聚类算法
高斯混合模型聚类
高斯混合模型(Gaussian Mixture Model)通常简称GMM,高斯混合模型是由多个高斯分布的结合组成的概率分布模型,是一种业界广泛使用的聚类算法,该方法使用了高斯分布作为参数模型,并使用了期望最大(Expectation Maximization,简称EM)算法进行训练。
输入
- 输入一个数据集,选择需要聚类的特征列,特征列只支持数值或数值列表类型。
输出
- 输出高斯混合聚类模型。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 聚类数 | 是 | 聚类数 范围:[2, 500]。 | 2 |
| 最大迭代次数 | 是 | 最大迭代次数 范围:[1, 10000]。 | 100 |
| 收敛容差 | 否 | 当小于该值时,停止迭代 范围:[0.0, inf)。 | 0.01 |
| 随机种子 | 否 | 随机种子,用于保证多次训练结果相同。 | -1 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 特征列 | 是 | 支持数值或数值列表类型。 | 无 |
计算逻辑
高斯混合模型:
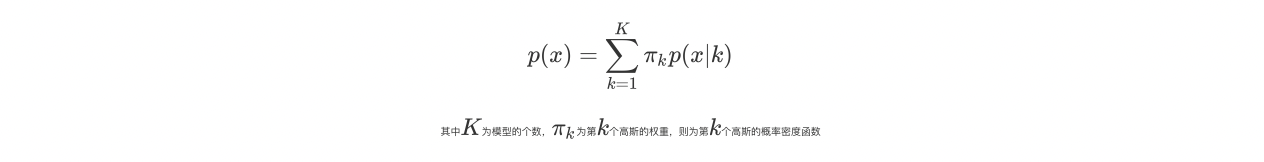
使用示例
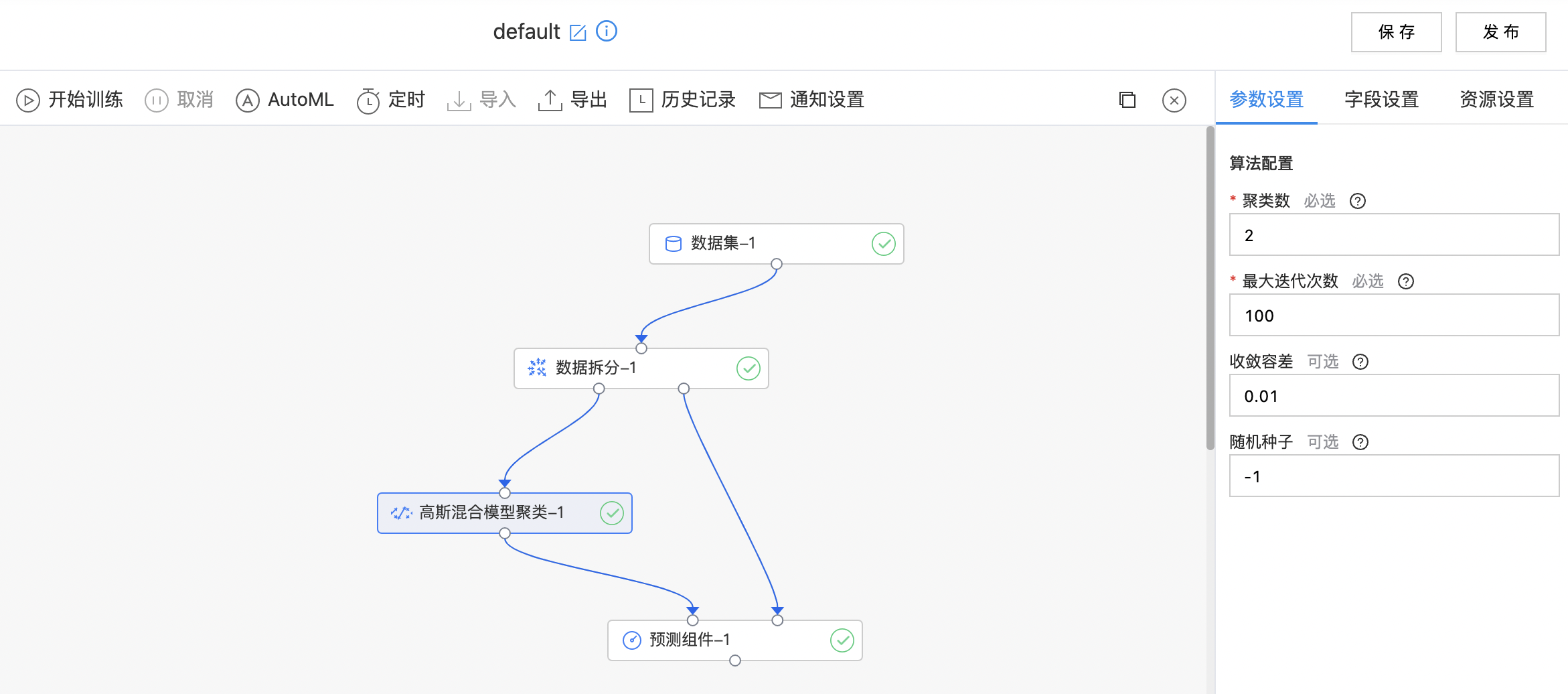
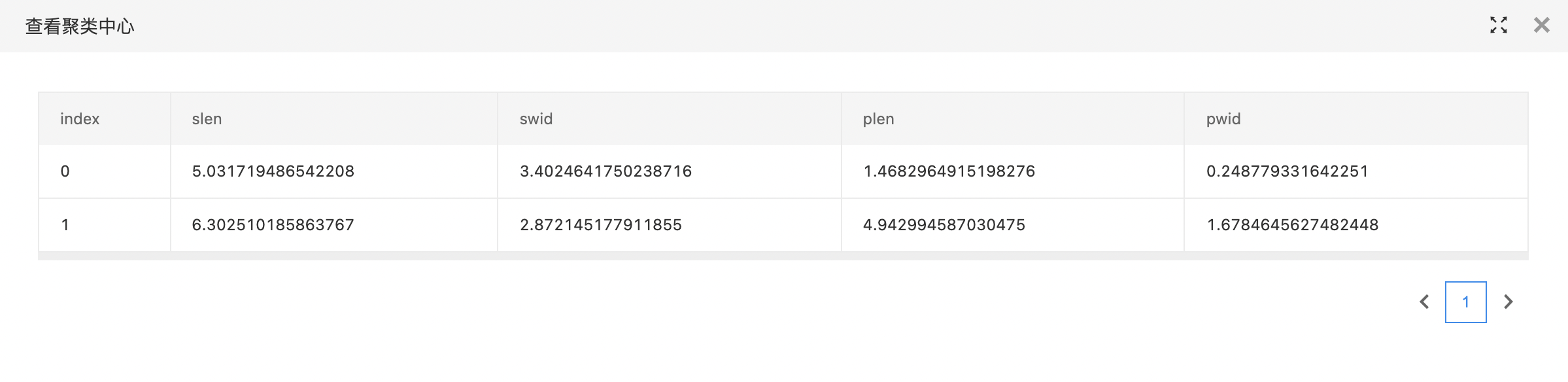
