




-
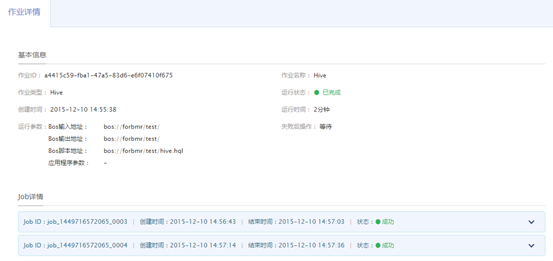
在“产品服务>MapReduce>MapReduce-作业列表”中,点击作业名称,可查看作业基本信息。
-
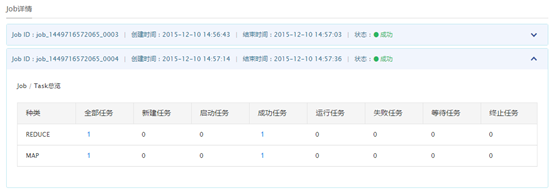
Hadoop将job分成若干个task进行处理,共有两种类型的task,分别为map task和reduce task。点击下拉尖括号,查看各task的任务处理情形。
-
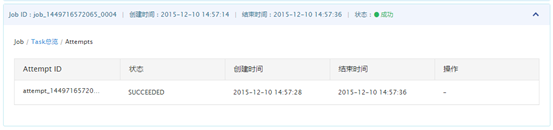
当task运行失败时,每个task有四次的重试机会,每次的重试信息记录在“查看Attempt”中。点击“MAP”和“REDUCE”对应的“查看Attempt”,查看attempt信息。
-
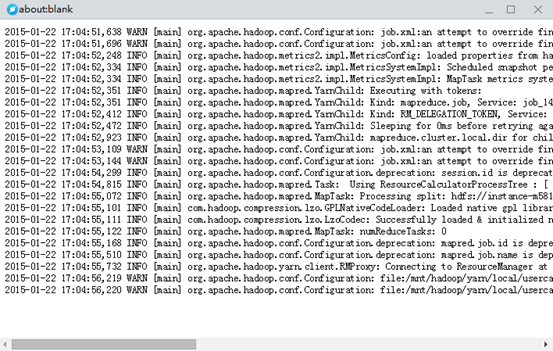
点击“作业日志”,可查看作业日志,其中Spark作业无作业日志。共有三种日志类型显示,分别是syslog、stderr和stdout。
-
Syslog是记录作业运行时的详细信息;
-
stderr是记录运行作业时的错误信息;
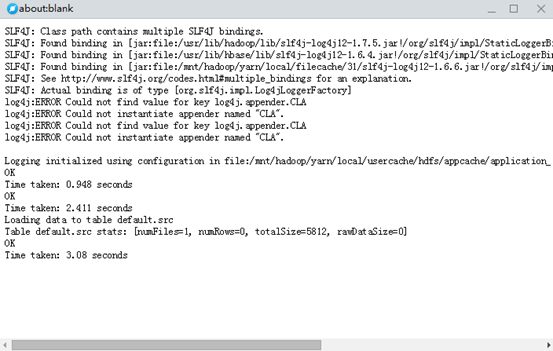
-
stdout记录作业运行完毕后的输出信息;
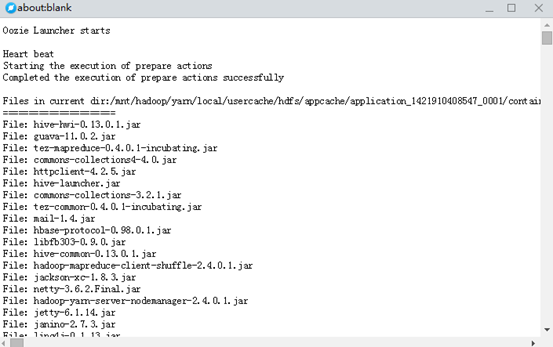
-
百度智能云MapReduce - 查看结果
文档简介:
在“产品服务>MapReduce>MapReduce-作业列表”中,点击作业名称,可查看作业基本信息。
Hadoop将job分成若干个task进行处理,共有两种类型的task,分别为map task和reduce task。点击下拉尖括号,查看各task的任务处理情形。
