




数据湖是一个集中式存储库,可存储任意规模结构化和非结构化数据,支持大数据和AI计算。数据湖构建服务(Data Lake Formation,DLF)作为云原生数据湖架构核心组成部分,帮助用户简单快速地构建云原生数据湖解决方案。数据湖构建提供湖上元数据统一管理、企业级权限控制,并无缝对接多种计算引擎,打破数据孤岛,洞察业务价值。
产品特色
数据入湖
支持多种数据类型和入湖渠道
支持数据统一清洗
元数据服务
智能元数据识别服务
统一收集避免分散管理
权限管理
企业级数据权限管理
用户可以针对库、表、字段分别设置权限
多引擎对接
支持上游多种计算引擎
轻松构建全链路数据湖服务
生态开放
兼容Hive Metastore
提供多语言Open API,易集成
数据加速
独有JindoFS数据加速功能
提供高性能数据湖分析加速能力
应用场景
开源生态构建数据湖
典型场景
用户已经基于阿里云开源大数据生态系统(E-MapReduce,实时计算Flink,DLA等产品)来构建自己的数据处理分析平台,而在数据量飞速膨胀的趋势下,用户存储资源与计算资源扩容速度不匹配,有成本优化方面的诉求;大数据生态的丰富,用户的数据来源广泛,元数据分散较难管理,用户希望能统一管理不同存储中的元数据
方案价值
元数据管理
数据湖构建支持自动采集发现多引擎元数据,可做到统一管理,避免数据孤岛
生态优势
阿里云大数据团队提供专家级服务支持
