批量作业管理的原型可以理解为Linux上的crontab,按照配置的调度规则自动触发任务的执行。在pingo中扩展了作业间的DAG依赖执行,重试机制,任务以及执行状态管理,以及自定义的任务扩展能力。
概念介绍
作业:执行的最小单元,如上图中的Spark、依赖检查等都是具体的一种类型的作业。
作业组:作业的集合,调度的最小单元。比如以这个cron格式"0 * * * *"调度,就意味着每小时执行一次作业组。
作业组实例:一个作业组执行后的镜像。比如2018.4.17凌晨一点执行后的镜像,实例中保存了作业组中每个作业的状态(成功、失败等),以及执行日志。
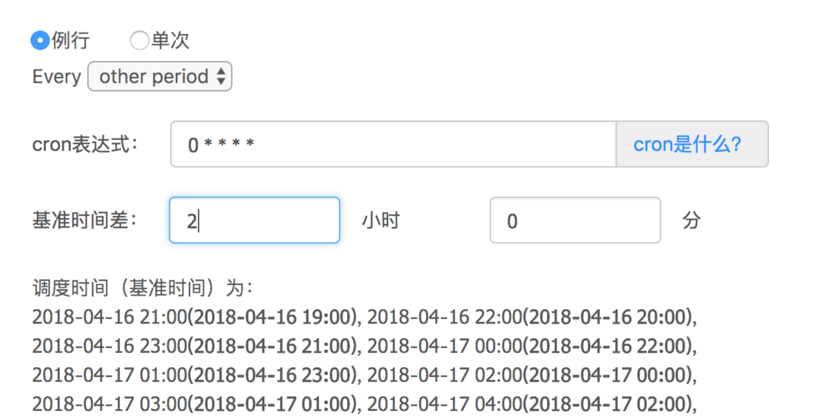
基准时间:还是以trade_table表为例,需要有一个任务每小时运行一次,计算这一个小时内的交易量,那么每个任务都要关联一个具体时间(比如20180417-13)的数据分片,这个时间就是基准时间,在作业中可以通过环境变量BASETIME访问到。
基准时间差:这个主要用来解决例行数据延迟的问题。还是以某电商的trade_table为例,假如每小时的数据都要延迟2小时就绪,也就是说6点的数据要等到8点才能就绪,那每个任务处理的数据都是两小时以前的。
新建作业组
由于没有作业的作业组是没有意义的,所以不可以建立一个空的作业组,因此必须先新建一个作业才可以新建一个作业组。选择任意一个类型的作业,填入有效的名称和各项参数,即可新建一个作业,该作业的名字就会同时默认成为作业组的名字。
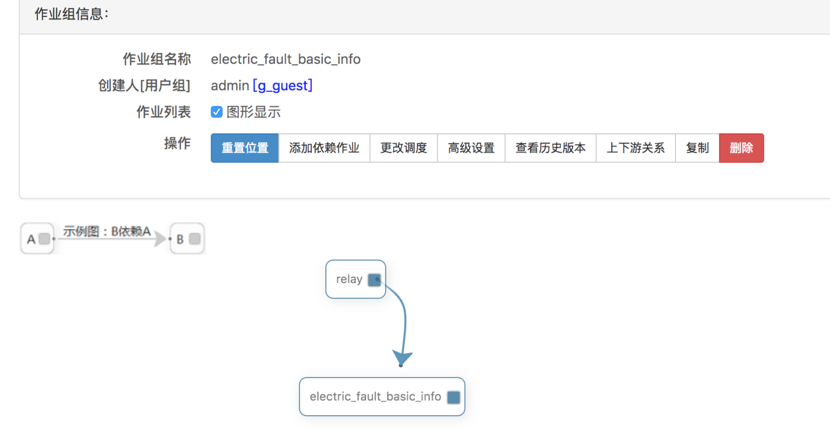
编辑作业组
点击"作业组列表"页面中的"编辑"按钮即可进入编辑作业组页面,如下图。点击"添加依赖作业"按钮可以添加一个新的作业到该作业组,拖动作业方框中的实心方块,可以建立作业间的依赖关系,这样在依赖的作业完成之前,后续的作业是不会启动的。双击作业方框可以进入作业的编辑页面。点击更改调度即可进入概念介绍示例的调度规则编辑页面。
Spark作业
在"创建新作业"中选择"Spark",即可创建spark类型的作业,Spark Plugin在批量作业中提供了Spark例行作业的入口,允许用户编辑Spark例行作业并设置调度例行运行。
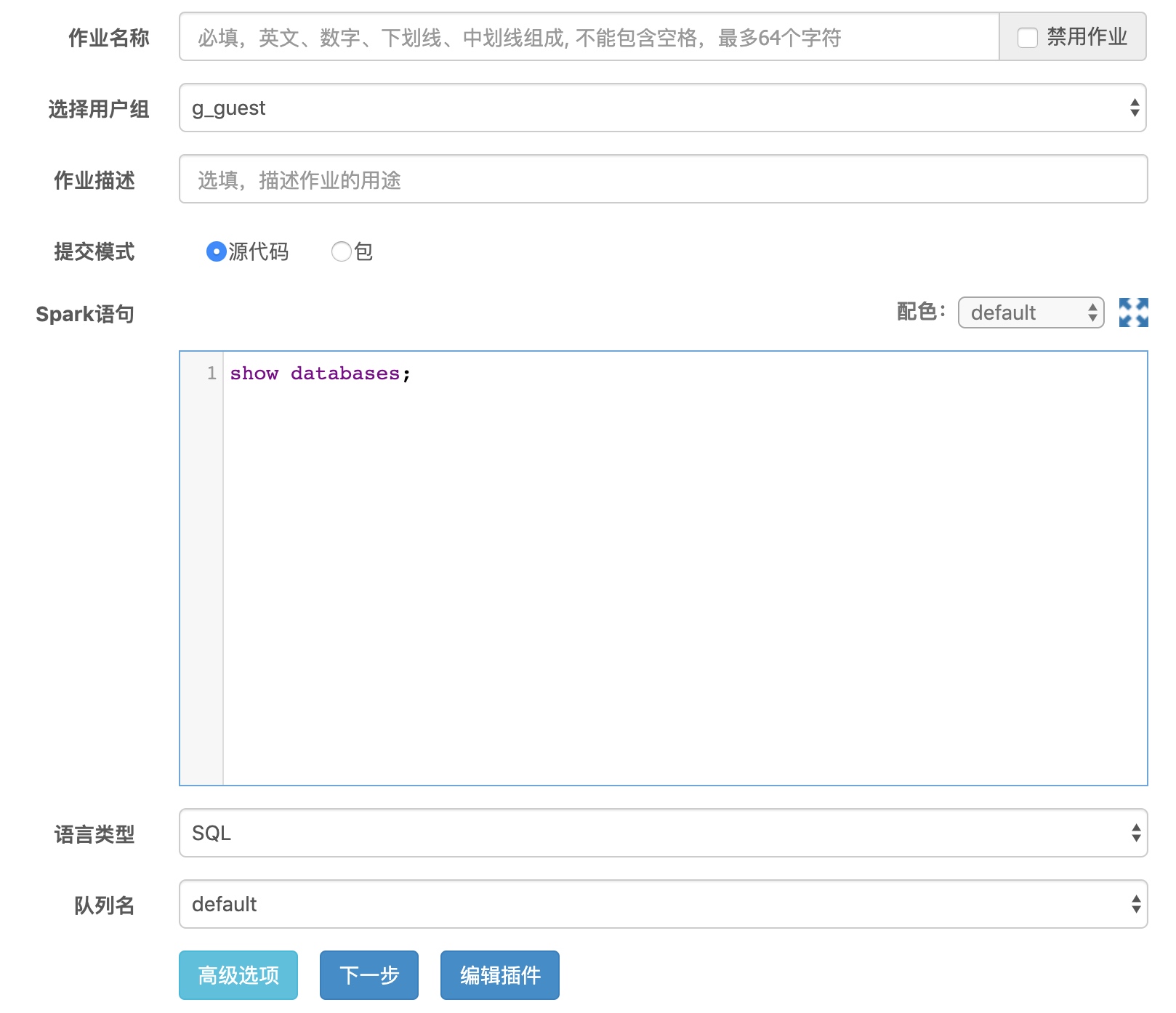
下面针对各个部分进行详细介绍。
提交模式
Spark Plugin提供了源代码和包两种提交模式
- 源代码模式对应于Spark-Client的交互式运行模式(spark-sql、spark-shell、pyspark),可以运行SQL/Scala/Python语言的Spark代码,无需编译直接提交运行
- 包模式对应于Spark-Client的文件提供模式(spark-submit),支持Python/Scala/Java的文件提交。两种提交模式均提供了cluster运行模式,可以直接将任务运行到集群中
注意: Spark Plugin不支持client或者local运行模式
源代码提交模式
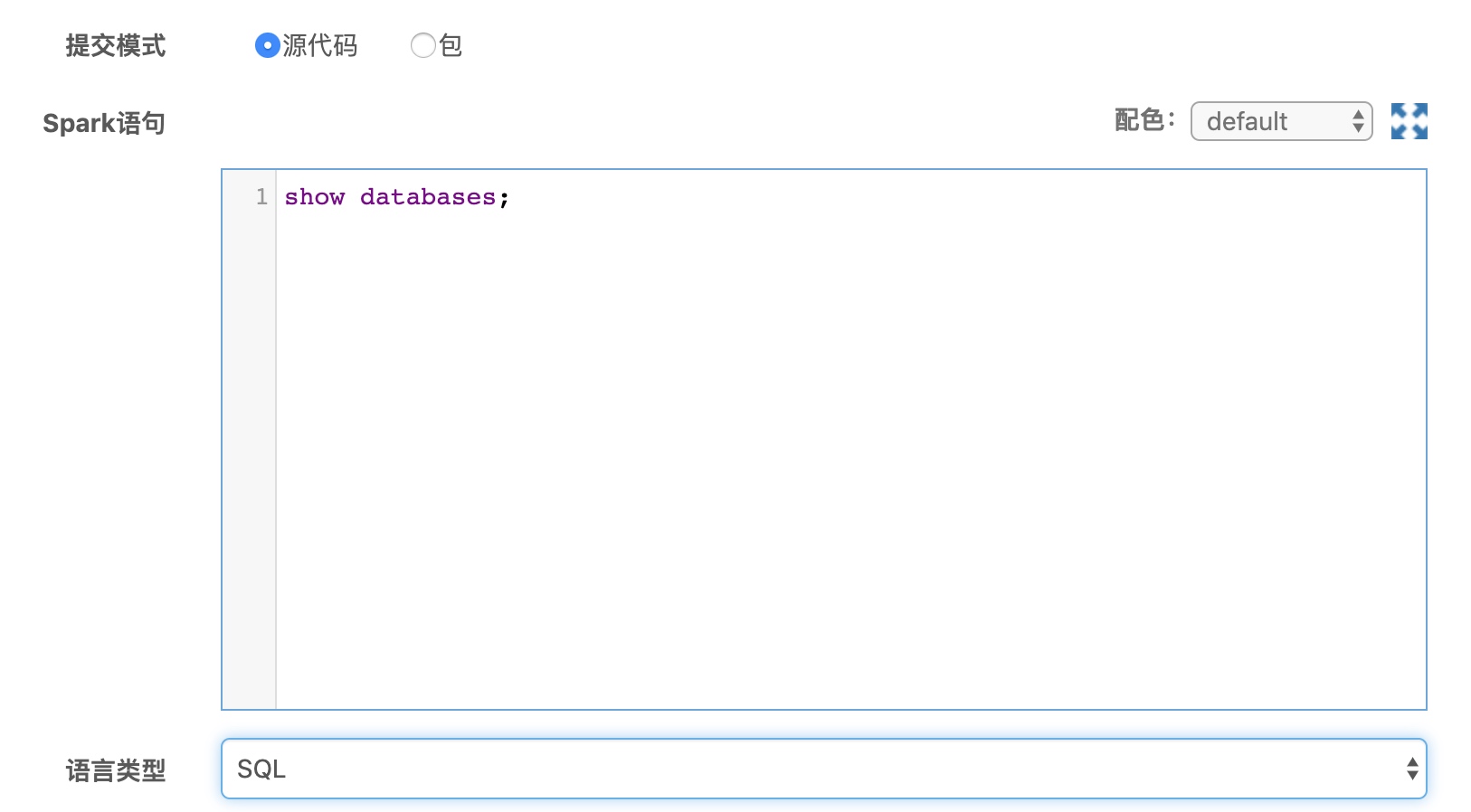
源代码提交模式核心部分由Spark语句输入框和语言类型组成,用户需要先选择语言类型,然后在Spark语句输入框中输入对应语言的Spark代码。 由于源代码提交模式是一种交互类运行模式,因此不同语言类型有一些特殊的书写规范,下面将进行一一列举。
SQL
- SQL语句可分行写,但最后要加";",当查询语句中存在";"时要进行转义
select *
from hive_table
where select_name="sql\;";
- SQL语句允许添加注释,SQL语句的注释是--,目前不支持一行中同时存在注释和代码
select *
-- hive_table是一个hive表
from hive_table
where select_name="sql\;";
- SQL语句中支持使用时间宏。SQL中可用{}包裹时间宏,程序会自动替换相应的日期。具体时间宏的种类请参考后面详细介绍
-- 读取hive_table某一天的数据
select *
from hive_table
where event_day="{DATE}";
Python
- 输入框模式将自动初始化SparkSession,因此请勿重复初始化SparkContext。下面变量将默认提供:spark、sc、sqlContext,其中spark对应于SparkSession,sc对应于SparkContext,sqlContext对应于SQLContext。
- 输入框无法执行Python文件头等相关内容,一旦输入将导致运行失败。下面代码是无法执行的,请勿添加到输入框
下面代码写入输入框会出错,请勿添加到输入框
!/bin/python
-*- coding: utf-8 -*-
- 输入框是自上而下顺序执行的,因此无需添加main函数,即使添加了也不会运行。
- 输入框中请勿添加或修改sys,添加或修改容易导致集群中Python加载异常。Spark原生是utf8编码,无需额外设置
下面代码写入输入框会出错,请勿添加到输入框
reload(sys)
sys.setdefaultencoding('utf8')
- 如果需要在Spark运行过程中添加打印日志,用print或者logging(配置stdout输出情况下)均会在运行结束后打印。需要用如下方法打印日志,日志将打印到Spark运行日志的stderr中。
def getLogger():
tag="application-user-log"
log4j = spark._jvm.org.apache.log4j
return log4j.LogManager.getLogger(tag)
logger = getLogger()
logger.info("test1")
- Python语言类型中也支持时间宏,除了像SQL一样支持时间宏替换外,还支持通过env获取时间宏。具体时间宏的种类,请参考后面的时间宏部分
下面两个等价
event_day="{DATE}"
import os
event_day=os.environ["DATE"]
Scala
- 输入框模式将自动初始化SparkSession,因此请勿重复初始化SparkContext。下面变量将默认提供:spark、sc、sqlContext,其中spark对应于SparkSession,sc对应于SparkContext,sqlContext对应于SQLContext。
- 输入框是自上而下顺序执行的,因此无需添加main函数,即使添加了也不会运行。
-
如果需要在Spark运行过程中添加打印日志,用print会在运行结束后打印。需要用如下方法打印日志,日志将打印到Spark运行日志的stderr中。
import org.apache.log4j.LogManager logger = LogManager.getLogger("application-user-log") logger.info("test1") -
Scala语言类型中也支持时间宏,除了像SQL一样支持时间宏替换外,还支持通过env获取时间宏。具体时间宏的种类,请参考后面的时间宏部分
下面两个等价 event_day="{DATE}" event_day=sys.env("DATE")
包提交模式
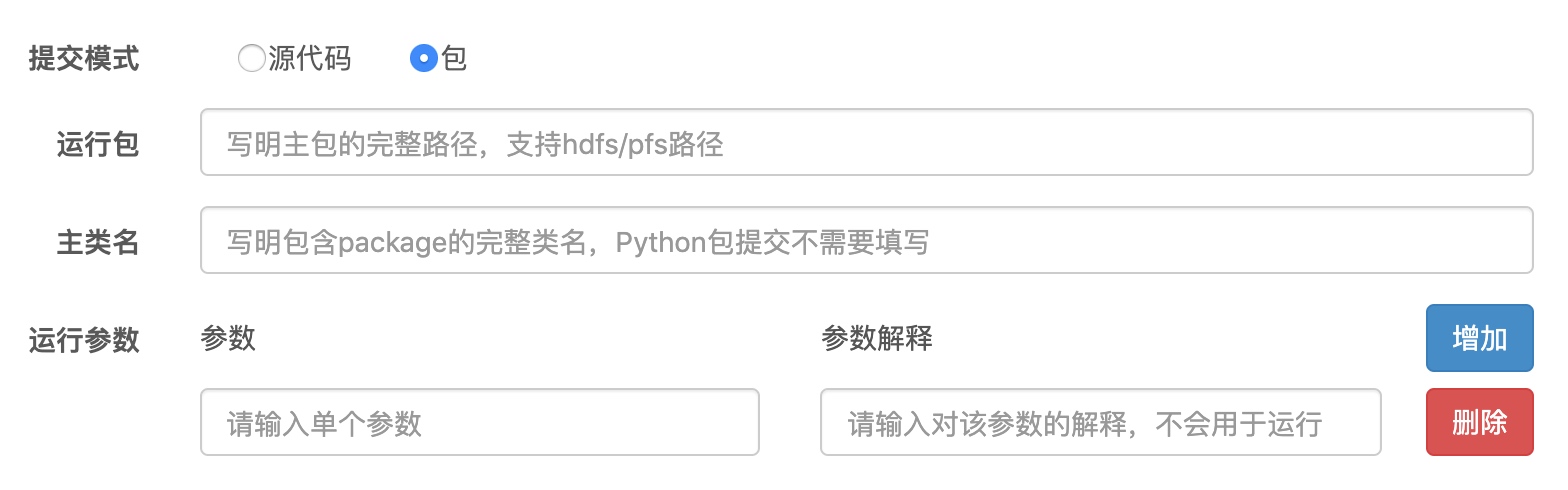
包运行模式下,允许用户提交jar包或者py文件运行,其中jar包支持Scala和Java两种语言。 详细样例case请参考“快速入门”的“运行代码包”部分
如何提交
-
运行包
- 用户需要将运行的jar或者是py文件上传到集群目录中
- 运行包位置填写完成集群路径
-
主类名
- 主类名是专门为jar包提供的,需要提供运行的主类
- py文件仅一个,会自动使用内部声明的主函数
-
运行参数
- 允许用户添加运行参数,每行输入一个运行参数,右侧框添加参数解释
注意事项
- Pingo默认是用了2.3版本的Spark,因此使用API或添加依赖时请注意Spark版本是2.3.3版本
- Jar包内请勿打包Spark依赖,相关依赖请注明provided
-
关于时间宏,运行包模式仅支持从环境变量中读取。具体时间宏的种类,请参考后面的时间宏部分
Python: import os event_day=os.environ["DATE"] Java: String event_day=System.getenv().get("DATE") Scala: val event_day=sys.env["DATE"]
高级选项
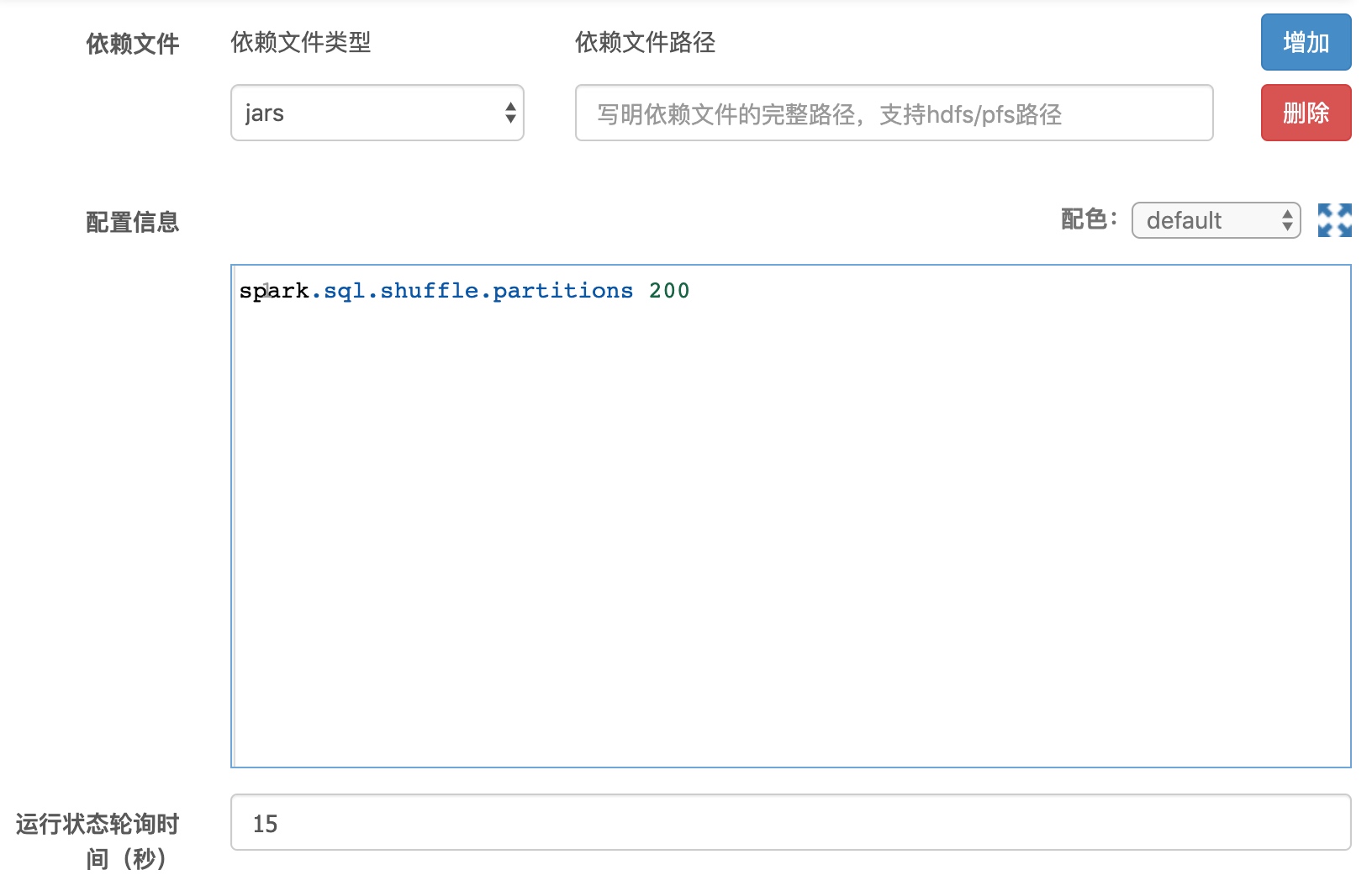
高级选项提供了对Spark作业进一步使用和优化的能力,其中依赖文件帮助用户注入运行依赖,配置信息部分帮助用户添加配置,运行状态轮询时间(默认请勿修改)调整获取Spark状态间隔
依赖文件
依赖文件中提供了jars、pyFiles、files、archives4中类型的依赖,所有的依赖类型都需要填写依赖文件完整的集群路径。下面是这几个依赖类型的区别,请根据具体需求使用。
| 依赖类型 | 依赖文件类型 | 说明 |
|---|---|---|
| jars | .jar | 通过jars依赖的文件将部署到driver和executor运行目录中,并自动添加到Java的CLASSPATH中,需要引用时,直接import即可 |
| pyFiles | .py/.egg/.zip | 通过pyFiles依赖的文件将部署到driver和executor运行目录中,并自动添加到Python的LD_LIBRARY_PATH中,需要引用时,直接from … import即可 |
| files | 任何类型 | 通过files依赖的文件将部署到driver和executor运行目录中,需要读取时,直接从当前目录读取即可 |
| archives | .tar.gz/.zip等 | 通过archives依赖的文件将部署到driver和executor运行目录中,并自动解压,解压后的目录名默认为压缩包名,可通过#定义别名。例如java.tar.gz#java解压后目录名为java |
配置信息
允许用户指定Spark配置,类似spark-defaults.conf功能,使用每行第一个空格分隔key和value,可以使用/#添加注释。 配置信息中也支持时间宏替换。具体时间宏的种类,请参考后面的时间宏部分
修改executor内存和task并行
spark.executor.cores 2
spark.executor.memory 4g
定义APP 名字
spark.app.name spark_test-{DATE}
Spark作业时间宏
Spark Plugin默认提供的时间宏如下:(宏替换指的是{DATE}替换方式;环境变量获取指的是从环境变量获取DATE的值)
| 关键字 | 对应时间 | 使用位置 |
|---|---|---|
| 基准时间 | 20190501 12:30:28 | |
| BASETIME | 20190501 12:30:28 | 宏替换/环境变量获取 |
| DATE | 20190501 | 宏替换/环境变量获取 |
| YEAR | 2019 | 宏替换/环境变量获取 |
| MONTH | 05 | 宏替换/环境变量获取 |
| DAY | 01 | 宏替换/环境变量获取 |
| HOUR | 12 | 宏替换/环境变量获取 |
| MINUTE | 30 | 宏替换/环境变量获取 |
| SECOND | 28 | 宏替换/环境变量获取 |
| YESTERDAY | 20190430 | 宏替换/环境变量获取 |
| FORWARD_7_DAY | 20130424 | 宏替换 |
| FORWARD_30_DAY | 20190401 | 宏替换 |
| FORWARD_90_DAY | 20190131 | 宏替换 |
| FORWARD_365_DAY | 20180501 | 宏替换 |
| FORWARD_WEEK_BEGIN | 20190429 | 宏替换 |
| FORWARD_WEEK_END | 20190429 | 宏替换 |
| FORWARD_MONTH_BEGIN | 20190401 | 宏替换 |
| FORWARD_MONTH_END | 20190430 | 宏替换 |
| FORWARD_2_MONTH_BEGIN | 20190301 | 宏替换 |
| FORWARD_2_MONTH_END | 20190331 | 宏替换 |
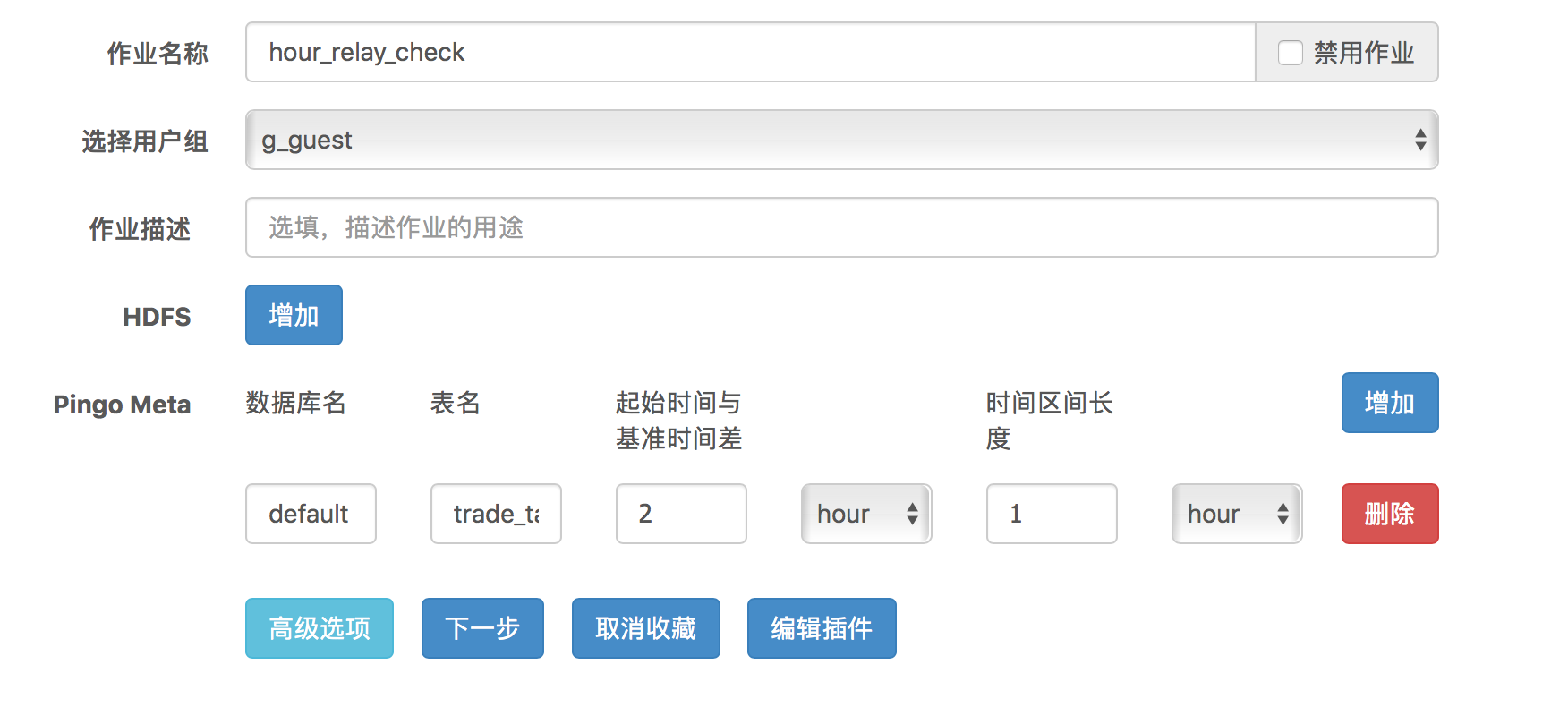
依赖检查作业
还是以trade_table为例,如果实际数据延迟两小时到达,那么真正的到达时间还是不可能精确到整点,那我们在10点整启动一个任务处理8点的数据,可能由于数据是10:01到达而导致任务失败或者结果非预期。这个依赖检查作业就是用来检验数据是否真的到达的,参考编辑作业组,让真正处理数据的Spark任务在这个依赖检查作业后续执行,即可保证正确的处理逻辑。 下图是配置一个依赖两小时前小时级数据的依赖检查作业。