

腾讯云消息队列 CKafka 实战教程 - PostgreSQL 到 Elasticsearch 实时数据同步
文档简介:
操作场景:
本文档满足如下场景:将 PostgreSQL 表的数据(存量+增量)实时同步数据同步到目标ES索引。实时同步需要同步新增,修改和删除操作。即当 PostgreSQL 源表出现新增、修改、删除时,目标 ES 中的数据也需要发生相应的增删改。



场景说明
本文档满足如下场景:将 PostgreSQL 表的数据(存量+增量)实时同步数据同步到目标ES索引。实时同步需要同步新增,修改和删除操作。即当 PostgreSQL 源表出现新增、修改、删除时,目标 ES 中的数据也需要发生相应的增删改。
使用限制
本种实时同步增删改的任务。一个订阅任务只能订阅一张表的数据,一个 Topic 里面只能存一个表的订阅数据。即订阅一张表的数据到 ES 需要创建一个订阅任务,一个 Topic,一个数据流出任务。同时为了保证数据同步的有序性,一个 Topic 只支持一个分区。
说明
如果需要同步多张表的数据到 ES 里面。则需要创建多个 Topic,同时创建多个订阅任务和流出任务。
操作步骤
步骤1:创建连接
1. 创建 PostgreSQL 连接
1. 单击连接器中的 连接列表,单击新建连接,选择 TDSQL-C 数据库。
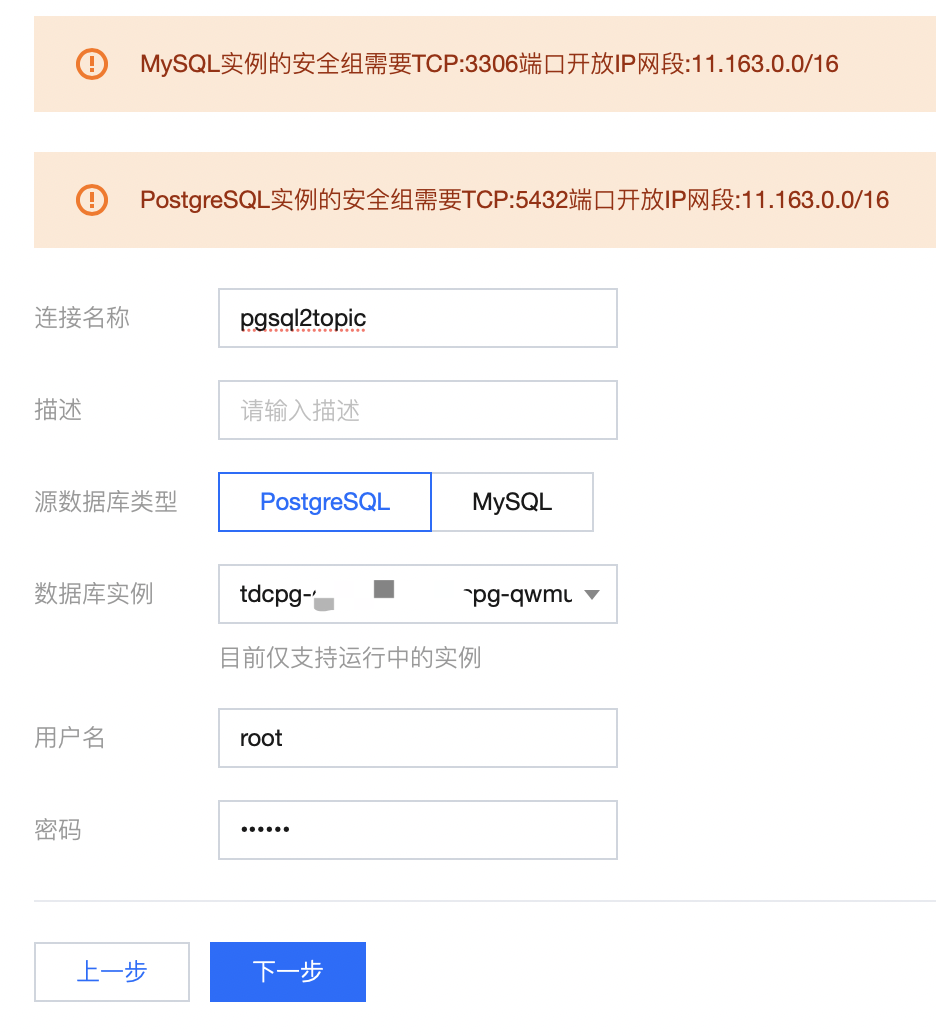
2. 填写需要同步的 PostgreSQL 数据库的相关信息。
2. 创建 Elasticsearch 连接
1. 单击连接器中的 连接列表,单击新建连接,选择 Elasticsearch Service。
