MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。
降低总体拥有成本
免平台运维,存储和计算分别仅按实际使用付费,总体拥有成本降低 50%以上。
简单易用的多功能计算服务
预置多种计算模型和数据通道能力,开通即用。支持直接对外部数据源的联邦计算及数据湖分析。
极致弹性能力
无服务器架构,超大规模的存储和计算扩展能力,无需容量规划即可应对规模的快速变化。
完善的平台服务
承诺99.9%可用性SLA,支持开放的生态,提供企业级安全管理能力。与阿里云其他大数据服务无缝集成。
精心打造的功能
TPCx-BB全球首家100TB规模测试通过
· 2017全球首家100TB规模TPCx-BB测试通过
· 100TB规模,连续4年全球最高分,2019年性能达25641.21QPM,2020年性能不变且成本下降40%
· 30TB规模,2019年性能达6427.86QPM,性能比第二名高一倍,成本比第二名低一半
· 2020年,30TB规模,较2019年性能提升50%以上,成本下降了30%以上
全托管的Serverless的在线服务
· 对外以WEB、SDK/API方式访问的在线服务,开箱即用
· 无需平台运维,最小化运维投入
· 实时根据业务需求变化,自动分配资源
弹性能力与扩展性、高性能
· 存储和计算独立扩展与计费,支持TB->EB数据规模的扩展能力,可以让企业将全部数据资产保存在一个平台上进行联动分析,消除数据孤岛
· 预铺设的大规模集群资源,近乎无限资源,按需使用和付费
· 单作业可根据需要秒级获得成千上万Core
统一丰富的计算和存储能力
