则无法通过认证鉴权。
apiVersion: v1 kind: Secret metadata: name: bos-secret data: bosak: dXNlcm5hbWU= # echo -n "bosak...." | base64 bossk:
cGFzc3dvcmQ= # echo -n "bossk...." | base64
配置 kubernetes 资源
在配置完日志管理规则后,需要确保kubernetes中的日志能够正确输出,因此需要在创建相关的kubernetes资源时传入指定的环境变量:
- 传入环境变量 cce_log_stdout 并指定 value 为 true 表示采集该容器的标准输出,不采集则无需传递该环境变量
- 传入环境变量 cce_log_internal 并指定 value 为容器内日志文件的绝对路径,此处需填写文件路径,不能为目录
- 采集容器内文件时需将容器内日志文件所在目录以 emptydir 形式挂载至宿主机。
请参考以下yaml示例:
apiVersion: apps/v1 kind: Deployment metadata: name: tomcat spec: selector: matchLabels: app: tomcat replicas:
4 template: metadata: labels: app: tomcat spec: containers: - name: tomcat image: "tomcat:7.0" env:
- name: cce_log_stdout value: "true" - name: cce_log_internal value: "/usr/local/tomcat/logs/catalina.*.log"
volumeMounts: - name: tomcat-log mountPath: /usr/local/tomcat/logs volumes: - name: tomcat-log emptyDir: {}
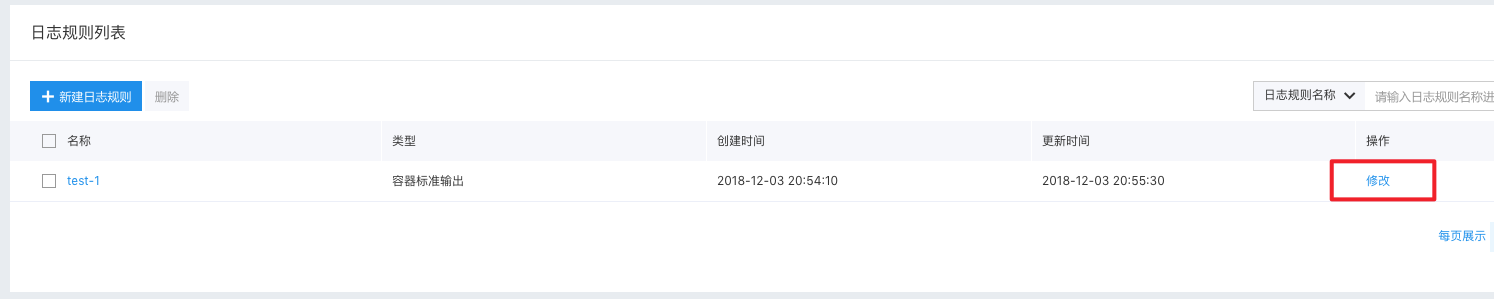
修改和删除日志规则
日志规则创建之后,用户可以随时对规则进行修改或者删除。点击修改可以重新编辑已经创建的日志规则,编辑页与新建页逻辑基本一致,但是不允许修改集群以及日志类型。
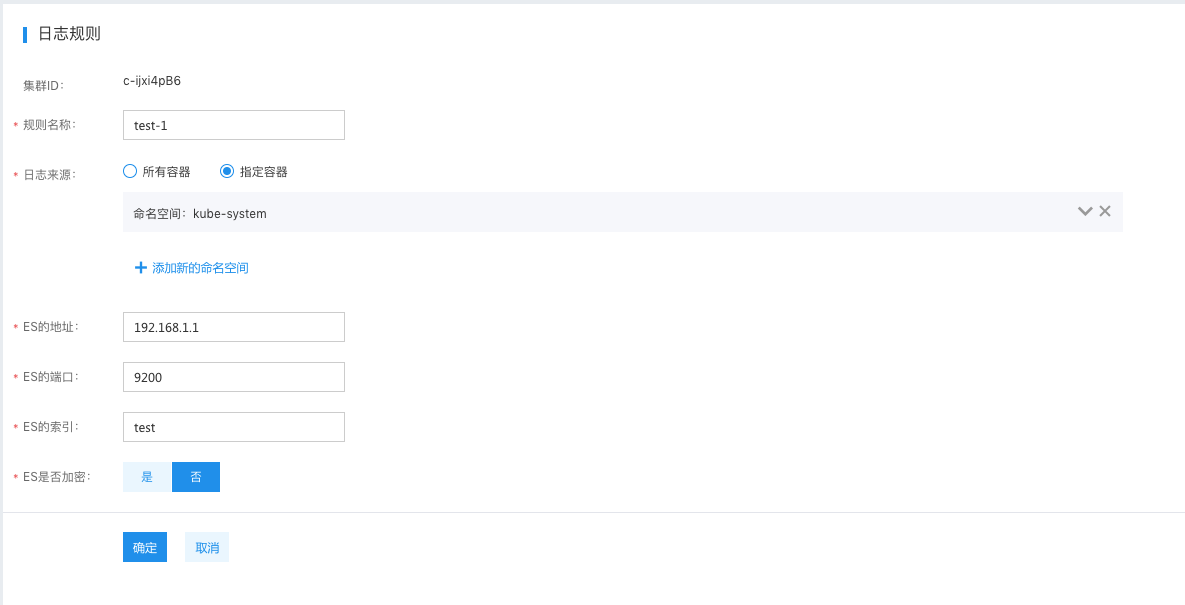
使用 BES (百度云 Elasticsearch) 服务
生产环境使用建议使用 BES 服务,具体参考: Elasticsearch 创建集群
K8S 集群自建 Elasticsearch (仅供参考)
本方法仅供测试,生产环境建议直接使用 BES 服务。使用如下的 yaml 文件,在 CCE 集群中部署 Elasticsearch:
apiVersion: v1 kind: Service metadata: name: elasticsearch-logging namespace: kube-system labels: k8s-app:
elasticsearch-logging kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "Elasticsearch" spec: ports: - port: 9200 protocol: TCP targetPort: db selector: k8s-app:
elasticsearch-logging --- # RBAC authn and authz apiVersion: v1 kind: ServiceAccount metadata:
name: elasticsearch-logging namespace: kube-system labels: k8s-app: elasticsearch-logging kubernetes.
