

腾讯云容器服务实战教程 - 原生节点提升集群装箱率
文档简介:
操作场景:
原生节点专用调度器 可以有效解决集群中装箱率高但利用率低的问题。通过使用原生节点专用调度器的节点放大能力,可以提高节点的装箱率,从而提升整体资源利用率,而无需对业务进行任何修改或重启操作。



操作场景
原生节点专用调度器 可以有效解决集群中装箱率高但利用率低的问题。通过使用原生节点专用调度器的节点放大能力,可以提高节点的装箱率,从而提升整体资源利用率,而无需对业务进行任何修改或重启操作。
然而,放大系数的配置应该如何确定?相应的水位线又应该如何搭配使用,以确保节点放大后的稳定性?这些问题直接关系到功能的稳定性和有效性。此外,放大能力带来的收益和风险具体有哪些?
原生节点放大的利与弊
|
收益
|
风险
|
|
1. 提高资源利用率:通过虚拟放大,可以更有效地利用节点的计算和存储能力,防止资源被占用后的空闲问题。这有助于降低成本,从而提高整体运行效率。
2. 业务零成本使用:原生节点放大能力调整的是节点的可调度容量,对业务零侵入零改造零迁移。这有助于快速测试新功能,并应用到实际生产环境中。
|
1. 资源争抢:如果节点上运行的容器都试图使用超分配的资源,这可能导致资源争抢,从而降低系统性能和稳定性。
2. 注意放大过度:如果节点上的工作负载的实际需求超过了可用资源,可能导致业务受损甚至导致系统崩溃和停机。
|
本文以第一视角的方式提供原生节点放大能力的最佳实践,帮助您充分发挥放大能力的同时降低功能风险。最佳实践主要包括以下五个步骤:
步骤1:寻找典型的需要放大的节点,即装箱率高但利用率低的节点。
步骤2:确定节点的利用率目标。只有明确目标,才能确定合理的放大系数配置数值。
步骤3:根据节点利用率目标和现状确定放大系数和水位线。
步骤4:选择目标节点,将这些节点上的 Pod 调度到放大的节点上。
步骤5:在步骤4中重新调度 Pod 运行后,可以下线目标节点。
操作步骤
步骤1:观察节点当前装箱率和利用率
说明:
装箱率和利用率定义如下:
装箱率:节点上所有 Pod 的 Request 之和除以节点的真实容量规格。
利用率:节点上所有 Pod 的实际使用量之和除以节点的真实容量规格。
TKE 提供了 TKE Insight,方便您直接查看节点的装箱率和利用率走势图,详情请参见 Node Map。
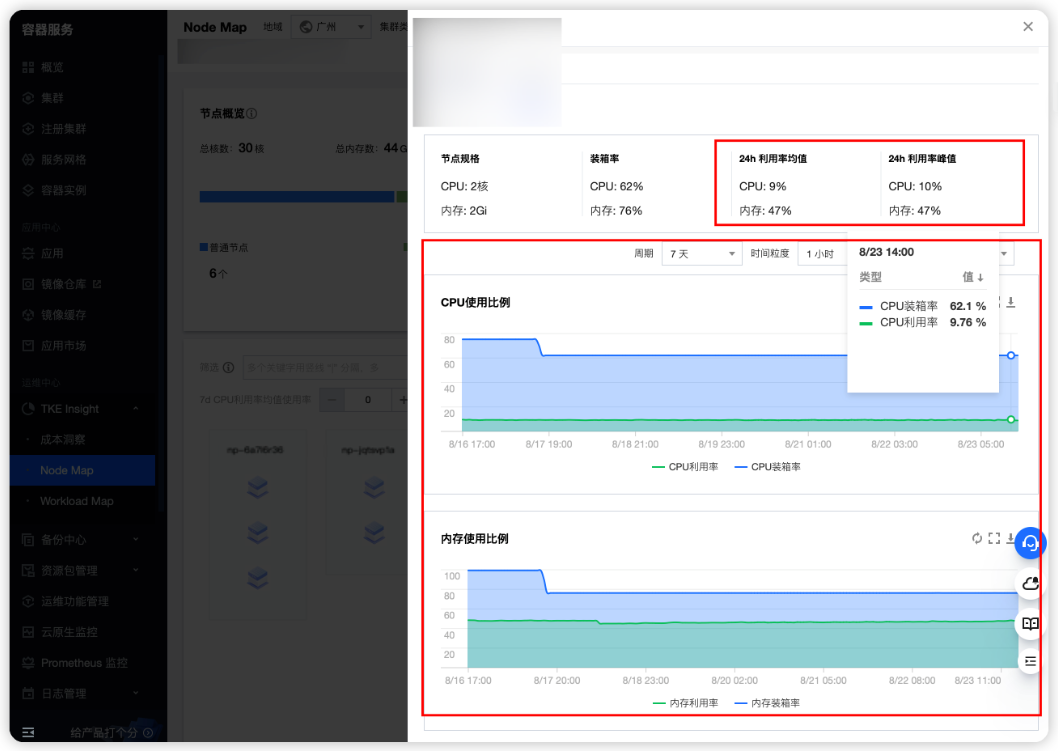
装箱率和利用率的关系的分析如下:
1. 装箱率高,利用率高
例如:装箱率90%以上,CPU利用率50%以上,或者内存利用率90%以上。
说明:节点资源使用情况合理,整体安全稳定,但需要注意节点内存可能会出现 OOM(Out of Memory)的情况。
建议:最好配置运行时水位90%,以防止节点稳定性风险。
2. 装箱率高,利用率低
例如:装箱率90%以上,CPU 利用率50%以下(如:10%),或者内存利用率90%以下(30%)。
说明:节点上的 Pod 存在过配的情况,即资源的申请量远大于实际使用量。由于装箱率已经很高,无法调度更多的 Pod,导致节点利用率无法提升。
建议:通过虚拟放大原生节点的规格,让节点的装箱率突破100%的上限,从而调度更多的 Pod,提升节点的利用率。
3. 装箱率低,利用率高
例如:装箱率90%以下(如50%),CPU 利用率50%以上,或者内存利用率90%以上。
说明:节点上的 Pod 普遍存在超卖场景,即 Limit(资源上限)大于 Request(资源需求),或者 Pod 没有配置 Request。
建议:这样配置的 Pod 的 QoS(Quality of Service)等级较低,在节点高负载时可能会重启甚至重新调度。需要确认这种配置的 Pod 是否是低优先级 Pod。此外,还建议再配置运行时水位90%,以防止节点稳定性风险。
4. 装箱率低,利用率低
例如:装箱率90%以下(如50%),CPU 利用率50%以下(如:10%),或者内存利用率90%以下(30%)。
说明:节点没有充分使用。
建议:可以调度更多的 Pod 到该节点上,或者将该节点上的 Pod 驱逐到其他节点上后,下线该节点。另外,也可以考虑更换一个更小规格的节点。
