目前百度智能云时序数据库提供了两种数据可视化方案,物可视和Sugar,可以根据自己的业务需求来灵活选择。
两种方案的使用场景如下:
- TSDB+物可视:
物可视适合于前端开发人员快速搭建可视化应用,可以加速前端可视化的开发进度。物可视是由百度智能云提供的可视化产品,是一个基于物联网场景的可视化设计器,无需部署和安装插件,可直接对接百度智能云时序数据库及物管理,支持组态和大屏设计,并可以将设计好的面板通过JS代码嵌入到其他可视化应用中。具体操作请参见物可视操作指南。
- TSDB+Sugar:
Sugar是百度智能云推出的敏捷 BI 和数据可视化平台,目标是解决报表和大屏的数据可视化问题,解放数据可视化系统的开发人力。Sugar提供界面优美、体验良好的交互设计,通过拖拽图表组件可实现5分钟搭建数据可视化页面。平台支持直连多种数据源(Excel/CSV、MySQL、SQL Server、PostgreSQL、Hive、Spark、Presto、Teradata、Baidu Palo、Baidu TSDB等),还可以通过API、静态JSON方式绑定可视化图表的数据,简单灵活,大屏与报表的图表数据源可以复用,用户可以方便地为同一套数据搭建不同的展示形式。
本文重点介绍TSDB利用Sugar做可视化展示的方法。用户可以利用Sugar的可视化能力,更好地分析存储在百度智能云TSDB中的数据。
