文档简介:



NLP算法
Bert命名实体识别
BERT 采用了 Transformer Encoder 的模型来作为语言模型,Transformer模型完全抛弃了 RNN/CNN 等结构,而完全采用 Attention 机制来进行 input-output 之间关系的计算。 Fine-tuning 方式是指在已经训练好的语言模型的基础上,加入少量的 task-specific parameters, 例如对于分类问题在语言模型基础上加一层 softmax 网络,然后在新的语料上重新训练来进行 fine-tune。 Bert命名实体识别模型将句子输入到bert中,在bert输出后连接一个crf层得到最后结果,输入的数据格式应满足BIO的标注格式。
输入
- 输入文本数据集,标注数据常采用BIO的标注方式。
输出
- 输出Bert命名实体识别模型。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| batch_size | 是 | 训练过程中的batch_size 范围:[1, inf)。 | 4 |
| epoch | 是 | 训练过程中的训练轮数 范围:[1, inf)。 | 1 |
| do_lower_case | 是 | 输入文本是否小写, 对于中文文本应当设置为True。 | 开启 |
| 学习率 | 是 | 训练开始时的学习率 范围:[0.0, 1.0]。 | 3e-05 |
| 序列最大长度,超过(序列最大长度-1)的输入字将被截取掉 | 是 | 序列最大长度 范围:[2, inf)。 | 128 |
| warmup_proportion | 是 | 进行线性学习率预热的训练比例 范围:[0.0, 1.0]。 | 0.1 |