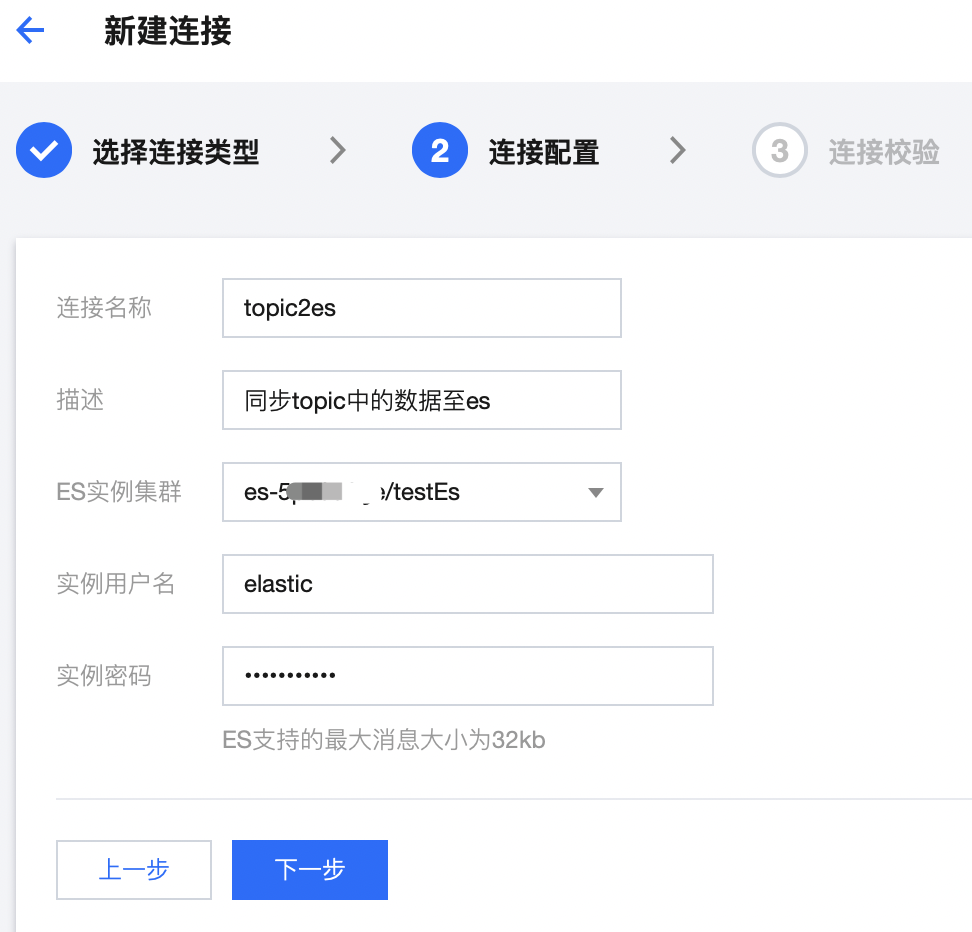
2. 配置 ES 相关的参数:
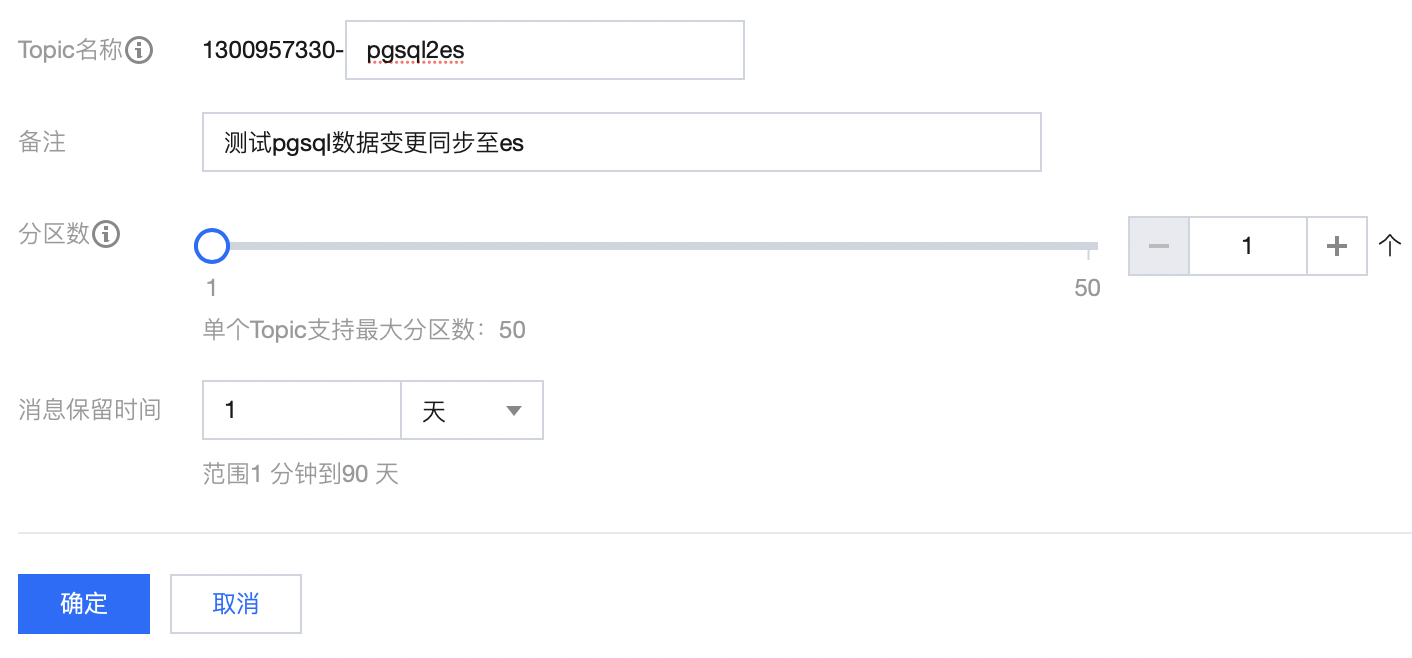
步骤2:创建 Topic
创建 Topic 有两种方式,如果已购买 kafka 实例,则直接在实例中新建 Topic 即可。否则,可以新建按量付费的 Topic(无需购买实例)。购买按量付费 Topic 操作步骤如下:
