

文档简介:



操作场景
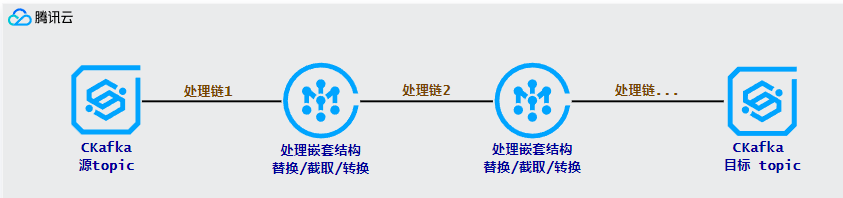
运行原理
前提条件
实际应用
处理字符串类型格式日志
66.249.65.159 - - [06/Nov/2014:19:10:38 +0600] "GET /news/53f8d72920ba2744fe873ebc.html
HTTP/1.1" 404 177 "-" "Mozilla/5.0 (iPhone; CPU iPhone OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML,
like Gecko) Version/6.0 Mobile/10A5376e Safari/8536.25 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
{"0": "66.249.65.159 - - [06/Nov/2014:19:10:38 +0600] ","1": "GET /news/53f8d72920ba2744fe873ebc.html HTTP/1.1","2": " 404 177 ","5": "Mozilla/5.0 (iPhone; CPU iPhone OS 6_0 like Mac OS X) AppleWebKit/536.26
(KHTML, like Gecko) Version/6.0 Mobile/10A5376e Safari/8536.25
(compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
}
{"1": "GET /news/53f8d72920ba2744fe873ebc.html HTTP/1.1","5": "Mozilla/5.0 (iPhone; CPU iPhone OS 6_0 like Mac OS X) AppleWebKit/536.26
(KHTML, like Gecko) Version/6.0 Mobile/10A5376e Safari/8536.25
(compatible; Googlebot/2.1; +http://www.google.com/bot.html)",
"0.0": "66.249.65.159 ","0.2": " [06/Nov/2014:19:10:38 +0600] ","2.1": "404","2.2": "177"}
{"1": "GET /news/53f8d72920ba2744fe873ebc.html HTTP/1.1","5": "Mozilla/5.0 (iPhone; CPU iPhone OS 6_0 like Mac OS X) AppleWebKit/536.26
(KHTML, like Gecko) Version/6.0 Mobile/10A5376e Safari/8536.25
(compatible; Googlebot/2.1; +http://www.google.com/bot.html)",
"0.0": "66.249.65.159 ","0.2": "06/Nov/2014:19:10:38 +0600","2.1": "404","2.2": "177"}
{"request": "GET /news/53f8d72920ba2744fe873ebc.html HTTP/1.1","http_user_agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 6_0 like Mac OS X)
AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5376e Safari/8536.25
(compatible; Googlebot/2.1; +http://www.google.com/bot.html)",
"remote_addr": "66.249.65.159 ","dateTime": "06/Nov/2014:19:10:38 +0600","status": "404","body_bytes_sent ": "177"}
处理嵌套类型格式日志
{"@timestamp": 1648803500.63659,"@filepath": "/var/log/tke-log-agent/test7/c816991f-adfe-4617-8cf3-9997aea90ded
/c_tke-es-687995d557-n29jr_default_nginx-add90ccf49626ef42d5615a636aae
74d6380996043cf6f6560d8131f21a4d8ba/jgw_INFO_2022-02-10_15_4.log",
"log": "15:00:00.000[4349811564226374227] [http-nio-8081-exec-64] INFO
com.qcloud.jgw.gateway.server.topic.TopicService",
"kubernetes": {"pod_name": "tke-es-687995d557-n29jr","namespace_name": "default","pod_id": "c816991f-adfe-4617-8cf3-9997aea90ded","labels": {"k8s-app": "tke-es","pod-template-hash": "687995d557","qcloud-app": "tke-es"},"annotations": {"qcloud-redeploy-timestamp": "1648016531476","tke.cloud.tencent.com/networks-status": "[{\n \"name\": \"tke-bridge\",\n
\"interface\": \"eth0\",\n \"ips\": [\n \"172.16.0.31\"\n ],\n
