

百度智能云智能边缘 - 部署模型SDK至Atlas200DK
文档简介:
1、概述:
本文将介绍如何在AI中台生成目标设备的模型部署包,然后将模型部署包部署至边缘设备。
本文使用的是一个安全帽模型,不需要模型序列号即可直接运行。



1、概述
- 本文将介绍如何在AI中台生成目标设备的模型部署包,然后将模型部署包部署至边缘设备
- 本文使用的是一个安全帽模型,不需要模型序列号即可直接运行
- 本文使用的边缘设备是atlas 200dk,固件与驱动版本为1.0.11,CANN版本为5.0.3alpha002,刷机镜像可在此处下载,提取码为kjm7。从1.0.11版本开始支持npu-smi info指令查看资源使用率。
- 本文使用BIE进程模式,可参考进程模式节点安装指南
- 检查/etc/ld.so.conf.d/mind_so.conf当中是否包含/home/HwHiAiUser/Ascend/acllib/lib64,如果没有,请添加。
cat /etc/ld.so.conf.d/mind_so.conf
/usr/lib64
/home/HwHiAiUser/Ascend/acllib/lib64
2、获取Atlas200类型部署包
- 参考导入模型章节,将原始安全帽检测模型导入模型中心
- 返回模型中心,点击部署包管理
- 在项目部署包页面,点击新建部署包
-
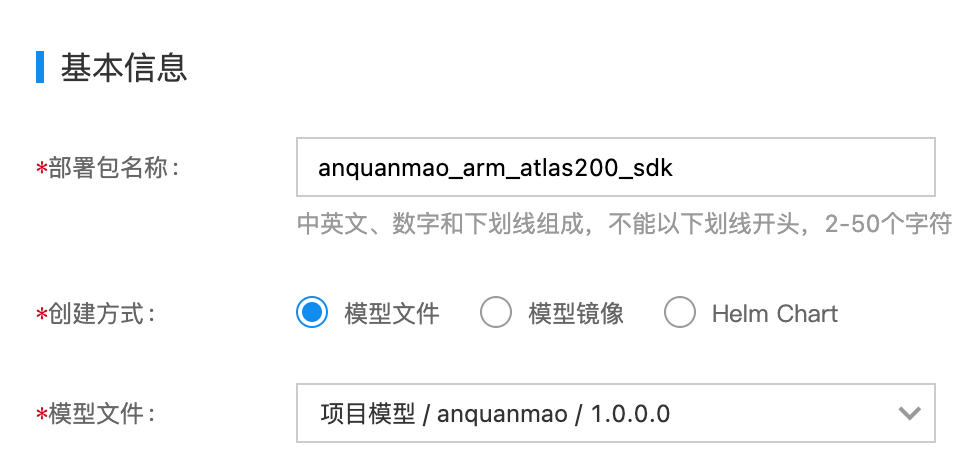
在新建部署包页面,填写信息
-
基本信息
- 部署包名称:anquanmao_arm_atlas200_sdk
- 创建方式:模型文件
