




新增按量付费
不上报数据时不收费,使用更加灵活,能满足海量数据同时上报的场景
一体化监控解决方案
云原生场景下的一体化可观测性平台,快速定位故障及性能瓶颈
实战教学视频
手把手教您从接入到使用腾讯云 Prometheus 监控服务,高效完成对云原生容器业务的监控
轻量
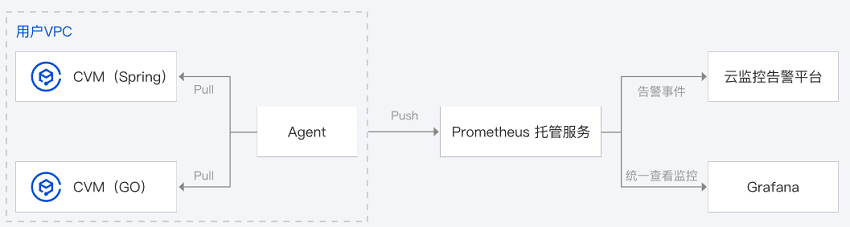
与开源 Prometheus 监控服务相比,Prometheus 监控服务的整体结构更加轻量化,您在云监控创建 Prometheus 监控服务实例后,即可开始使用。Agent 仅占用1G以内内存即可完成数据抓取。
稳定可靠
Prometheus 监控服务仅占用 MB 级用户资源,相比开源 Prometheus,占用更低资源。同时,结合腾讯云云存储服务及自身的副本能力,可减少系统中断运行次数,为您提供可用性更强的服务。
开放
Prometheus 监控服务提供了开箱即用的 Grafana 服务,同时也集成了丰富的 Kubernetes 基础监控 以及常用服务监控的 Dashboard,用户开通后即可快速使用。
低成本
Prometheus 监控服务提供了原生的 Prometheus 监控服务,在您购买 Prometheus 监控服务的实例之后,可以快速与腾讯云容器服务 TKE 集成,为运行在 Kubernetes 之上的服务提供监控服务,免去搭建运维及开发成本。
扩展性
Prometheus 监控服务的数据存储能力无上限,不受限于本地磁盘。可以结合腾讯云自研的分片和调度技术,实现动态扩缩,满足用户的弹性需求,同时支持负载均衡。解决开源 Prometheus 无法水平扩展的痛点。
兼容性
100%兼容 Prometheus 开源协议,支持核心 API、自定义多维数据模型、灵活的查询语言 PromQL 和通过动态服务或静态配置发现采集目标。您可以轻松迁移及接入。
应用场景
云监控提供一站式开箱即用的 Prometheus 监控服务,天然集成 Grafana 大盘。支持一键拉起所有服务,大大减轻用户的安装运维成本。
开源 Prometheus 作为云原生(如 Kubernetes等)监控的事实标准。Prometheus 为运行在 kubernetes 之上的服务提供监控服务,同时 Prometheus 的 Exporter 几乎覆盖了所有开源基础设施软件的指标采集能力。云监控全面对接开源 Prometheus 监控能力,提供了原生的 Prometheus 监控服务。免去用户搭建运维 Prometheus 服务的成本。
云监控结合 Prometheus 监控服务提供了开箱即用的 Grafana 服务,同时也集成了丰富的 Kubernetes 基础监控以及常用服务的预设监控面板,节省自建监控面板的时间成本。
Prometheus 监控服务基于云监控告警通道的能力,打通了 Prometheus Alertmanager,同时提供丰富的告警规则模板,免去用户学习告警配置的时间成本。
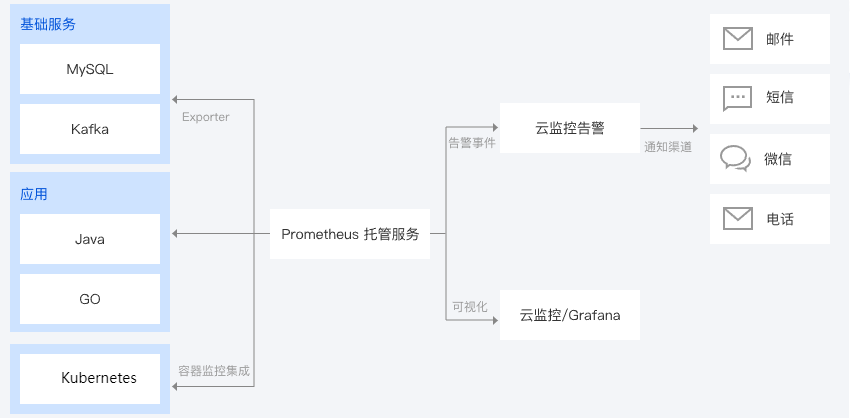
应用服务监控场景
某应用提供了对外的接口服务,但无法了解该接口服务质量。Prometheus 监控服务可对应开发语言进行集成,实时对接口的访问量/延时/成功率进行监控。
Prometheus 监控服务同时也会对服务进行异常检测,可了解该异常影响了哪些接口、发生在哪些主机,或者了解该异常是单机问题还是整个集群的共性问题。
对于 Java 应用来说,可进行单机的 GC/内存/线程状态等监控,全方面的了解 JVM 内部的状态。
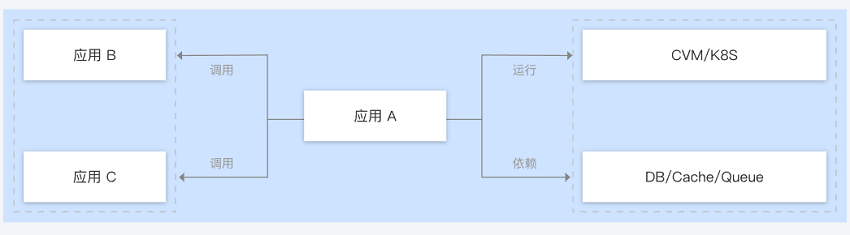
CVM 监控场景
当您的服务部署在 CVM 上时,几乎每次服务的扩缩容都要修改 Prometheus 的抓取配置。针对这类场景,结合腾讯云平台提供的标签能力和 Prometheus Agent 对腾讯云标签的发现能力,用户只需合理的对 CVM 关联标签即可方便的管理监控目标对象, 免去了需要不断手动更新配置的维护成本,例如:
服务 A 同时部署在 2 台 CVM 上,并对其所在的 CVM 关联标签(服务名:A);