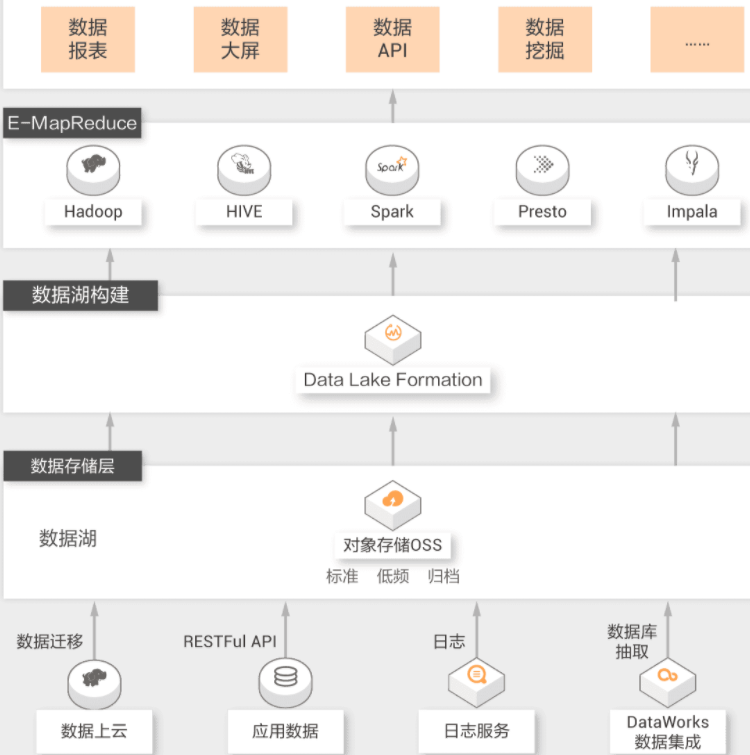
构建湖仓一体数据仓库
典型场景
数据仓库和数据湖,是大数据架构的两种设计取向。数据湖优先的设计,通过开放底层文件存储,给数据入湖带来了最大的灵活性。而数据仓库优先的设计,更加关注的是数据使用效率、大规模下的数据管理、安全/合规这样的企业级成长性需求。灵活性和成长性,对于处于不同时期的企业来说,重要性不同。随着用户业务的逐渐清晰与沉淀,用户面临着数据湖和数据仓库架构的融合,依托于阿里云数据仓库(MaxCompute、Hologres、ADB等产品)和数据湖构建产品,帮助用户打造湖仓一体的数据系统,让数据和计算在湖和仓之间自由流动,从而构建一个完整的有机的大数据技术生态体系
方案价值
免运维
数据湖构建产品提供用户全托管服务,仅需简单点击操作,就可以协助用户快速搭建起云上的数据湖系统
安全有保证
统一权限管理体系,可做到对数据库、表、列的权限控制。
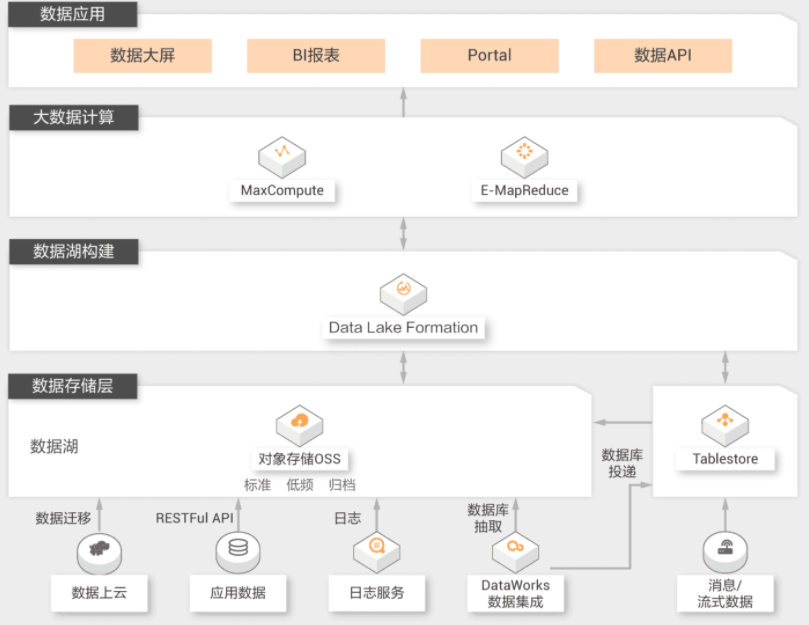
数据湖数据实时分析
典型场景
用户大量不同类型数据存储在OSS中,希望能对数据做各种多种维度的分析查询,如实时数据分析、OLAP查询,并将对应的结果反馈到业务系统中。同时用户希望能方便的对接云上多种计算引擎,在数据查询时能够直接进行,不需要提取全部数据到查询系统
方案价值