进入 Ckafka 控制台,选择弹性 Topic,单击新建 Topic。(若计划将数据同步至 Ckafka 实例中的 topic 则可跳过此步骤)
步骤3:创建数据订阅任务
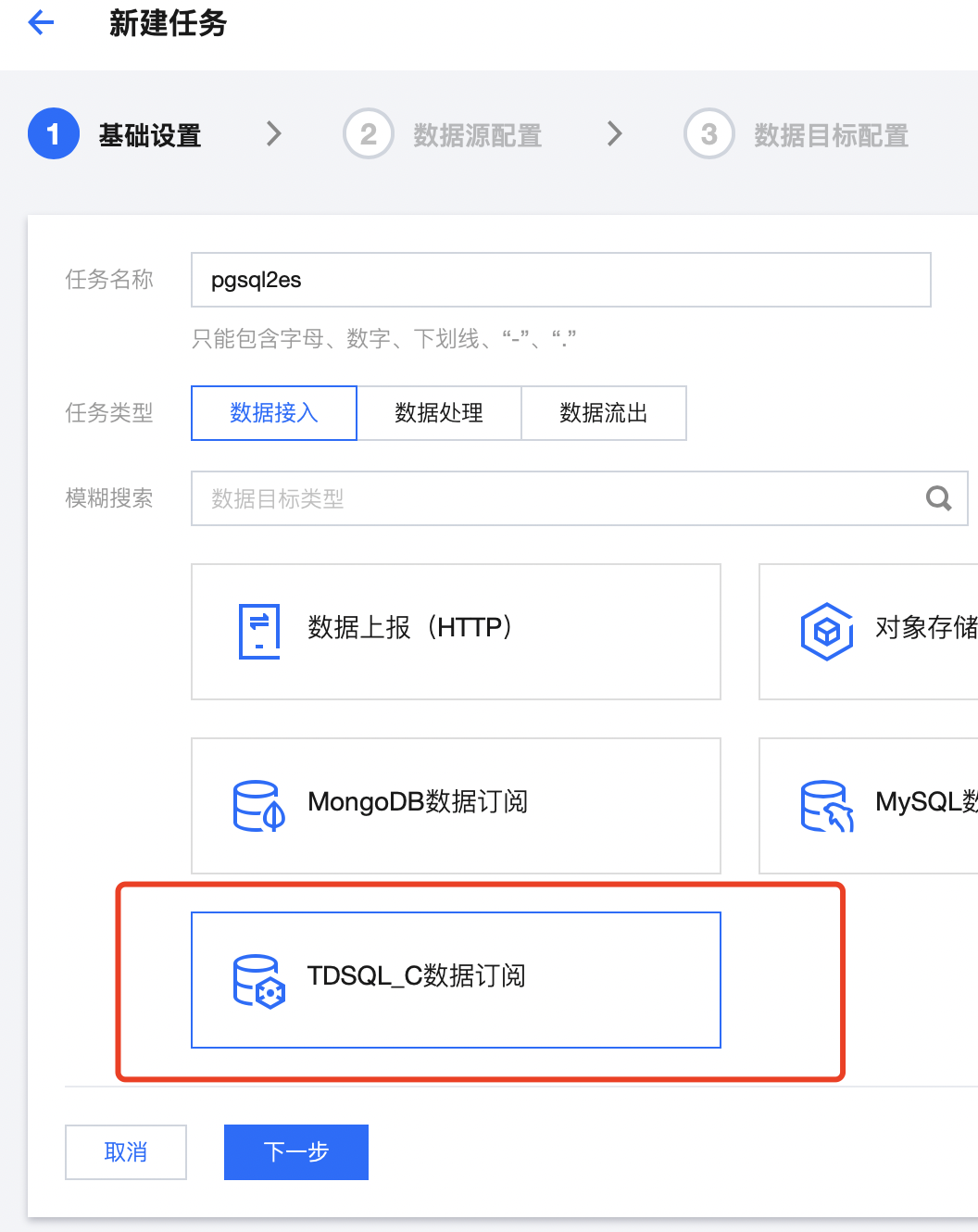
1. 单击连接器中的 任务管理,单击任务列表,单击新建任务。
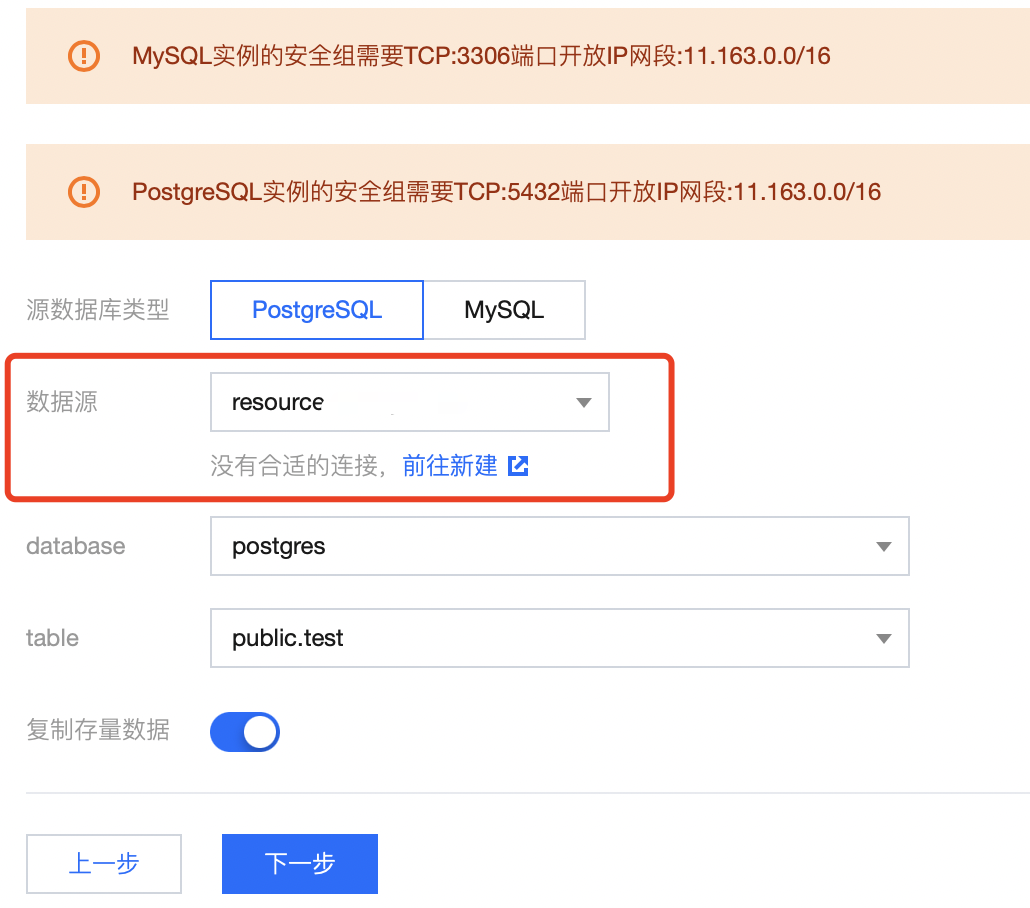
2. 单击下一步,填写数据源配置信息,数据源为 步骤一 中创建的 Postgresql 订阅连接:
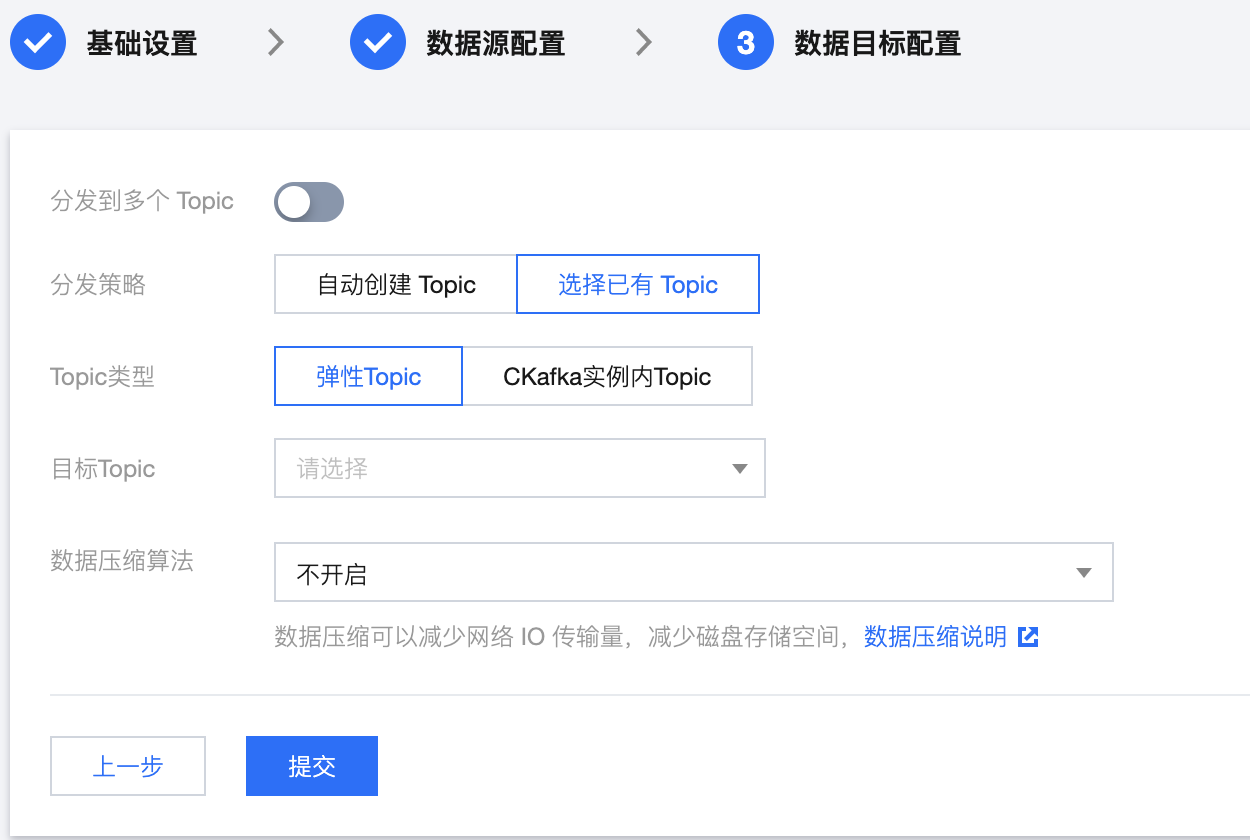
