

腾讯云消息队列 CKafka 实战教程 - 替换 Canal 实现 MySQL 数据库订阅
文档简介:
背景:
Canal 是阿里巴巴开源的一款通过解析 MySQL 数据库增量日志,达到增量数据订阅和消费目的 CDC 工具。Canal 解析 MySQL 的 binlog 后可投递到 kafka 一类的消息中间件,供下游系统进行分析处理。



背景
Canal 是阿里巴巴开源的一款通过解析 MySQL 数据库增量日志,达到增量数据订阅和消费目的 CDC 工具。Canal 解析 MySQL 的 binlog 后可投递到 kafka 一类的消息中间件,供下游系统进行分析处理。
如果您正在或考虑使用 Canal 同步 MySQL 的增量变更记录到 kafka,腾讯云 CKafka 连接器提供了完美兼容此场景的能力。
本文介绍 Canal 拉取 MySQL 变更记录并投递到 kafka 的简易使用场景以及 CKafka 连接器相应的替换处理方式。
CKafka 连接器订阅 MySQL 功能列表
允许选择多库多表。
允许指定根据队列消息进行分区同步。
允许通过正则匹配选择多表。
支持存量数据的同步。
同时支持 DDL、DML 类型的变更。
兼容 Canal、debezium 等消息格式。
案例说明
前提:已有 MySQL 实例和 kafka 实例
Canal 订阅 MySQL 变更记录到 kafka
1. 下载 canal server: canal.deployer-1.1.x.tar.gz 并解压。
tar -zxvf canal.deployer-1.1.x.tar.gz
2. 进入解压目录,配置 conf/example/instance.properties 文件,下面展示必须配置的 mysql 实例信息以及消息中间件的 topic、partition 等信息:
canal.instance.master.address=xx.xx.xx.xx:3306canal.instance.dbUsername=usercanal.instance.dbPassword=passwordcanal.mq.topic=canal-test-1canal.mq.partition=0
3. 进入解压目录,配置 conf/canal.properties 文件,下面展示必须配置的消息中间件实例信息:
canal.serverMode = kafkakafka.bootstrap.servers = xx.xx.xx.xx:9092kafka.acks = allkafka.compression.type = nonekafka.batch.size = 16384kafka.linger.ms = 1kafka.max.request.size = 1048576kafka.buffer.memory = 33554432kafka.max.in.flight.requests.per.connection = 1kafka.retries = 0
4. 启动 canal server:
sh bin/startup.sh
启动 canal server 后,Canal 开始根据配置获取 MySQL 的增量变更消息并推送到 kafka 集群。
CKafka 连接器 订阅 MySQL 变更记录到 kafka
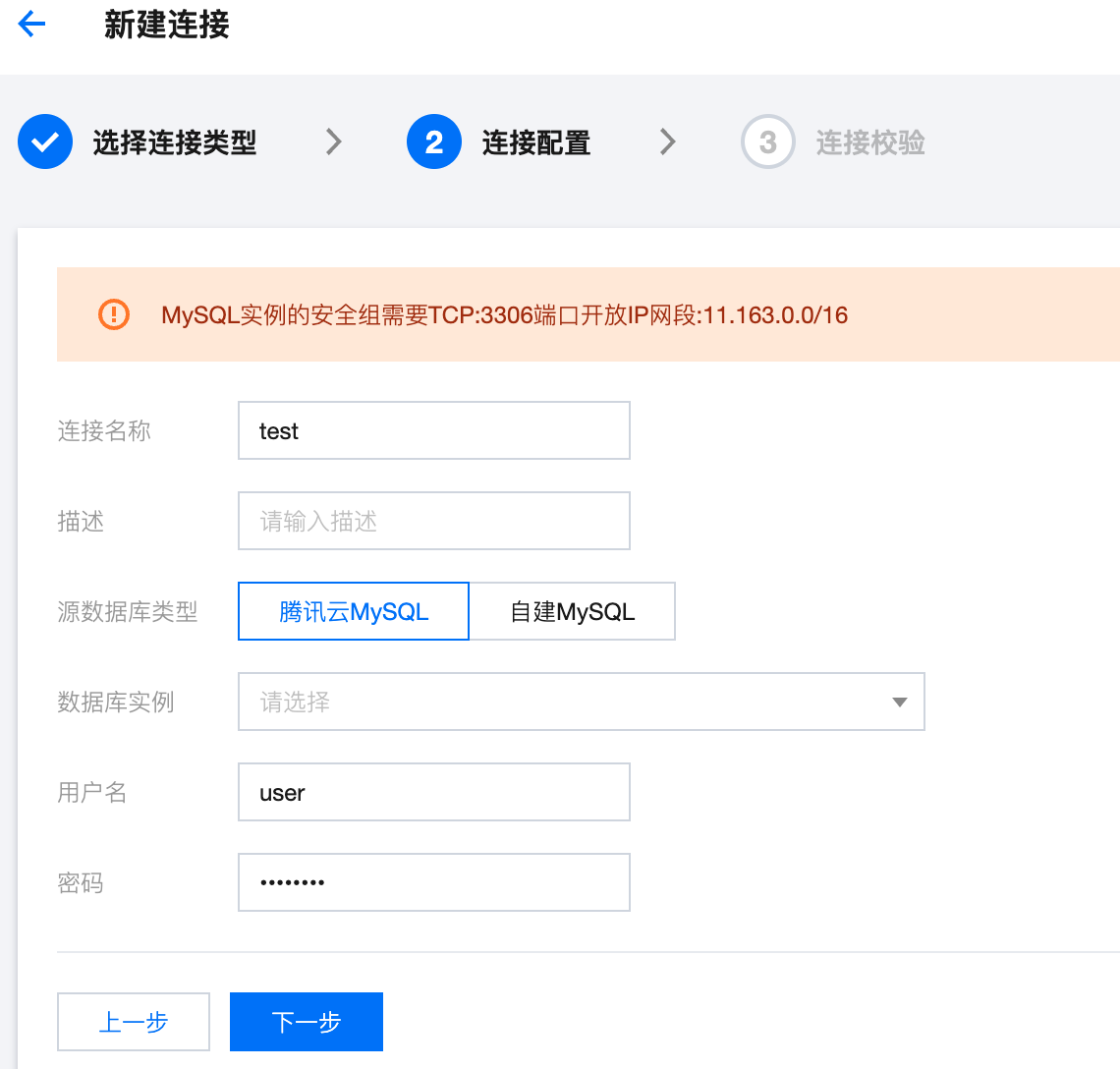
1. 新建连接,选择 MySQL 实例,CKafka 连接器同时支持腾讯云 MySQL 实例和云上自建 MySQL 实例:
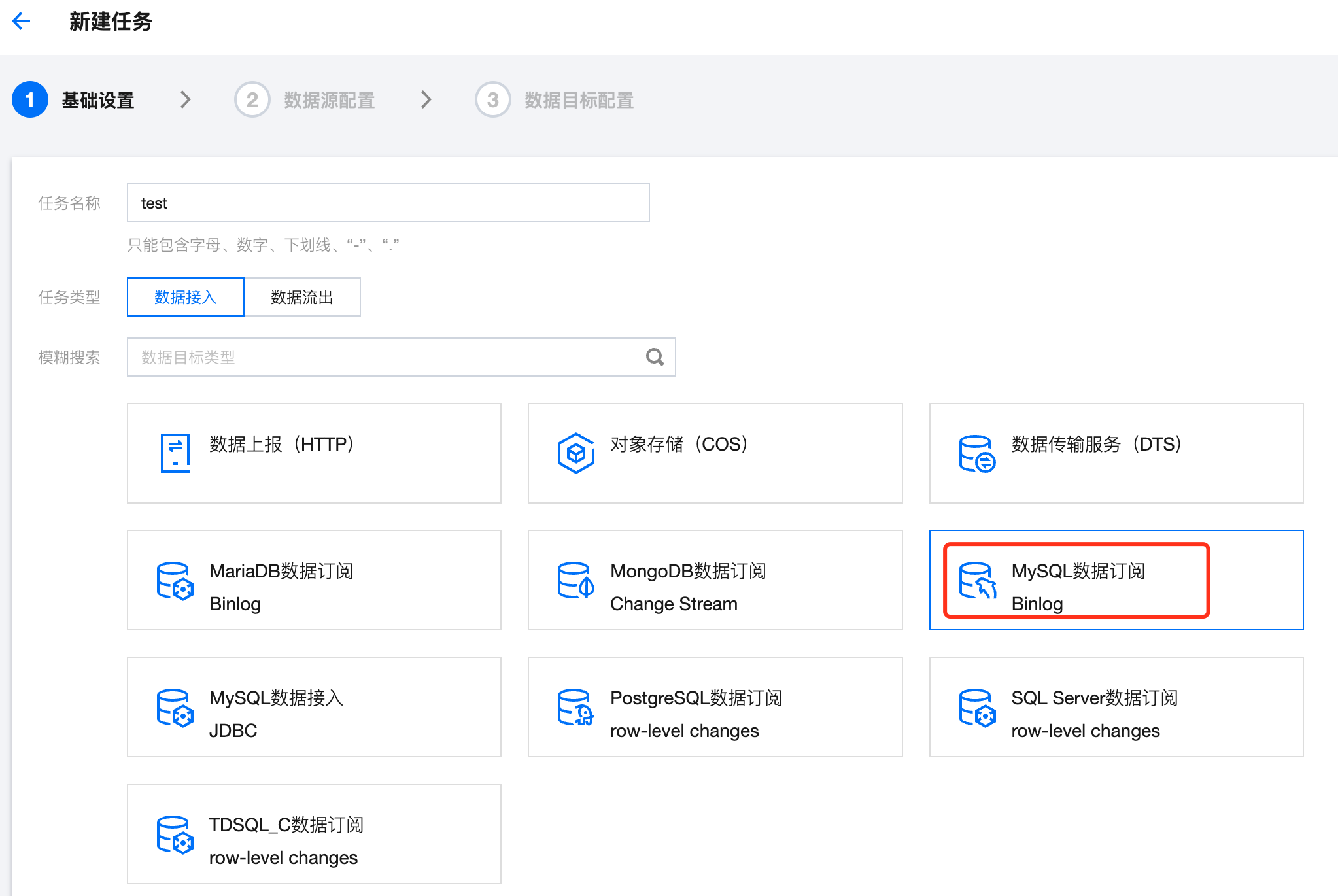
2. 新建数据接入任务,选择 MySQL 数据订阅(Binlog):