实时数据入湖
提供数据实时入湖能力,提供业务时效性
元数据自动发现
数据湖构建可以自动对数据进行抓取、编排和准备,以进行分析,避免复杂手动操作
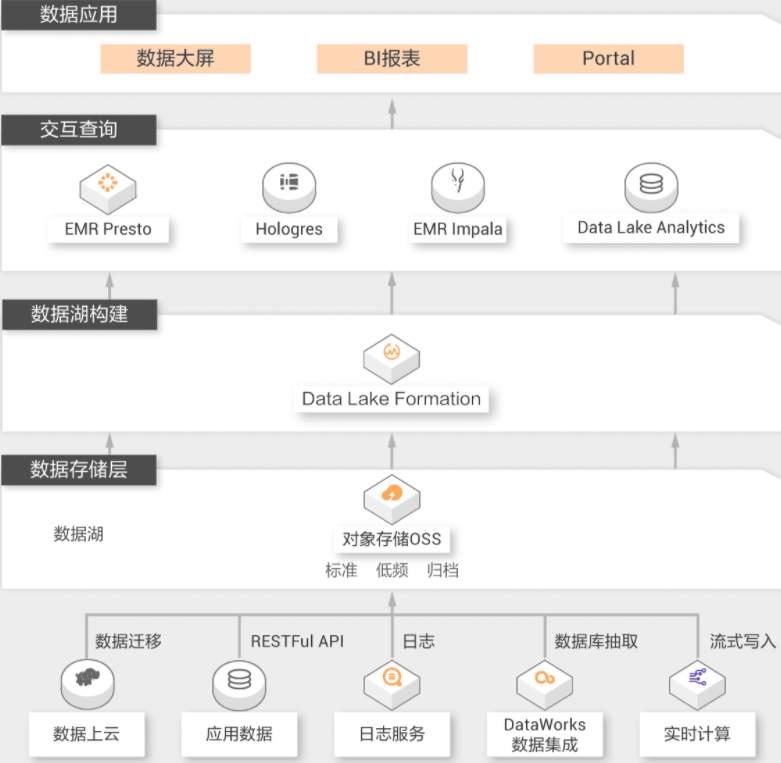
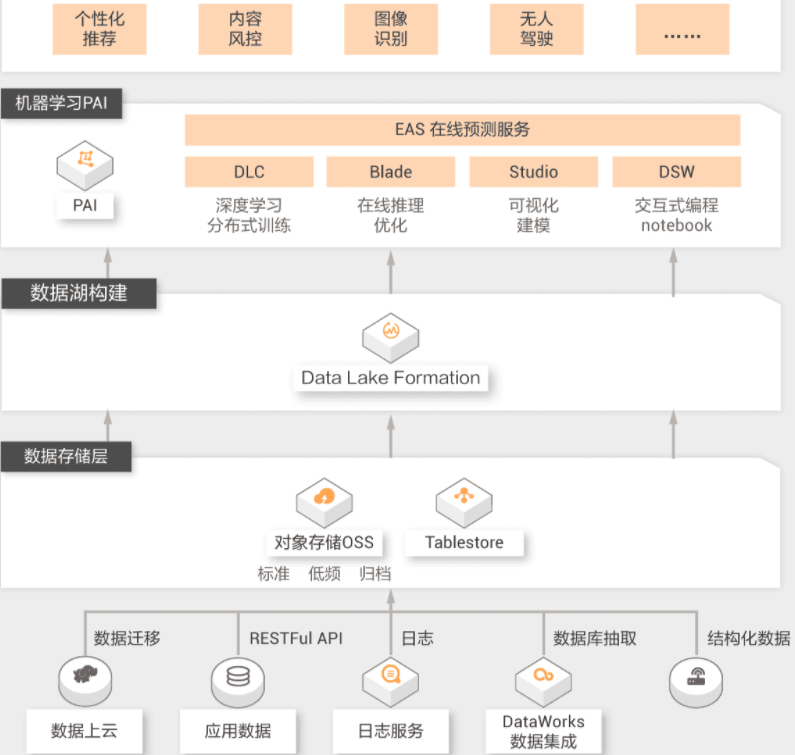
数据湖构建机器学习
典型场景
大数据是AI的基础,AI也是大数据的未来。数据湖可以很好的在经典机器学习场景和深度学习场景下服务用户:在机器学习场景下,用户面临数据量大,模型训练慢,算法效果差的问题,需要数据湖具备能够对接成熟的机器学习平台的能力。在深度学习时,用户需要能够动态的调整对GPU资源的使用,节约成本
方案价值
易用性强
数据湖构建无缝对接阿里云机器学习平台,同时提供多种Open API,方便用户集成
数据规范化
数据湖构建支持用户在入湖时对数据进行清洗处理、标准化,方便后续使用机器学习模型分析
应用实践
在线教育数据湖实践
用户数过亿的某在线教育平台
客户需求
用户希望课件素材、应用日志、学习采样等数据能够集中存储,统一管理。用户也希望能够对不同类型数据提供课件播放、离线分析、机器学习,实现在线教育不同场景的应用
客户价值
数据湖构建完美适配数据存储OSS,同时对接大量计算引擎,满足用户不同的分析需求

在线游戏数据湖实践
亚洲领先的某互动娱乐公司
客户需求