步骤2:定节点利用率目标
在设置合理的节点放大系数和水位线时,需要确定节点的利用率目标,以确保高利用率的同时防止节点出现异常。以下是涉及多个利用率指标的示例:
节点 CPU 利用率:根据腾讯内部上云成熟度大规模落地的经验,将节点的 CPU 利用率峰值设定为50%是一个比较理想的目标。
节点内存利用率:通过对百万业务规模的分析,发现节点的内存利用率普遍较高,且波动没有 CPU 大。因此,将节点的内存利用率峰值设定为90%是一个比较理想的目标。
根据实际情况和业务需求,您可以根据这些指标来设定节点的利用率目标,以便在放大节点时保持节点的稳定性和高效利用。
步骤3:定放大系数和水位线
在了解节点当前利用率现状和目标后,可以确定节点的放大系数和水位线,以达到目标利用率。放大系数表示节点容量可以放大的倍数。示例如下:
假设当前利用率为20%,目标利用率为40%。这意味着还可以放入当前一倍的业务到该节点上,因此节点的放大系数需要配置为2。
假设当前利用率为15%,目标利用率为45%。这意味着还可以放入当前三倍的业务到该节点上,因此节点的放大系数需要配置为3。
注意:
通常使用峰值来查看当前利用率,以确保在业务波峰时有足够的资源使用。
放大系数的计算公式如下:
CPU 放大系数 = CPU 目标利用率 / CPU 当前利用率
内存放大系数 = 内存目标利用率 / 内存当前利用率
以 步骤1 中的示例为例:
当前 CPU 利用率峰值为10%,内存利用率峰值为47%。假设 CPU 目标利用率为50%,内存目标利用率为90%。
则 CPU 的放大系数为5(注意不要设置得太高,以免 CPU 够用但节点内存出现瓶颈);内存的放大系数为2。
确定目标利用率后,可以根据目标来设置水位线。例如:
调度时水位:建议设置小于等于目标利用率,以允许未达到目标利用率的节点持续调度 Pod。设置得太高可能导致节点过负载。例如,如果目标 CPU 利用率为50%,可以将 CPU 的调度时水位设置为40%。
运行时水位:建议设置大于等于目标利用率,以防止利用率过高导致节点过负载。例如,如果目标 CPU 利用率为50%,可以设置 CPU 的运行时水位为60%。
步骤4:往放大的节点调度 Pod
只有将 Pod 调度到放大的节点上,才能提升节点的资源利用率。有两种方式可以实现:
1. 封锁其他节点:将新需要调度的 Pod 仅调度到放大的节点上,阻止其他节点接收新的 Pod 调度请求。
2. 使用 Workload 的标签选择器能力:通过标签选择器,将 Pod 指定调度到放大的节点上。
建议:
在进行节点放大时,最好选择那些容易下线的节点,将这些节点上的 Pod 重新调度到放大的节点上。这些节点可能包括:
Pod 数量很少的节点。
按量计费节点。
快到期的包年包月的节点。
如果您指定了节点的 CPU 和内存放大系数,可以通过查看与放大系数相关的 Annotation:expansion.scheduling.crane.io/cpu,expansion.scheduling.crane.io/memory来确认。示例如下:
kubectl describe node 10.8.22.108...Annotations: expansion.scheduling.crane.io/cpu: 1.5 # CPU 放大系数expansion.scheduling.crane.io/memory: 1.2 # 内存放大系数...Allocatable:cpu: 1930m # 该节点原始可调度资源量ephemeral-storage: 47498714648hugepages-1Gi: 0hugepages-2Mi: 0memory: 1333120Kipods: 253...Allocated resources:(Total limits may be over 100 percent, i.e., overcommitted.)Resource Requests Limits-------- -------- ------cpu 960m (49%) 8100m (419%) # 该节点 Request 和 Limit 占用量memory 644465536 (47%) 7791050368 (570%)ephemeral-storage 0 (0%) 0 (0%)hugepages-1Gi 0 (0%) 0 (0%)hugepages-2Mi 0 (0%) 0 (0%)...