\"mac\": \"ae:61:12:4a:c2:ba\",\n \"default\": true,\n \"dns\": {}\n}]"
},"host": "10.0.96.47","container_name": "nginx","docker_id": "add90ccf49626ef42d5615a636aae74d6380996043cf6f6560d8131f21a4d8ba","container_hash": "nginx@sha256:e1211ac17b29b585ed1aee166a17fad63d344bc973bc63849d74c6452d549b3e","container_image": "nginx"}}
{"@timestamp": 1.64880350063659E9,"@filepath": "/var/log/tke-log-agent/test7/c816991f-adfe-4617-8cf3-9997aea90ded/
c_tke-es-687995d557-n29jr_default_nginx-add90ccf49626ef42d5615a636aae
74d6380996043cf6f6560d8131f21a4d8ba/jgw_INFO_2022-02-10_15_4.log",
"log": "15:00:00.000[4349811564226374227] [http-nio-8081-exec-64] INFO
com.qcloud.jgw.gateway.server.topic.TopicService",
"$.kubernetes.pod_name": "tke-es-687995d557-n29jr","$.kubernetes.namespace_name": "default","$.kubernetes.pod_id": "c816991f-adfe-4617-8cf3-9997aea90ded","$.kubernetes.labels": {"k8s-app": "tke-es","pod-template-hash": "687995d557","qcloud-app": "tke-es"},"$.kubernetes.annotations": {"qcloud-redeploy-timestamp": "1648016531476","tke.cloud.tencent.com/networks-status": "[{\n \"name\": \"tke-bridge\",\n
\"interface\": \"eth0\",\n \"ips\": [\n \"172.16.0.31\"\n ],\n
\"mac\": \"ae:61:12:4a:c2:ba\",\n \"default\": true,\n \"dns\": {}\n}]"
},"$.kubernetes.host": "10.0.96.47","$.kubernetes.container_name": "nginx","$.kubernetes.docker_id": "add90ccf49626ef42d5615a636aae74d6380996043cf6f6560d8131f21a4d8ba","$.kubernetes.container_hash": "nginx@sha256:e1211ac17b29b585ed1aee166a17fad63d344bc973bc63849d74c6452d549b3e","$.kubernetes.container_image": "nginx"}
{"@timestamp": 1648803500.63659,"@filepath": "/var/log/tke-log-agent/test7/c816991f-adfe-4617-8cf3-9997aea90ded
/c_tke-es-687995d557-n29jr_default_nginx-add90ccf49626ef42d5615a636aae
74d6380996043cf6f6560d8131f21a4d8ba/jgw_INFO_2022-02-10_15_4.log",
"log": "15:00:00.000[4349811564226374227] [http-nio-8081-exec-64] INFO
com.qcloud.jgw.gateway.server.topic.TopicService",
"$.kubernetes.pod_name": "tke-es-687995d557-n29jr","$.kubernetes.namespace_name": "default","$.kubernetes.pod_id": "c816991f-adfe-4617-8cf3-9997aea90ded","$.kubernetes.host": "10.0.96.47","$.kubernetes.container_name": "nginx","$.kubernetes.docker_id": "add90ccf49626ef42d5615a636aae74d6380996043cf6f6560d8131f21a4d8ba","$.kubernetes.container_hash": "nginx@sha256:e1211ac17b29b585ed1aee166a17fad63d344bc973bc63849d74c6452d549b3e","$.kubernetes.container_image": "nginx","$.kubernetes.labels.k8s-app": "tke-es","$.kubernetes.labels.pod-template-hash": "687995d557","$.kubernetes.labels.qcloud-app": "tke-es","$.kubernetes.annotations.qcloud-redeploy-timestamp": "1648016531476","$.kubernetes.annotations.tke.cloud.tencent.com/networks-status": "[{\n