- 模型文件:选择前面导入的安全帽模型
-
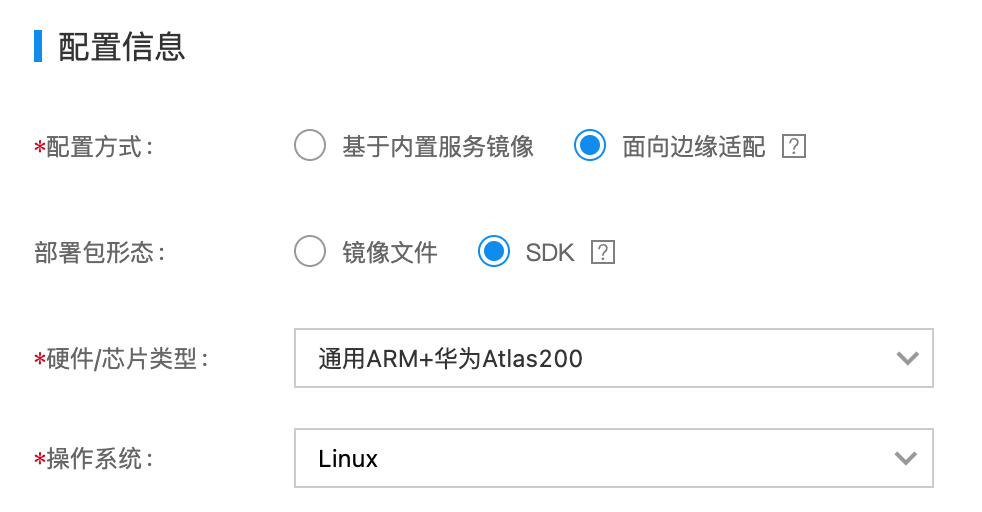
配置信息
- 配置方式:面向边缘适配
- 部署包形态:SDK
- 硬件/芯片类型:通用ARM+华为Atlas200
- 操作系统:Linux
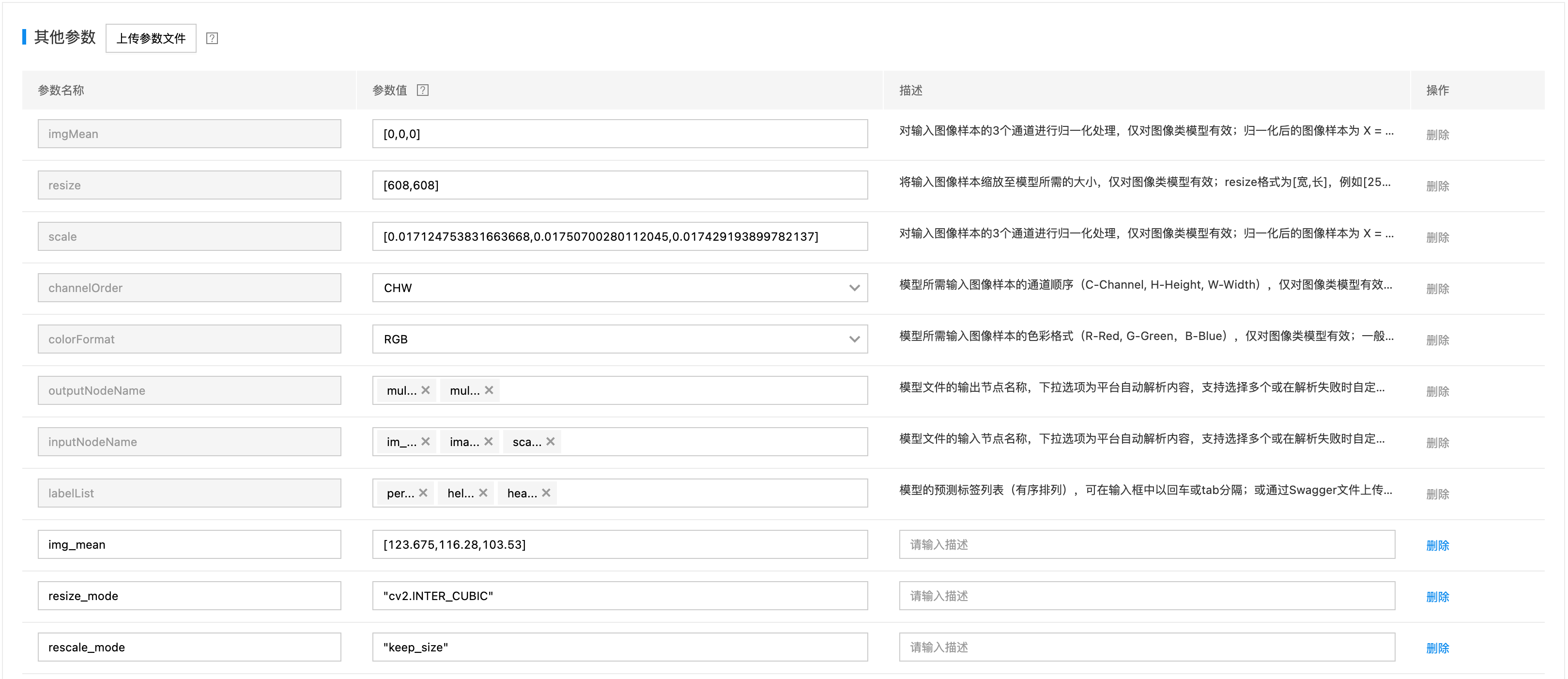
- 其他参数:如果在模型导入环节上传了模型转换参数,此处不需要再重复导入
-
参数信息
- 选择资源池,然后提交
-
- 接下来进入到模型部署包构建阶段,构建模型部署包需要一定时间,构建完成如下图所示:
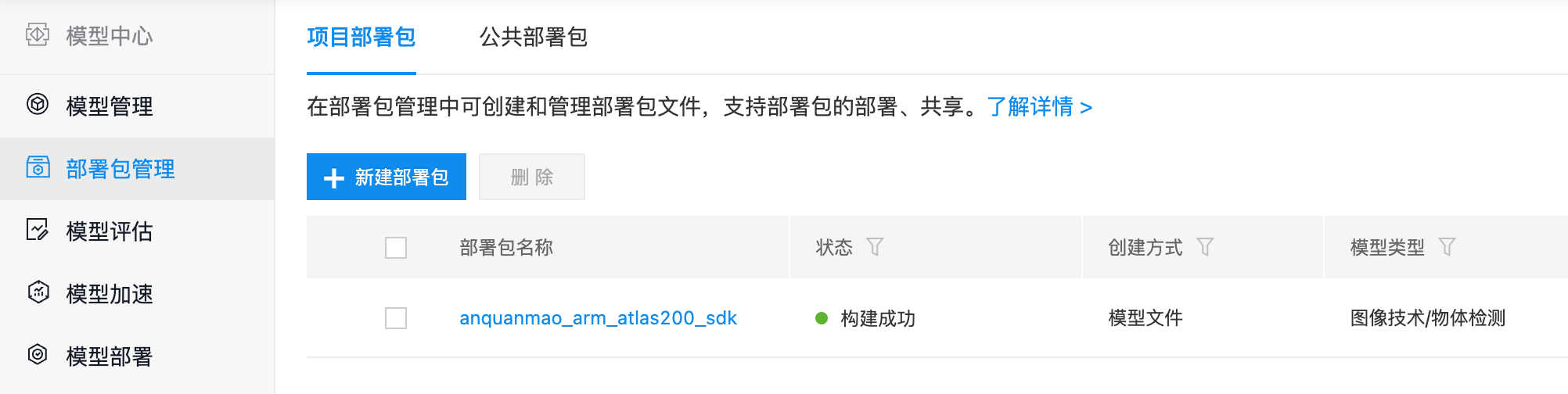
- 点击部署包名称,进入部署包详情,在详情也当中点击导出
![]()
- 点击任务列表按钮,查看导出任务,点击下载,获取部署包
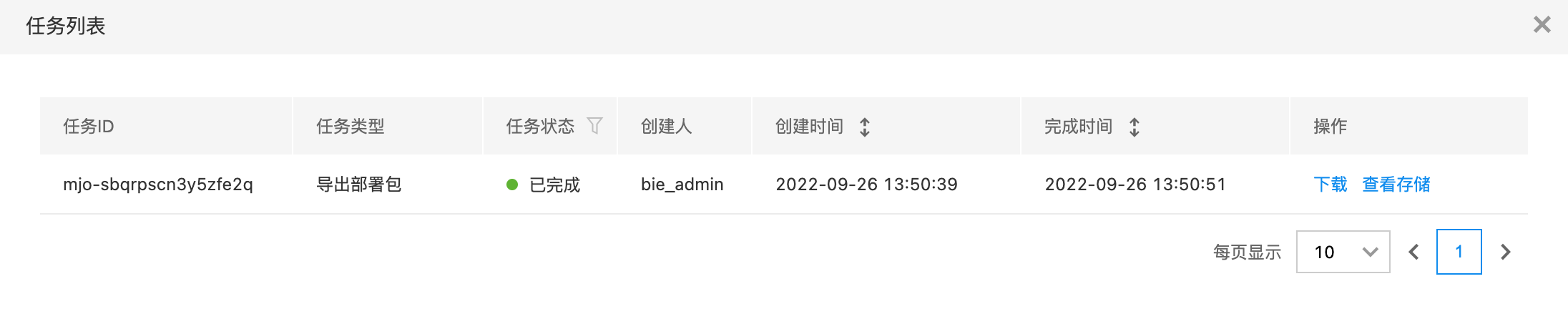
- 上传部署包支持对象存储,并获取下载URL
3、在BIE上创建配置与应用
3.1 创建程序包
- 导入进程程序包-paddle-opensource-sdk-edge-serving.json,与文档可执行脚本类型进程应用 当中创建的程序包是一样的。
3.2 创建模型文件配置项
- 导入配置项-dpkg-rqkuqxrbcnixn6y3.zip.json
3.3 创建进程应用
- 导入应用-linux-atlas-rqkuqxrbcnixn6y3.json
3.4 配置说明
- 程序包、模型配置文件、进程应用按顺序导入