使用说明
TSDB已接入百度智能云Sugar,用户可以通过SugarBI访问TSDB,对TSDB中存储的数据进行多种交互式数据分析。百度智能云Sugar对所有新老用户提供30天免费全功能试用,30天后需付费使用,请参见Sugar产品定价。
1. 创建数据源
- 登录Sugar会自动进入「空间广场」,点击「我的空间」中的任意空间,进入该空间页面。
- 点击空间页面左侧的「数据管理」> 「数据源」>「添加数据源」,添加百度TSDB数据源。
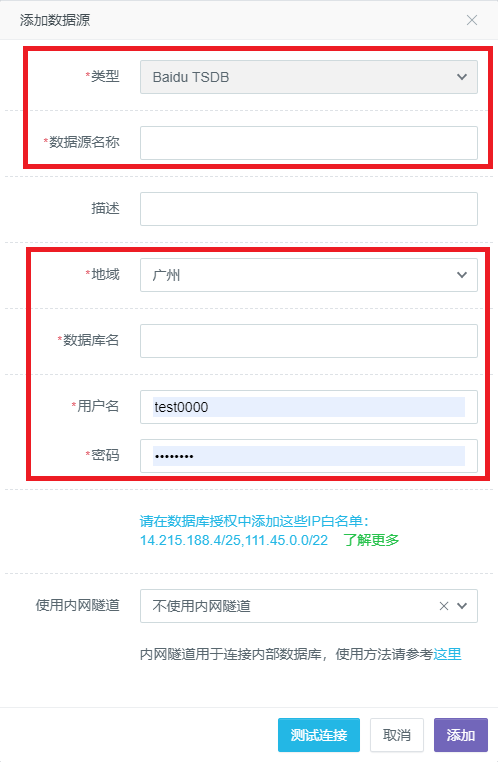
- 在弹出的数据源编辑框中,「类型」选择“Baidu TSDB”,「数据源名称」填写用户自定义的数据源名称,「数据库名」、「地域」填写用户名下想要接入的TSDB实例的名称和所在的区域,底部的「用户名」和「密码」填写用户在TSDB中创建的MySQL协议账号信息。TSDB创建MySQL协议账号具体操作请参见XXXX。
2. 报表示例
接下来简单说明一下如何制作报表来分析TSDB中存储的数据。
创建报表
-
首先,在左侧的管理中心中进入「报表管理」,新建一个报表页面。
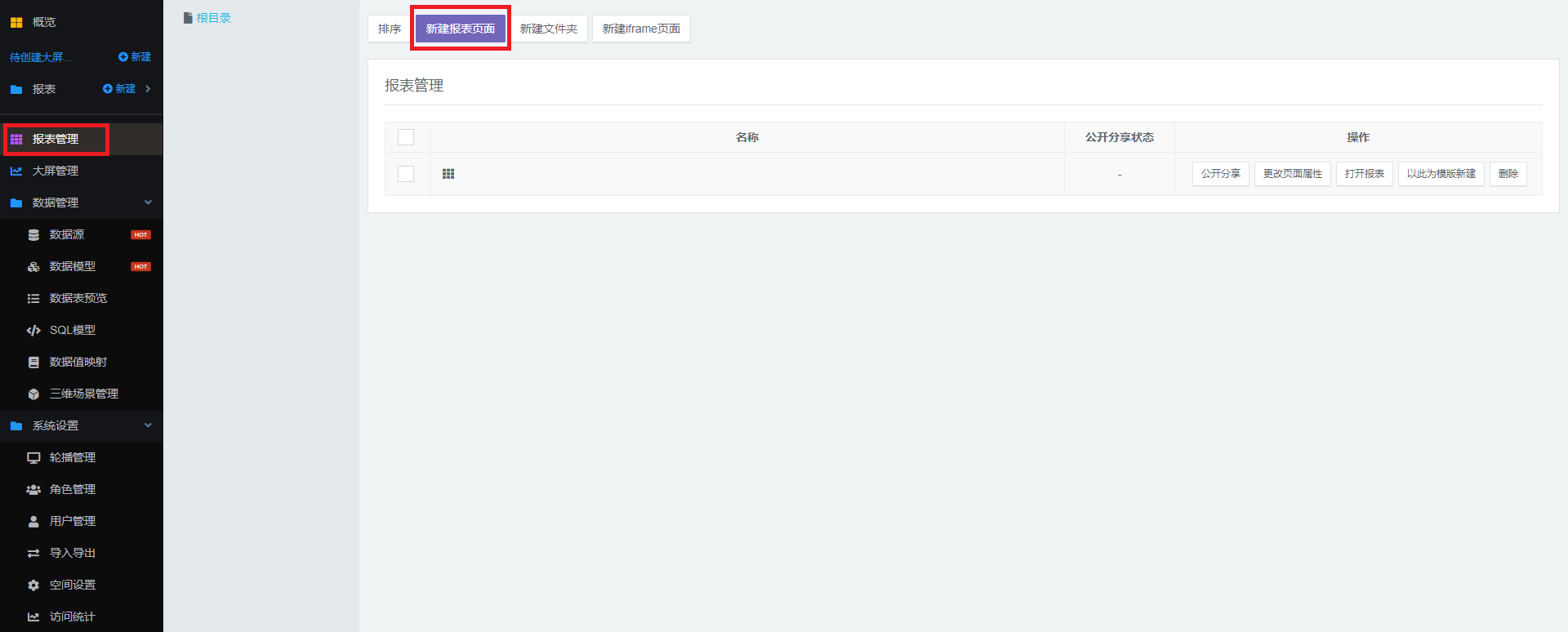
- 在「报表管理」列表中,选中你想要编辑的报表,点击「打开报表」进入报表详情页面。
- 在报表详情页面,点击右上角的编辑按钮可以进入编辑模式。
