




概览
通过定时任务创建BMR集群,分析日志数据,定时释放集群,为用户大大节约了使用成本。
需求场景
对于业务稳定且有规律的用户,日志的峰值和低谷的规律一般是固定的。对于有规律的日志业务场景,用户只需要在特定的时间段内用集群进行分析即可,其余时间无需使用集群。传统的大数据集群一旦构建则无法释放或者需要人工手动释放,使用成本较高。解决这一场景下的日志分析十分必要。
方案概述
通过定时任务您可定时启动集群运行作业,适用于对已有数据有规律的定时分析并获取结果。优势如下:
- 省时:任务只需一次创建,一键启停。
- 省钱:集群随任务的启停而启停。
- 省力:托管式集群,无需部署和运维。
本文通过定时启动集群运行MapReduce作业分析网站日志以统计每天的访问量,介绍定时任务的实现过程:
示例日志
示例日志是Nginx日志,存储在对象存储服务BOS的公共可读的路径中:
-
存储在“华北-北京”区域的样例数据仅华北区域的BMR集群可用,路径如下:
- bos://datamart-bj/access-log/201701102000/access.log
- bos://datamart-bj/access-log/201701112000/access.log
- bos://datamart-bj/access-log/201701122000/access.log
- bos://datamart-bj/access-log/201701132000/access.log
- bos://datamart-bj/access-log/201701142000/access.log
-
存储在“华南-广州”区域的样例数据仅华南区域的BMR集群可用,路径如下:
- bos://datamart-gz/access-log/201701102000/access.log
- bos://datamart-gz/access-log/201701112000/access.log
- bos://datamart-gz/access-log/201701122000/access.log
- bos://datamart-gz/access-log/201701132000/access.log
- bos://datamart-gz/access-log/201701142000/access.log
关于百度智能云的区域说明,请参考区域选择说明。
设计作业
- 撰写作业程序。本文使用的MapReduce样例程序的代码已上传至:https://github.com/BCEBIGDATA/bmr-sample-java,您可通过GitHub克隆代码至本地设计自己的程序。
- 编译程序生成jar包,具体可参考编译Maven项目。
- 上传编译生成的jar包到对象存储BOS(具体操作详见对象存储BOS入门指南)。
存储日志
- 规划时间策略如下:自2017年1月10日至1月14日,每天20时分析前一天的日志数据。
- 准备日志数据。您可直接使用百度智能云提供的示例日志,在熟悉定时任务后,可参考数据准备选择您自己的日志数据。
启动定时任务
创建集群模板
- 登录控制台,选择“产品服务->MapReduce BMR”,点击“集群模板”,进入模板列表页。
-
点击“创建模板”,在“集群基础设置”区做如下配置:
- 集群模板:输入模板名称“timedtask”。
- 日志:选择集群日志的存储路径。
- 高级设置:打开“自动终止”开关。
- 在“集群配置”区,选择镜像版本BMR 1.0.0(hadoop 2.7),并选择模板“hadoop”。