· 多计算模型(MR,DAG,SQL,ML)及丰富的UDF,包括Java/Python UDF/UDT/UDJ,计算速度比Hive快一倍以上提高数据处理速度
· 所有数据均以表格式存储,采用列压缩存储格式并以压缩后数据量进行计费,通常情况下MaxCompute存储具备5倍压缩的能力,大幅节省存储成本
数据湖探索分析
· 默认集成对数据湖(如OSS服务) 的访问分析,处理非结构化或开放格式数据
· 支持外表映射、Spark直接访问方式开展数据湖分析
· 在同一套数据仓库服务下和用户接口下实现数据湖分析和数据仓库的关联分析
与DataWorks原生集成
· 一站式数据研发平台,全生命周期数据应用开发
· 全域数据汇聚、融合加工、数据治理
· MaxCompute的项目管理、web端查询编辑都是通过DataWorks实现
集成AI能力
· 与PAI无缝集成,提供强大的机器学习处理能力
· 可使用用户熟悉的Spark-ML开展智能分析
· 使用Python机器学习三方库
深度集成Spark引擎
· 内建Apache Spark引擎,提供完整的Spark功能
· 与MaxCompute计算资源、数据和权限体系深度集成增强Spark安全
提供统一的企业数据视图
· 提供租户级别的统一元数据,让企业能够轻松获得完整的企业数据目录
· 对于更广泛的数据源,通过外表建立数据仓库与外部数据源的连接
细粒度数据安全
· 细粒度数据安全、跨租户数据共享、动态脱敏、审计和监控
· 数据备份与恢复
典型实战场景
菜鸟智能物流
成本低,数据处理时间显著提升
菜鸟智能物流分析引擎是基于搜索架构建设的物流查询平台,日均处理包裹事件几十亿,承载了菜鸟物流数据的大部分处理任务。
更低成本的整体硬件资源