io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile --- kind: ClusterRole apiVersion:
rbac.authorization.k8s.io/v1 metadata: name: elasticsearch-logging labels: k8s-app: elasticsearch-logging
kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile rules: - apiGroups:
- "" resources: - "services" - "namespaces" - "endpoints" verbs: - "get" --- kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1 metadata: namespace: kube-system name: elasticsearch-logging labels:
k8s-app: elasticsearch-logging kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode:
Reconcile subjects: - kind: ServiceAccount name: elasticsearch-logging namespace: kube-system apiGroup:
"" roleRef: kind: ClusterRole name: elasticsearch-logging apiGroup: "" --- # Elasticsearch deployment
itself apiVersion: apps/v1 kind: StatefulSet metadata: name: elasticsearch-logging namespace: kube-system labels:
k8s-app: elasticsearch-logging version: v6.3.0 kubernetes.io/cluster-service: "true" addonmanager
.kubernetes.io/mode: Reconcile spec: serviceName: elasticsearch-logging replicas: 2 selector: matchLabels: k8s-app:
elasticsearch-logging version: v6.3.0 template: metadata: labels: k8s-app: elasticsearch-logging version:
v6.3.0 kubernetes.io/cluster-service: "true" spec: serviceAccountName: elasticsearch-logging containers:
- image: hub.baidubce.com/jpaas-public/elasticsearch:v6.3.0 name: elasticsearch-logging resources:
# need more cpu upon initialization, therefore burstable class limits: cpu: 1000m requests: cpu:
100m ports: - containerPort: 9200 name: db protocol: TCP - containerPort: 9300 name: transport protocol:
TCP volumeMounts: - name: elasticsearch-logging mountPath: /data env: - name: "NAMESPACE" valueFrom: fieldRef:
fieldPath: metadata.namespace volumes: - name: elasticsearch-logging emptyDir: {} # Elasticsearch requires
vm.max_map_count to be at least 262144. # If your OS already sets up this number to a higher value, feel free
# to remove this init container. initContainers: - image: alpine:3.6 command:
["/sbin/sysctl", "-w", "vm.max_map_count=262144"] name: elasticsearch-logging-init securityContext: privileged: true
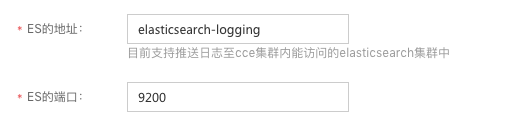
部署成功后将创建名为 elasticsearch-logging 的 service,如下图所示在创建日志规则时 ES 的地址可填为该 service 的名字,端口为 service 的端口:
使用如下 yaml 部署 kibana,部署成功后通过创建的名为 kibana-logging 的 LoadBalancer 访问 kibana 服务:
apiVersion: v1 kind: Service metadata: name: kibana-logging namespace: kube-system labels: k8s-app:
kibana-logging kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "Kibana" spec: ports: - port: 5601 protocol: TCP targetPort: ui selector:
k8s-app: kibana-logging type: LoadBalancer --- apiVersion: apps/v1 kind: Deployment metadata:
name: kibana-logging namespace: kube-system labels: k8s-app: kibana-logging kubernetes.io/cluster-service:
"true" addonmanager.kubernetes.io/mode: Reconcile spec: replicas: 1 selector: matchLabels: k8s-app:
kibana-logging template: metadata: labels: k8s-app: kibana-logging annotations: seccomp.security.
alpha.kubernetes.io/pod: 'docker/default' spec: containers: - name: kibana-logging image: hub
.baidubce.com/jpaas-public/kibana:v6.3.0 resources: # need more cpu upon initialization,
therefore burstable class limits: cpu: 1000m requests: cpu: 100m env: - name: ELASTICSEARCH_URL
value: http://elasticsearch-logging:9200 - name: SERVER_BASEPATH value: "" ports: - containerPort: 5601 name: ui protocol: TCP
注意
生产环境下建议使用百度智能云的 Elasticsearch 服务或者自建专用的 Elasticsearch 集群