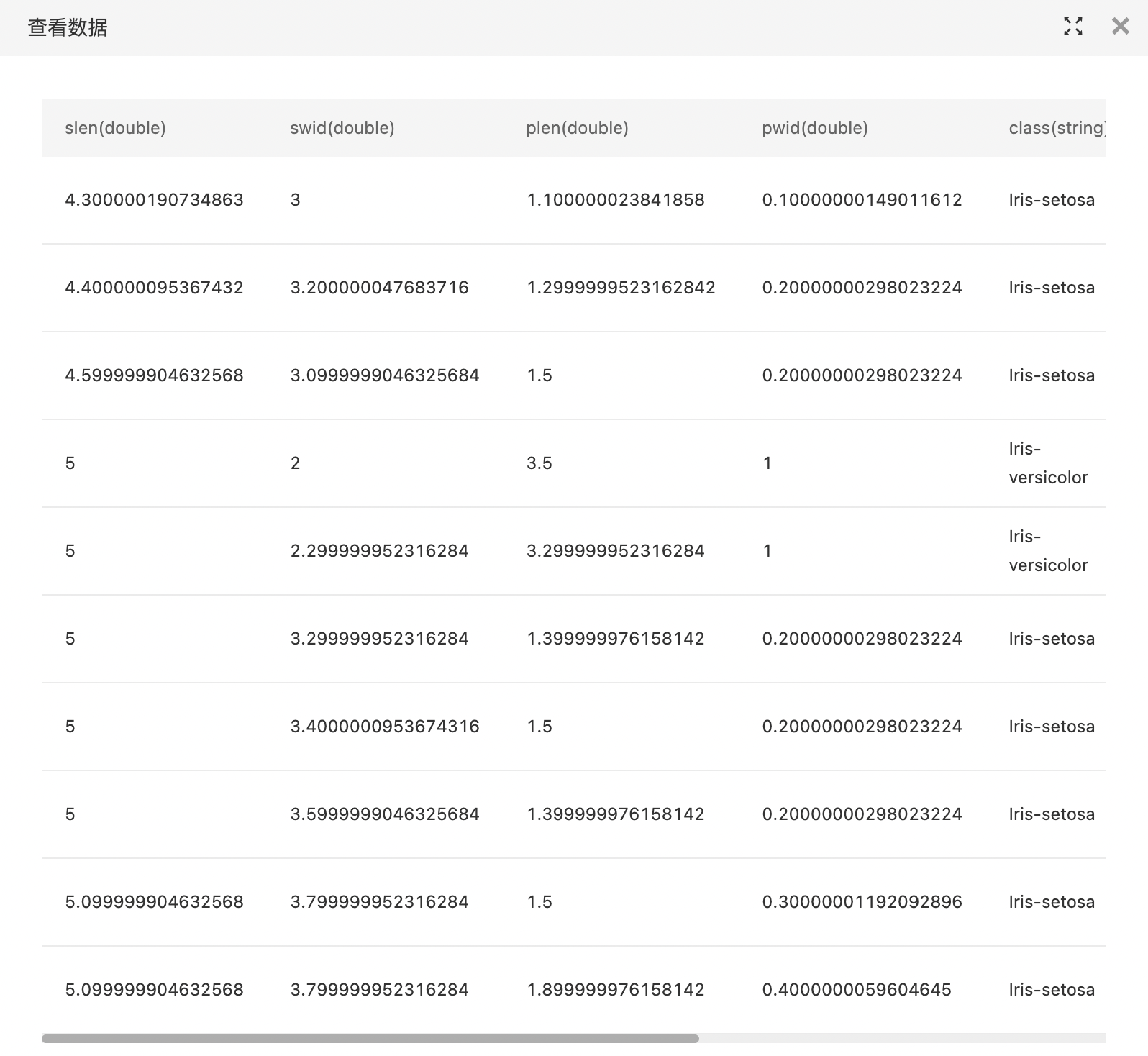
查看聚类中心。
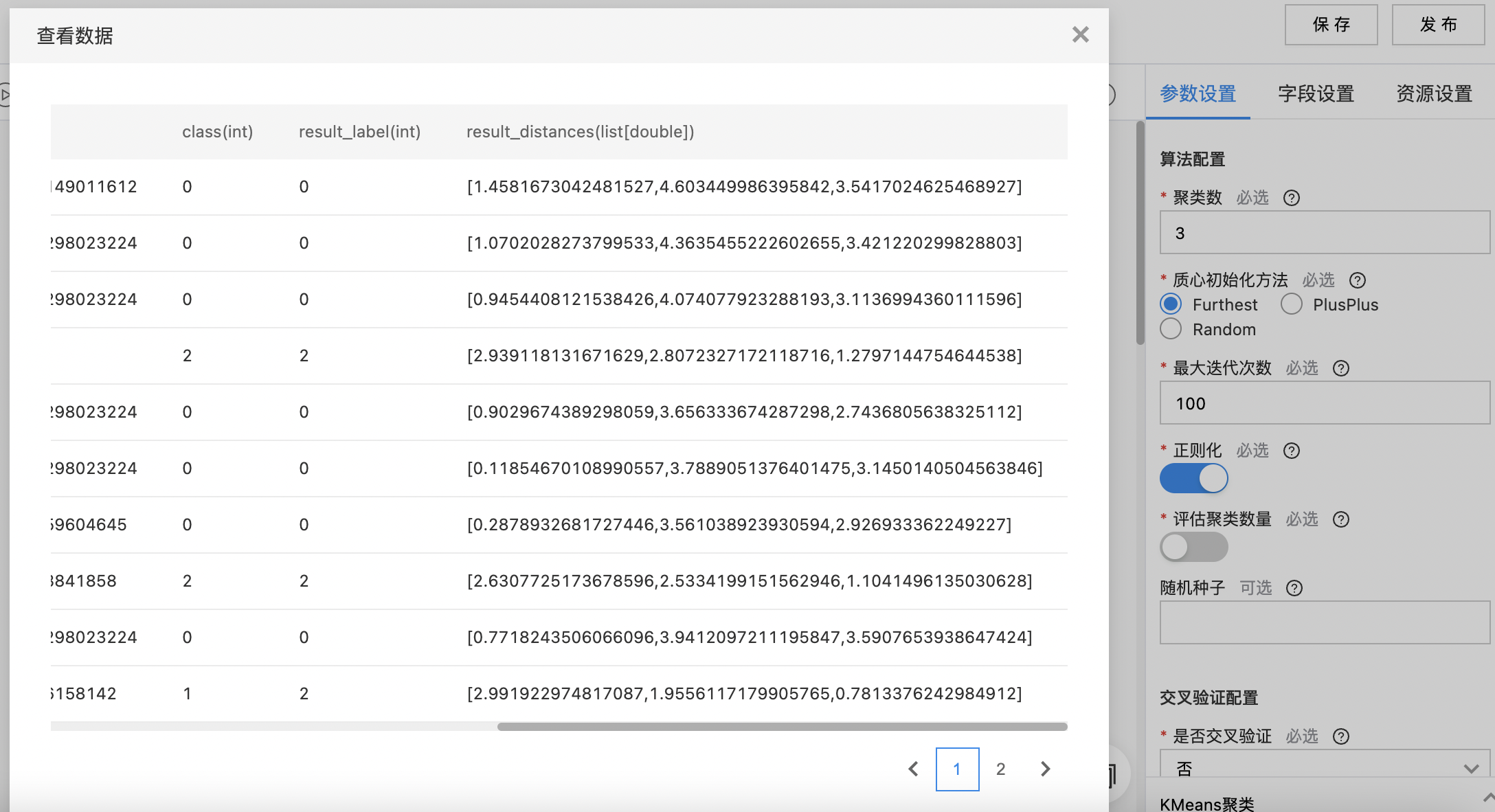
查看聚类结果。
KMeans聚类
KMeans 聚类是一种得到最广泛使用的聚类算法,把 n 个对象分为 k 个簇,使簇内具有较高的相似度。相似度根据一个簇中对象的平均值来计算。 算法首先随机地选择 k 个对象,每个对象初始地代表了一个簇的平均值或中心。对剩余的每个对象根据其与各个簇中心的距离,将它赋给最近的簇,然后重新计算每个簇的平均值。这个过程不断重复,直到准则函数收敛。 它假设对象属性来自于空间向量,并且目标是使各个群组内部的均方误差总和最小。