| save_checkpoints_steps | 是 | 保存checkpoint的频率 范围:[1, inf)。 | 1000 |
| 训练集/验证集划分比例 | 是 | 训练集合比例设置成 1 则不使用验证集。 范围:[0.01, 1.0]。 | 0.8 |
| 选择预训练模型 | 是 | 选择预训练模型 | 中文训练模型 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 文本列 | 是 | 请选择文本列,句子分字,字之间必须以空格间隔,类型为字符串。 | 无 |
| 标签列 | 是 | 请选择标签列,采用BIO格式标注方式,标签之间必须以空格间隔且个数和文本列相同,类型为字符串。 | 无 |
使用示例
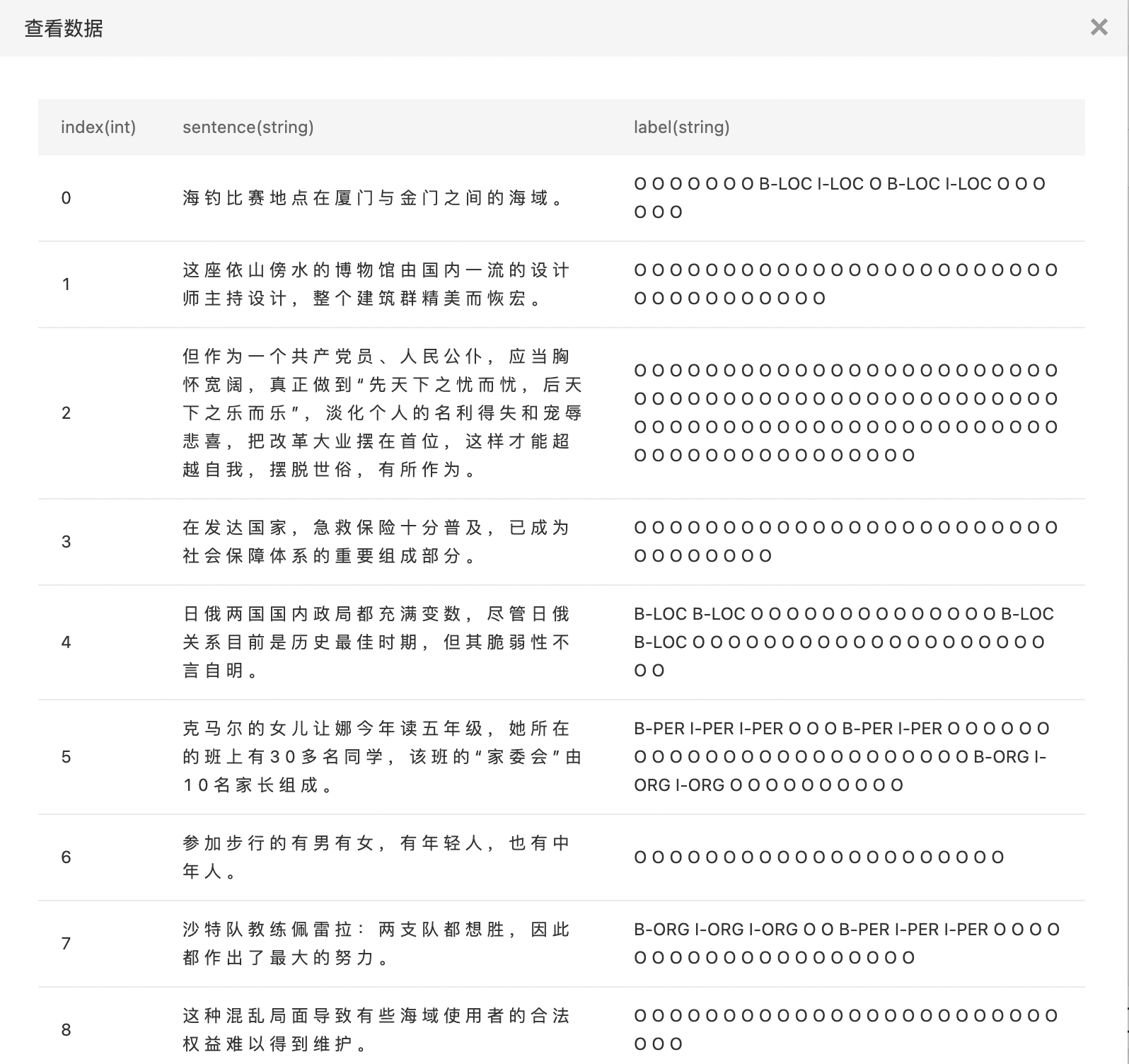
- BIO方式标注的数据。
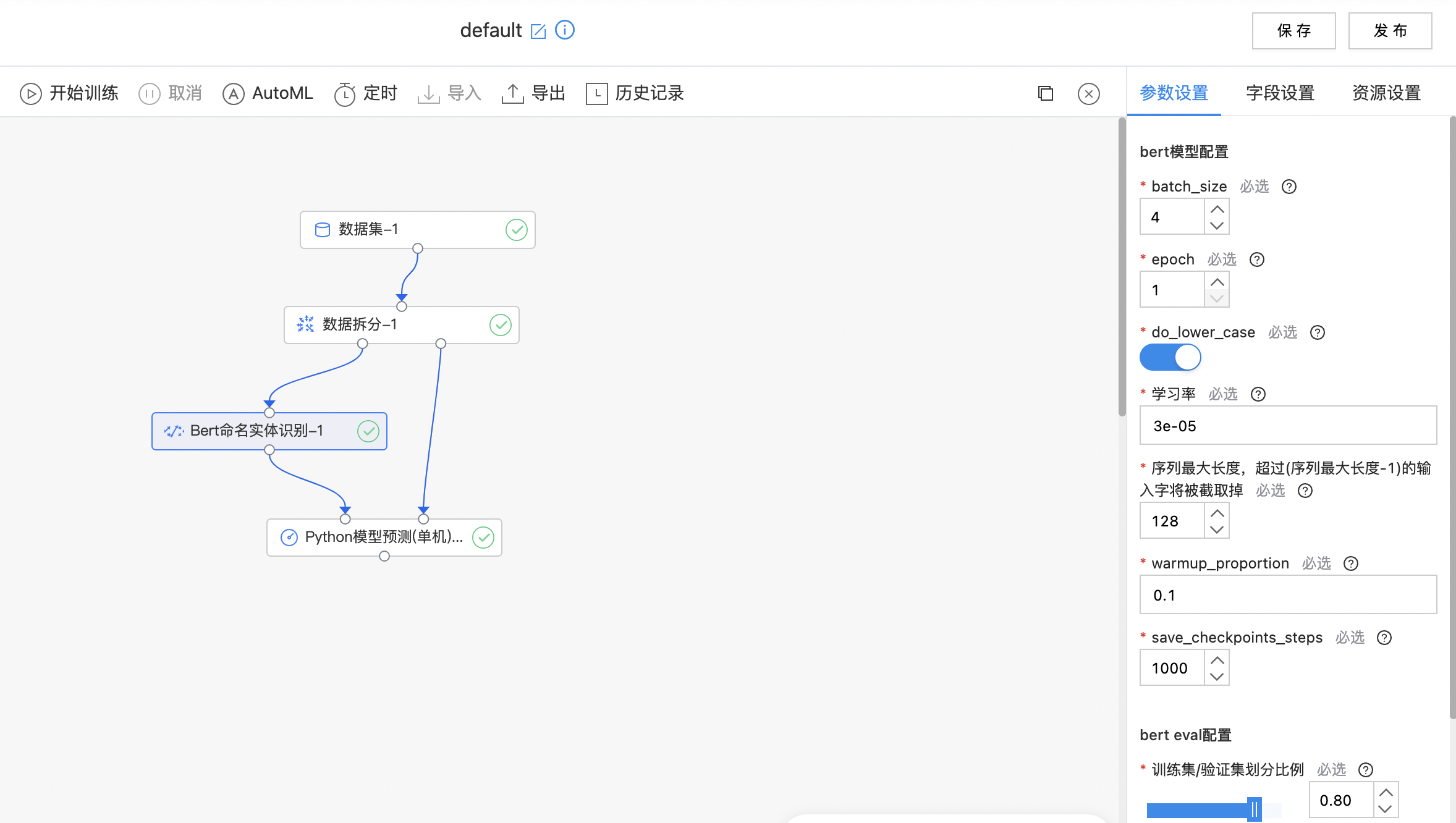
- 构件算子结构,完成训练,如果训练失败提示oom信息,请您增加内存后重新训练。
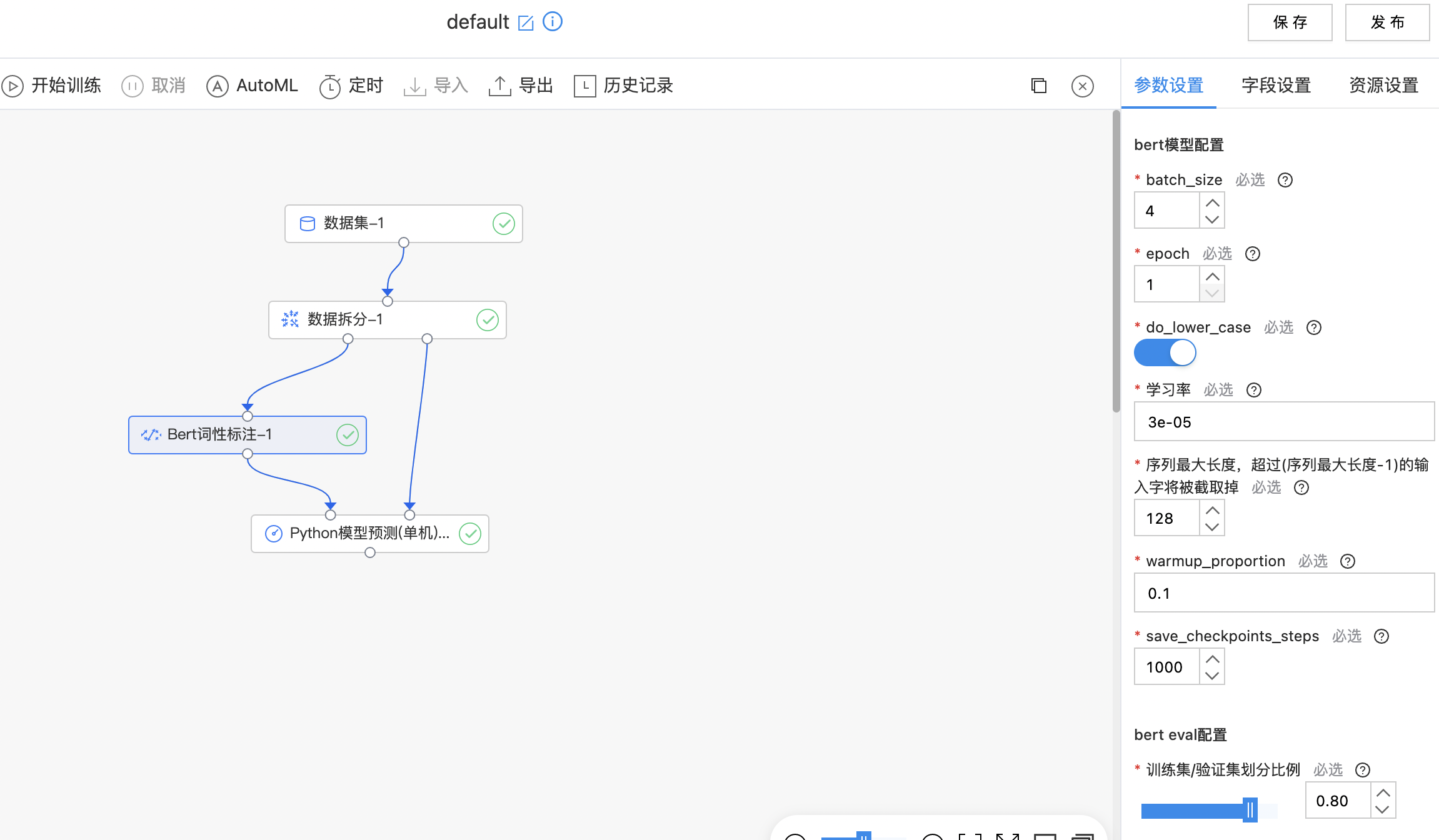
Bert词性标注
BERT 采用了 Transformer Encoder 的模型来作为语言模型,Transformer模型完全抛弃了 RNN/CNN 等结构,而完全采用 Attention 机制来进行 input-output 之间关系的计算。 Fine-tuning 方式是指在已经训练好的语言模型的基础上,加入少量的 task-specific parameters, 例如对于分类问题在语言模型基础上加一层 softmax 网络,然后在新的语料上重新训练来进行 fine-tune。 Bert词性标注模型为:BERT + CRF,输入的数据格式应满足BIO的标注格式。
