
实战:使用 DataSync 将 Oracle 数据库迁移到 GaussDB
|
在上篇文章中,介绍了使用SDR工具进行Oracle到GaussDB的数据迁移过程,文中提及过在SDR之前还曾使用DataSync工具进行迁移测试;虽然最终采用SDR作为正式迁移方案,但DataSync本身也有其可取之处,本文将对之前的测试过程做一个简单的回顾。
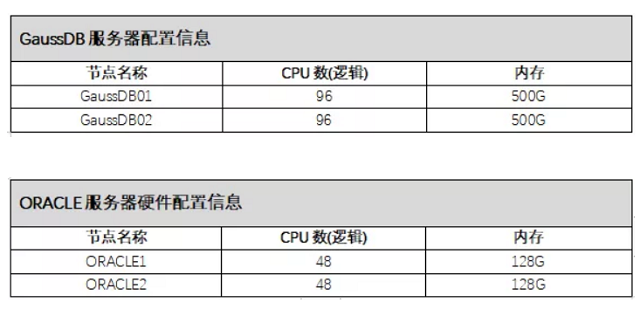
1、环境信息
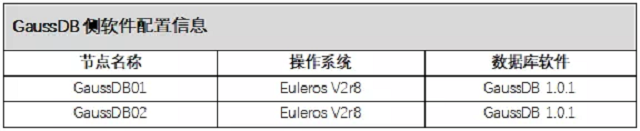
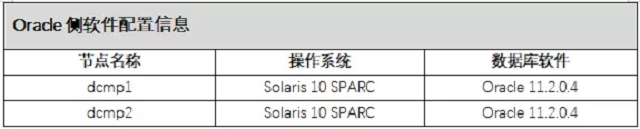
2)软件配置信息
GaussDB侧操作系统及数据库软件版本如下所示:
ORACLE侧操作系统及数据库软件版本如下所示:
由于本次文章的重点不在于环境的搭建,所以操作系统及GaussDB的安装过程就不细述。
Datasync是什么
1、Datasync工具使用注意事项
使用时必须确保迁移数据库的服务器和被迁移数据库的服务器可以正常连接。
使用时用户应提前创建好目标库表结构,确保源表与目标表的字段顺序和表结构一致、字段类型兼容。(并非必要条件)
使用时需保证通过配置的IP、端口、用户名、密码能够正确连接数据库。
使用时用户需要评估目标数据库占用空间和割接过程中使用的空间是否满足需求。
使用时确保已在运行迁移工具的设备安装JAVA,版本须为1.8及以上。
使用时确保当前运行迁移工具设备的IP已配置在源数据库和目标数据库的白名单中,避免数据迁移工具连接数据库失败。
用户需要将需要导出的源数据库JDBC驱动放置在dependency-jars中且驱动包名需要跟规定的一致,否则会导致连接数据库失败。
GaussDB 100 V300R001数据库密码不支持" "(空格)和";"(分号),否则工具无法使用zsql命令连接数据库。l 确保配置用户有权限执行相关操作,否则会导致运行工具达不到预期结果。
data_path配置项中所有路径均需遵循迁移工具路径白名单规则:路径只允许包含大小写字母、数字、 '\', '/', ':', '-', '_',不能以'-'开头,不能同时包含 / 和 \。
2、Datasync工具准备
在源库服务器及目标端服务器同时挂载迁移用的NFS文件系统。
源库操作:
mkdir /datasync mount -F nfs -o rw,bg,hard,rsize=32768,wsize=32768,vers=3,nointr,proto=tcp,suid 192.168.xxx.xx:/vx/tycj_dcmp_tmp /datasync
在目标端操作:
mount -t nfs -o rw,bg,hard,rsize=32768,wsize=32768,vers=3,nointr,proto=tcp,suid 188.0.xxx.xx:/vx/tycj_dcmp_tmp /datasync
2)上传和解压介质
① 上传介质到NFS目录
使用FTP工具上传GAUSSDB100-V300R001C00-DATASYNC.tar.gz 至/datasync目录。
② 解压介质
在源库服务器操作:
cd /datasync tar -xvf GAUSSDB100-V300R001C00-DATASYNC.tar.gz
tar -xvftar -zxvf DataSync.tar.gz。
3、检查java版本不低于1.8(源端目标端都要更新)
由于Datasync的脚本都需要依赖java驱动,要求服务器的java版本不低于1.8。
Java version “1.8.0_231 Java(TM) SE Runtime Environment (build 1.8.0_231-b11) Java HotSpot 64-Bit Server VM (build 25.231-b11, mixed mode)
4、把JDBC驱动包迁移到指定目录
由于datasync本身没有Oracle的JDBC的驱动包,需要提前把源库的JDBC驱动包拷贝到dependency-jars目录中(缺失这个驱动包,会在检查配置时提示无法连接Oracle库)。