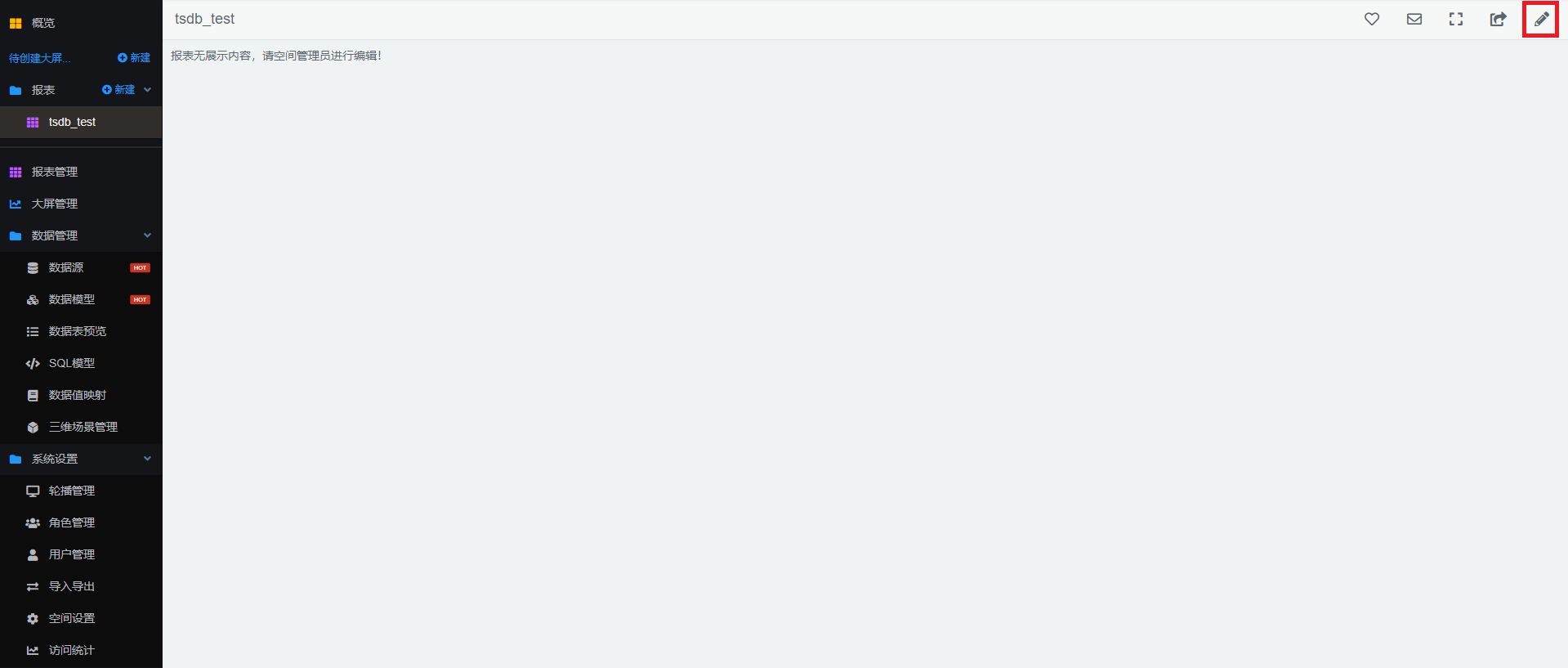
-
现在我们可以添加自己喜欢的图表并为其绑定SQL模型来展示我们的数据了。如何添加图表并绑定数据。
示例应用
这里我们使用的示例数据源含有2015年全年北京、上海、广州3个城市每一个空气监测站的每一天的早晨8点采集的有关风的气象模拟数据(非真实数据)。在TSDB中这样存储,Wind作为metric,表示TSDB存储的是有关风的气象数据,metric下有speed速度和direction方向两个域field,用每一个数据点所属城市的名称、邮编,以及该数据点对应的监测站的地理位置(经纬度)作为tag标签。
根据以上示例数据,我们可以根据以下几种场景制作合适的报表。
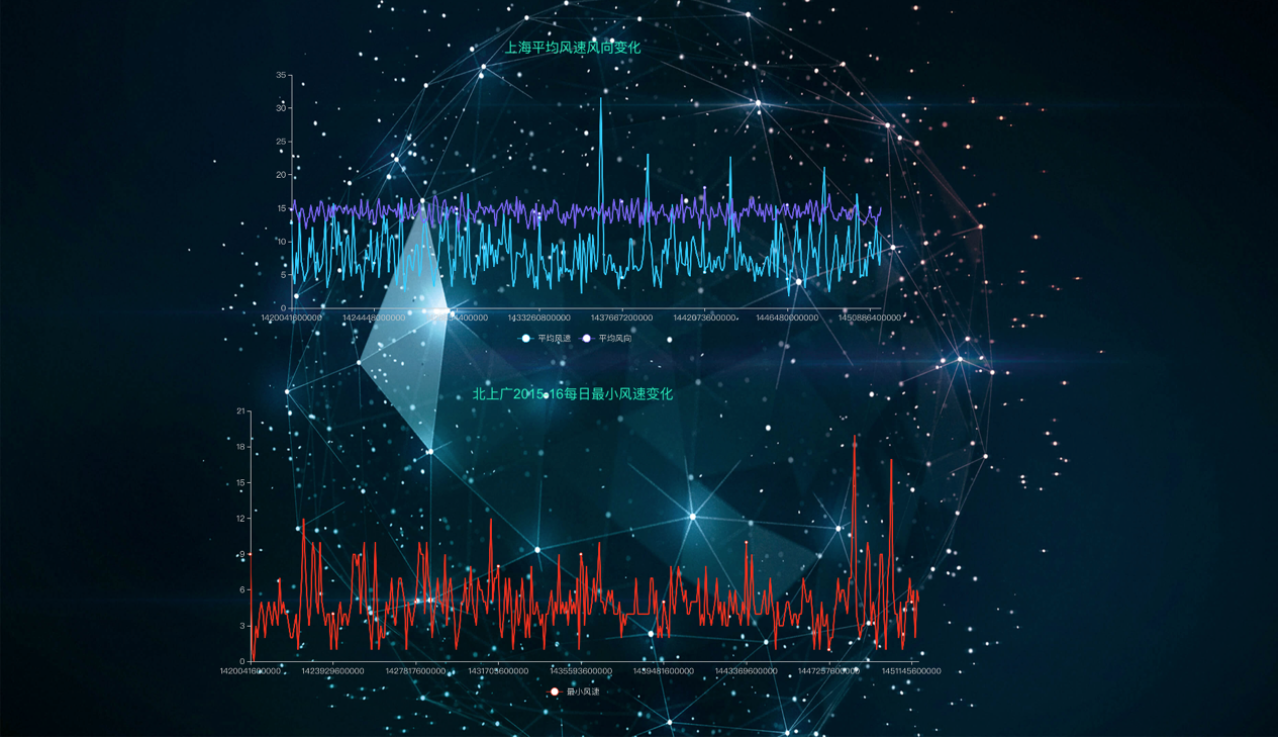
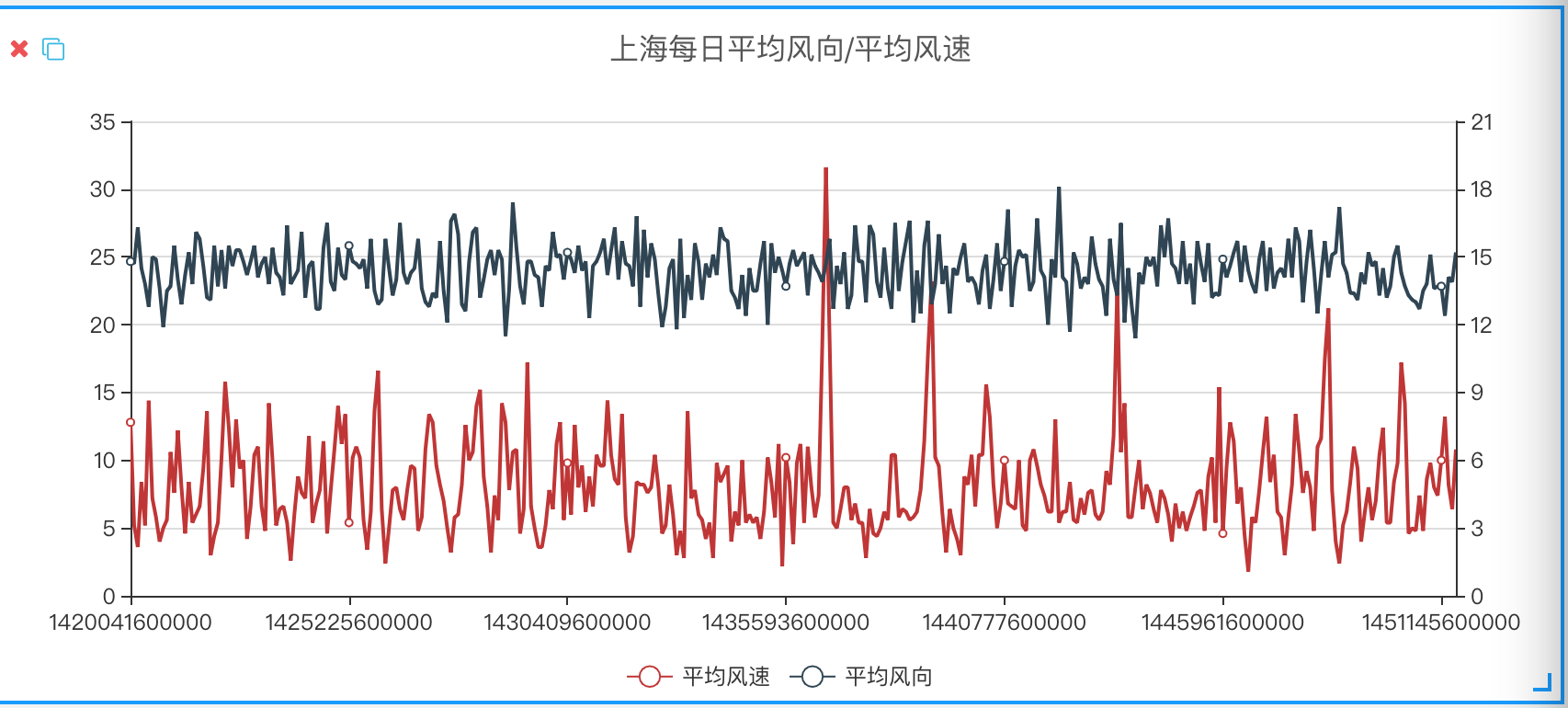
场景一: 制作报表分析2015年内,上海市每天的风向以及平均风速。
- 首先,新建一张图表;为了观察趋势变化,这里我们选择了折线图。
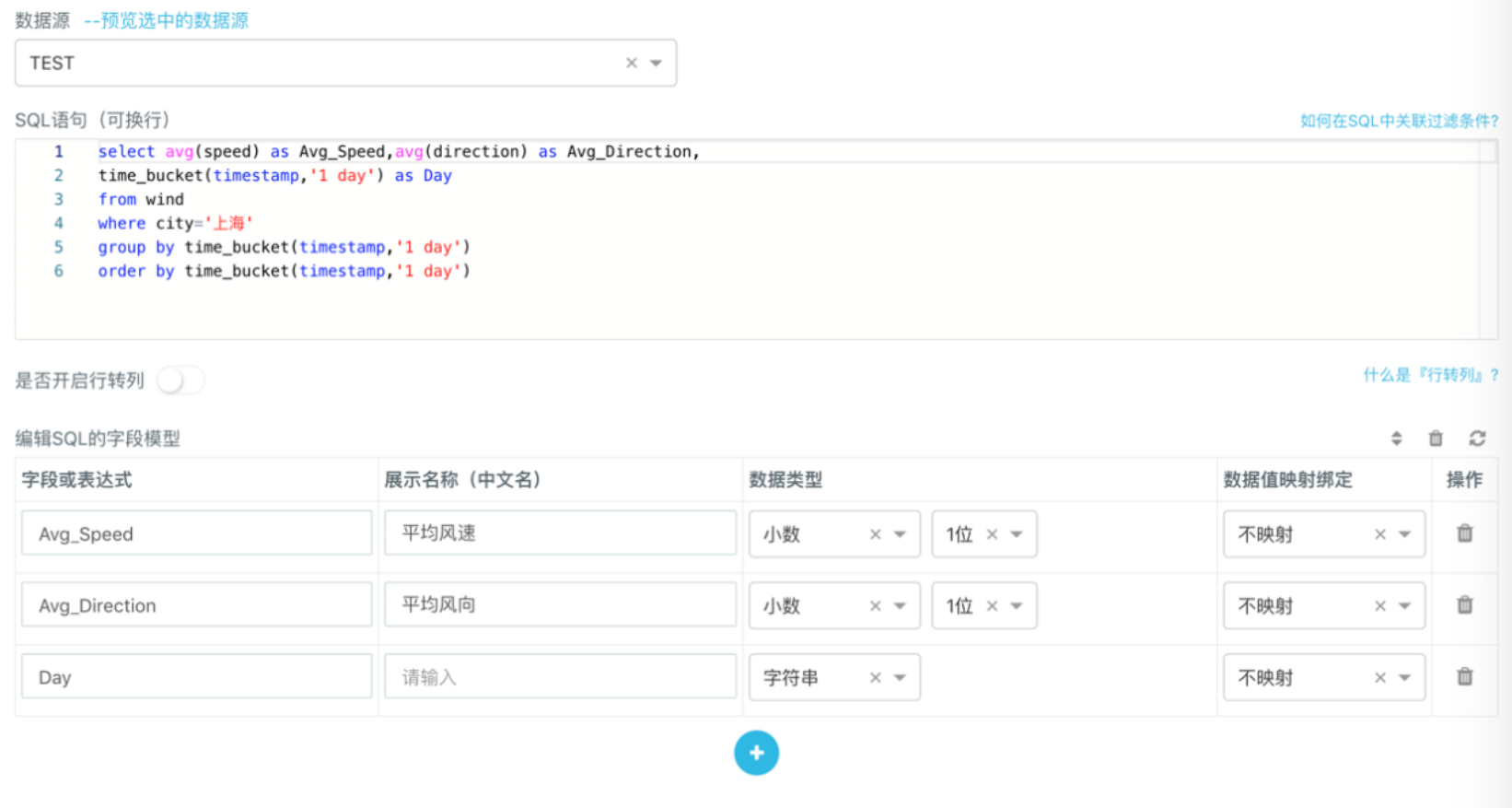
- 在折线图对应的「控制面板」> 「数据」> 「SQL建模」里新建一个SQL模型。
- 在模型编辑框中输入以下SQL查询语句并设置好字段模型。