输入
- 输入文本数据集,标注数据常采用BIO的标注方式。
输出
- 输出Bert词性标注模型。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| batch_size | 是 | 训练过程中的batch_size 范围:[1, inf)。 | 4 |
| epoch | 是 | 训练过程中的训练轮数 范围:[1, inf)。 | 1 |
| do_lower_case | 是 | 输入文本是否小写, 对于中文文本应当设置为True。 | 开启 |
| 学习率 | 是 | 训练开始时的学习率 范围:[0.0, 1.0]。 | 3e-05 |
| 序列最大长度,超过(序列最大长度-1)的输入字将被截取掉 | 是 | 序列最大长度 范围:[2, inf)。 | 128 |
| warmup_proportion | 是 | 进行线性学习率预热的训练比例 范围:[0.0, 1.0]。 | 0.1 |
| save_checkpoints_steps | 是 | 保存checkpoint的频率 范围:[1, inf)。 | 1000 |
| 训练集/验证集划分比例 | 是 | 训练集合比例设置成 1 则不使用验证集。 范围:[0.01, 1.0]。 | 0.8 |
| 选择预训练模型 | 是 | 选择预训练模型 | 中文训练模型 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 文本列 | 是 | 请选择文本列,句子分字,字之间必须以空格间隔,类型为字符串。 | 无 |
| 标签列 | 是 | 请选择标签列,采用BIO格式标注方式,标签之间必须以空格间隔且个数和文本列相同,类型为字符串。 | 无 |
使用示例
