




MapReduce混部方案可以让您以“分时”的方式使用BCC云服务器,即在云服务器BCC繁忙的时候专注自身业务,空闲的时候分一部分精力帮助BMR集群的大数据计算。既提高了云服务器BCC的资源利用率,也提高了BMR集群的计算能力,降低总体IT支出。
国内某著名互联网企业,租用BCC云服务器用于搭建业务系统,并创建了BMR集群对每天的业务数据做大规模计算,如下图所示:
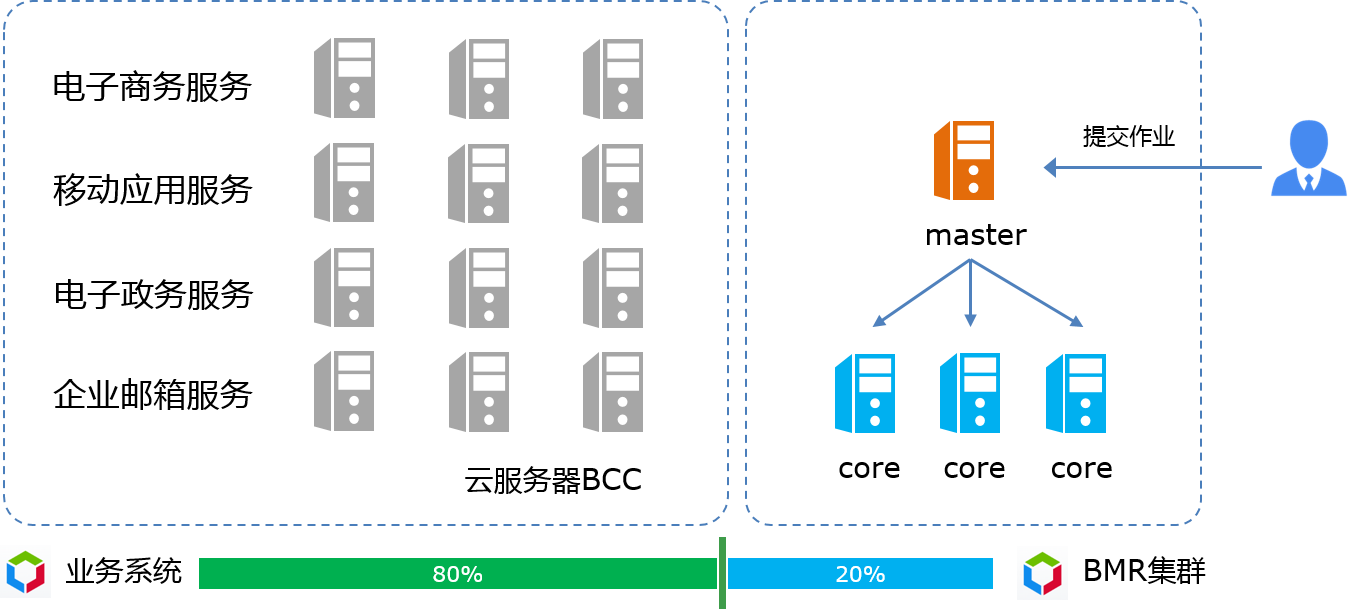
电子商务、邮件等业务系统的访问量具有明显的波峰波谷现象,为了保证业务的正常运转,该企业已按照业务的最高使用量来购买了BCC资源,但凌晨网站的访问量非常少,这时支撑业务系统的BCC资源会大量被浪费。
BMR混部方案可以解决这个问题!在凌晨业务系统资源占用率较低时,将空闲的BCC计算资源纳入到BMR的大数据计算中,增加BMR集群的计算能力,当访问量回升时,再将其从BMR系统中分离出来,如下图所示,这样,分时使用BCC资源,通过削峰填谷保证了资源利用最大化,大大降低了总成本。
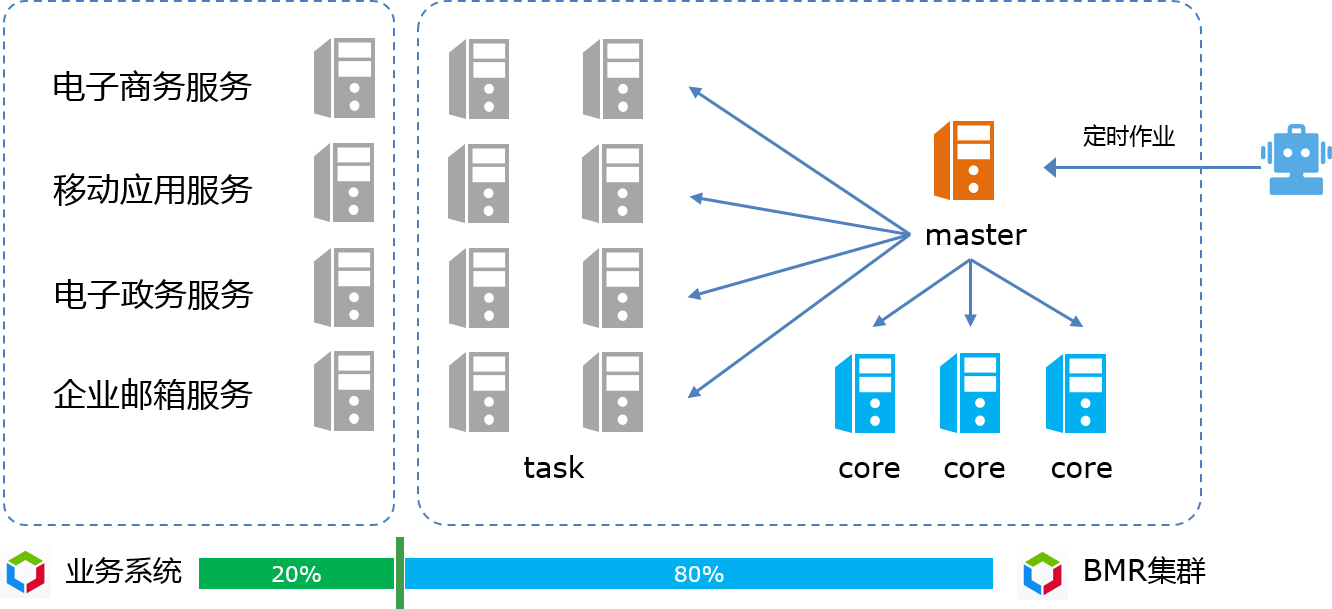
本质上,BMR混部方案使用BCC为BMR集群扩容,即扩容后的集群中包含BMR节点以及BCC节点,其中BCC节点相当于BMR集群的task节点,增加了BMR集群的计算能力。扩容后,Master节点在分配任务时对来自BCC或者BMR的task节点一视同仁,同样享受BMR提供的作业级容错。
如需深入了解BMR混部方案,请联系bce@baidu.com或者提交工单,百度智能云会为您提供完整的解决方案。