在源库服务器执行:
cd $ORACLE_HOME/jdbc/ cp ojdbc6.jar/datasync/GAUSSDB100-V300R001C00-DATASYNC/DataSync/dependency-jars/ojdbc8-12.2.0.1.jar
注意:ojdbc8-12.2.0.1.jar这个命名是固定的,必须要改成同名文件才能识别。
3、Datasync配置
如下所示:
cfg.ini:配置服务器和数据库配置信息,必须配置该文件。 exp_obj.ini:配置需要导出或导入的库、用户或表,可以不配置该文件。 exclusive_obj.ini:配置迁移时需要排除的库、用户或表,可以不配置该文件。 ignore_ddl.ini:配置迁移时不要校验DDL表结构的库、用户或表,可以不配置该文件
2)配置密码密文
出于安全方面的考虑,迁移过程中需要用到的密码都必须使用密文方式记录在配置文件中,使用明文密码会被当做错误密码无法识别。因此在修改配置文件cfg.ini前,需要先将目标库服务器账号、源库数据库账号、目标库数据账号等账号密码生成对应密文。
生成密码密文方法如下:
① 生成导出数据库密码
② 生成导入数据库密码
③ 生成导入服务器密码
-pwd后面跟的数字表示cfg.ini文件中要生成密文的密码类型。取值范围是:整数,[1, 9]。
具体含义如下:
1:导出数据库密码; 2:导入数据库密码; 3:导入服务器密码; 4:导出操作所使用数据文件所在的远程服务器密码; 5:导入操作所使用数据文件所在的远程服务器密码; 6:导出数据库生成truststore文件设置的密码; 7:导出数据库生成keystore文件设置的密码; 8:导入数据库生成truststore文件设置的密码; 9:导入数据库生成keystore文件设置的密码。
PS:密码如果更新,或者重新生成新密文后,都需要更新配置文件里面的密文;另外往Gaussdb导入的时候不能使用root用户导入,必须使用其他账号。
3)新建存储导出文件目录(如果没有用NFS需要在源端和目标端分别创建)
4)修改配置文件cfg.ini(部分配置参数内容)
vi cfg.ini { "flow_type":1,导出程序 "export_db":{ "database_type":2, ##数据库类型Oracle "db":{ "ip":"192.168.xxx.xxx", "username":"username", "password":"B/AaX+yBemxxxxxxxx", ##刚刚生成的密文密码 "port":1522, "db_name":"db_name", "server_name":" server_name 1", "trust_store":"", "trust_store_password":"", "key_store":"", "key_store_password":"" } },
"import_db":{ "database_type":6, ##数据库类型为GaussDB "db":{ "ip":"192.168.xxx.xxx", "username":"username", "password":"Cbs48z0vL+AUyY1xxxxxxxxx", "port":40000, …… …… }, "server":{ "ip":"192.168.xxx.xxx", "username":"username", "password":"N2B+M6xIRQxxxxxxxxxxx", "pub_key_file":"", "port":22 } },
"data_path":{ "export_local_path":"/datasync/GAUSSDB100-V300R001C00-DATASYNC/DataSync/data", "export_remote_path":{ "ip":"", "username":"", "password":"", "pub_key_file":"", "port":22, "path":"" }, "import_local_path":"/datasync/GAUSSDB100-V300R001C00-DATASYNC/DataSync/data", …… …… } },
