

文档简介:



在深度学习建模过程中,除了大规模的数据集,超参数调节也显著影响模型效果。即使对于有经验的算法工程师,有时候也很难把握调节超参数的规律,而对于初学者来说,要花更多的时间和精力。
自动超参搜索应用超参搜索策略,对模型的超参数进行自动调优,在配置训练任务的页面,完成数据集的配置后,可以选择使用自动超参搜索进行配置。
您可以选择「随机搜索」,「贝叶斯搜索」,「进化算法」作为搜索策略进行超参搜索,所有默认值都是基于试验得出的效果较好的取值。 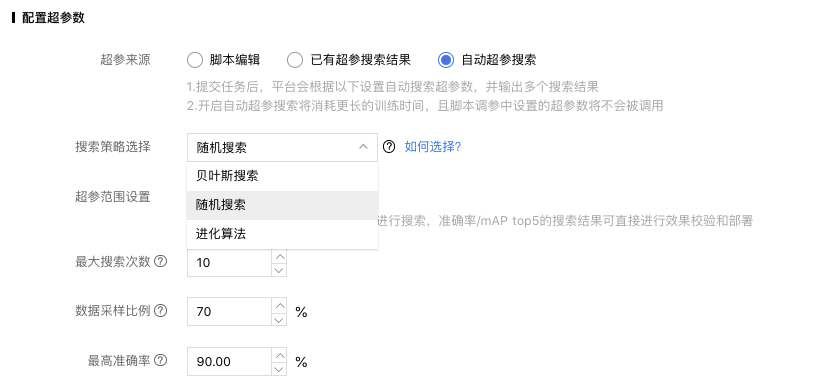
随机搜索
作为基线标准,不需要更多额外的设置,就能高效地进行超参数搜索。
贝叶斯搜索
贝叶斯搜索中,您需要设置初始点数量和最大并发量.
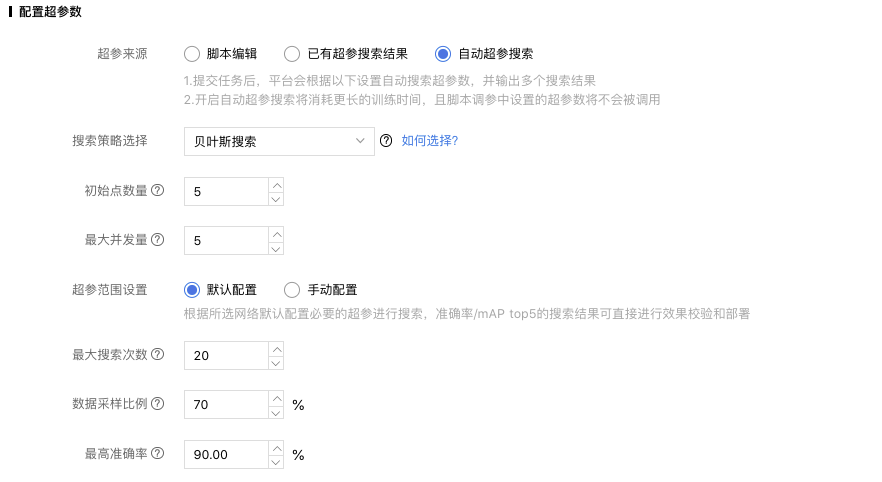
「初始点数量」:代表贝叶斯搜索中,初始化时参数点的数量,该算法基于这些参数信息推测最优点 ,填写范围1-20;
「最大并发量」:贝叶斯搜索中,同时进行试验的数量,并发量越大,搜索效率越高,填写范围1-20。
进化算法
进化算法是一种效果较好的算法,应用此算法时也需要进行较多的选项设置
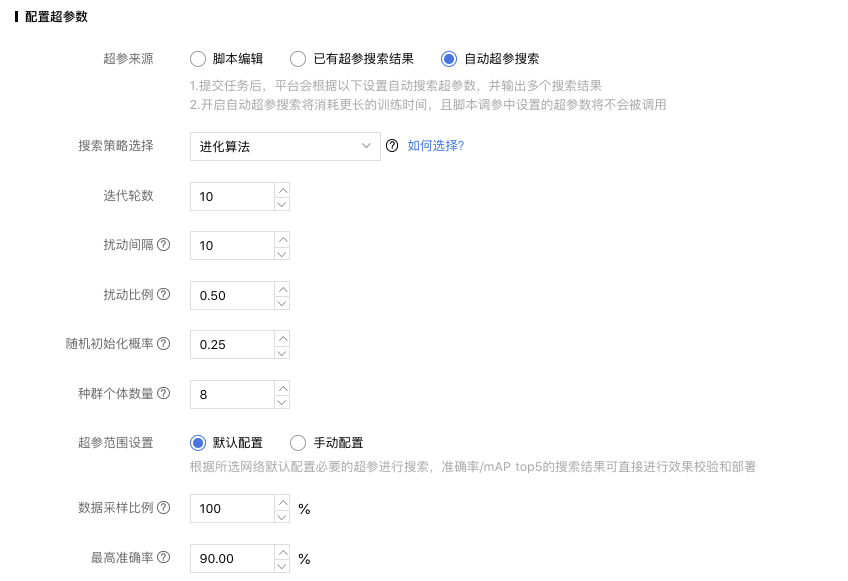
「迭代轮数」:进化算法运行中迭代的轮数,范围5-50;
「扰动间隔」:进化算法每隔几个epoch就会进行随机扰动,利用随机因素防止算法结果收敛于局部最优解;
「扰动比例」:类似于染色体交叉的形式,迭代中一个种群内最好与最坏的个体依据扰动比例进行交叉;
「随机初始化概率」:在扰动中,有一定概率对个体的超参数进行初始化;
「种群个体数量」:一个个体代表一种超参数设置,一个种群中包含多个个体。
超参范围设置
超参范围设置中,可以设置需要搜索的超参数和搜索范围。您可以在「默认配置」,「手动配置」中进行选择。
默认配置
如果您不行进行超参数选择和范围设置,可以选用默认配置,后台会根据所选网络默认配置必要的超参数进行搜索。