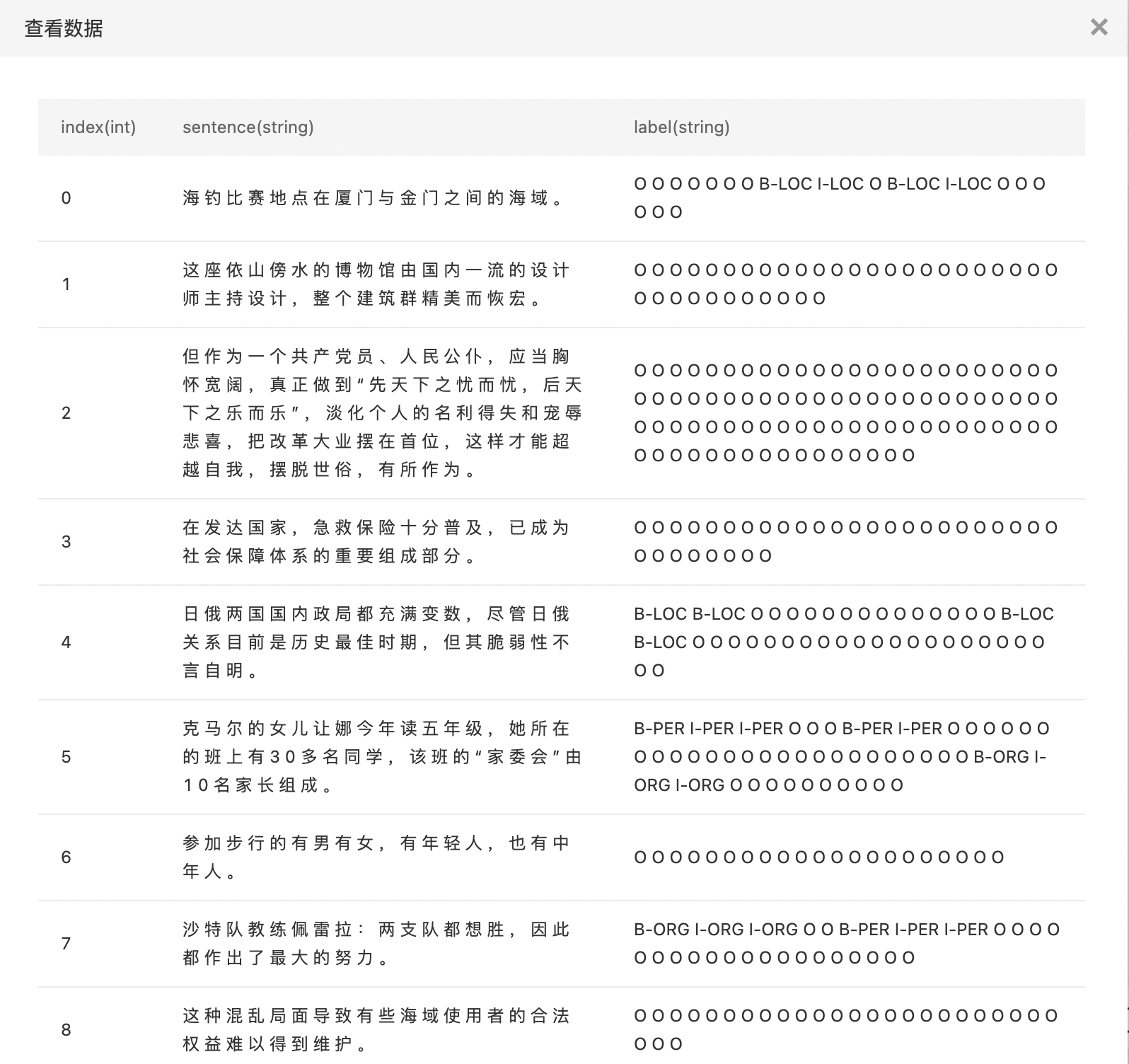
- BIO方式标注的数据。
- 构件算子结构,完成训练,如果训练失败提示oom信息,请您增加内存后重新训练。
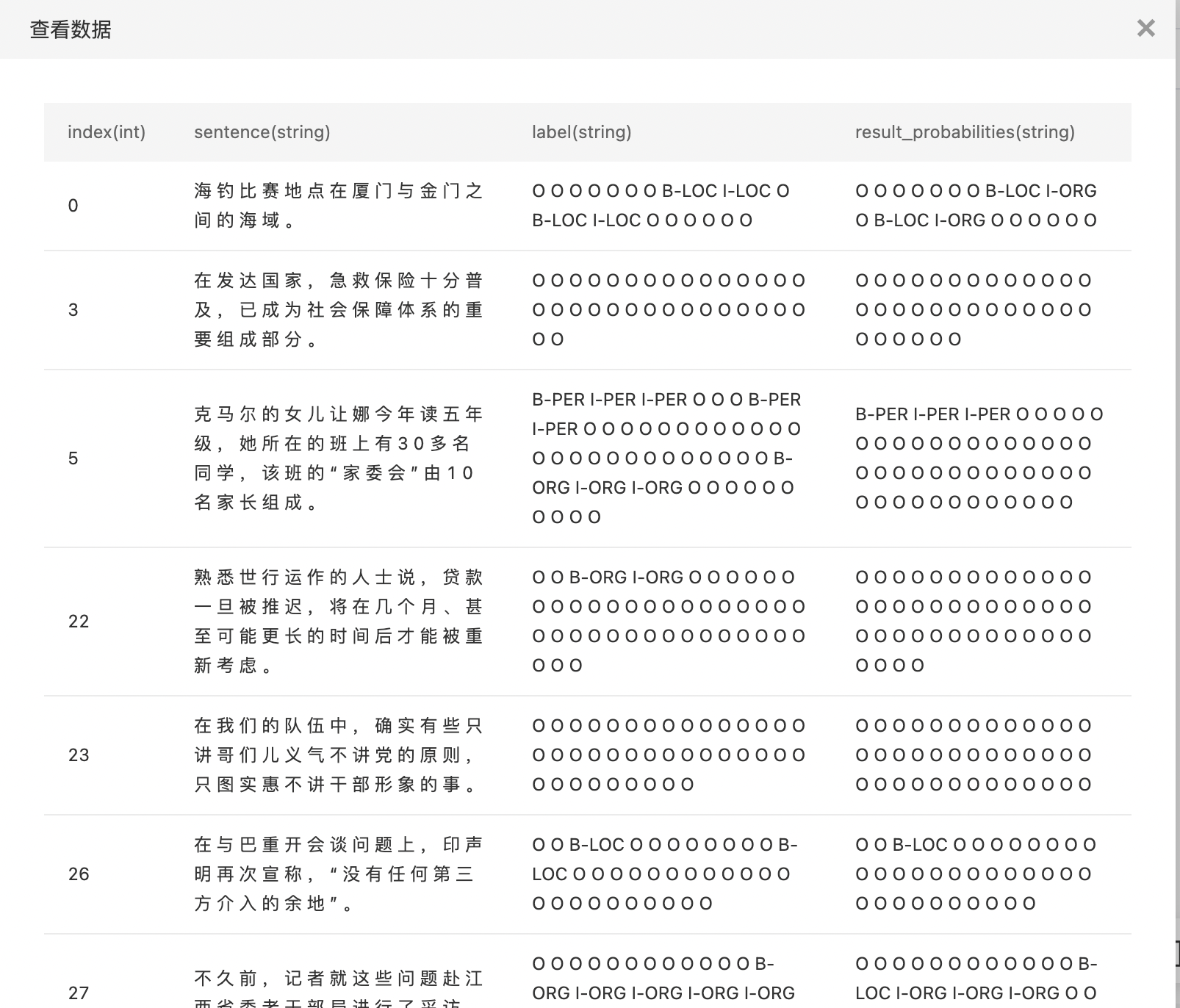
- 查看预测结果。
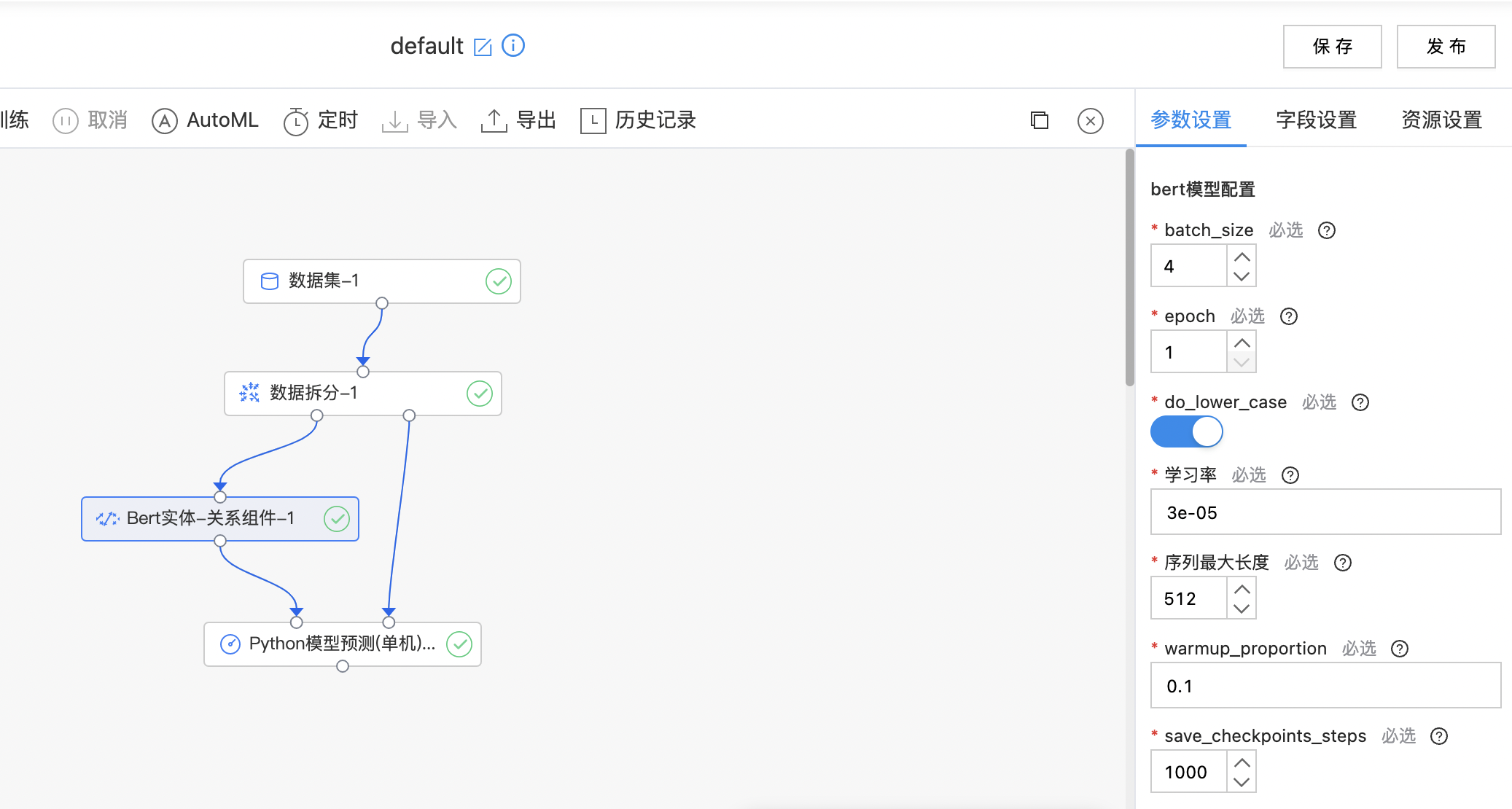
Bert实体-关系组件
BERT 采用了 Transformer Encoder 的模型来作为语言模型,Transformer模型完全抛弃了 RNN/CNN 等结构,而完全采用 Attention 机制来进行 input-output 之间关系的计算。 Fine-tuning 方式是指在已经训练好的语言模型的基础上,加入少量的 task-specific parameters, 例如对于分类问题在语言模型基础上加一层 softmax 网络,然后在新的语料上重新训练来进行 fine-tune。 Bert实体-关系模型:BERT + Fine-tuning。
输入
- 输入数据集,特征列按顺序选择两列实体与一列文本(类型为字符串类型)。
输出
- 输出Bert实体-关系组件模型。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| batch_size | 是 | 训练过程中的batch_size 范围:[1, inf)。 | 4 |
| epoch | 是 | 训练过程中的训练轮数 范围:[1, inf)。 | 1 |
| do_lower_case | 是 | 输入文本是否小写, 对于中文文本应当设置为True。 | 开启 |
| 学习率 | 是 | 训练开始时的学习率 范围:[0.0, 1.0]。 | 3e-05 |
