
时序数据库 Prometheus 支撑百亿级话单实时全景监控
|
背景
随着流量业务的高速发展以及已经到来的5G时代,业务支撑系统的规模不断增大、服务不断增多,业务、应用和系统运行性能指标数据持续以指数级的速度增长,每日计费话单量已突破百亿。系统监控的实时性、准确性的能力不足成为运维工作的瓶颈。
江苏移动IT运维团队以SRE理念为指导,结合实时监控“高并发写入”、“低查询延时,高查询并发”、“轻量级存储”等实际诉求,深入研究时序数据库的特性和适用程度,打造符合自身系统运维特点的性能管理平台,实现百亿级话单处理过程的实时全景监控分析。
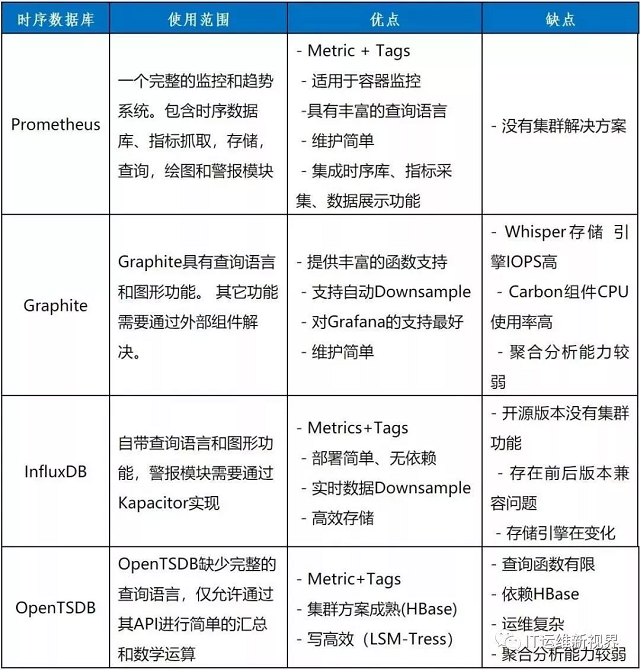
时序库选型
通过比较,我们发现Prometheus最适合搭建BOSS运维监控系统。单个的Prometheus实例就能实现每秒上百万的采样,同时支持对于采集数据的快速查询。Prometheus对于采样数据进行压缩存储,16字节的采样数据平均只需要1.37个字节的存储空间,极大减少了存储资源占用。查询实时数据时,磁盘I/O平均负载小于1%。
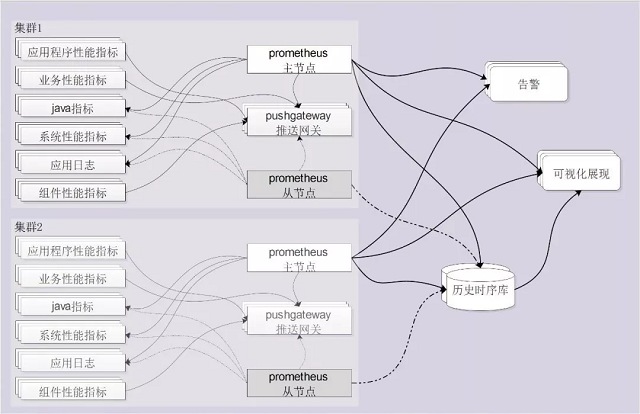
性能管理平台架构设计
1、根据业务系统的部署,我们在双中心各部署一套Prometheus集群。
2、对于系统、应用日志、Java应用我们采用拉取方式采集指标数据;对于应用、业务、组件的性能指标数据采用推送网关(pushgateway)暂存数据,然后再由Prometheus拉取的方式采集。
3、为保证实时采集和查询的高性能,采集Prometheus时序库中保存短期内较近数据,同时写入一份到远程的历史时序库中。
4、可视化展示和实时告警通过负载均衡从Prometheus和历史库中采集数据。
适配性改造
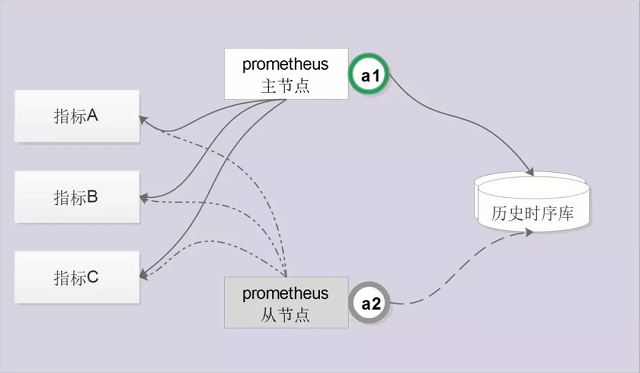
1、夯实高可用能力:原生的Prometheus部署都是单点的,不足以保证数据可用性,为此我们通过服务注册的方式实现了Prometheus的高可用性。集群启动时每个节点都尝试获取锁,获取成功的节点成为主节点执行任务,若主节点宕机,从节点获取锁成为主节点并接管服务。
高可用能力实现方式
2、优化数据存储方式:在Prometheus节点上保存短周期数据用于告警实时触发和展现,引入InfluxDB用于实时传输并保存长周期的历史数据,保证采集数据的连续性并为后续数据挖掘提供资源支撑。