- 其他设置可保持默认设置,点击“完成”即可。
- 点击已创建的集群模板,可查看模板详情如下:

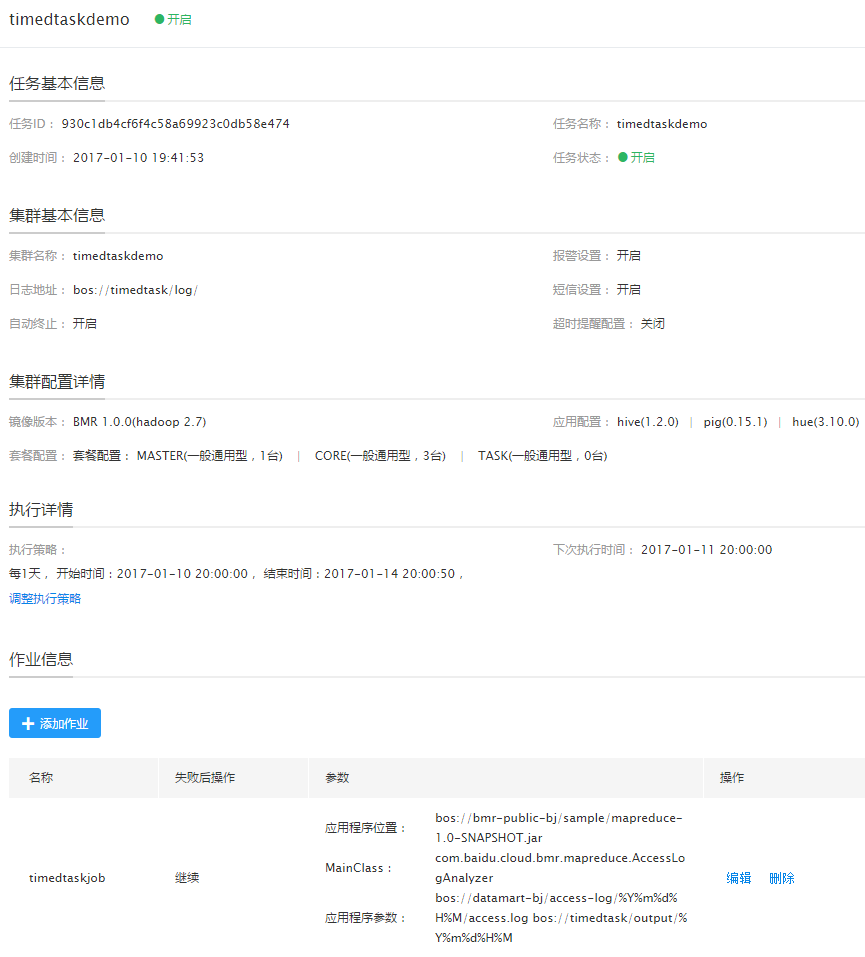
创建定时任务
- 在“产品服务->MapReduce BMR”页,点击“定时任务”,进入定时任务列表页。
- 点击“创建定时任务”,在“任务参数”区输入任务名称,并选择已创建的集群模板“timedtask”。
- 在“执行频率”区,设置执行频率为“每1天”,并指定开始任务时间点“2017年1月10日20:00:00”,任务结束时间点“2017年1月10日20:00:00”。
-
在“作业设置”区,点击“添加作业”,做如下配置:
- 作业类型:选择“java作业”。
- 作业名称:输入“timedtaskjob”。
-
应用程序位置:若使用您自行编译的程序,请上传程序jar包至BOS或者您本地的HDFS中,并在此输入程序路径;您也可直接使用百度智能云提供的样例程序,路径如下:
- 华北-北京区域的BMR集群对应的样例程序路径:bos://bmr-public-bj/sample/mapreduce-1.0-SNAPSHOT.jar。
- 华南-广州区域的BMR集群对应的样例程序路径:bos://bmr-public-gz/sample/mapreduce-1.0-SNAPSHOT.jar。
- 失败后操作:继续。
- MainClass:输入“com.baidu.cloud.bmr.mapreduce.AccessLogAnalyzer”。
-
应用程序参数:指定输入数据的路径、结果输出的路径(可选BOS或HDFS),其中输出路径必须具有写权限且该路径不能已存在。以样例日志作为输入数据,BOS作为输出路径为例,输入如下:
- 华北-北京区域的BMR集群对应的参数:bos://datamart-bj/access-log/201701102000/access.log bos://{your-bucket}/output/%Y%m%d%H%M。
-
华南-广州区域的BMR集群对应的参数:bos://datamart-gz/access-log/201701102000/access.log bos://{your-bucket}/output/%Y%m%d%H%M。
说明:
- 请替换{your-bucket}为您自己的bucket名字。
- 系统启动集群时可根据输入/输出地址自动匹配字串“%Y%m%d%H%M”对应时间的文件。即2017年11月28日20:00启动集群时调用地址是bos://datamart-bj/access-log/201701102000/access.log的数据,运行结果自动输出至地址是bos://{your-bucket}/output/201711282000/文件夹内。
- 点击“确定”完成定时任务的作业添加。
- 点击“完成”,定时任务创建完毕。
- 可在“产品服务>MapReduce>MapReduce-定时任务”页中查看已创建的任务,如下图所示:
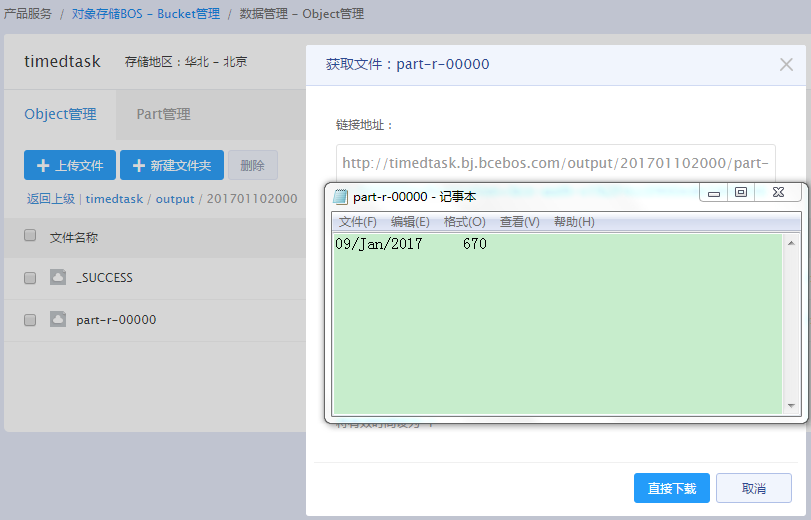
读取分析结果
2017年1月10日至1月14日,每天20时系统会自动启动集群并运行作业,作业运行结束后集群自动释放,您可至bos://{your-bucket}/output/路径下查看每次任务的执行结果。下图是第一次任务的分析结果:
相关产品
BMR(MapReduce)、对象存储(BOS)