输入
- 输入一个数据集,选择需要聚类的特征列,支持数值或数值列表类型。
输出
- 输出KMeans聚类。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 聚类数 | 是 | 聚类数 范围:[2, 500]. | 2 |
| 质心初始化方法 | 是 |
质心初始化方法: Furthest PlusPlus Random |
Furthest |
| 最大迭代次数 | 是 | 最大迭代次数 范围:[1, 10000] | 100 |
| 正则化 | 是 | 是否进行正则化处理 | 开启 |
| 评估聚类数量 | 是 | 开启后,算法会从1到设置的聚类数依次评估合适的聚类数 | 关闭 |
| 随机种子 | 否 | 随机种子,用于保证多次训练结果相同 | 无 |
| 是否交叉验证 | 是 | 是否进行交叉验证 | 否 |
| 交叉份数 | 是 | 交叉验证的份数 范围:[2, 20] | 2 |
| 交叉验证划分方式 | 是 | 交叉验证每份的划分方式,目前支持取余划分和随机划分 | 随机划分 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 特征列 | 是 | 支持数值或数值列表类型 | 无 |
使用示例
- 构建算子结构,配置参数,完成训练。
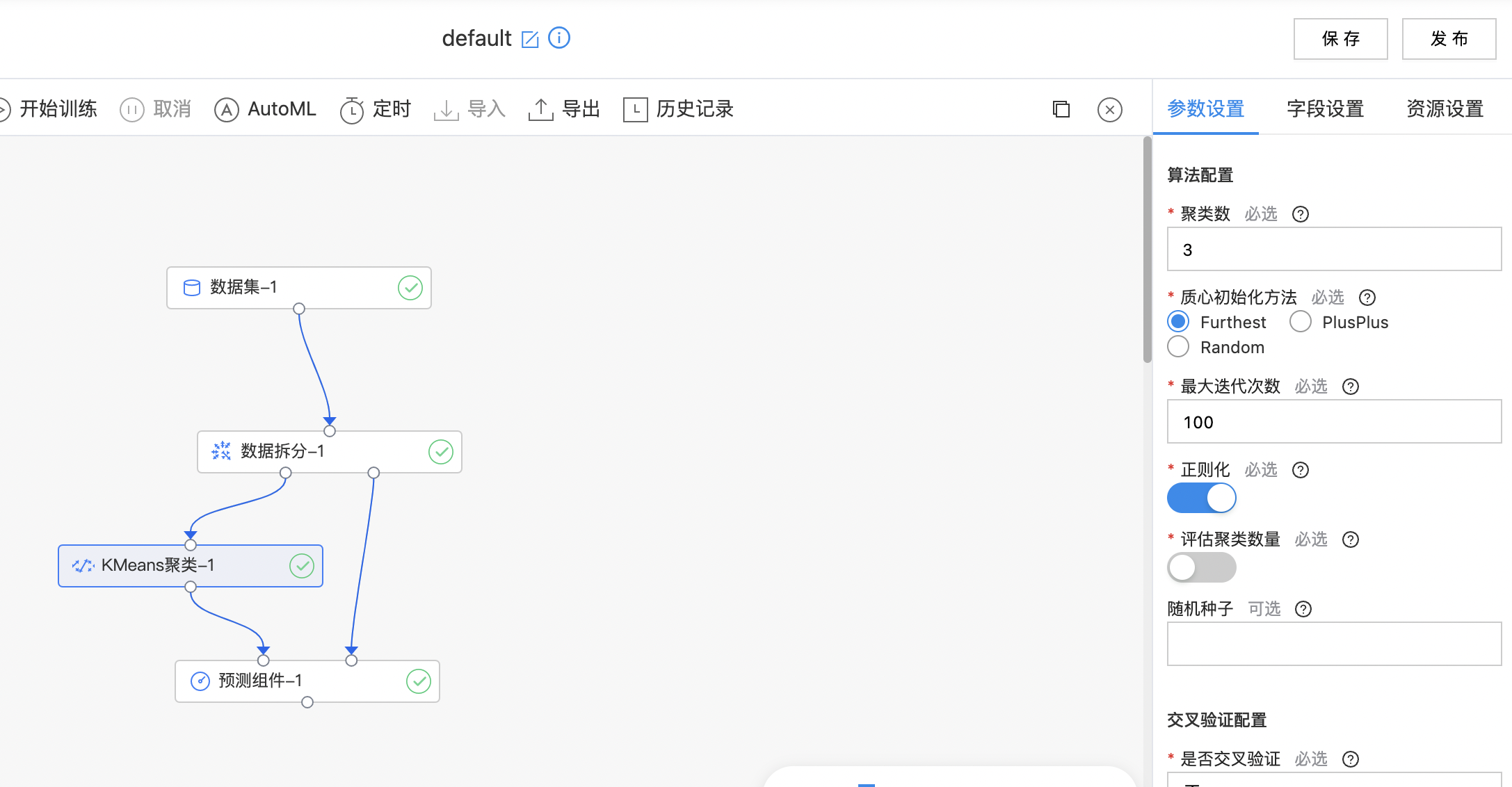
- 查看聚类结果。