| 序列最大长度 | 是 | 序列最大长度 范围:[2, inf)。 | 128 |
| warmup_proportion | 是 | 进行线性学习率预热的训练比例 范围:[0.0, 1.0]。 | 0.1 |
| save_checkpoints_steps | 是 | 保存checkpoint的频率 范围:[1, inf)。 | 1000 |
| 训练集/验证集划分比例 | 是 | 训练集合比例设置成 1 则不使用验证集。 范围:[0.01, 1.0]。 | 0.8 |
| 选择预训练模型 | 是 | 选择预训练模型 | 中文训练模型 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 文本列 | 是 | 按顺序选择两列实体与一列文本(类型为字符串类型)。 | 无 |
| 标签列 | 是 | 选择一列标签列。 | 无 |
使用示例
构建算子结构,配置参数,完成训练。
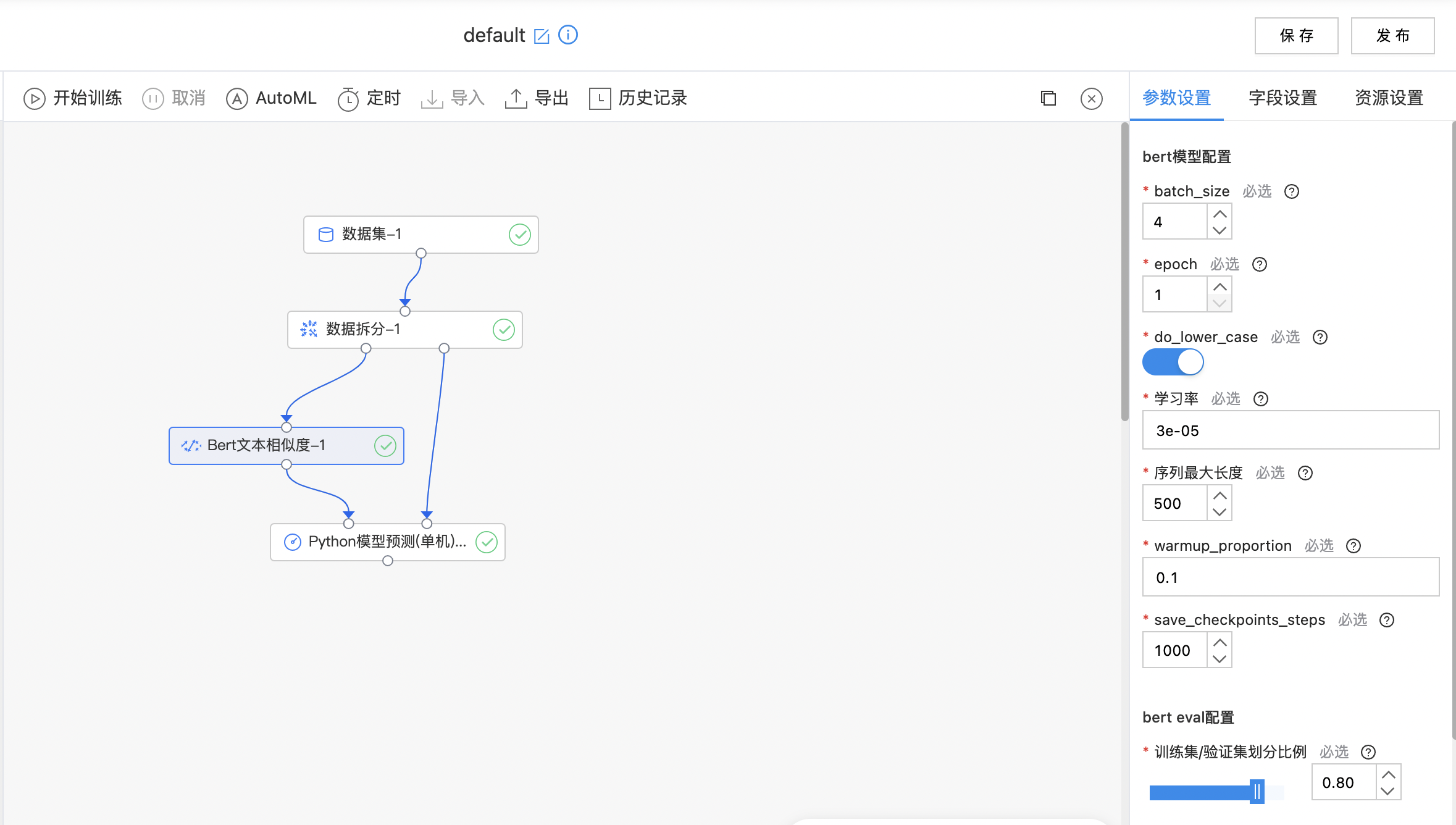
Bert文本相似度
BERT 采用了 Transformer Encoder 的模型来作为语言模型,Transformer模型完全抛弃了 RNN/CNN 等结构,而完全采用 Attention 机制来进行 input-output 之间关系的计算。 Fine-tuning 方式是指在已经训练好的语言模型的基础上,加入少量的 task-specific parameters, 例如对于分类问题在语言模型基础上加一层 softmax 网络,然后在新的语料上重新训练来进行 fine-tune。 Bert 文本相似度模型:BERT + Fine-tuning。
输入
- 输入数据集,特征列为两列文本列(类型为字符串类型),标签列为一列文本列(类型为整型)。