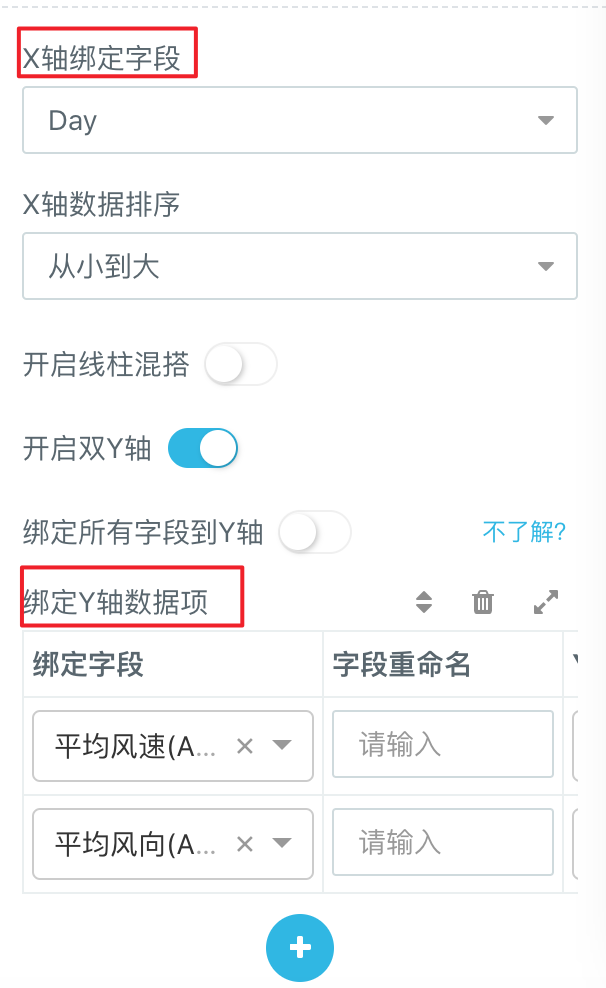
- 最后回到「控制面板」> 「数据」中为X轴、Y轴绑定好对应数据,点击刷新即可生成我们需要的报表。
select avg(speed) as Avg_Speed, avg(direction) as Avg_Direction,
time_bucket(timestamp, '1 day') as Day
from wind
where city = '上海'
group by time_bucket(timestamp, '1 day')
order by time_bucket(timestamp, '1 day')
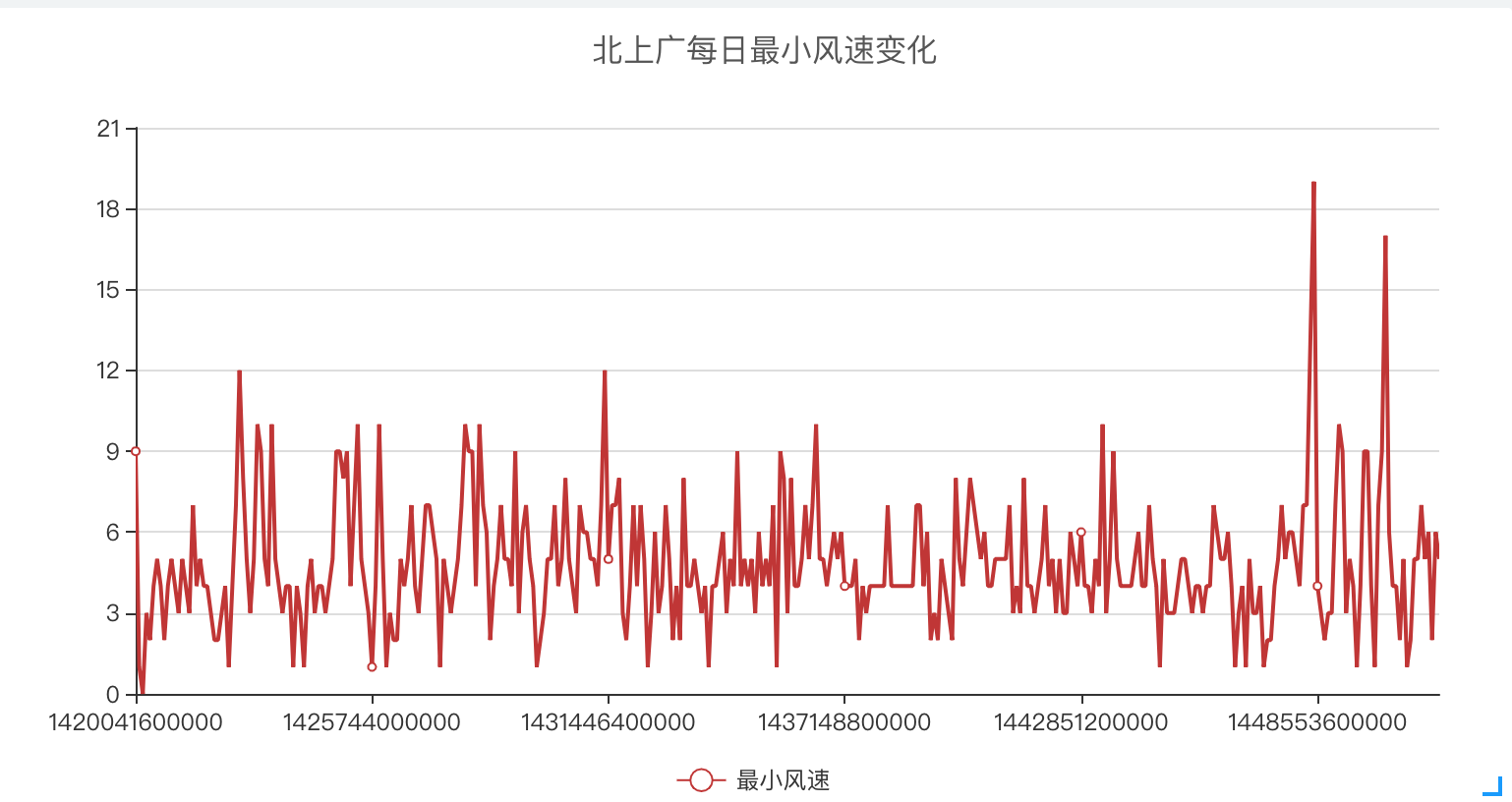
场景二: 制作报表分析2015年内,每天北京、上海、广州三个城市内所有监测点所采集到的最小风速。
- 首先,新建一张图表;为了观察趋势变化,这里我们选择了折线图。
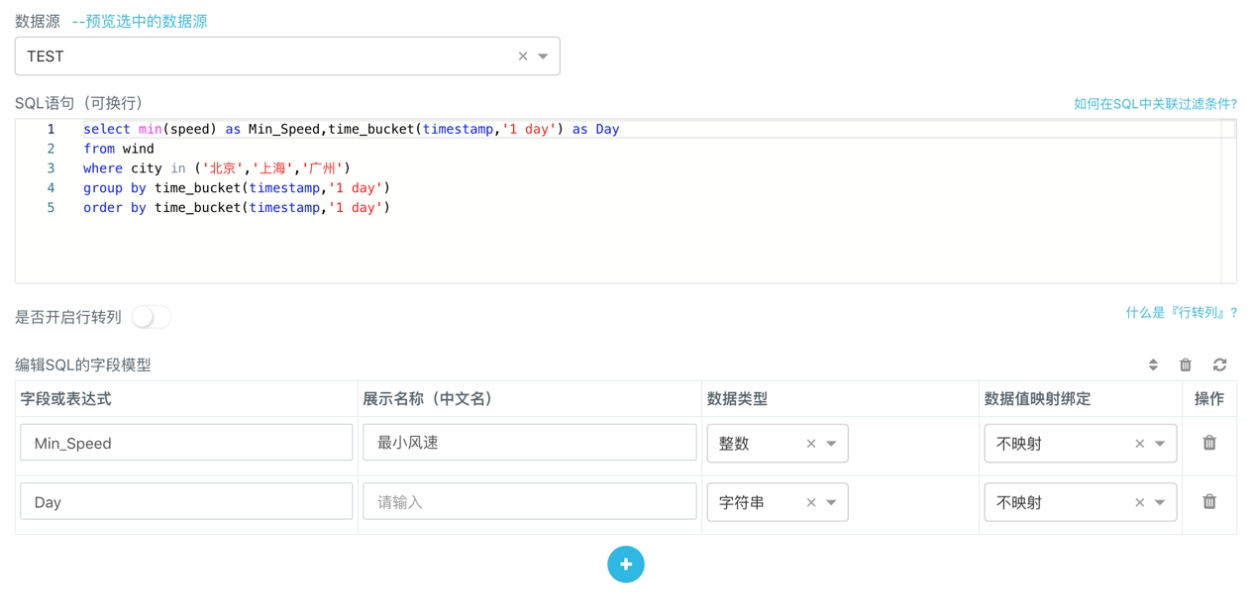
- 在折线图对应的「控制面板」> 「数据」> 「SQL建模」里新建一个SQL模型。
- 在模型编辑框中输入以下SQL查询语句并设置好字段模型。
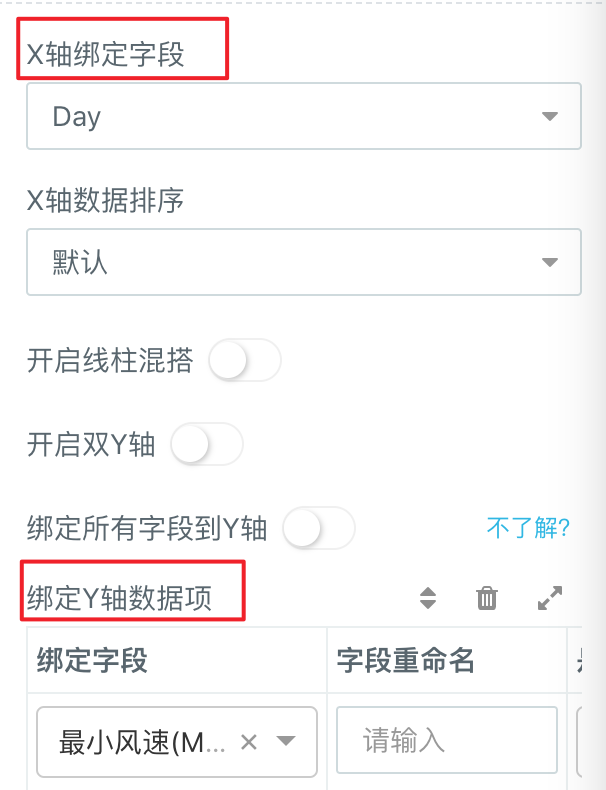