"option":{ …… …… "ignore_lost_table":3, ##自动创建缺失的表 "disable_trigger":true, ##导入时禁用触发器 "import_total_task":40, ##资源允许下开启更大并行可提高导入效率 "export_total_task":25, ##资源允许下开启更大并行可提高导出效率 …… ……. } }
部分参数配置可参考下表:
Datasync执行(离线导入+导出)
2)启动导出进程
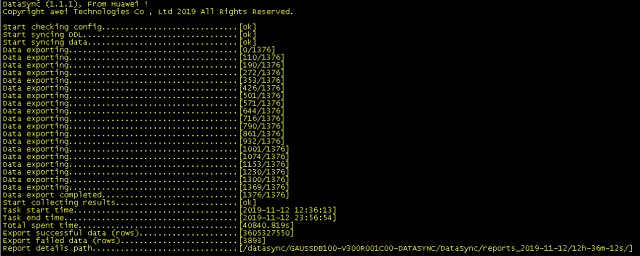
3)查看导出结果
2、在目标端执行
“flow_type”:2
2)手动导入源库所有表的DDL(可选)
在cfg.ini中有ignore_lost_table参数控制,可在目标库不存在导入表时,选择忽略该表并继续导入/报错并自动退出/自动创建不存在表。但在实际使用过程中,选择自动创建表时受到的影响因素太多,容易出现较多的创建失败对象,影响整体数据的导入成功率,所以建议手动导入DDL。
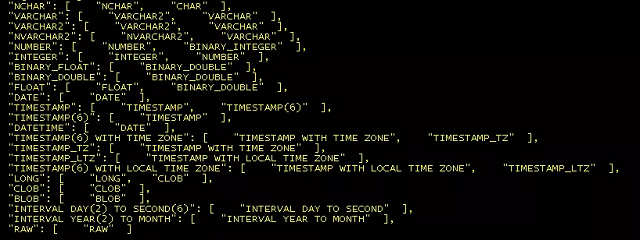
导入DDL的方式可通过在源库用dbms_metadata.get_ddl包导出所有DDL,并手动删除DDL中GaussDB不支持的参数(例如storage和maxtrans等)和修改需要转换的数据类型(例如:数据类型long需要改成clob等),在datasync的安装目录下有一个TypeMappers目录,里面有OracleToGauss.json文件,包含大部分Oracle迁移到GaussDB需要转换的数据类型,可作为参考。
OracleToGauss.json部分内容截图:
3)在目标库提前创建用户和表空间
用户、用户权限和用户的默认表空间需要提前手动创建,具体创建语法跟Oracle基本一致。这里就不一一细述。
4)启动导入进程(在目标库执行)
命令和选项都跟导出命令是一样的,区别就在于提前修改cfg.ini文件中的flow_type参数,从1改到2。
5)查看导入结果
导入进程跑完之后可以在安装目录的reports_日期目录下面的LoadReport.csv文件查看详细到的导入情况,下面是部分截图:
迁移结果的校验
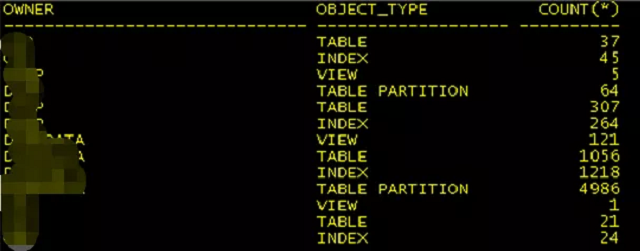
1、在源库执查看对象情况:
2、在目标库库执查看对象情况:
通过对比可以看到索引、视图等对象都有部分缺失,GaussDB暂时不支持DBLINK和存在索引字段总字节数不能超过3900等限制,这些需要协调业务层进行调整。
而在源库导出时部分表有中文乱码、业务表之间太多外键约束等问题,容易导致部分视图和索引会创建失败。这种情况可以根据报错信息,逐项修改。
小结
在整个迁移过程中,Datasync迁移数据的过程可以简单总结为:把源库数据的DDL和数据按根据定义的格式分别导出,并完成数据的校验和转换,通过load文件的形式导入到GaussDB中,跟ORACLE数据泵的导数迁移过程相似。而在实际操作当中,仍然会有诸如中文乱码/大字段表导出和校验慢/外键约束限制等等问题,需要根据实际报错信息进行逐一修改和调整。
在迁移测试的时候也发现,导出数据过程需要进行较长时间DDL和数据检验,即使开启并行导出也无法明显降低导出时间。另外,本次使用的Datasync版本暂时不支持增量备份,所以如要用Datasync进行数据迁移,可能需要准备较长的工程时间。
作者介绍
莫熙钟,新炬网络数据库运维专家。精通Oracle、MySQL、PostgreSQL等数据库运维技术,拥有Oracle OCP、MySQL OCP、GaussDB HCIP等认证,拥有丰富的数据库系统架构转型、分布式改造、数据迁移经验,擅长开源数据库转型技术支持,参与多个行业核心系统的Oracle到MySQL转型项目。2019年开始学习和研究华为GaussDB数据库运维技术,目前正在积极参与国产数据库转型改造项目和国产数据库通用型自动化运维工具的研发等工作。
相关文章 |







有话要说