手动配置
针对不同的预训练网络,我们提供了丰富的超参数供开发者手动配置,每一个超参数都能选择数据类型和设置搜索范围。 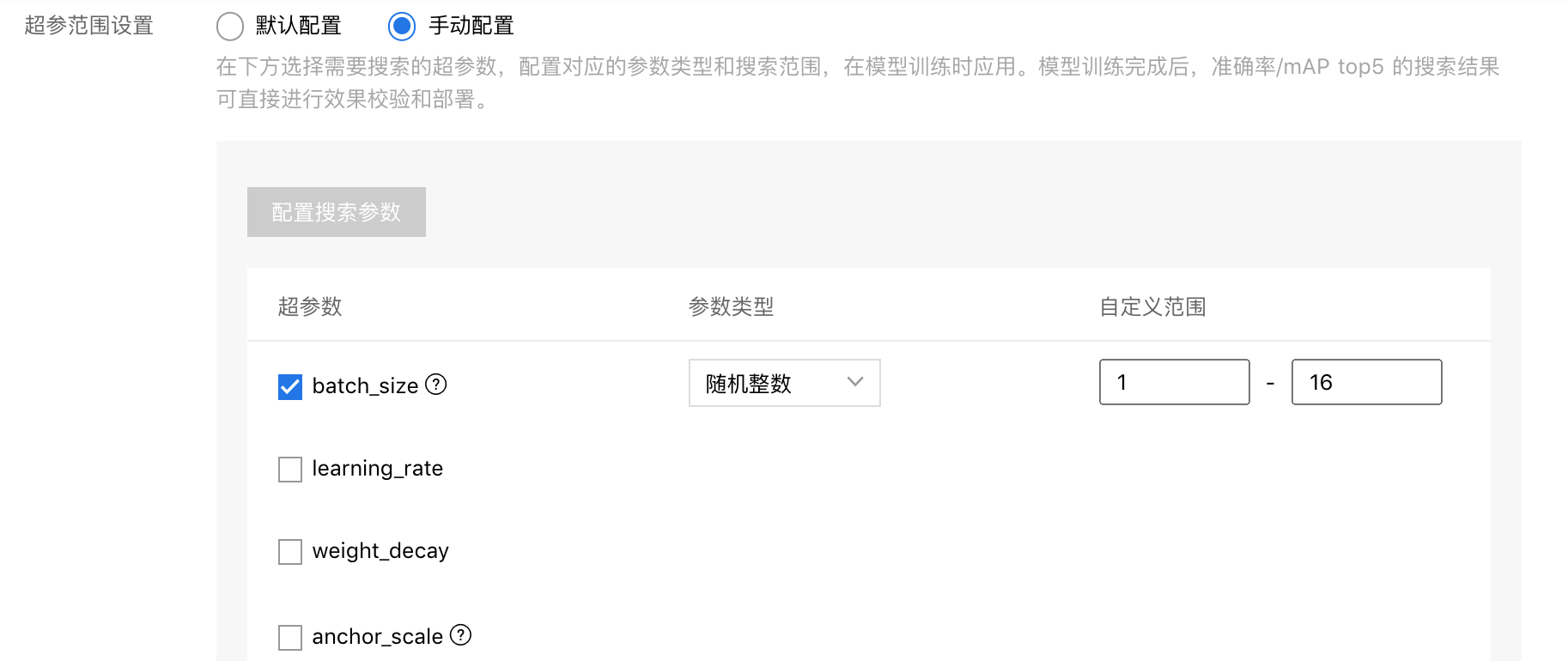
详细超参数列表请见下面超参数列表
搜索超参数列表
| 超参数 | 参数类型 | 说明 |
|---|---|---|
| batch_size | 离散值、随机整数 | 每一个批次处理的数据数量,需根据网络不同机型和网络调整最大值,否则可能因显存不足导致失败 |
| learning_rate | 离散值、平均采样、对数平均采样 | 控制深度学习网络的学习速度,学习率越低,损失函数的变化速度就越慢,反之亦然 |
| weight_decay | 离散值、平均采样、对数平均采样 | 对深度学习网络进行权重衰减,防止网络出现过拟合情况 |
| mix_up | 布尔值 | 选择是否使用mix_up策略,mix_up是一种数据增广方式 |
| label_smoothing | 布尔值 | 选择是否使用label_smoothing策略,label_smoothing是一种正则化方法 |
| anchor_scale | 离散值,随机整数 | anchor大小的缩放尺度,anchor是一组预设的参考框 |
| anchor_ratio | 离散值,随机整数 | anchor的长宽比,anchor是一组预设的参考框 |
通用配置项
『最大搜索次数』:是指最多组合出多少组超参并跑试验,当然有可能会因为提前达到目标而停止,节约费用。
『数据采样比例』:使用超参搜索时,会对原始数据集进行采样后再训练,加快搜索速度。当数据集并不大时,不推荐采样哟,可能会影响最终效果,只有大数据量时才有使用采样的必要。
『最高mAP/最高准确率』:是指大家期望模型效果可以达到的mAP(物体检测)或准确率(图像分类)的值,当试验中达到这个值了搜索就会停止,避免后续浪费搜索时间。