用户希望通过数据分析,及时调整游戏关卡难度,掉宝率,资源产出率,保证用户的游戏体验、提高用户留存率。用户也希望云上资源有灵活的扩展和升级能力,而数据湖方案可以解决传统的大数据集群计算和存储资源紧绑定的问题,提供用户更多弹性能力
客户价值
数据湖构建帮助用户快速搭建云上数据湖服务,解决存储计算资源问题,同时对接实时计算分析引擎,可以帮助用户实时调整业务
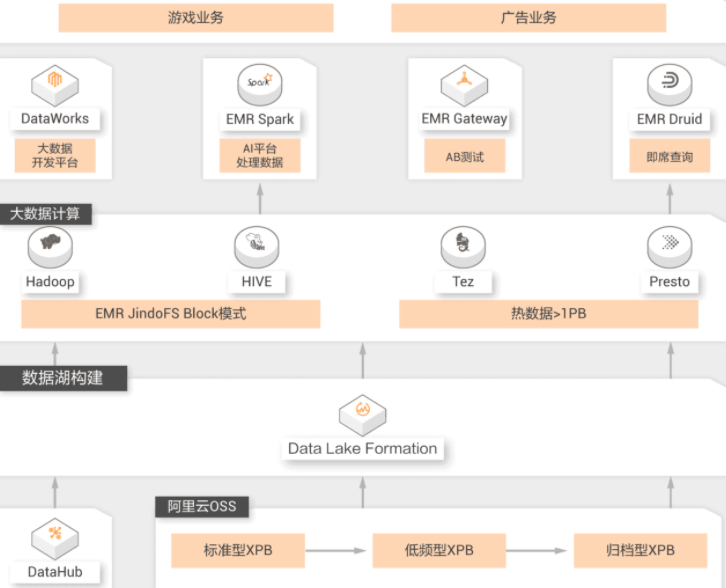
互娱新媒体数据湖实践
月活用户数破亿的某互联网新媒体平台
客户需求
用户希望可以统一管理多个存储系统的元数据,提供数据的共享分析能力,服务业务发展
客户价值
利用数据湖构建将分散的元数据统一集中管理,特有的发现能力可以从用户数据库和对象存储中收集并按目录分类数据
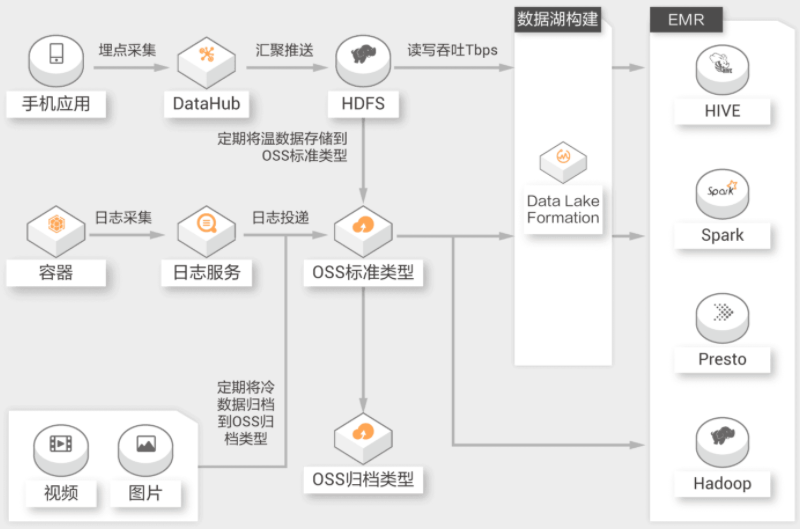
更多产品与服务
E-MapReduce
构建在阿里云云服务器 ECS 上的开源 Hadoop、Spark、HBase、Hive、Flink 生态大数据 PaaS 产品
大数据计算服务 · MaxCompute
提供快速、完全托管的PB级数据仓库解决方案,经济并高效的分析处理海量数据
交互式分析
兼容PostgreSQL协议的实时交互式分析产品
对象存储 OSS
海量、安全、低成本、高可靠的云存储服务,提供99.9999999999%的数据可靠性