- 最后回到「控制面板」> 「数据」中为X轴、Y轴绑定好对应数据,点击刷新即可生成我们需要的报表。
select min(speed) as Min_Speed, time_bucket(timestamp, '1 day') as Day
from wind
where city in ('北京','上海','广州')
group by time_bucket(timestamp, '1 day')
order by time_bucket(timestamp, '1 day')
聚合查询
这里需要注意的是,做聚合查询时,分组时的字段名必须对接time_bucket函数,根据数据采集的周期适当聚合时间戳,否则生成的图表可能出现不必要的间断,无法做到趋势变化的展示。在以上示例中,采集周期为一天一次,因此在time_bucket聚合时选择以一天周期聚合,生成连续折线图。
time_bucket(timestamp, '1 day')
3.下钻示例
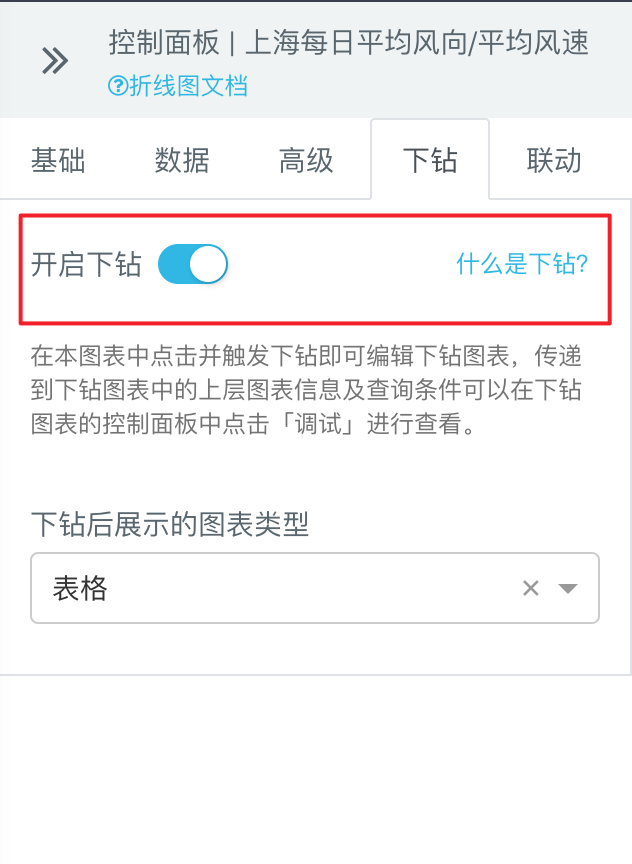
在完成报表制作后,用户可以选中一张图表,点击「下钻」开启下钻功能;「下钻」是指在点击一张图表的某一部分时,可以打开一个新的图表或超链接,进而查看与图表此部分相关的详细信息。 这里我们用之前生成的上海市平均风速风向的折线图作为示例来简单说明如何下钻。
