




交互分析概述
Pingo提供Notebook式的交互分析环境,基于开源的jupyter项目,进行了一系列优化、适配。具备以下特性:
- 用户隔离:使用普通账号启动jupyter hub,然后通过一个设置了SUID位的程序将每位用户都映射到不同的uid,实现了Linux账号级别的安全控制,并且比原生的sudo-spawner资源隔离方案更加安全、可扩展。
- SparkSQL内核:提供了可以直接写SparkSQL的内核。
- SparkSQL和Dataframe混写:在通一个session里既可以写SparkSQL,也可以写dataframe。
- 一键例行:可以将当前note中的代码直接提交到工作空间中,创建为例行任务。
Note文件
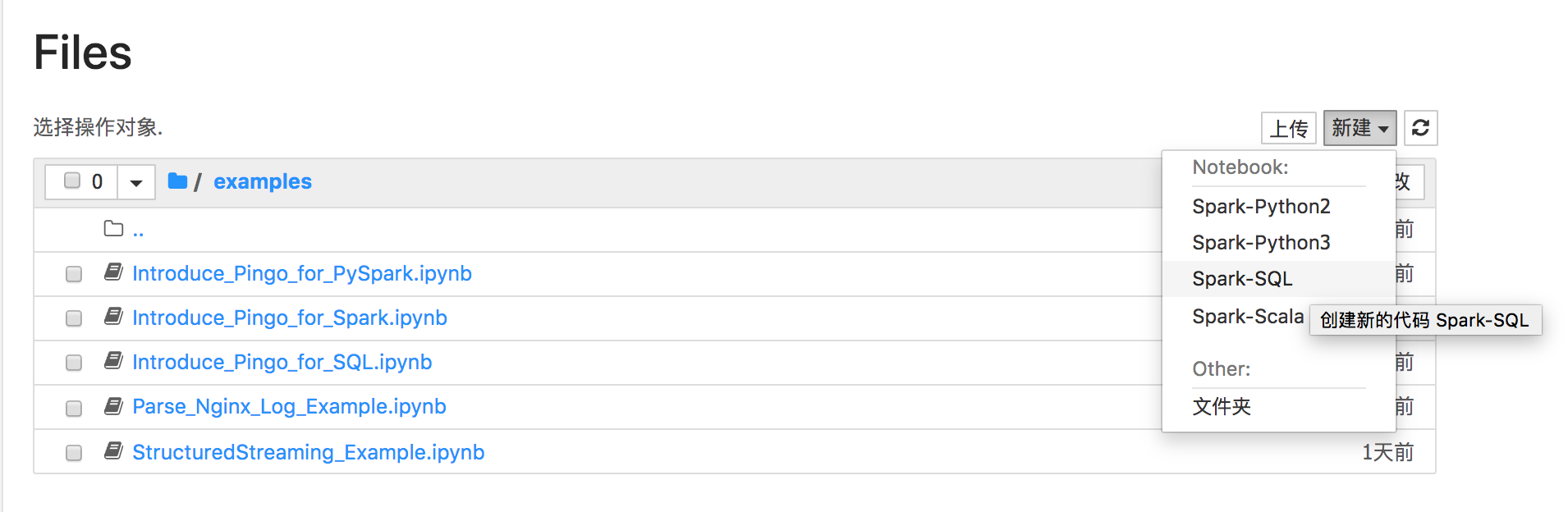