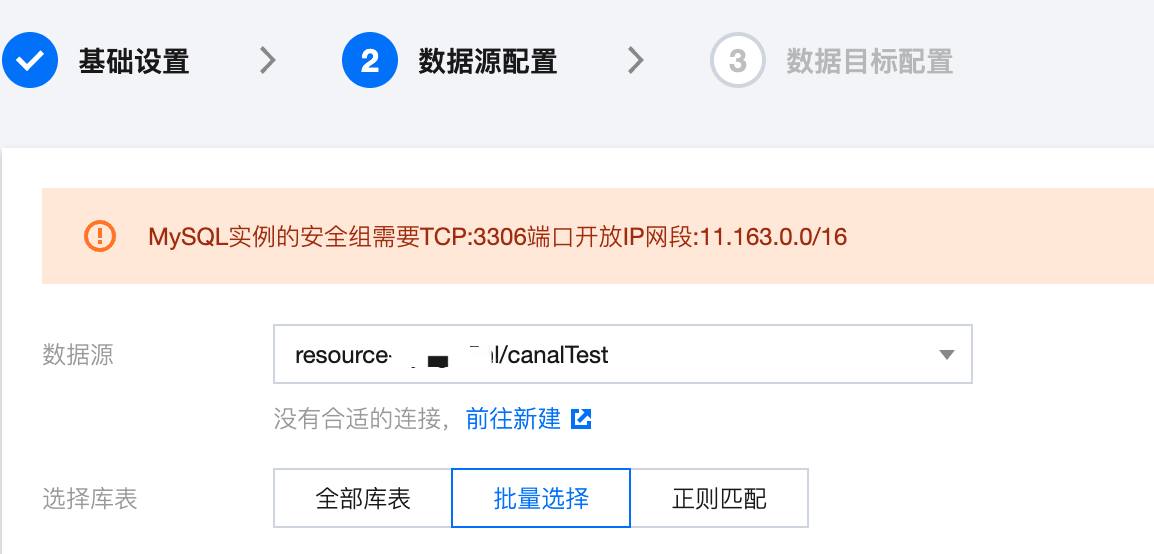
3. 数据源选择第一步中配置的连接,CKafka 连接器支持多种订阅库表的方式,包括全部库表、批量选择、正则匹配:
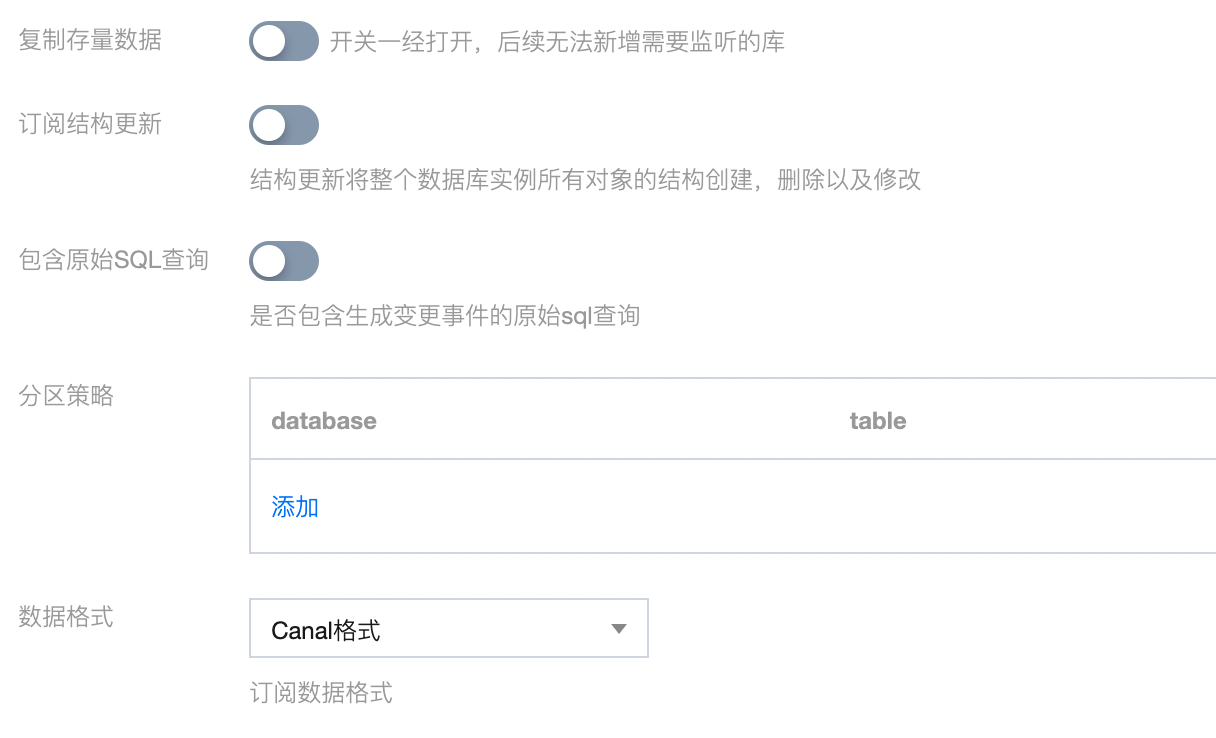
4. CKafka 连接器提供了高级配置选项,您可以根据业务需求自行进行选择配置,其中数据格式选择 Canal 格式:
5. 最后配置 Canal 的数据目标,CKafka 连接器支持将消息推送到 Ckafka 实例中的 Topic 或单独创建的弹性 Topic。
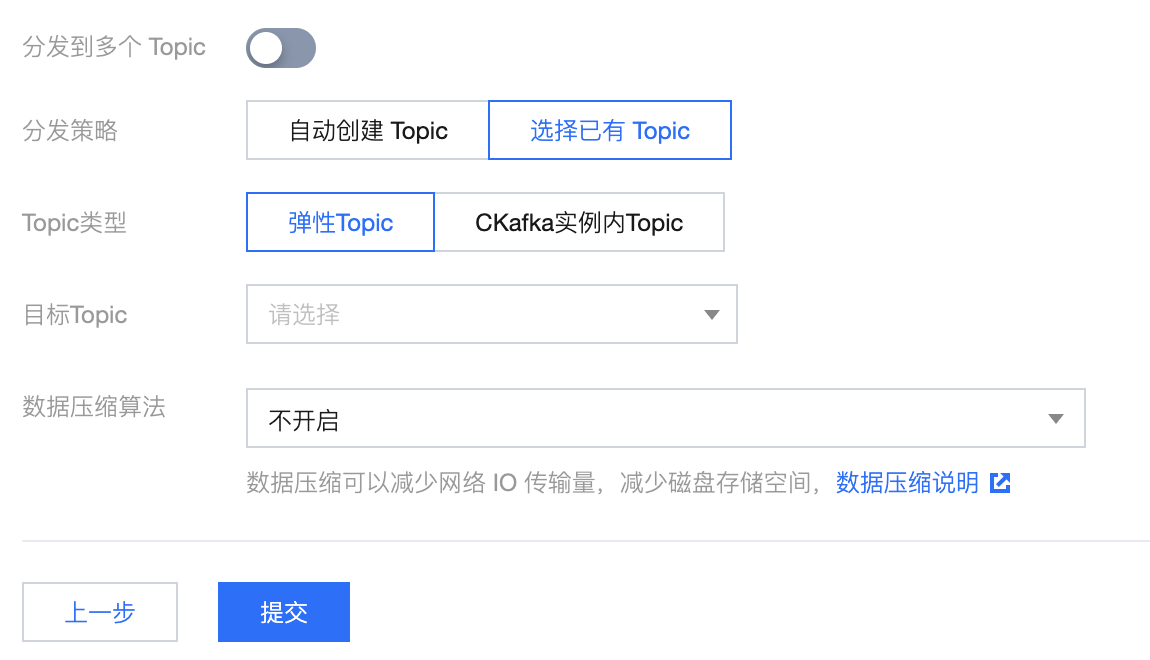
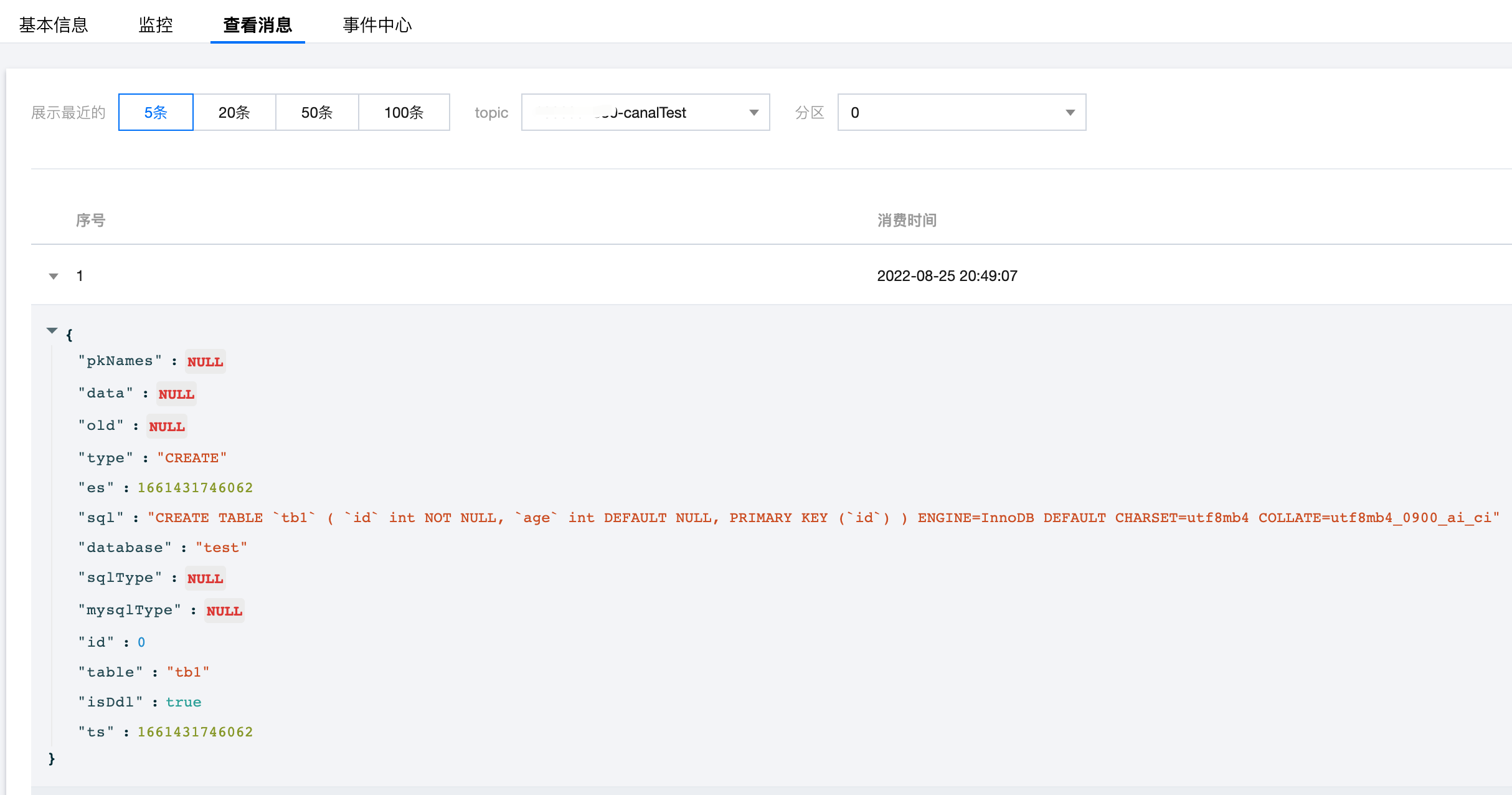
6. 可在控制台查看 Topic 的落盘消息情况:
更多功能
多种上游数据源的订阅
除了订阅 MySQL 数据源,CKafka 连接器同时支持订阅其他多种上游数据源,如 Postgresql、MongoDB、MariaDB、SQL Server 等。
可视化实时监控面板
CKafka 连接器提供了可视化的实时监控面板,可以一键更改配置信息、一键查看各种性能指标、一键查看 Topic 中落盘的消息内容,能够做到高可靠、免运维。
对标 logstash 的数据处理
CKafka 连接器提供了对标 logstash 的数据处理能力,仅需通过界面进行编辑即可创建多种数据处理规则。详情参见 数据处理规则说明。
多种下游数据源的投递
CKafka 连接器支持多种下游数据源的消息推送功能,包括 Elastic Search、ClickHouse 等。如果您正在或考虑使用 Canal 将消息同步到 kafka 以外的其他数据源,CKafka 连接器同样提供了相应的能力。