- 点击想要进行下钻的折线图,在右侧「控制面板」> 「下钻」中点击选项卡开启下钻并设置触发的下钻图表类型统一为表格。
注:折线图只能触发单一类型下钻,个别类型图表可触发多种类下钻。
-
点击折线图里的任意一点可以触发下钻并打开下钻数据展示框。我们下钻得到的数据会展现在左侧,右侧则是用户可以编辑设置的「控制面板」。
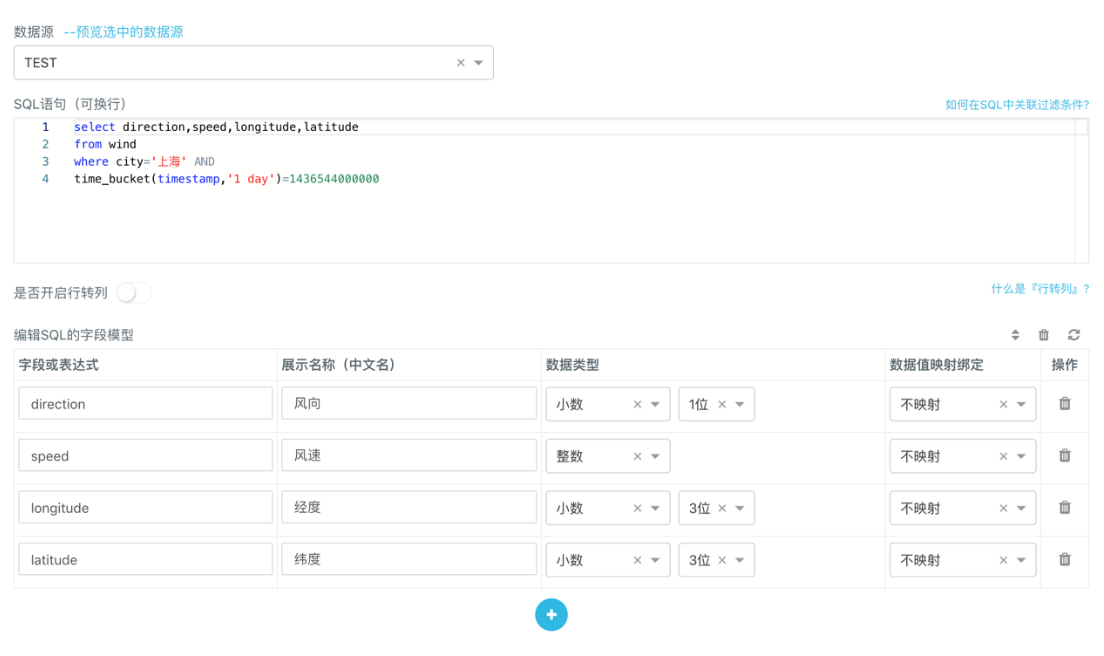
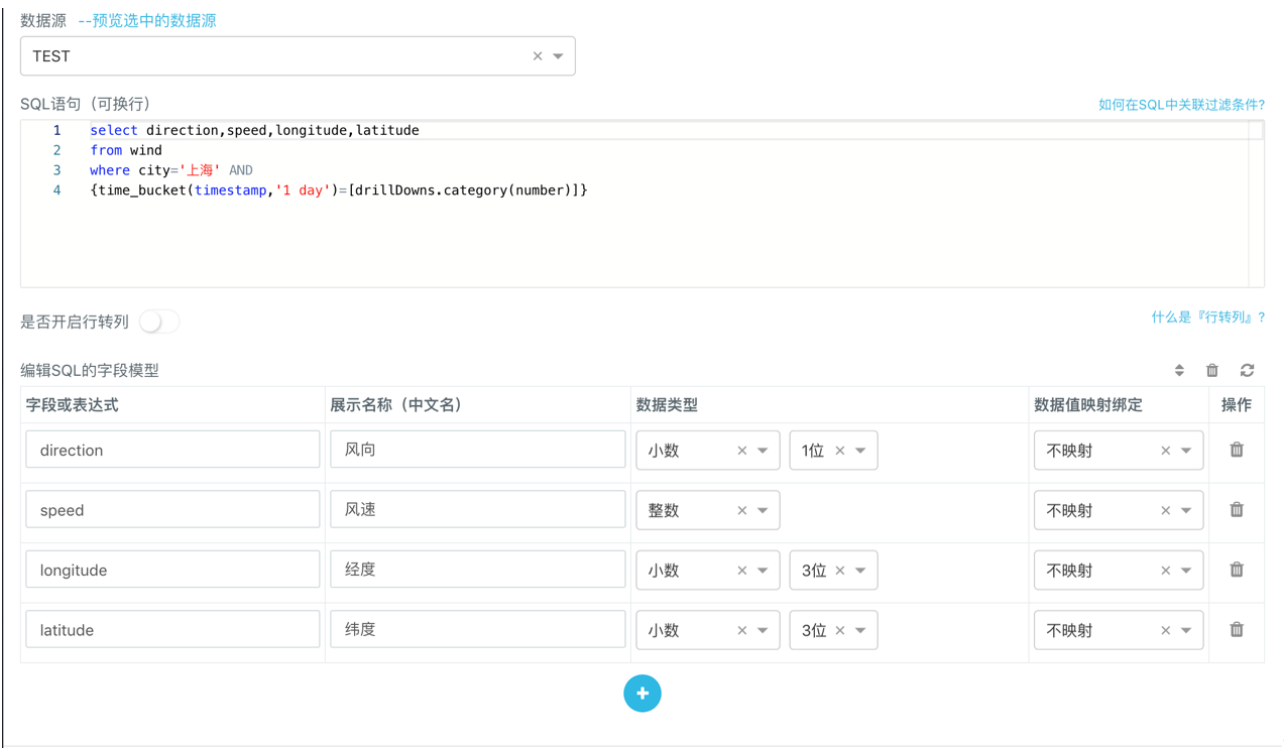
- 通过「下钻」,虽然当前折线图仅展示了上海市的平均风速风向,我们可以选中图中的任意数据点查看该点对应的timestamp里上海市每个监测点分别采集到的风速风向信息。 举个例子,我们在折线图上选中timestamp=1436544000000的任意数据点,在弹出的下钻「控制面板」> 「数据」>「SQL建模」里新建一个SQL模型。在模型编辑框中输入以下SQL查询语句并设置好字段模型。
select direction, speed, longitude, latitude
from wind
where city='上海' AND time_bucket(timestamp, '1 day') = 1436544000000
 因为在示例折线图中,timestamp按照time_bucket函数作过聚合,所以在下钻建模时,按照timestamp过滤的条件需要改为按照 time_bucket函数过滤,否则无法查询到数据。