输出
- 输出Bert文本相似度模型。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| batch_size | 是 | 训练过程中的batch_size 范围:[1, inf)。 | 4 |
| epoch | 是 | 训练过程中的训练轮数 范围:[1, inf)。 | 1 |
| do_lower_case | 是 | 输入文本是否小写, 对于中文文本应当设置为True。 | 开启 |
| 学习率 | 是 | 训练开始时的学习率 范围:[0.0, 1.0]。 | 3e-05 |
| 序列最大长度 | 是 | 序列最大长度 范围:[2, inf)。 | 128 |
| warmup_proportion | 是 | 进行线性学习率预热的训练比例 范围:[0.0, 1.0]。 | 0.1 |
| save_checkpoints_steps | 是 | 保存checkpoint的频率 范围:[1, inf)。 | 1000 |
| 训练集/验证集划分比例 | 是 | 训练集合比例设置成 1 则不使用验证集。 范围:[0.01, 1.0]。 | 0.8 |
| 选择预训练模型 | 是 | 选择预训练模型。 | 中文训练模型 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 文本列 | 是 | 选择两列文本列(类型为字符串类型) | 无 |
| 标签列 | 是 | 选择一列文本列(类型为整型) | 无 |
使用示例
构建算子结构,配置参数,完成训练。
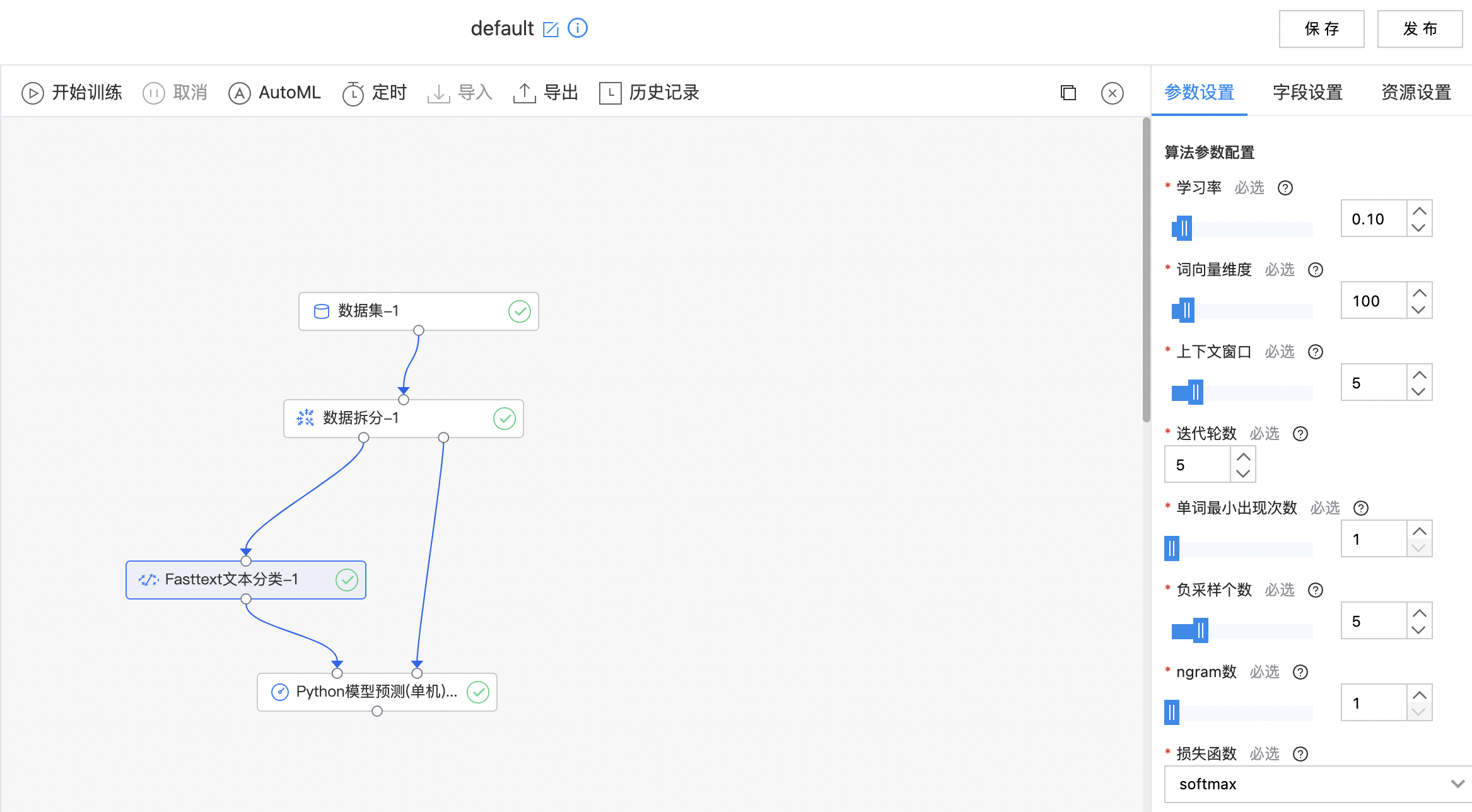
Fasttext文本分类