现有数据规模的处理需求,整体硬件资源成本下降60%+
更快的全链路处理速度
全量数据处理时间极大被压缩,2亿的记录,端到端只需要3分钟
更高效便捷的数据查询操作
一个系统满足多种场景查询,没有数据冗余,还有查询报错功能
云数据仓库
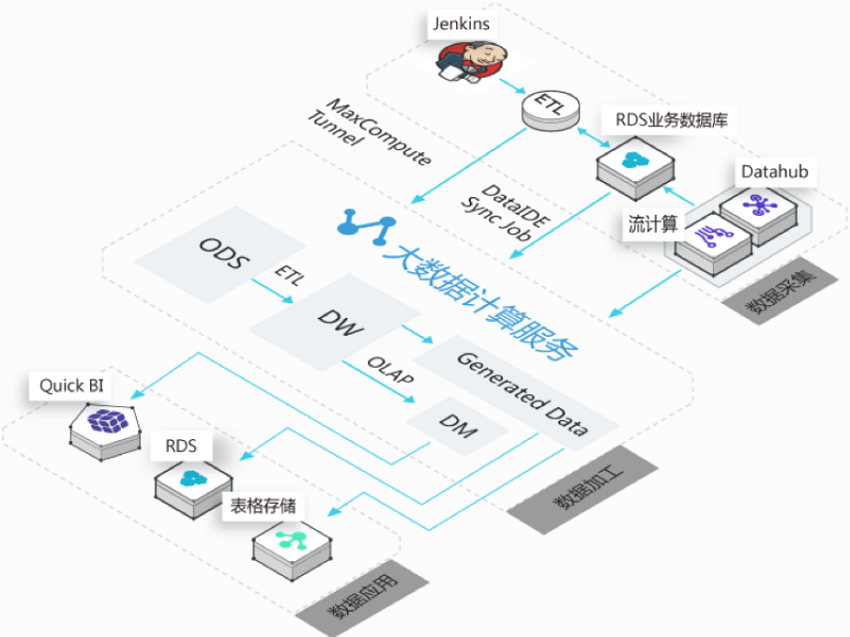
小红唇
大数据仓库
在云计算、大数据时代,数据仓库的重要性毋庸置疑,其建设也在不断的进化中。小红唇在横向对比之后,毅然决定基于数加MaxCompute强大的计算能力之上进行数据仓库的建设。
数据上云
第一阶段通过DataX和Tunnel向MaxCompute同步数据
数据清洗
第二阶段通过内部产品打通在Data IDE进行同步和数据清洗
数据展现
Data IDE进行ETL和OLAP的数据通过Quick BI进行产出报表
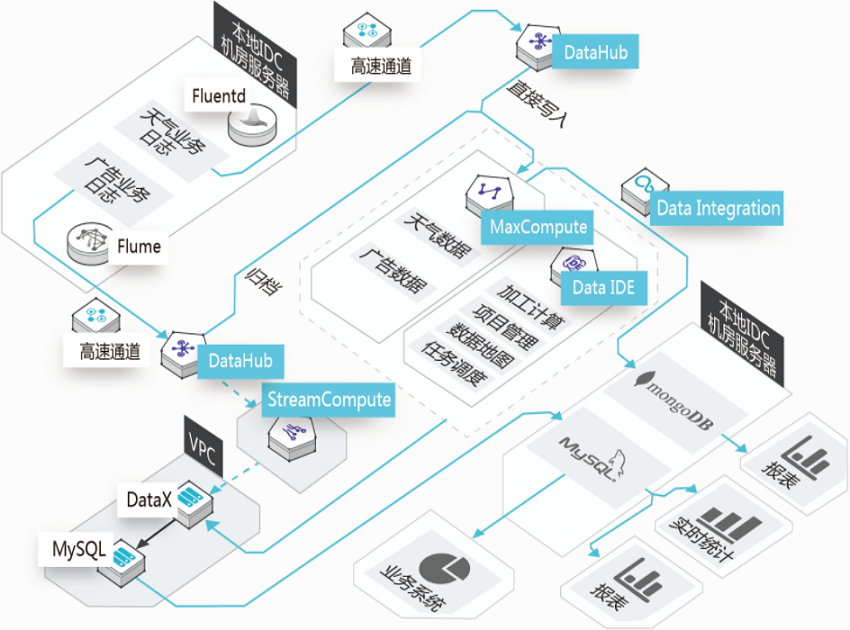
日志大数据分析
墨迹天气
提升开发效率,降低存储和计算成本
墨迹天气日志分析业务迁移到数加MaxCompute后,开发效率提升了超过5倍,存储和计算费用节省了70%,每天处理分析2TB的日志数据,更高效的赋能其个性化运营策略。
提高工作效率
日志数据全部通过SQL进行分析,工作效率提升了5倍以上
提升存储利用率
整体存储和计算的费用比之前节省70%,性能和稳定性也有提升
降低大数据使用门槛
MaxCompute提供多种开源软件的插件,轻松完成数据上云
精细化运营
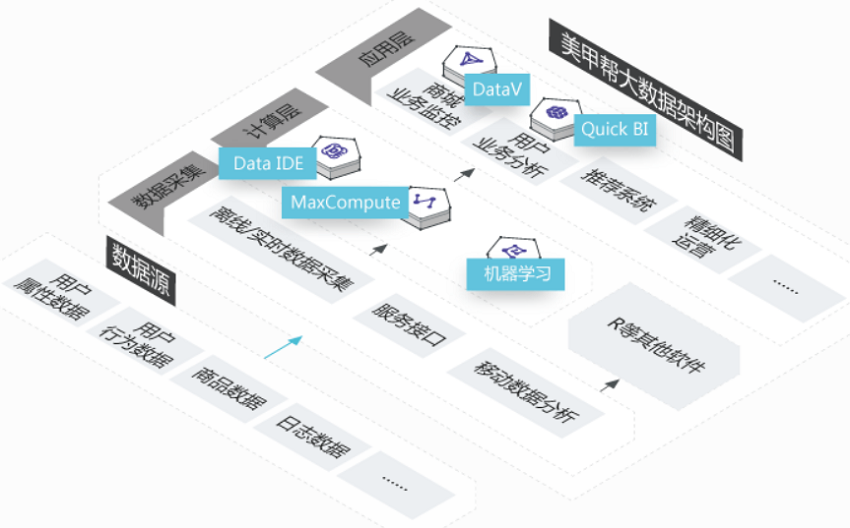
美甲帮
盘活海量数据,实现百万用户精细化运营