因为在示例折线图中,timestamp按照time_bucket函数作过聚合,所以在下钻建模时,按照timestamp过滤的条件需要改为按照 time_bucket函数过滤,否则无法查询到数据。
time_bucket(timestamp, '1 day') = 1436544000000
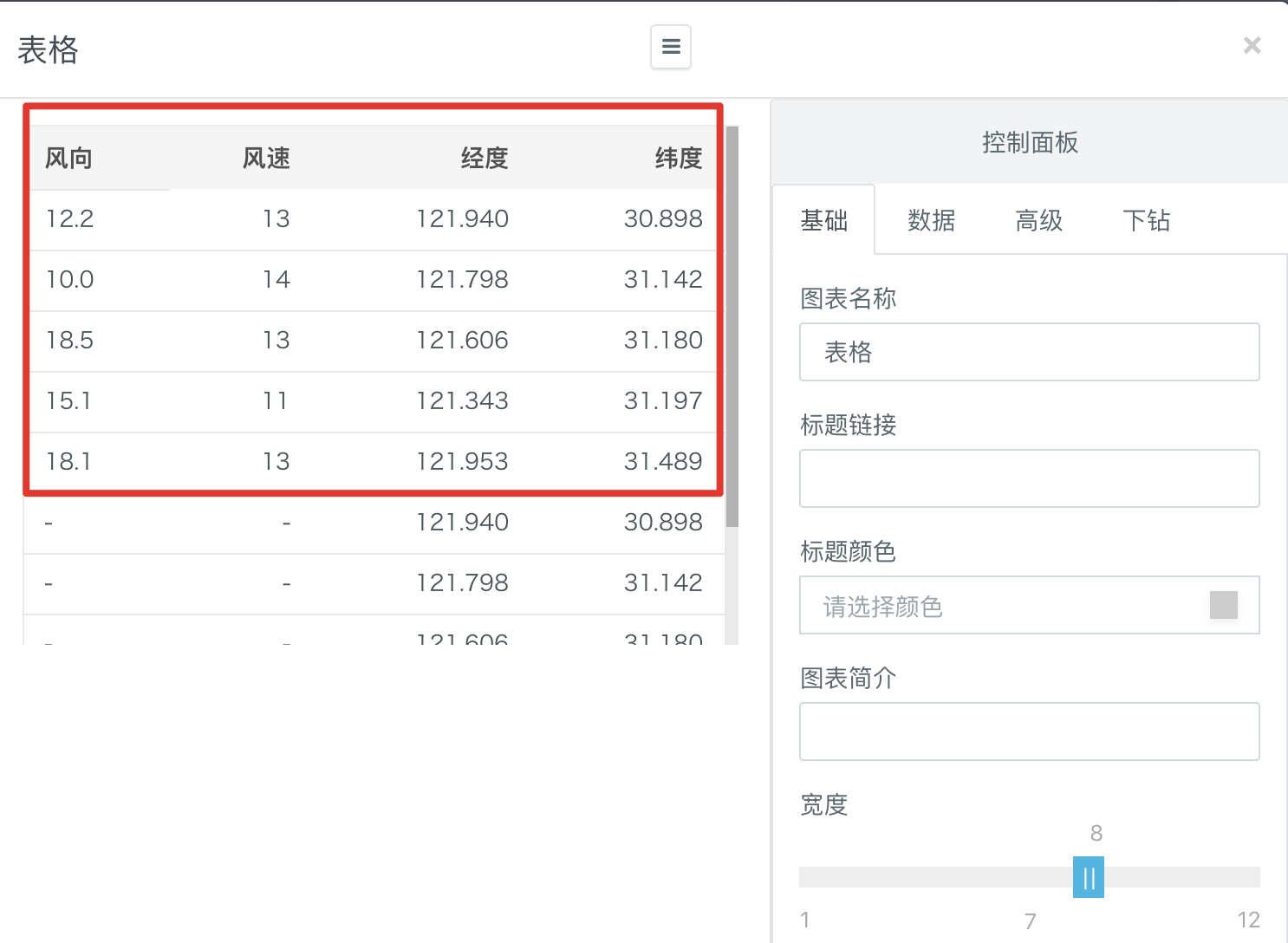
- 刷新图表后,可以在左侧看到在timestamp=1436544000000的那天,上海市一共5个监测点分别收集到的风速风向信息:
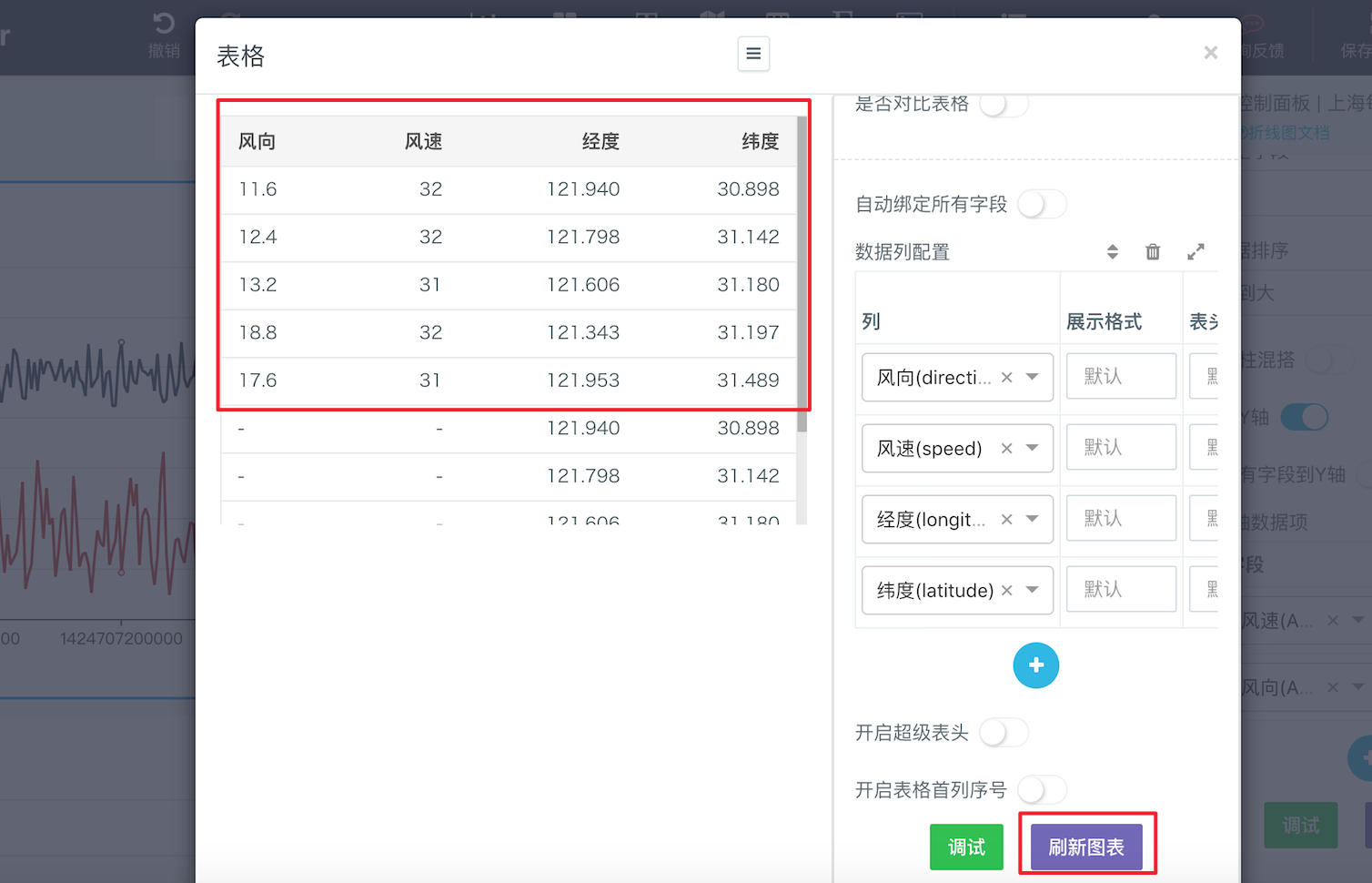
- 更方便的是,我们还可以使用下钻参数来编写用来下钻的SQL模型。 举个例子,我们可以用drillDowns里面的category变量替换之前恒定的timestamp。这样修改后,只要选中折线图上任意一点,展示下钻数据的图表都会直接根据选中点的timestamp自动刷新,生成在选中点对应timestamp里,上海市所有监测点分别采集的风速风向信息,无需手动修改SQL语句。
select direction, speed, longitude, latitude
from wind
where city='上海' AND