说明:
当前节点的原始 CPU 可调度量为1930m,节点上所有 Pod 的 CPU 请求总量为960m。在正常情况下,该节点最多只能调度970m的 CPU 资源(1930m - 960m)。然而,通过虚拟放大,该节点的 CPU 可调度量已经增加到2895m(1930m * 1.5),实际剩余的 CPU 可调度资源为1935m(2895m - 960m)。
此时,如果创建一个工作负载,只有一个 Pod,其 CPU 请求量为1500m,如果没有节点放大的能力,则无法将该 Pod 调度到该节点上。
apiVersion: apps/v1kind: Deploymentmetadata:namespace: defaultname: test-schedulerlabels:app: nginxspec:replicas: 1selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:nodeSelector: # 指定节点调度kubernetes.io/hostname: 10.8.20.108 # 指定使用被样例中的原生节点containers:- name: nginximage: nginx:1.14.2resources:requests:cpu: 1500m # 申请量大于放大之前的节点可调度量,但有小于放大之后的节点可调度量ports:- containerPort: 80
该工作负载创建成功:
% kubectl get deploymentNAME READY UP-TO-DATE AVAILABLE AGEtest-scheduler 1/1 1 1 2m32s
再次检查节点的资源占用情况:
kubectl describe node 10.8.22.108...Allocated resources:(Total limits may be over 100 percent, i.e., overcommitted.)Resource Requests Limits-------- -------- ------cpu 2460m (127%) 8100m (419%) # 该节点 Request 和 Limit 占用量。
可以看到,Request 总和超过了节点原始可调度量,节点规格放大成功。
memory 644465536 (47%) 7791050368 (570%)ephemeral-storage 0 (0%) 0 (0%)hugepages-1Gi 0 (0%) 0 (0%)hugepages-2Mi 0 (0%) 0 (0%)
步骤5:移除多余节点
在 步骤4 中选择的节点上,当节点上的非 DaemonSet 的 Pod 全部移出后,可以将该节点移出并删除,从而用更少的节点承载相同的业务量。
通过以上方式,可以对集群中的 Pod 进行规整。例如,假设集群中有20个原生节点和20个普通节点,规格相同,整体资源利用率为 CPU 10%和内存 40%。通过将20个原生节点的 CPU 和内存放大一倍,可以将20个普通节点上的 Pod 迁移至原生节点上。这样,原生节点的资源利用率将提高到 CPU 20%和内存 80%。同时,普通节点上将没有 Pod 存在,因此可以将这些普通节点从集群中移除,从而减少了一半的节点规模。
通过以上方式,可以对集群中的 Pod 进行规整。例如,假设集群中有20个原生节点和20个普通节点,规格相同,整体资源利用率为 CPU 10%和内存 40%。通过将20个原生节点的 CPU 和内存放大一倍,可以将20个普通节点上的 Pod 迁移至原生节点上。这样,原生节点的资源利用率将提高到 CPU 20%和内存 80%。同时,普通节点上将没有 Pod 存在,因此可以将这些普通节点从集群中移除,从而减少了一半的节点规模。
