
【UCloud】大数据解决方案
助力企业降本增效,获取数据时代核心竞争力,
UCloud大数据生态全面支持集数据采集、数据存储、数据分析和数据应用为一体的大数据应用场景,助力企业快速构建大数据处理体系,实现商业目标。




UCloud大数据生态全面支持集数据采集、数据存储、数据分析和数据应用为一体的大数据应用场景,助力企业快速构建大数据处理体系,实现商业目标。
开箱即用
简单几步,即可轻松完成集群创建和部署
智能运维
丰富的集群运维经验,结合专业的智能监控运维工具,及时发现并排除风险隐患,有效降低企业成本
资源独享
集群节点独占、数据独享,数据更私密、安全
一站式服务
提供终端到云端全链路服务,集数据采集、数据存储、数据分析和数据应用为一体
UES 基于开源分布式搜索和分析引擎 Elasticsearch 构建,提供开箱即用的分析能力。客户可以基于 UES 快速构建起 ELK 日志分析架构,即使用 Beats 作为日志采集器,采集各个服务器节点上的日志数据,经过 Logstash 解析、过滤后,汇集至 UES 集群存储,然后借助 Kibana 的可视化分析能力构建分析看板,高效的进行可视化日志分析工作。如果日志日志规模庞大,可以在上述架构中引入消息队列 UKafka,确保持续稳定的数据传输和处理。
UFlink 基于开源流式计算引擎 Flink 构建,提供了完全托管的流式计算平台。客户可以将数据源不断产生的流式数据接入各类流式数据存储,如消息队列 UKafka,然后创建 UFlink 集群从 UKafka 中订阅流式数据。开发者将编写的业务处理代码提交至 UFlink 集群,即可借助其强大的流式计算能力对这些数据进行实时处理,计算结果可以推送到各类数据存储中,如数据仓库 UDW,以供业务应用或者进行进一步的处理。
可以利用UHadoop/UDW快速的构建离线数仓,对海量数据进行分析和展示;利用Lafka+UFlink+UDW构建实时数仓,可以轻松的应对上百亿数据的实时分析平台;对当前的业务数据进行实时\准实时分析、挖掘,加快需求响应速度,能够让企业快速的感知市场的变化,加快决策与实施。
MADlib提供了丰富的分析模型,包括回归分析,决策树,随机森林,贝叶斯分类,向量机,风险模型,KMEAN聚集,文本挖掘,数据校验等。通过UDW的MADlib扩展,用户可以在UDW数据库中方便的使用MADlib功能;利用UHadoop中Spark MLlib中的机器学习库,实现业务的预测分析、个性化推荐、异常检测等。
Step1 需求对接
对用户业务、需求架构进行分析、评估。
Step2 提供方案
针对用户业务提供基于UCloud云计算平台及技术的定制方案。
Step3 方案确定
同用户共同优化方案,确定最终方案。
Step4 方案实施
根据方案提供云计算产品,提供所需架构。
Step5 业务迁移
协助用户进行业务迁移,快速排查前一过程遇到的问题,并提供专家指导。
Step6 后续保障优化
快速响应用户在运维过程中遇到的问题,并提供专家建议
开箱即用
简单几步,即可轻松完成集群创建和部署
智能运维
丰富的集群运维经验,结合专业的智能监控运维工具,及时发现并排除风险隐患,有效降低企业成本
资源独享
集群节点独占、数据独享,数据更私密、安全