- 导入以后部署至边缘节点可直接运行,不需要任何序列号
- 端口号此处指定为8702,通过进程应用的环境变量设置。
4、部署进程应用
进入进程应用linux-atlas-rqkuqxrbcnixn6y3,设置目标节点,如下图所示:
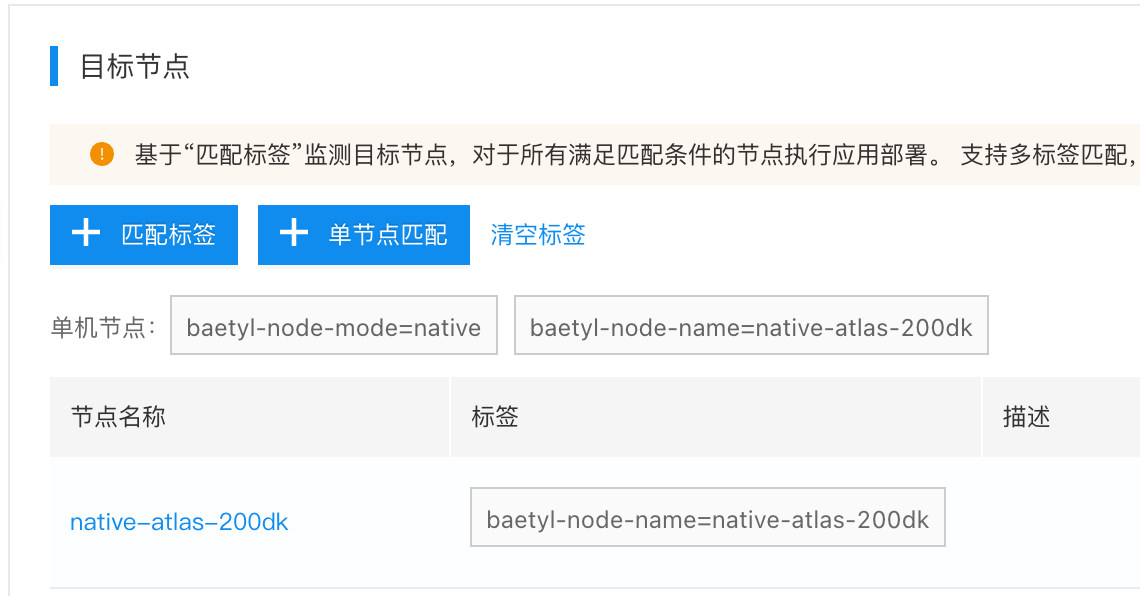
5、验证边缘节点AI推断服务
通过浏览器打开在线推断服务:http://ip:8702,上传测试图片,推断结果如下,证明AI服务正常启动。

压测查看AI加速卡资源使用
- 准备测试图片test.jpeg和压测脚本run-always.py,放在同一个目录下
ls -l
-rw-r--r-- 1 root root 242 Oct 12 05:55 run-always.py
-rw-r--r-- 1 root root 62197 Oct 12 05:55 test.jpeg
- run-always.py如下,注意端口号与文件名需要实际匹配
import requests
with open('./test.jpeg', 'rb') as f:
img = f.read() while True:
result = requests.post('http://127.0.1:8702/', params={'threshold': 0.2},data=img).json()
- 在terminal 1当中启动npu-smi命令,监控资源使用
npu-smi info watch
- 在terminal 2当中运行压测脚本
python3 run-always.py