Fasttext 是一种简单有效的句子分类算法, 通过词向量以及 n-gram 向量的平均值计算出句子的向量表示,再通过全连接层网络对句子进行分类。
输入
- 输入一个数据集,特征列需要是字符串列表或字符串类型(如果是字符串类型,假设字符串已经经过了分词,以空格或tab分割),标签列需要是枚举类型。
输出
- 输出Fasttext模型,可以使用python预测组件进行预测。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 学习率 | 是 | 学习率 范围:[0.01, 1.0]。 | 0.10 |
| 词向量维度 | 是 | 词向量维度 范围:[50, 500]。 | 100 |
| 上下文窗口 | 是 | 训练词向量考虑的上下文窗口大小 范围:[3, 15]。 | 5 |
| 迭代轮数 | 是 | 算法运行的 epoch 数,迭代几轮训练集 范围:[1, 100]。 | 5 |
| 单词最小出现次数 | 是 | 小于该数值的单词记为OOV 范围:[1, 10]。 | 1 |
| 负采样个数 | 是 | 负采样个数 范围:[1, 20]。 | 5 |
| ngarm数 | 是 | ngram数 范围:[1, 5]。 | 1 |
| 损失函数 | 是 |
损失函数,目前支持: softmax hs ns ova |
softmax |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 输入列 | 是 | 必须是字符串列表或字符串类型。如果是字符串类型,需要提前以空格或tab分词。 | 无 |
| 标签列 | 是 | 需要是枚举类型。 | 无 |
使用示例
构建算子结构,配置参数,完成训练。
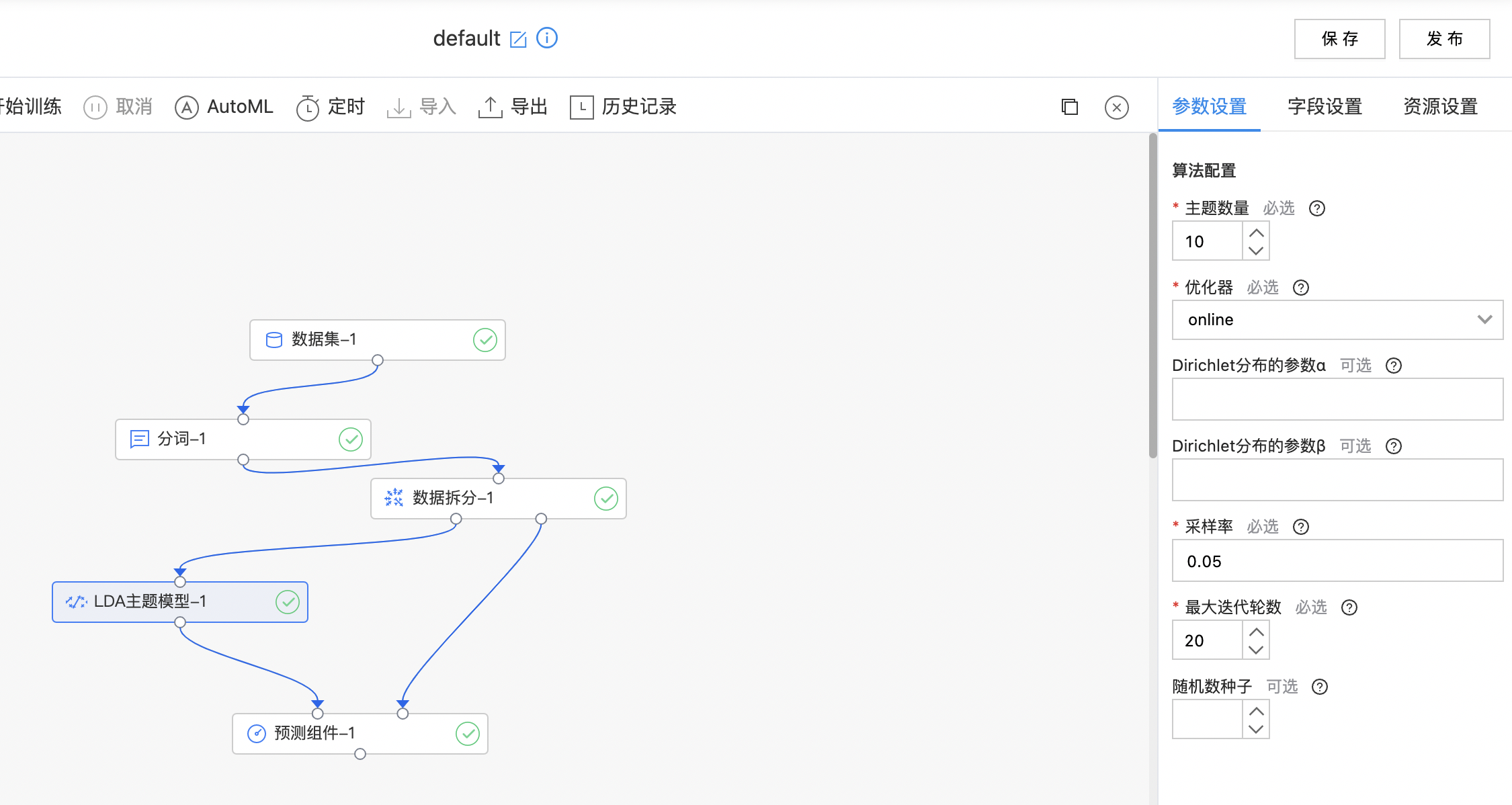
LDA主题模型