3. 继续单击下一步,选择数据目标信息,即同步 PostgreSQL 数据的 topic,根据实际情况选择弹性 Topic 或 CKafka 实例内 Topic 即可,此处选择 步骤二 中创建的弹性 topic:
4. 任务创建成功后,在任务详情 > 查看消息可以看到订阅的数据信息:
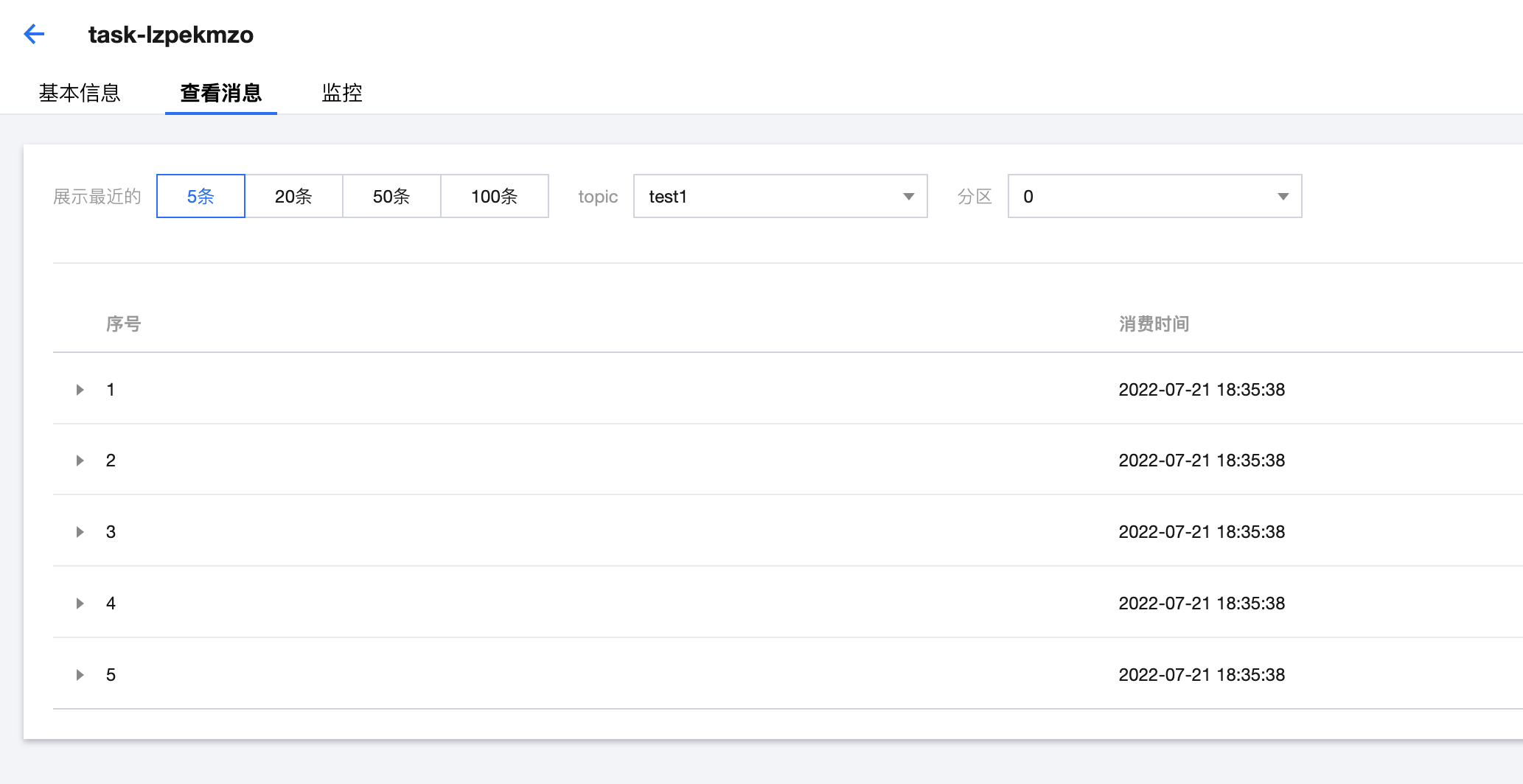
注意:
只有源表有数据存在的时候,才会订阅到消息。当源表没有数据时,可执行如下类似的 insert 语句,触发订阅行为,即可查询到订阅的数据:
insert into test values('testname',25);
步骤4:创建数据流出任务
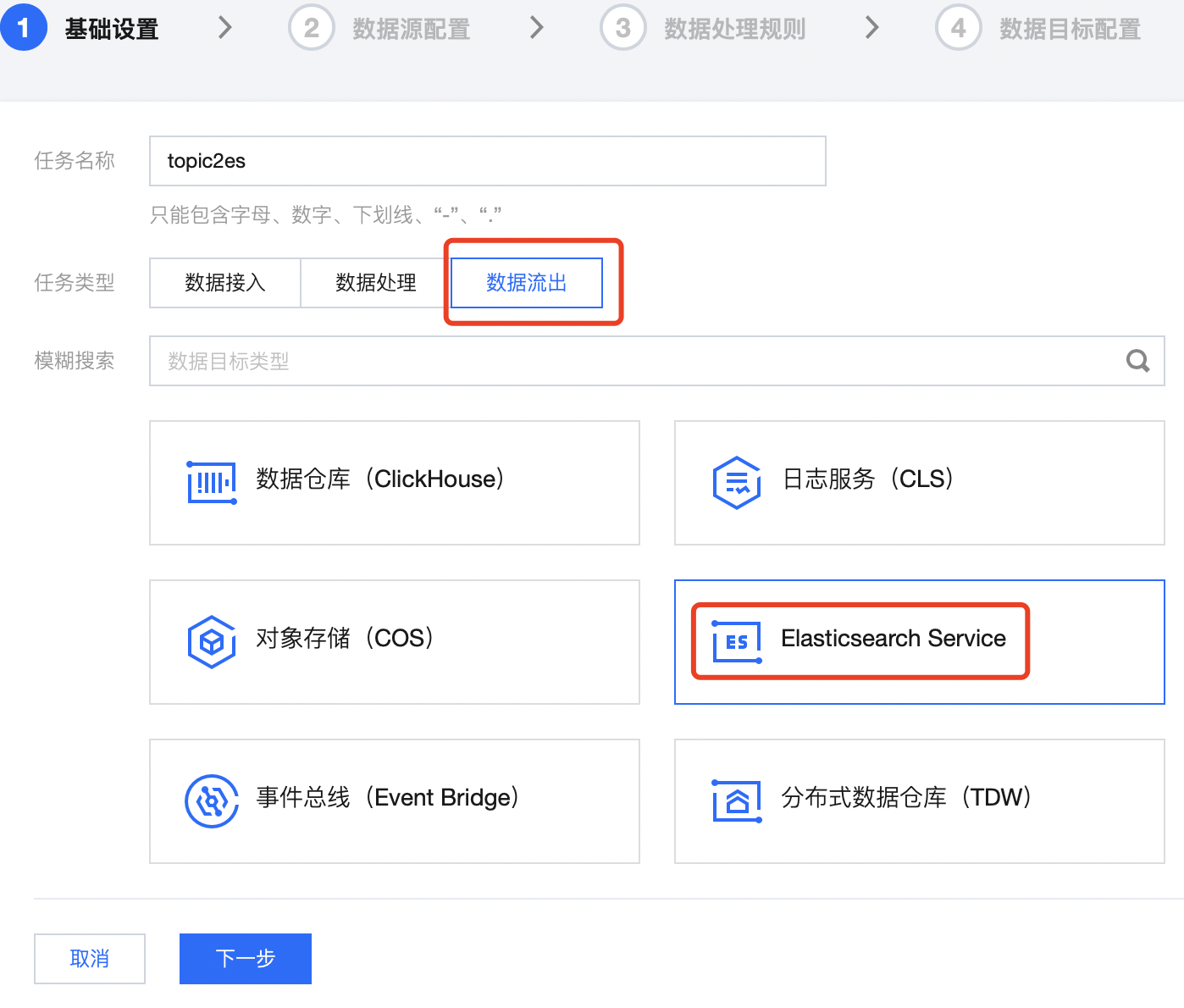
1. 新建连接后,单击任务管理 > 任务列表,单击新建任务,任务类型选择数据流出,选择 Elasticsearch Service:
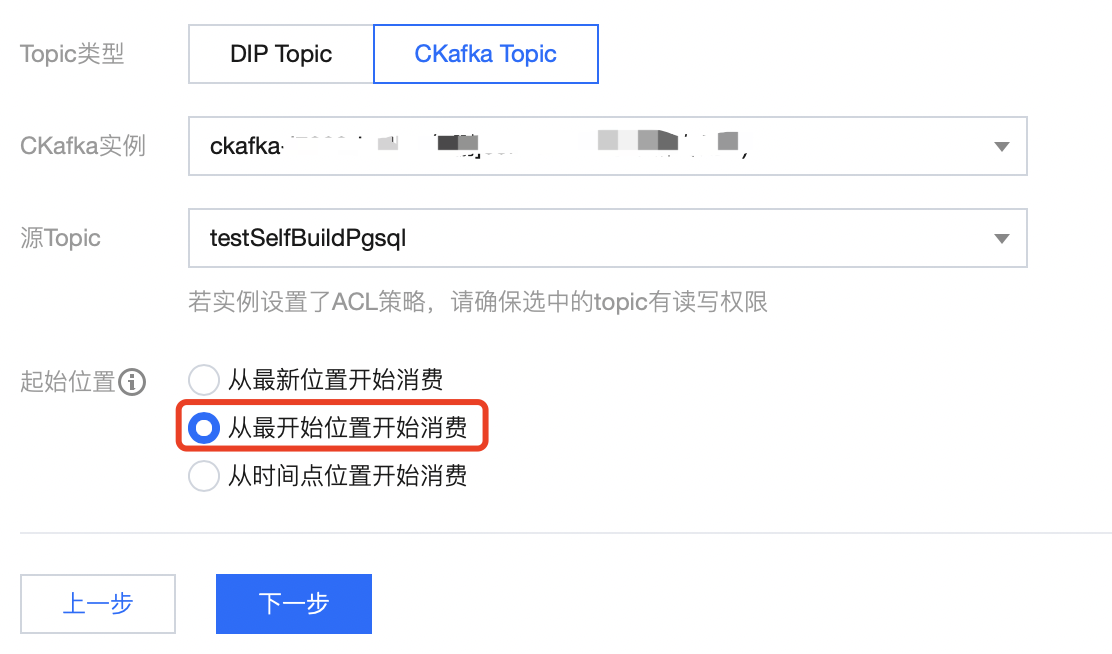