如上图,可以通过新建按钮新建一个文件,选中一个文件后会出现复制、例行、关闭、查看、编辑、删除等操作按钮。文件有是否运行的状态,运行中的文件,实际会对应一个后端的进程。另外我们会提供一些介绍基础用法的文件,都是以Introduce_Pingo_for_xxx的方式进行命名,用户直接参考实例进行操作即可。
文件操作
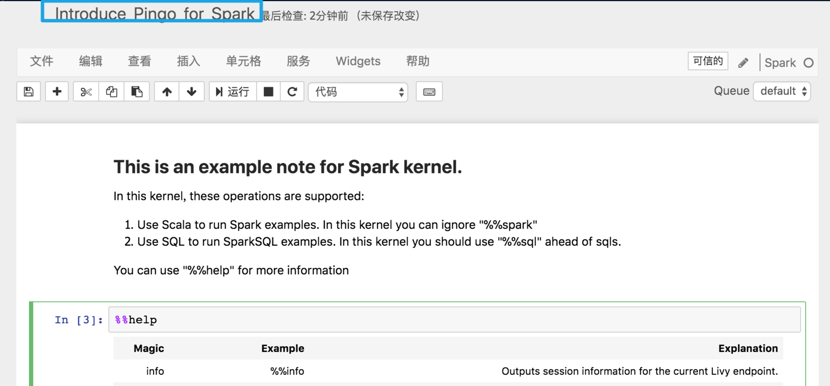
这里列一些基本的操作指导,详细的可以去浏览官方文档或者到搜索引擎进行查找。
点击上图中的蓝色方框,可以对当前文件进行重命名。In [3]后面的方块称为单元格,是执行命令的基本单元。将鼠标点击一个单元格后,可以点击菜单中的运行按钮来执行,或者使用快键键Ctrl+Enter,Shift+Enter可以在执行当前单元格的同时在下面新增一个单元格。