一站式服务
提供终端到云端全链路服务,集数据采集、数据存储、数据分析和数据应用为一体
技术架构
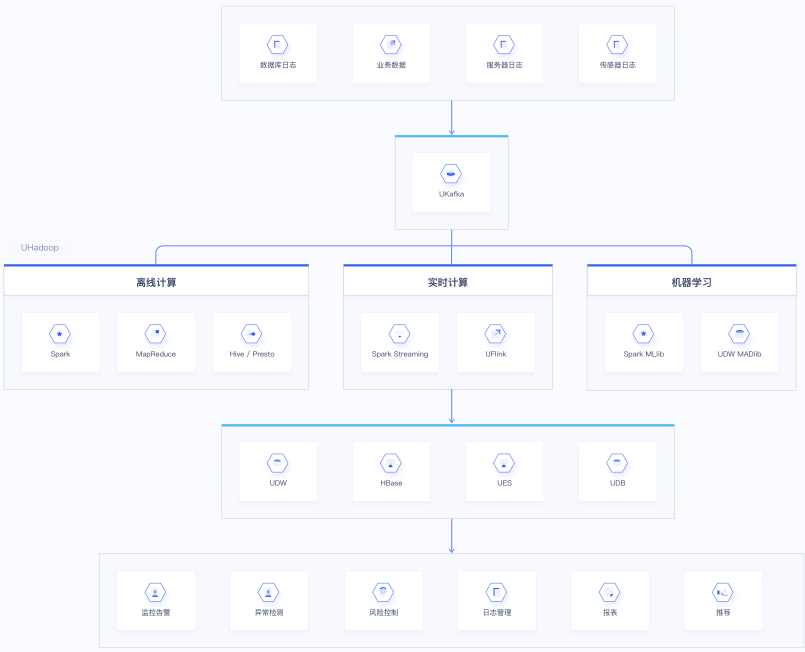
1. 用户通过Flume/DataX/Logstash等工具把日志数据、业务数据收集到UKafka中,UKafka中的数据可以给实时计算使用,或转存到HDFS、UES、HBase、UDW等存储系统中做离线分析和数据挖掘使用;
2. 实时计算可以通过UFlink、UHadoop中的Spark Streaming在UKafka实时读取数据,进行实时ETL、实时分析、实时训练;
3. 离线计算可以通过Hive、Spark 、MapReduce进行数据清洗分析;
4. 计算结果数据可以存储在UDW、HBase、UES、MySQL等存储系统中,以支撑个性化推荐、报表、风控、监控等业务使用。
适用场景
日志分析
UES 基于开源分布式搜索和分析引擎 Elasticsearch 构建,提供开箱即用的分析能力。客户可以基于 UES 快速构建起 ELK 日志分析架构,即使用 Beats 作为日志采集器,采集各个服务器节点上的日志数据,经过 Logstash 解析、过滤后,汇集至 UES 集群存储,然后借助 Kibana 的可视化分析能力构建分析看板,高效的进行可视化日志分析工作。如果日志日志规模庞大,可以在上述架构中引入消息队列 UKafka,确保持续稳定的数据传输和处理。
实时计算
UFlink 基于开源流式计算引擎 Flink 构建,提供了完全托管的流式计算平台。客户可以将数据源不断产生的流式数据接入各类流式数据存储,如消息队列 UKafka,然后创建 UFlink 集群从 UKafka 中订阅流式数据。开发者将编写的业务处理代码提交至 UFlink 集群,即可借助其强大的流式计算能力对这些数据进行实时处理,计算结果可以推送到各类数据存储中,如数据仓库 UDW,以供业务应用或者进行进一步的处理。
数据仓库
可以利用UHadoop/UDW快速的构建离线数仓,对海量数据进行分析和展示;利用Lafka+UFlink+UDW构建实时数仓,可以轻松的应对上百亿数据的实时分析平台;对当前的业务数据进行实时\准实时分析、挖掘,加快需求响应速度,能够让企业快速的感知市场的变化,加快决策与实施。
机器学习
MADlib提供了丰富的分析模型,包括回归分析,决策树,随机森林,贝叶斯分类,向量机,风险模型,KMEAN聚集,文本挖掘,数据校验等。通过UDW的MADlib扩展,用户可以在UDW数据库中方便的使用MADlib功能;利用UHadoop中Spark MLlib中的机器学习库,实现业务的预测分析、个性化推荐、异常检测等。
简单六步
让您的业务轻松上云
Step1 需求对接
对用户业务、需求架构进行分析、评估。
Step2 提供方案
针对用户业务提供基于UCloud云计算平台及技术的定制方案。
Step3 方案确定
同用户共同优化方案,确定最终方案。
Step4 方案实施
根据方案提供云计算产品,提供所需架构。
Step5 业务迁移
协助用户进行业务迁移,快速排查前一过程遇到的问题,并提供专家指导。
Step6 后续保障优化
快速响应用户在运维过程中遇到的问题,并提供专家建议
