

文档简介:



1 BMR spark sql
1.1 Spark-tsdb-connector
TSDB对接spark sql是通过实现org.apache.spark.rdd.RDD(即Resilient Distributed Dataset)和一些相关的接口,方便用户通过spark来查询TSDB的数据。
Jar下载地址:http://tsdb-bos.gz.bcebos.com/spark-tsdb-connector-all.jar
如果是本地spark集群,请下载jar到本地;如果使用bmr,则上传到bos或者直接使用地址bos://iot-tsdb/spark-tsdb-connector-all.jar。
支持的版本:spark 2.1.0,jdk 1.7。
1.2 作业程序
1.2.1 查询tsdb的通用作业程序
Main class:
package com.baidu.cloud.bmr.spark;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SQLContext;
public class TsdbSparkSql {
public static void main(String[] args) {
if (args.length != 6) {
System.err.println("usage: spark-submit com.baidu.cloud.bmr.spark.TsdbSparkSql"
+ "");
System.exit(1);
}
String endpoint = args[0];
String ak = args[1];
String sk = args[2];
String metric = args[3];
String sql = args[4];
String output = args[5];
SparkConf conf = new SparkConf().setAppName("TsdbSparkSql");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
Datasetdataset = sqlContext.read()
.format("tsdb") // 设置为tsdb源
.option("endpoint", endpoint) // tsdb实例endpoint
.option("access_key", ak) // AK
.option("secret_key", sk) // SK
.option("metric_name", metric) // 对应的metric
.load();
dataset.registerTempTable(metric);
sqlContext.sql(sql).rdd().saveAsTextFile(output); // 执行sql并存储到output中
}
}
endpoint为IP:PORT格式的情形下:
package com.baidu.cloud.bmr.spark;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SQLContext;
public class TsdbSparkSql {
public static void main(String[] args) {
if (args.length != 8) {
System.err.println("usage: spark-submit com.baidu.cloud.bmr.spark.TsdbSparkSql
"
+ "");
System.exit(1);
}
String endpoint = args[0];
String host = args[1];
String grpcPort = args[2];
String ak = args[3];
String sk = args[4];
String metric = args[5];
String sql = args[6];
String output = args[7];
SparkConf conf = new SparkConf().setAppName("TsdbSparkSql");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
Datasetdataset = sqlContext.read()
.format("tsdb") // 设置为tsdb源
.option("endpoint", endpoint) // tsdb实例endpoint
.option("host", host) // host
.option("grpc_port", grpcPort) // grpc port
.option("access_key", ak) // AK
.option("secret_key", sk) // SK
.option("metric_name", metric) // 对应的metric
.load();
dataset.registerTempTable(metric);
sqlContext.sql(sql).rdd().saveAsTextFile(output); // 执行sql并存储到output中
}
}
依赖:
org.apache.sparkspark-sql_2.102.1.2
需要将程序打包为jar文件,放入bos中,在配置作业时需要用到该文件的bos路径。
1.2.2 更多参数的作业程序
Main class:
package com.baidu.cloud.bmr.spark;
import static org.apache.spark.sql.types.DataTypes.DoubleType;
import static org.apache.spark.sql.types.DataTypes.LongType;
import static org.apache.spark.sql.types.DataTypes.StringType;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.types.Metadata;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
public class TsdbSparkSqlMoreOptions {
public static void main(String[] args) {
if (args.length != 6) {
System.err.println("usage: spark-submit com.baidu.cloud.bmr.spark.TsdbSpa
rkSqlMoreOptions"
+ "");
System.exit(1);
}
String endpoint = args[0];
String ak = args[1];
String sk = args[2];
String metric = args[3];
String sql = args[4];
String output = args[5];
SparkConf conf = new SparkConf().setAppName("TsdbSparkSqlMoreOptions");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
StructType schema = new StructType(new StructField[] {
new StructField("time", LongType, false, Metadata.empty()), // 设置time列,为long
new StructField("value", DoubleType, false, Metadata.empty()), // 设置value列,为double
new StructField("city", StringType, false, Metadata.empty()) // 设置city列,为string
});
Datasetdataset = sqlContext.read()
.format("tsdb") // 设置为tsdb源
.schema(schema) // 设置自定义schema
.option("endpoint", endpoint) // tsdb实例endpoint
.option("access_key", ak) // AK
.option("secret_key", sk) // SK
.option("metric_name", metric) // 对应的metric
.option("field_names", "value") // schema中属于field的列名,用逗号分割,如"field1, field2",表示有两个field分别为field1,field2
.option("tag_names", "city") // 指定schema中的tag名,用逗号分割,"city,latitude",表示有两个tag分别为city,latitude
.option("split_number", "10") // 设置split的个数,split数据时会尽量与split number接近。
.load();
dataset.registerTempTable(metric);
sqlContext.sql(sql).rdd().saveAsTextFile(output);
}
}
依赖:
org.apache.sparkspark-sql_2.102.1.2
1.3 创建bmr spark集群
在使用BMR时,强烈建议您先阅读BMR文档.