3、自研改造推送网关组件:在实际使用过程中我们发现推送网关(pushgateway)中的数据有较大概率被重复采集到Prometheus中,容易产生错误的性能数据和误告警。为此我们在Prometheus的采集方法中增加从pushgateway拉取数据后主动删除数据的保障机制,确保数据采集的唯一性。
4、拓展集成数据展示方式:性能数据可视化展示原先采用Grafana原生组件,但是使用过程中发现插件配置灵活性不足,难以展现多种形式关联指标数据的情形。因此我们自研了可视化工具,实现涵盖系统、应用、业务性能等多维度指标的个性化展示,实时掌控系统健康状态。
5、更改时区:原生的Prometheus查询指标时页面显示的指标趋势图是根据GMT时间显示的,与北京时间相差8小时,为此我们将源码中获取时间的方式修改成从本地系统时间获取,成功解决了该问题。
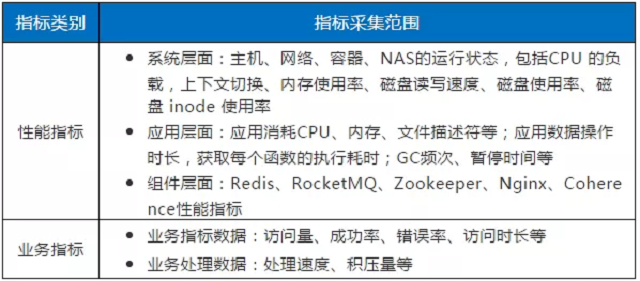
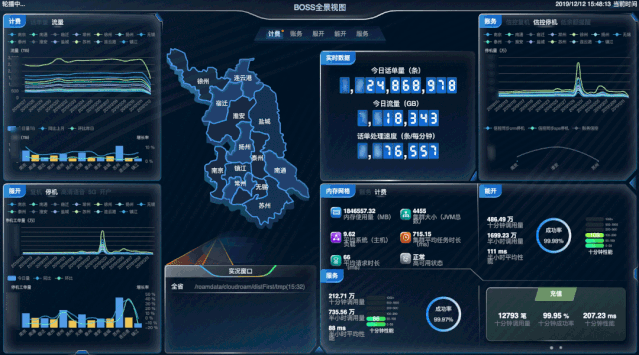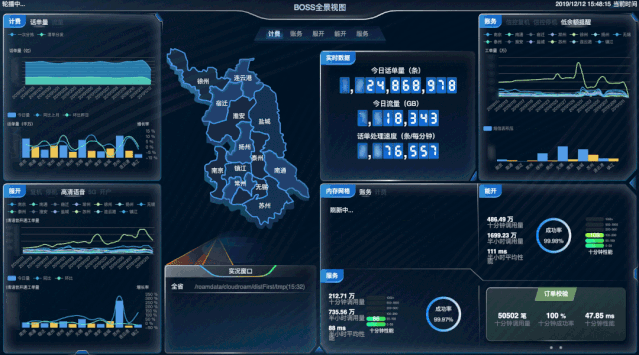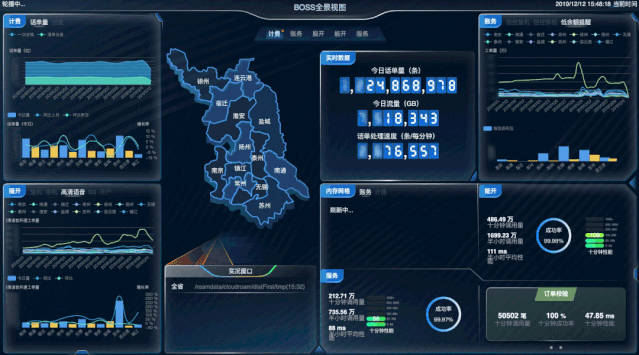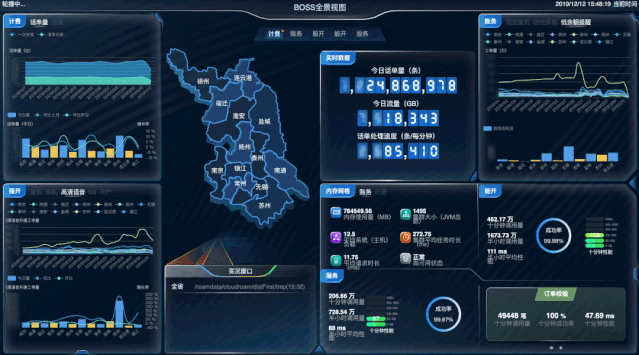
指标采集范围
实时展示
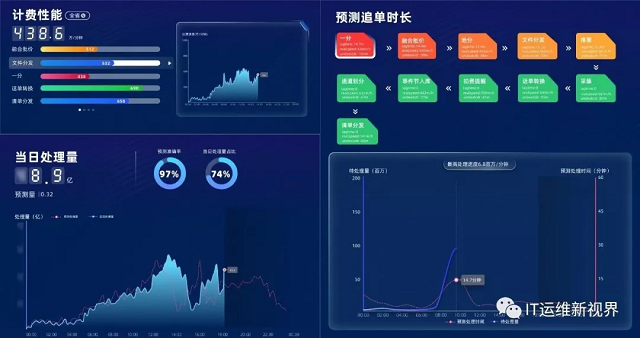
实时全景视图
趋势预测及异常检测
1、性能预测:通过对应用处理速度的实时监控、历史数据比对分析,自动计算应用处理最大速度,实时准确预测完成待处理话单所需时间。
2、业务趋势预测:通过对时序库中存储大量系统和业务指标数据按天、周、月维度进行平均、加权序时平均、移动平均、加权移动平均、特列统计等分析,预测未来话单处理趋势、系统资源利用趋势,为系统容量管理提供合理依据。
3、异常检测:通过对数据进行环比分析、同比分析、均值变化分析、相同时间窗口内数据的均值和标准差分析、局部数据波动分析、周期性特征分析等算法及时发现业务处理异常。
性能预测场景示意
总结与展望
该性能平台已成功应用在BOSS系统,未来将进一步总结经验并持续改进提升,陆续向其他业务支撑领域和管信领域进行推广。 |

有话要说