2. 配置数据源,选择同步了 MySQL 数据的 topic,这里选择 步骤1 中的 topic,选择 从最开始位置开始消费。
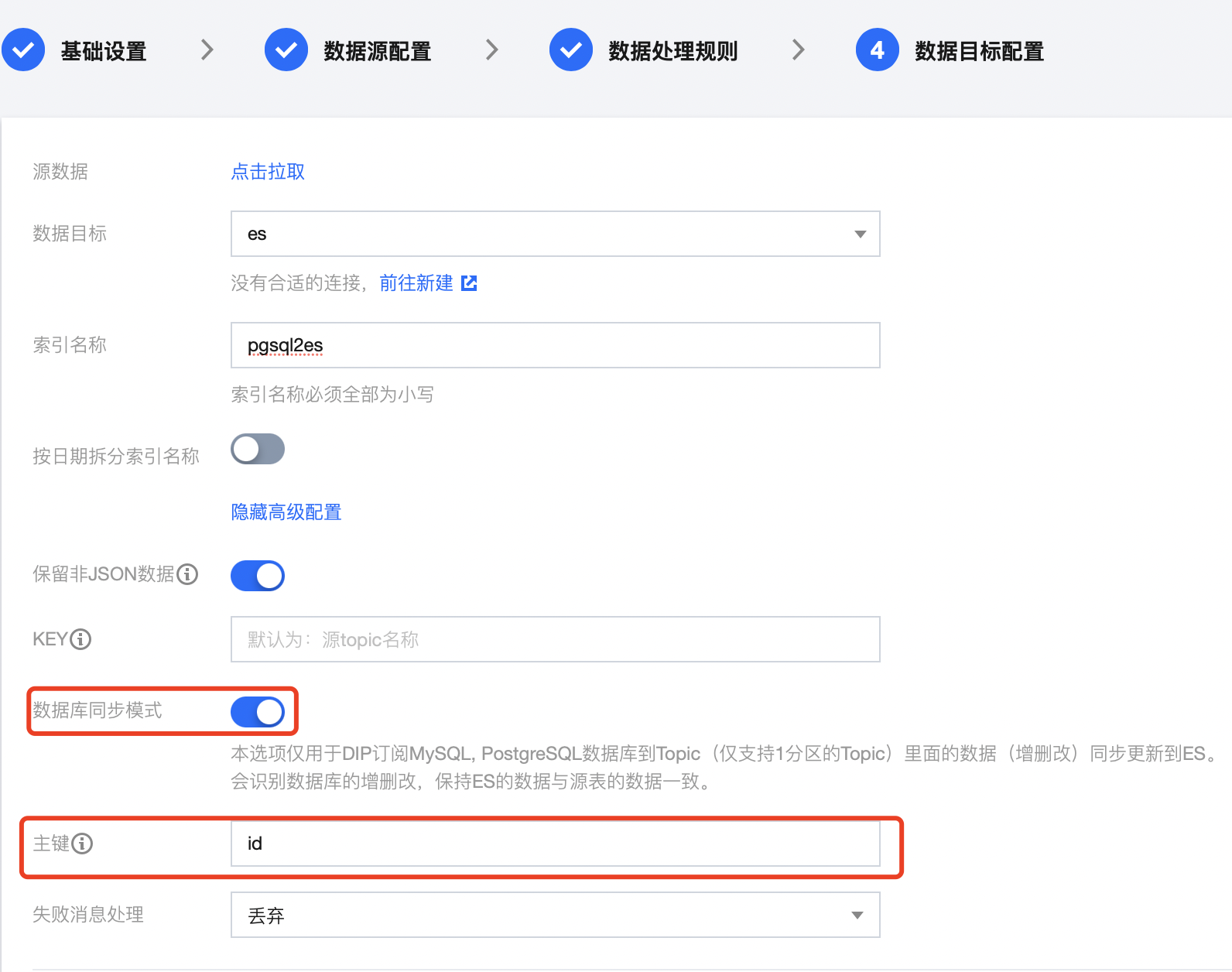
3. 下一步中数据处理可根据实际情况进行配置,这里不进行相关配置,使用原始消息数据。最后进行 ES 相关配置,其中主键为数据库表的主键名称。
注意
此模式需要开启 数据库同步模式,并填写表的主键的列名,如此处主键列名为 id。
4. 当数据任务运行后,即可在 ES 对应的索引中查询到相应的消息。