选择BMR1.1.0版本,并选择spark 2.1.0。

1.4 创建作业
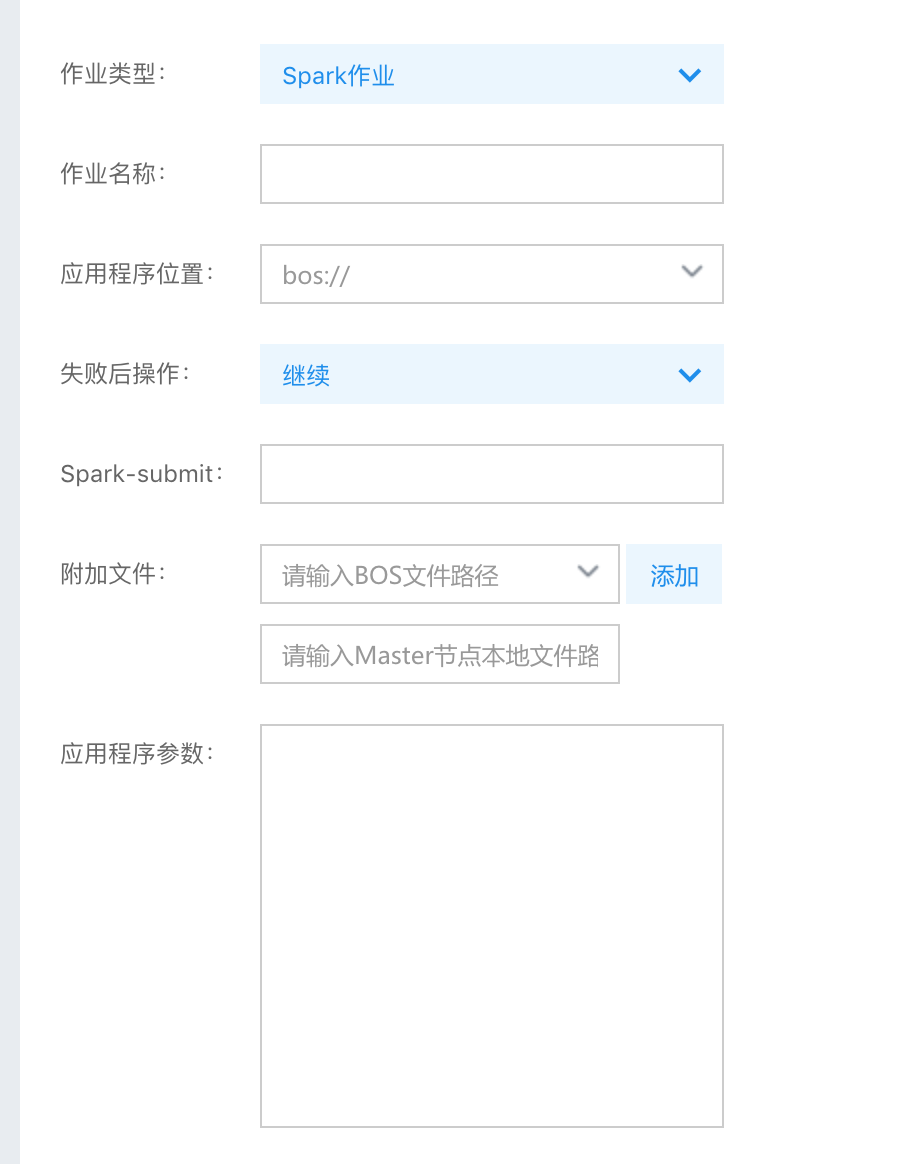
作业配置如下:
应用程序位置:bos://.jar Spark-submit:--class com.baidu.cloud.bmr.spark.TsdbSparkSql --jars bos:///spark-tsdb-connector-all.jar 应用程序参数:..tsdb.iot.gz.baidubce.com
"select count(1) from" "bos:///output/data"
需要注意的是:
- 应用程序配置其实是与2.1中作业程序相关的,请根据自己的作业程序来配置;
- Spark-submit中记得需要最后的“--jars”参数不能省略,需要指定为1.1中tsdb的connector。
1.5 场景示例
1.5.1 计算风速
风速数据由传感器定时上传到tsdb中,数据包含两个field分别为x和y,表示x轴和y轴方向的风速,如下由两个垂直方向的风速来计算出总的风速。
Main class:
package com.baidu.cloud.bmr.spark;
import static org.apache.spark.sql.types.DataTypes.DoubleType;
import static org.apache.spark.sql.types.DataTypes.LongType;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.types.Metadata;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
public class WindSpeed {
public static void main(String[] args) {
String endpoint = "";
String ak = "";
String sk = "";
String metric = "WindSpeed";
String output = "bos:///output/data";
SparkConf conf = new SparkConf().setAppName("TsdbSparkSqlMoreOptions");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
StructType schema = new StructType(new StructField[] {
new StructField("time", LongType, false, Metadata.empty()), // 设置time列,为long
new StructField("x", DoubleType, false, Metadata.empty()), // 设置x列,为double
new StructField("y", DoubleType, false, Metadata.empty()) // 设置y列,为double
});
Datasetdataset = sqlContext.read()
.format("tsdb") // 设置为tsdb源
.schema(schema) // 设置自定义schema
.option("endpoint", endpoint) // tsdb实例endpoint
.option("access_key", ak) // AK
.option("secret_key", sk) // SK
.option("metric_name", metric) // 对应的metric
.option("field_names", "x,y") // schema中属于field的列名
.load();
dataset.registerTempTable(metric);
sqlContext.sql("select time, sqrt(pow(x, 2) + pow(y, 2)) as speed from WindSpeed")
.rdd()
.saveAsTextFile(output);
}
}
依赖:
org.apache.sparkspark-sql_2.102.1.2
原始数据:
metric:WindSpeed
| time | field : x | field : y |
|---|---|---|
| 1512086400000 | 3.0 | 4.0 |
| 1512086410000 | 1.0 | 2.0 |
| 1512086420000 | 2.0 | 3.0 |
结果:
结果输出到output指定的bos文件夹中,样例如下
[1512086400000,5.000]
[1512086410000,2.236]
[1512086420000,3.606]
1.5.2 计算车辆在时间上的使用情况
车辆在行驶过程中会定时(每10秒)将数据上传到tsdb中,数据中包含车速speed。需要统计三种时长:
(1)停止时长:一段时间内这台车子有上报数据,但是上报的车速显示是0,可能是车子在等红灯。
(2)运行时长:一段时间内这台车子有上报数据,且上报的车速显示大于0,这台车子正在行驶中。
(3)离线时长:一段时间内这台车子没有上报数据的时长,这台车子已经停下并熄火了。
Main class:
package com.baidu.cloud.bmr.spark;
import static org.apache.spark.sql.types.DataTypes.LongType;