\"name\": \"tke-bridge\",\n \"interface\": \"eth0\",\n \"ips\": [\n
\"172.16.0.31\"\n ],\n \"mac\": \"ae:61:12:4a:c2:ba\",\n \"default\": true,\n \"dns\": {}\n}]"
}
{"@timestamp": 1.64880350063659E9,"@filepath": "/var/log/tke-log-agent/test7/c816991f-adfe-4617-8cf3-9997
aea90ded/c_tke-es-687995d557-n29jr_default_nginx-add90ccf49626ef42d5615a636
aae74d6380996043cf6f6560d8131f21a4d8ba/jgw_INFO_2022-02-10_15_4.log",
"log": "15:00:00.000[4349811564226374227] [http-nio-8081-exec-64] INFO
com.qcloud.jgw.gateway.server.topic.TopicService",
"pod_name": "tke-es-687995d557-n29jr","namespace_name": "default","pod_id": "c816991f-adfe-4617-8cf3-9997aea90ded","host": "10.0.96.47","container_name": "nginx","docker_id": "add90ccf49626ef42d5615a636aae74d6380996043cf6f6560d8131f21a4d8ba"}
处理字符串序列化 JSON 格式日志
{"key": " {\n \"categories\": [\"dev\"],\n \"created_at\":
\"2020-01-05 13:42:19.324003\",\n \"icon_url\": \"https://assets
.chucknorris.host/img/avatar/chuck-norris.png\",\n \"id\":
\"elgv2wkvt8ioag6xywykbq\",\n \"updated_at\": \"2020-01-05
13:42:19.324003\",\n \"url\": \"https://api.chucknorris.io/jokes
/elgv2wkvt8ioag6xywykbq\",\n \"value\": \"Chuck Norris's keyboard
doesn't have a Ctrl key because nothing controls Chuck Norris.\"\n }\n"
}
{"key": " {\n \"categories\": [\"dev\"],\n \"created_at\":
\"2020-01-05 13:42:19.324003\",\n \"icon_url\": \"https://assets.
chucknorris.host/img/avatar/chuck-norris.png\",\n \"id\": \"elgv2wkvt8i
oag6xywykbq\",\n \"updated_at\": \"2020-01-05 13:42:19.324003\",\n
\"url\": \"https://api.chucknorris.io/jokes/elgv2wkvt8ioag6xywykbq\",\n
\"value\": \"Chuck Norris's keyboard doesn't have a Ctrl key because
nothing controls Chuck Norris.\"\n }\n"
}
{"key.categories": ["dev"],"key.created_at": "2020-01-05 13:42:19.324003","key.icon_url": "https://assets.chucknorris.host/img/avatar/chuck-norris.png","key.id": "elgv2wkvt8ioag6xywykbq","key.updated_at": "2020-01-05 13:42:19.324003","key.url": "https://api.chucknorris.io/jokes/elgv2wkvt8ioag6xywykbq","key.value": "Chuck Norris's keyboard doesn't have a Ctrl key because nothing controls Chuck Norris."}
{"categories": ["dev"],"created_at": "2020-01-05 13:42:19.324003","icon_url": "https://assets.chucknorris.host/img/avatar/chuck-norris.png","id": "elgv2wkvt8ioag6xywykbq","updated_at": "2020-01-05 13:42:19.324003","url": "https://api.chucknorris.io/jokes/elgv2wkvt8ioag6xywykbq","value": "Chuck Norris's keyboard doesn't have a Ctrl key because nothing controls Chuck Norris."}
目前 RAW JSON 只支持解析 MAP 类型的数据。当最外层为 List 类型时,例如 "[\"test1\",\"test2\"]",
或者 "[{\"key\":\"value\"}]",由于无法解析合适的键值,因此将会提示解析失败。