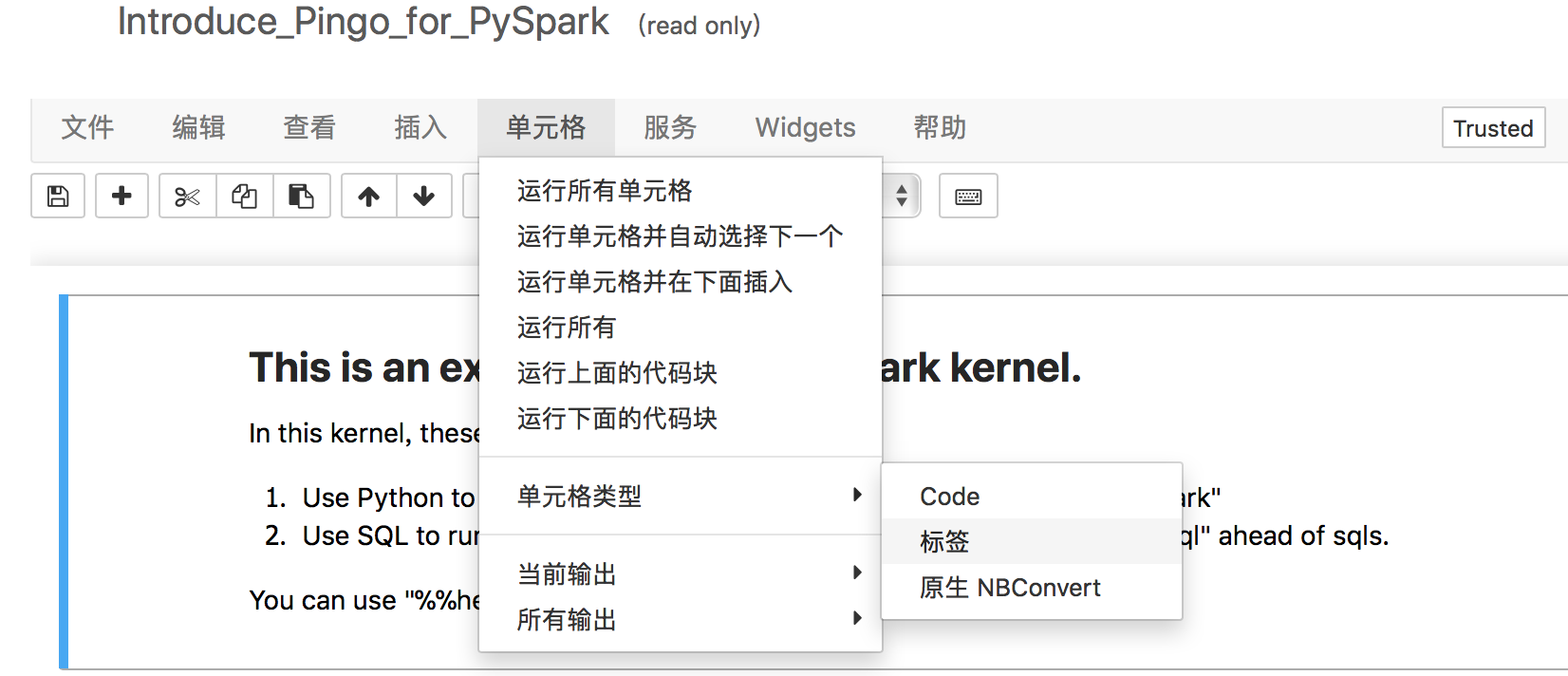
如下图,可以将当前选中的单元格的类型改为"标签",可以写markdown代码,生成这个文件中的说明文档等。改为markdown代码后执行一下当前单元格,就可以生成结果。修改的时候双击对应的markdown单元格即可进行编辑。
执行Spark
如Note文件中所述,新建一个SQL类型的文件,即可在新建的文件的单元格中执行SparkSQL,具体语法可以参考官方文档。新建文件类型选择为Spark或者PySpark则可分别执行Scala或者Python的Dataframe,具体写法也可以参考官方文档。对于已经非常熟悉SQL的用户,直接使用SparkSQL内核是非常推荐的方案。