美甲帮的主营业务在商城方面,截至目前已经拥有百万级别的用户,积累了大量的用户数据,如何更好的服务用户并提升客户体验是美甲帮进行大数据探索的出发点
提升业务洞察能力
通过MaxCompute计算能力实现了针对百万用户的精细化运营
业务数据化
对业务数据分析能力提升并有效监控,更好的业务赋能
快速响应业务需求
数加生态满足新业务数据分析需求的“随机应变”能力
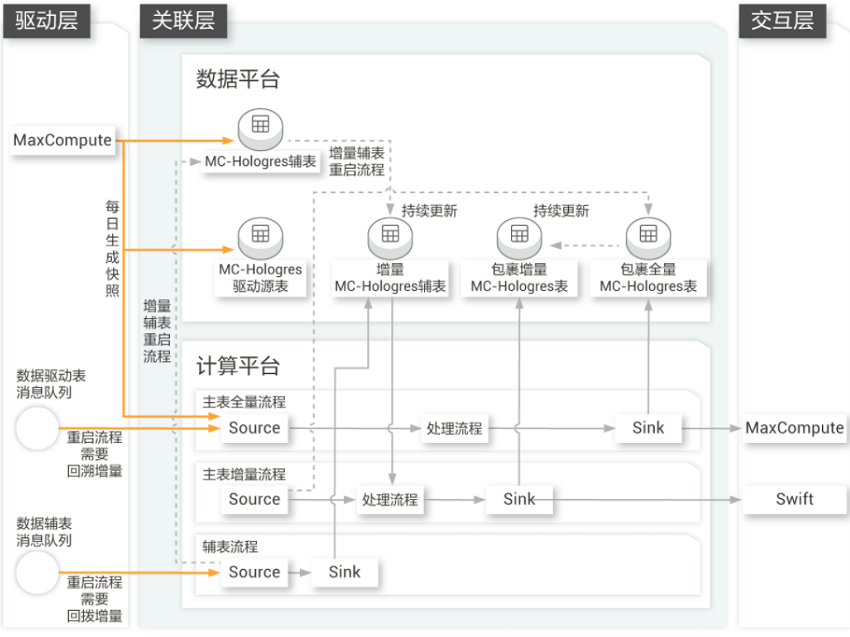
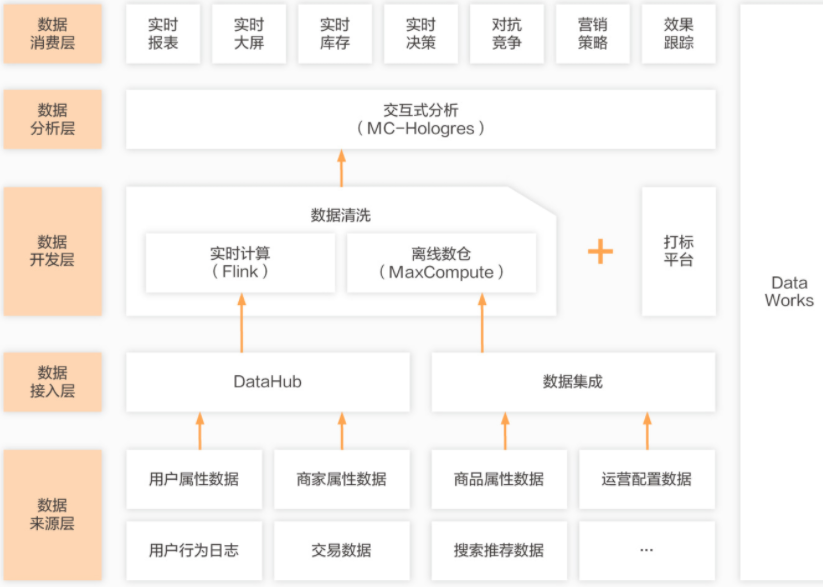
搜索推荐
阿里巴巴搜索
解放人力,减少沟通成本,提升业务效率
目前阿里巴巴淘系已能通过平台自助打标后,在报表中做自助即席多维分析,涵盖1000+自定义维度信息,无需开发同学额外支持,解放人力,减少沟通成本。
能够解决
更快速更精准地获取用户数据
无需更改blink作业,整体维度变更链路1小时内完成维表数据切换
更快的查询响应
数据量大,资源有限下,数据生产基本无延迟,且查询秒级内响应
实现数据输出的交互式、个性化、高扩展性
几十亿商品的特征信息仅耗时5分钟完成数据切换
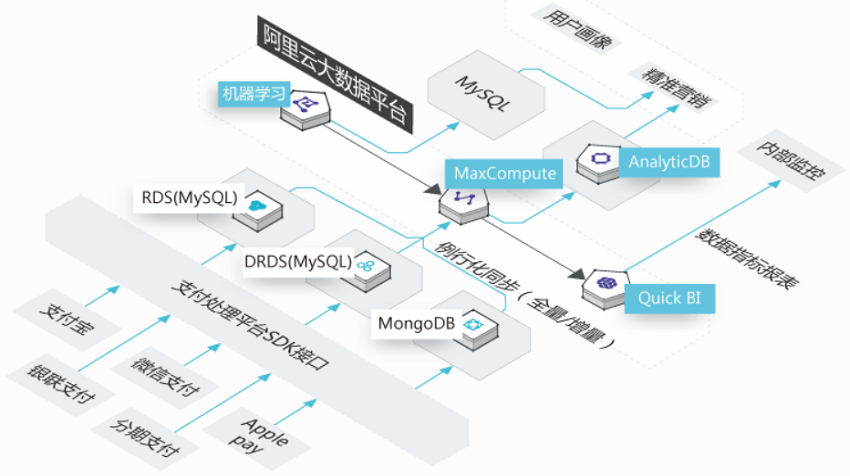
海量营销数据分析
PING++
海量营销数据分析
Ping++当前日交易笔数为百万级,目前已经积累了海量交易数据。如何对海量数据进行数据分析与业务创新从而提高用户黏性,Ping++ 亟需搭建安全、可靠、稳定的大数据平台。
数据创新
一站式大数据平台同时满足存储、计算、BI和机器学习等功能
快速、高效、低成本
作为互联网创业公司,需尽可能以最低的成本去实现
安全、稳定、可靠
需要严格的数据隐私保护机制,商户的数据只用于自身分析