import static org.apache.spark.sql.types.DataTypes.StringType;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.types.Metadata;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
public class VehicleSpeed {
public static void main(String[] args) {
String endpoint = "";
String ak = "";
String sk = "";
String metric = "vehicle";
String output = "bos:///output/data";
SparkConf conf = new SparkConf().setAppName("TsdbSparkSqlMoreOptions");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
StructType schema = new StructType(new StructField[] {
new StructField("time", LongType, false, Metadata.empty()), // 设置time列,为long
new StructField("speed", LongType, false, Metadata.empty()), // 设置speed列,为long
new StructField("carId", StringType, false, Metadata.empty()) // 设置carId列,为string
});
Datasetdataset = sqlContext.read()
.format("tsdb") // 设置为tsdb源
.schema(schema) // 设置自定义schema
.option("endpoint", endpoint) // tsdb实例endpoint
.option("access_key", ak) // AK
.option("secret_key", sk) // SK
.option("metric_name", metric) // 对应的metric
.option("field_names", "speed") // schema中属于field的列名
.option("tag_names", "cardId") // 指定tag名
.load();
dataset.registerTempTable(metric);
sqlContext.sql("select floor((time - 1512057600000) / 86400000) + 1 as day, count(*) * 10 as stop_seconds"
+ " from vehicle where carId='123' and time >= 1512057600000 and time
< 1514736000000 and speed = 0" + " group by floor((time - 1512057600000) / 86400000)") .rdd() .
saveAsTextFile(output + "/stopSeconds"); sqlContext.sql("select floor((time - 1512057600000) /
86400000) + 1 as day, count(*) * 10 as run_seconds" + " from vehicle where carId='123' and time >= 1512057600000 and time
< 1514736000000 and speed > 0"
+ " group by floor((time - 1512057600000) / 86400000)")
.rdd()
.saveAsTextFile(output + "/runSeconds");
sqlContext.sql("select floor((time - 1512057600000) / 86400000) + 1 as day, 2678400 - count(*) * 10 as"
+ " offline_seconds from vehicle where carId='123' and time >= 1512057600000
and time < 1514736000000" + " group by floor((time - 1512057600000) / 86400000)") .rdd()
.saveAsTextFile(output + "/offlineSeconds"); } }
依赖:
org.apache.sparkspark-sql_2.102.1.2
原始数据
metric : vehicle
| time | field : speed | tag |
|---|---|---|
| 1512057600000 | 40 | carId=123 |
| 1512057610000 | 60 | carId=123 |
| 1512057620000 | 50 | carId=123 |
| ... ... | ... | carId=123 |
| 1514721600000 | 10 | carId=123 |
结果
结果输出到output指定的bos文件夹中,样例如下:
[1,3612]
[2,3401]
...
[31,3013]
[1,17976]
[2,17968]
...
[31,17377]
[1,64812]
[2,65031]
...
[31,66010]