同时,Note文件也支持在Note内使用其他类型的内核,在使用前添加%%spark或%%sql前缀即可(Note中每运行一种内核对应一个后端进程)。更多使用详情可通过执行%%help来查看(如下图)。
Pingo在Spark执行层也引入了很多扩展和优化。在SQL语法层面,我们支持了namespace,语法上的表现可以简单理解为允许在database的命名中包括".",另外我们支持了insert overwrite directory语法。
一键例行
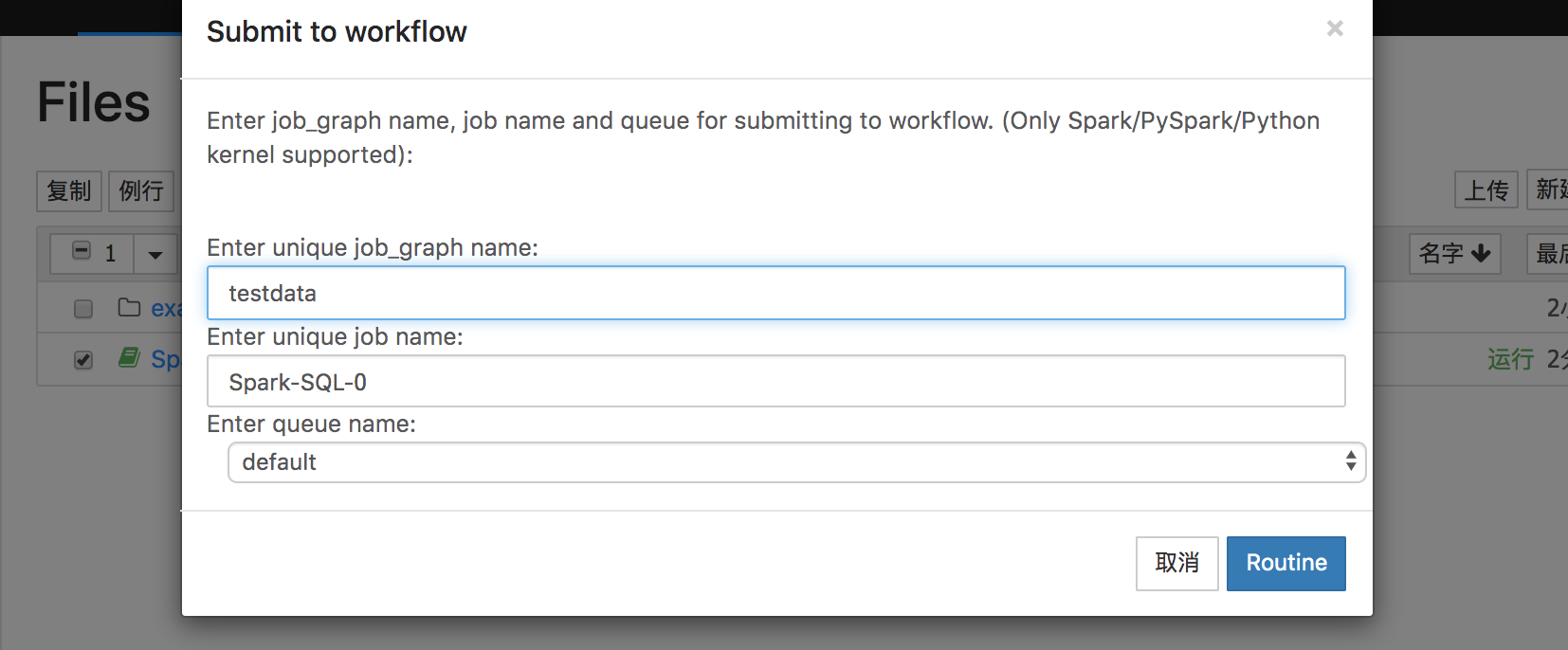
当我们在Notebook中进行探索式查询,验证了查询的过程和结果,希望每天例行查询操作,则可以将Notebook中编写的代码一键例行至批量作业。在Note列表页面,勾选需要例行的Note文件,出现更多操作按钮之后,点击例行,在对话框中填写作业组和作业的名称之后,点击Routine进行提交。