- 监控terminal 1当中的资源变化,我们可以观测到 AI Core(%) 和 Memory BW(%) 在运行压测脚本以后的变化
root@davinci-mini:~# npu-smi info watch NpuID(Idx) ChipId(Idx) Pwr(W) Temp(C) AI Core(%) AI Cpu(%)
Ctrl Cpu(%) Memory(%) Memory BW(%) # =============未运行压测脚本============= 0 0 12.8 46 0 0 3
51 0 0 0 12.8 46 0 0 5 51 0 0 0 12.8 46 0 0 2 51 0 0 0 12.8 46 0 0 1 51 0 0 0 12.8 46 0 0 0 51 0
0 0 12.8 46 0 0 0 51 0 0 0 12.8 46 0 0 7 51 0 # =============开始运行压测脚本============= 0 0
12.8 47 0 0 25 51 13 0 0 12.8 48 3 0 25 51 10 0 0 12.8 48 3 0 25 51 8 0 0 12.8 50 17 0 24 51 14
0 0 12.8 50 17 0 24 51 9 0 0 12.8 50 17 0 25 51 0 0 0 12.8 49 17 0 3 51 0 0 0 12.8 49 13 0 0 51
0 0 0 12.8 49 13 0 0 51 0 # =============关闭压测脚本============= 0 0 12.8 48 0 0 3 51 0