LDA 在主题模型中占有非常重要的地位,常用来文本分类,它可以将文档集中每篇文档的主题以概率分布的形式给出,从而通过分析一些文档抽取出它们的主题分布后,便可以根据主题分布进行主题聚类或文本分类。
输入
- 输入一个数据集,输入列为字符串数组类型(既经过分词后的数据)。
输出
- 输出LDA主题模型。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 主题数量 | 是 | 主题数量(聚簇中心数量) 范围:[2, inf)。 | 10 |
| 优化器 | 是 |
优化器用来学习LDA模型,当前支持: online:Online Variational Bayes和em:Expectation-Maximization |
online |
| Dirichlet分布的参数α | 否 | 文档在主题上分布的先验参数(超参数α),值越大推断出得分布越平滑 范围:[1.000000000000001, inf)。 | 无 |
| Dirichlet分布的参数β | 否 | 主题在单词上的先验分布参数,值越大推断出得分布越平滑 范围:[1.000000000000001, inf)。 | 无 |
| 采样率 | 是 | 小批量梯度下降的每次迭代中要采样和使用的语料的比例 范围:[1.0E-15, 1.0]。 | 0.05 |
| 最大迭代轮数 | 是 | 当迭代次数大于该数值时,停止迭代 范围:[1, inf)。 | 20 |
| 随机种子 | 否 | 随机数种子。 | 无 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 输入列 | 是 | 需要做LDA的列,类型需要是字符串数组。 | 无 |
使用示例
构建算子结构,配置参数,完成训练。