由于需要进行业务活动,原有cvm数量不满足业务活动需求,需再扩容 3 台 CVM,这时只需要对这 3 台 CVM 关联标签(服务名:A)。成功关联后,Agent 就会自动发现新增的3台 CVM,主动抓取监控标指;
活动过后缩容下线 3 台 CVM,服务发现功能会自动感知服务下线,停止抓取监控标指。
产品家族
云拨测
零代码、覆盖全球全地域、以真实终端用户使用场景为视角,模拟真实用户最后一公里的可用性探测服务。
应用性能观测
与容器服务高度集成,高可用、全托管、免搭建的高效运维平台,兼容开源生态丰富多样的应用组件,减少开发和运维成本。
前端性能监控
可用于 Web 和小程序的前端真实体验监控服务,基于腾讯内部多年实践,一行代码、无侵接入,实现页面性能和前端质量的实时可观测。
Grafana 可视化服务
提供安全、免运维的 Grafana 能力,内建腾讯云多种数据源插件,如 Prometheus 监控服务、日志服务、容器服务等,最终实现数据的统一可视化。
帮助与文档
产品概述
介绍Prometheus 监控服务的产品功能、产品优势等。
快速入门
介绍如何快速使用 Prometheus 监控服务。
购买指南
介绍Prometheus 监控服务的计费模式、实例价格等。
最佳实践
介绍 Prometheus 监控服务的最佳实践。
常见问题
云上版本 100% 兼容开源版本,相比自建有运维和研究改造社区版本的成本,使用云服务能节省这些运维成本。也会集成常见服务的大盘和报警,节省了开发成本。
无法从内网访问容器服务 TKE 集群,如何解决?
在安装 Agent 时,需要通过内网访问容器服务,如果对应的容器服务集群未打开【内网访问】将会导致安装失败,可以通过如下步骤指引进行解决:
1.登录 容器服务控制台,选择对应地域下的容器集群。
2.在【基本信息】>【集群APIServer信息】下开启【内网访问】。
kube-proxy 采集目标状态全部为 DOWN,该如何解决?
TKE 中 kube-proxy 未指定启动参数 --metrics-bind-address,而 metrics 服务默认监听地址为127.0.0.1,因此 Agent 无法根据 POD IP 拉取到 metrics,可通过如下步骤指引进行解决:
1.登录 容器服务控制台,选择对应地域下的容器集群。
2.在【基本信息】>【集群 APIServer 信息】>【通过 Kubectl 连接 Kubernetes 集群操作说明】根据指引设置 kubectl。
3.执行命令 kubectl edit ds kube-proxy -n kube-system,在 spec.template.spec.containers.args 中添加启动参数--metrics-bind-address=0.0.0.0。
独立 TKE 集群 Master 节点上组件采集目标状态全部为 DOWN,该如何解决?
独立 TKE 集群 Master 节点的默认安全组入站规则不允许访问部分组件的 metrics 端口,可通过如下步骤指引进行解决:
1.登录 安全组控制台,选择对应区域。
2.在安全组搜索框中输入 tke-master-security-for-。例如集群 ID 是 cls-xxx,那么搜索内容为 tke-master-security-for-cls-xxx。
3.单击搜索出的安全组 ID 进入编辑入站规则对话框。
4.要编辑的规则的协议端口列应包含 TCP:60001,60002,逐条选择规则,添加端口10249,10252,10251,9100,9153。各个端口用途如下:
10249 kube-proxy metrics 的端口
10252 kube-controller-manager metrics 的端口
10251 kube-scheduler metrics 的端口
9100 node-exporter metrics 的端口
9153 core-dns metrics 的端口
配置了服务发现,但是没有指标上报?
1.通过对应 Prometheus 实例下集成的容器服务下面的 Target 有没有对应的任务状态。
2.如果没有对应任务状态,需要查看一下对应的配置是不是有问题,具体可以参考抓取配置说明。