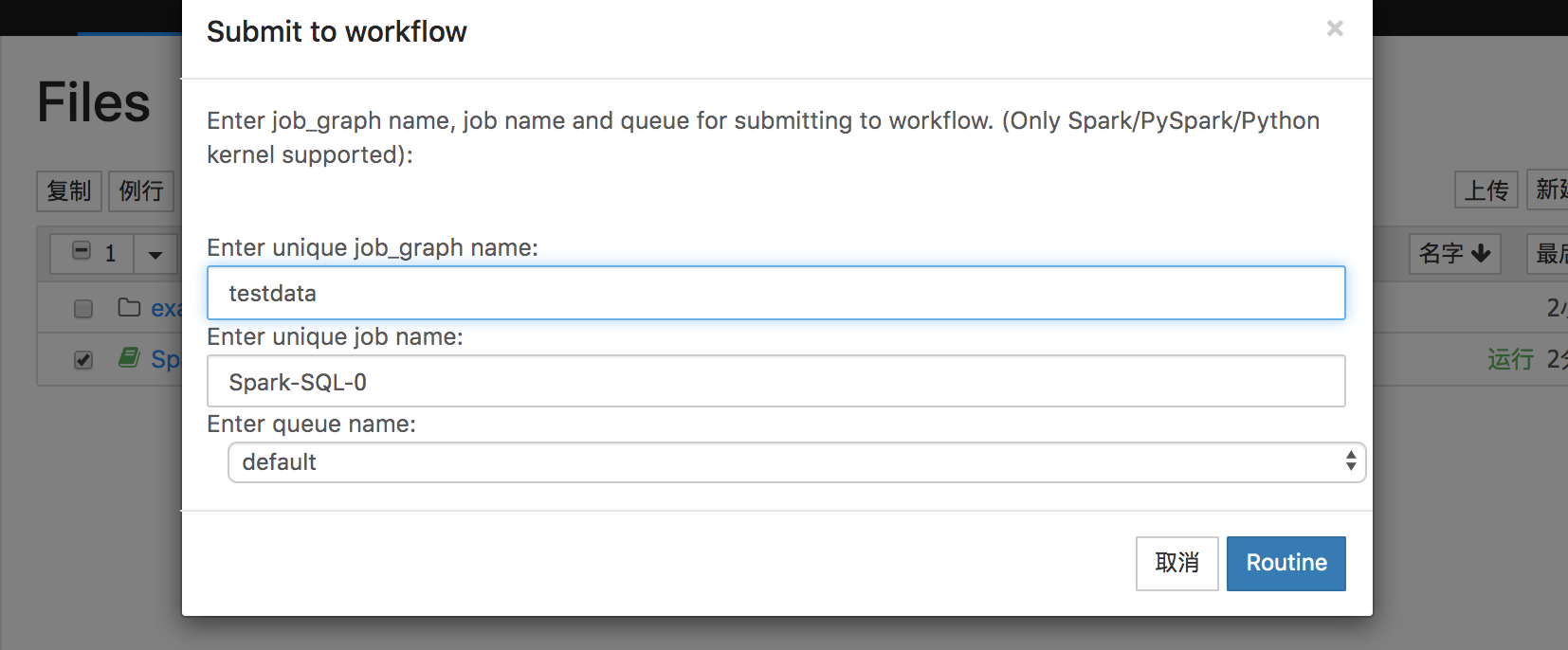
提交之后,到批量作业中可以看到从Notebook一键例行生成的作业组。
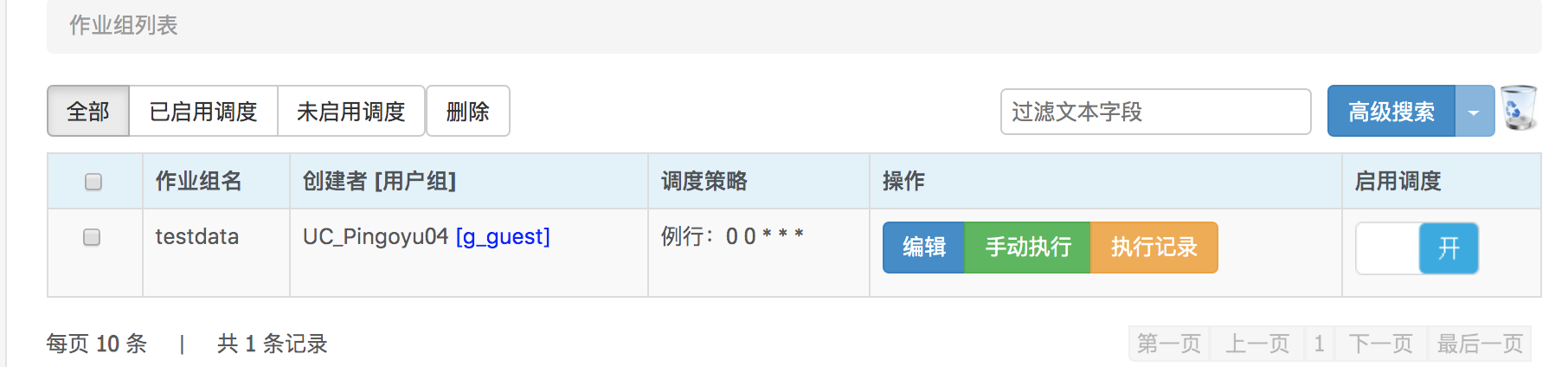
从Notebook中直接生成的作业组往往不能直接例行,因为在SQL中查询通常指定的是具体的时间分区,为了能正常例行,需要通过设置宏的方式编辑作业,例如作业中如果是具体的日期,需要改为宏{DATE}。更多Spark作业时间宏。
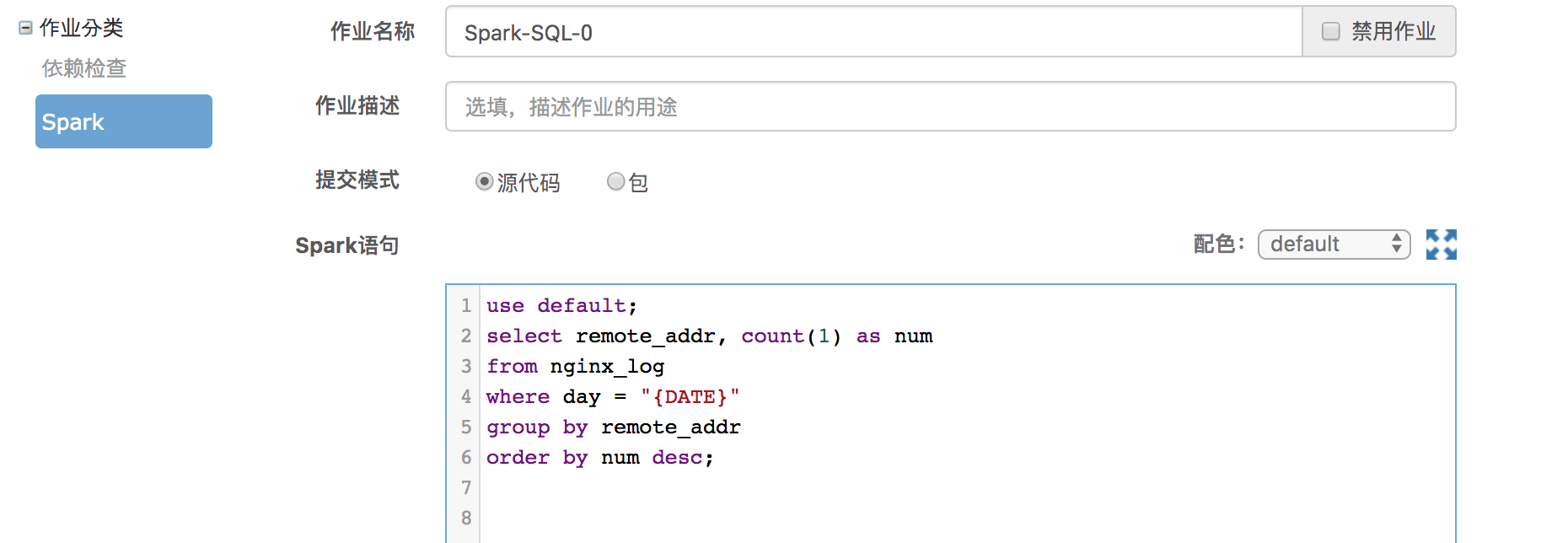
然后再按照批量作业管理的方式设置调度周期、依赖作业等,提交之后就可以正常例行起来了。