{time_bucket(timestamp, '1 day')=[drillDowns.category(number)]}
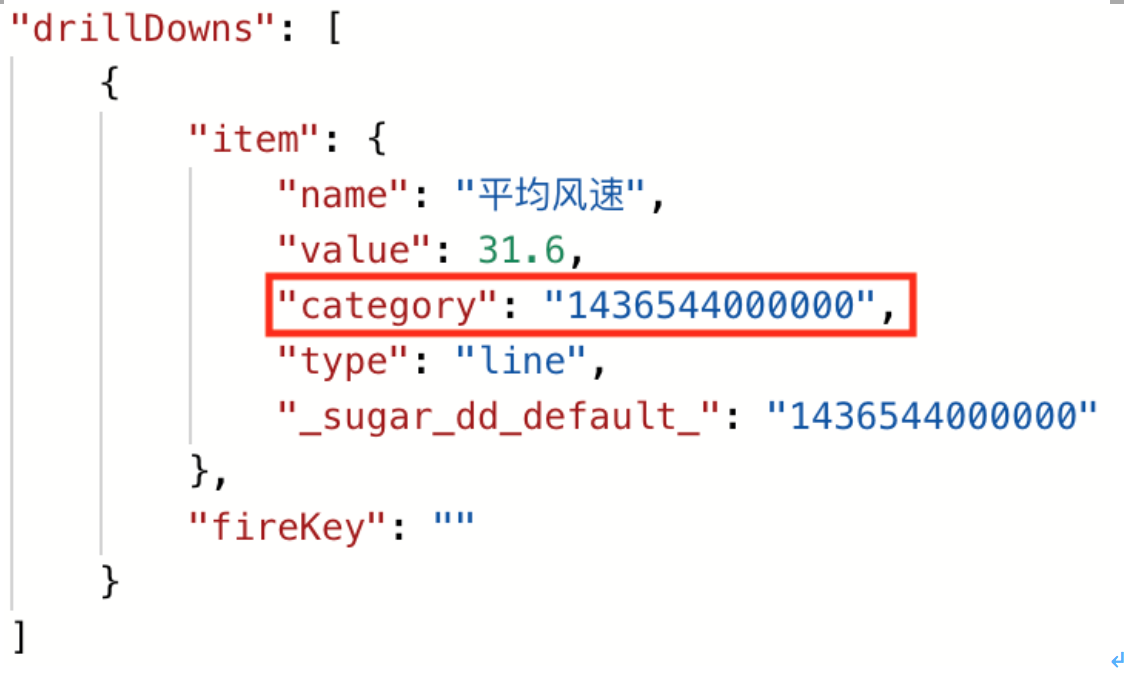
比如此时任意选择一个timestamp=1420041600000的数据点,点击触发下钻,弹出的数据展示框已经展示了在timestamp=1420041600000的那天,上海市一共5个监测点分别收集到的风速风向信息,无需我们手动更新SQL模型里timestamp的值。
4. 大屏展示示例
下面简单介绍如何对报表进行大屏展示,详细的教程可参见大屏制作。
- 在Sugar「空间广场」的左侧管理中心点击进入「系统设置」> 「大屏管理」,然后点击「添加新的大屏」,输入自定义信息并选择喜欢的模板来新建大屏。
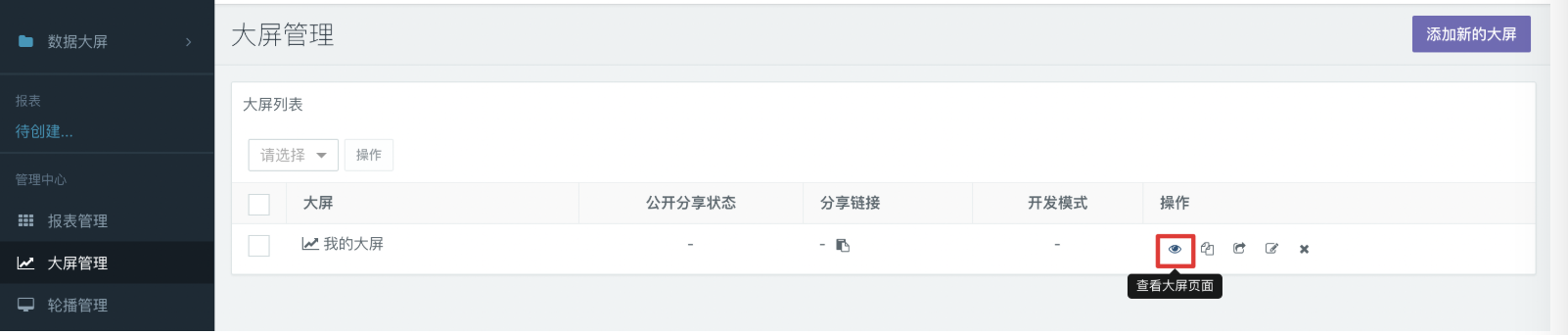
- 新建完成后,可以在大屏列表中看到刚刚新建的大屏。点击右侧的眼睛图标进入大屏浏览页面,然后再点击右上角的编辑按钮即可以进入编辑模式。
- 进入大屏编辑页面后,新建折线图,利用已经建立的SQL模型(参见上方报表示例)为图表绑定数据,生成图表后利用工具栏中文字选项为大屏上的报表添加合适标题,示例如下:
- 现在可以对整个界面做一些基础美化,比如为整个大屏选择合适的背景,对新建的两个折线图进行排版,按照水平线对齐,经整理后示例效果如下: