




目录
1.物体检测简介
2.平台入口
3.准备数据
3.1 道路交通电子眼检测数据介绍
3.2 创建及导入数据集
4.训练模型
5.模型分析和调优
6.部署模型
7.公有云调用
7.1 使用流程
用BML实现物体检测:以道路交通电子眼检测为例
物体检测简介
亲爱的开发者您好,欢迎使用百度BML全功能AI开发平台开启您的AI开发之旅!
物体检测任务是当前深度学习应用最广的计算机视觉应用任务,主要是检测图中每个物体的位置、名称。适合图中有多个主体要识别、或要识别主体位置及数量。其主要应用场景有:
- 视频监控:如检测是否有违规物体、行为出现。
- 工业质检:如检测图片里微小瑕疵的数量和位置。
- 医疗诊断:如医疗细胞计数、中草药识别等。
下文中将以道路交通电子眼检测任务为例,分步骤向您详细介绍如何使用百度BML全功能AI开发平台开发您自己的物体检测模型。
道路交通电子眼检测任务简介:
在实时地图导航场景下,对于不同种类的交通电子提示装置的实时提醒,在规范车主驾驶行为、保障用户出行等方面至关重要。而各类电子提示装置分布于道路大街小巷,这类物体普通目标小,不易发现,通过常规的数据采集和人力手段很难识别,为实现导航规划增加了额外成本。对以电子眼为代表的道路交通要素进行检测,有着较大的价值。
平台入口
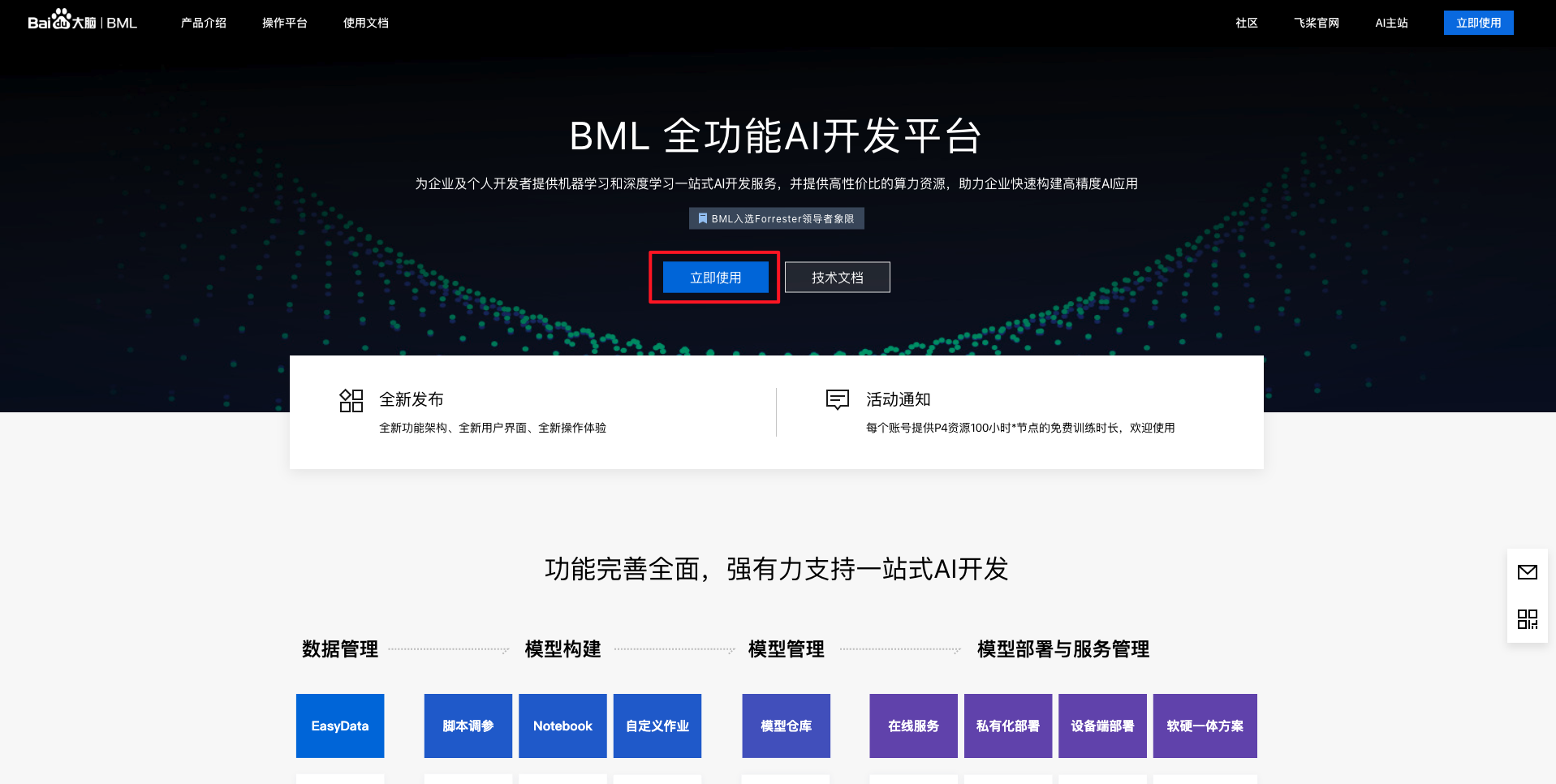
BML全功能AI开发平台为企业及个人开发者提供机器学习和深度学习一站式AI开发服务,并提供高性价比的算力资源,助力企业快速构建高精度AI应用,进入官方网站点击【立即使用】。
准备数据
准备数据是AI模型开发的关键一环,训练数据的质量决定了训练所得模型效果可达到的上限,下面来介绍数据规范与相关操作步骤。
道路交通电子眼检测数据介绍
道路交通电子眼检测数据集来自于百度与曙光合作的『先导杯·计算应用大奖赛』的比赛数据,采集自百度地图的实际业务数据。训练集包括近2W样本,其中包含三类目标:rect_eye、sphere_eye、box_eye。
导入平台即可使用,数据下载链接:道路交通电子眼检测数据-json格式
创建及导入数据集
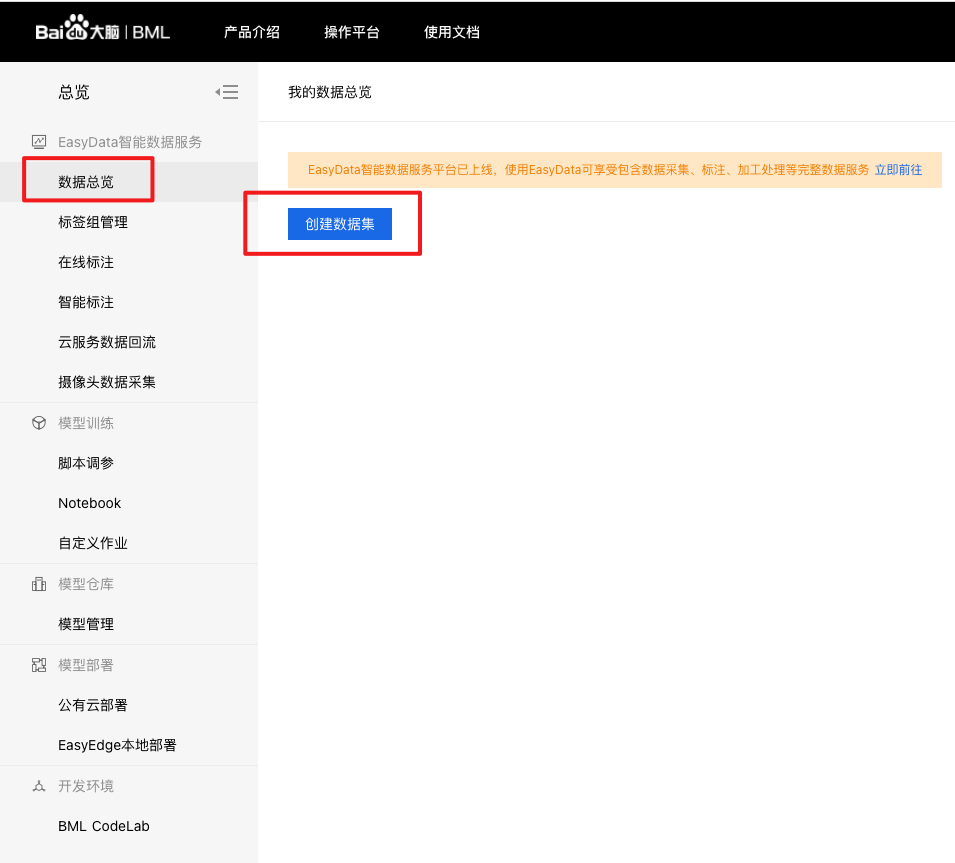
1、在官网界面点击【数据总览】,进入数据集操作界面,点击【创建数据集】。
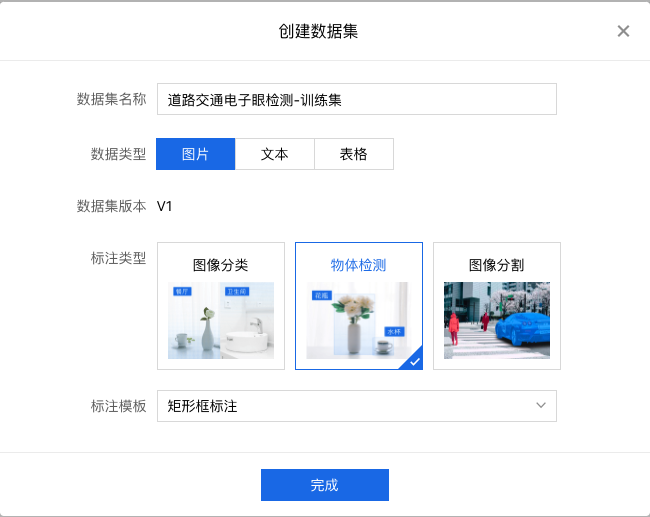
2、进入创建数据集界面,填写相关信息,选择数据和标注类型(注意训练集、验证集、测试集需要分开创建)。
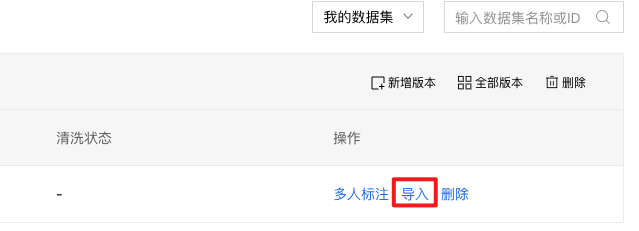
3、数据集创建完成后,可以在数据总览界面看到刚才创建好的数据集ID,点击【导入】,将自己要训练的数据集导入。
以本地导入-上传压缩包为例:导入方式选择【本地导入】,选择标注格式,点击【上传压缩包】。
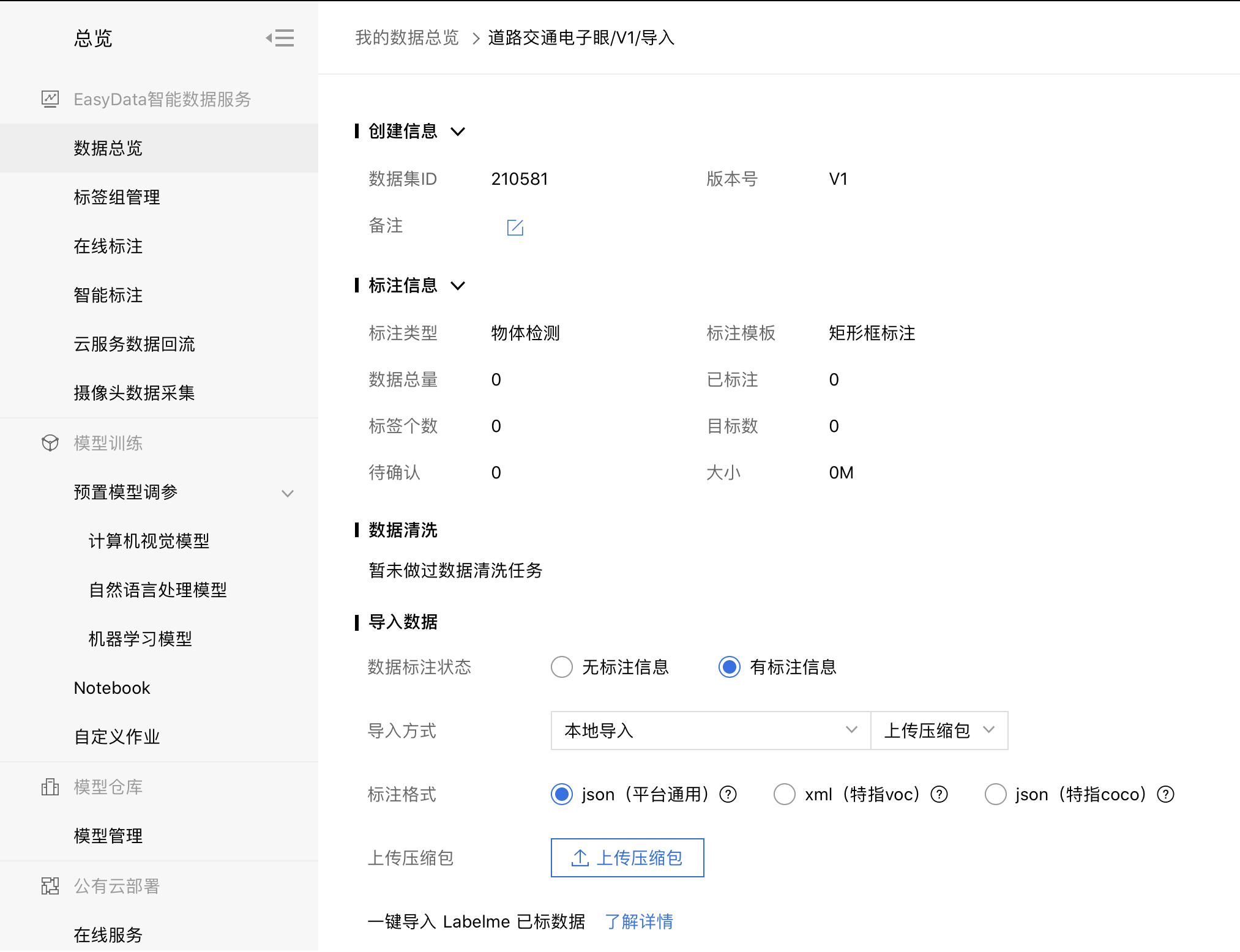
仔细阅读上传压缩包格式要求,可点击【下载示例压缩包】确认格式:
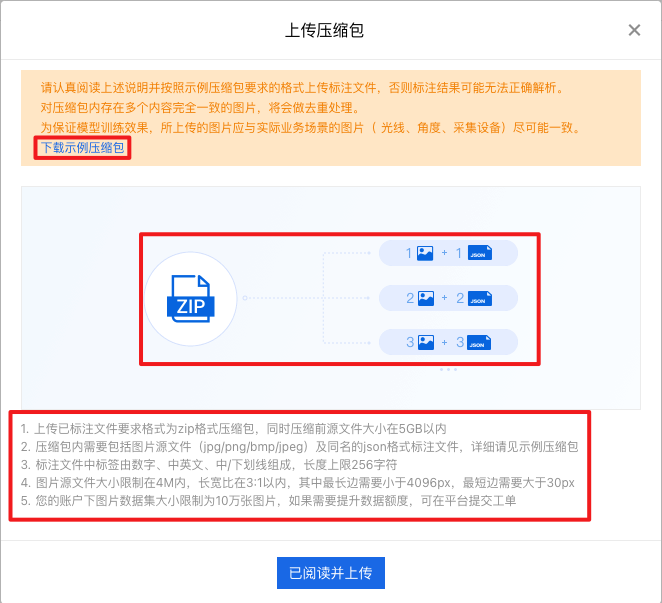
确认格式无误后,点击【已阅读并上传】, 注意上传时不要关闭网页:

点击【确认并返回】后自动开始导入:
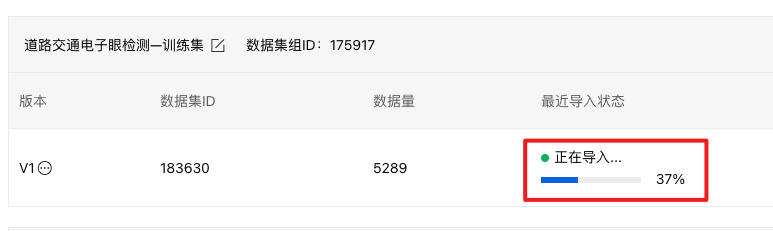
可看到【标注状态】为100%,如果数据集没有全部标注,可使用平台【智能标注】功能。
训练模型
BML上提供了预置模型调参、NoteBook建模、自定义作业三种开发模式,开发难度和开发的灵活性程度不一,分别满足不同水平和需求的开发者。
本文以使用者最多的预置模型调参开发模式为例,示意训练模型的基本步骤。
1、进入bml官方平台点击【预置模型调参】-【计算机视觉模型】,点击【创建】。
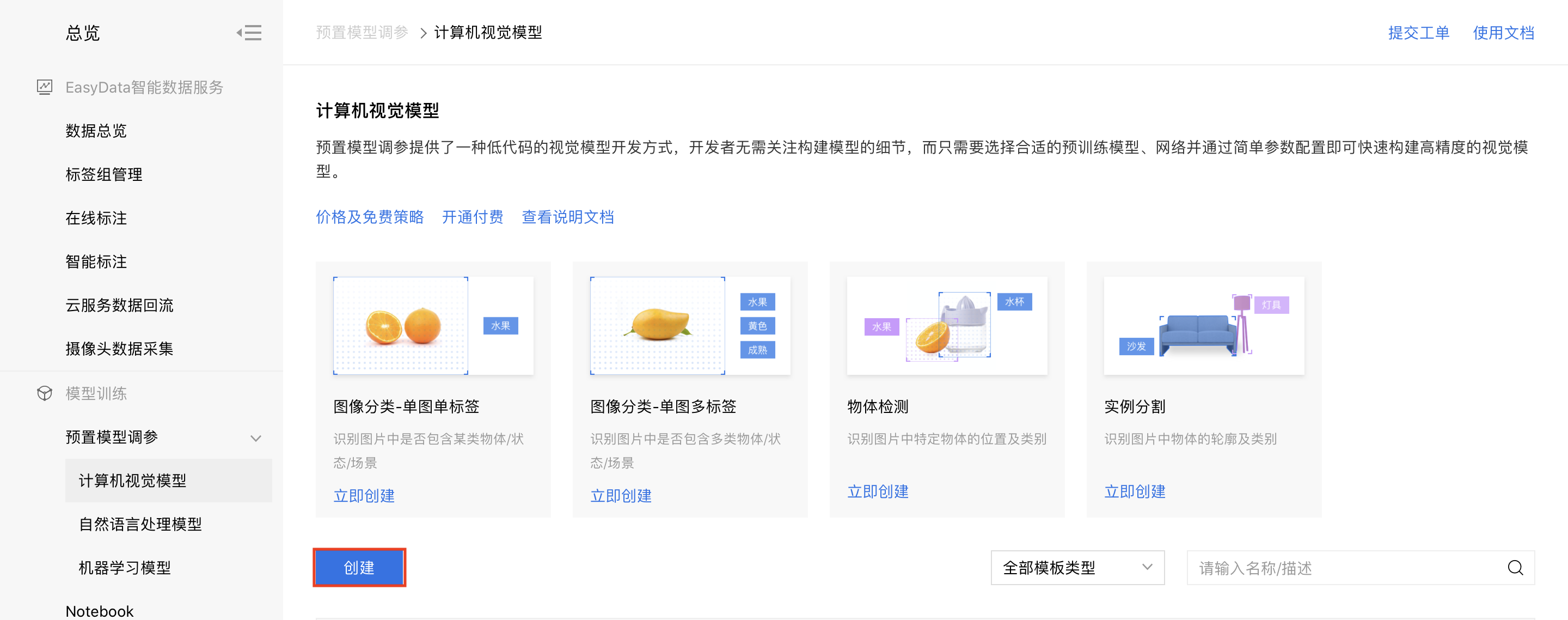
2、填写项目信息并点击【新建】。
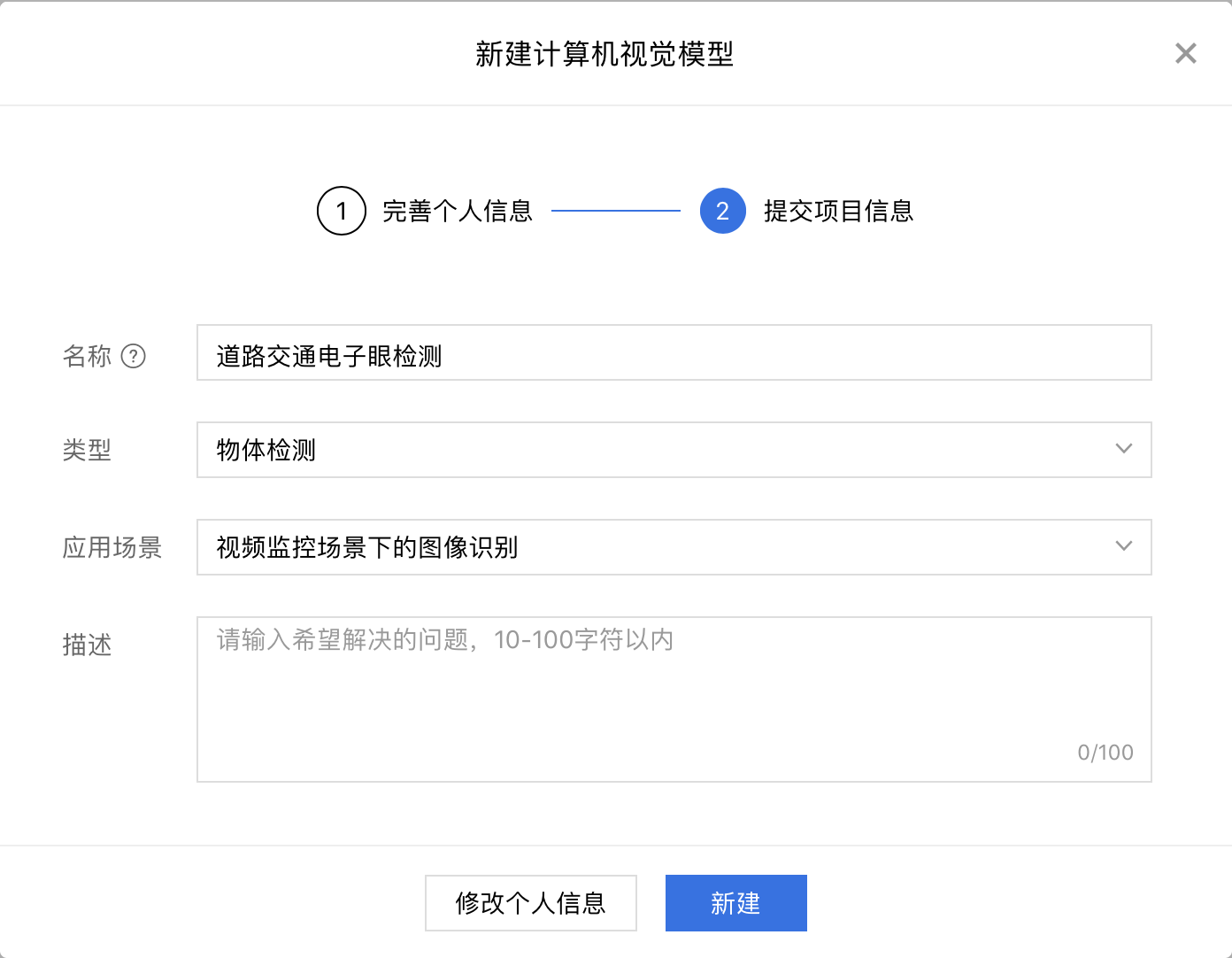
3、点击【新建任务】。

4、点击【+请选择】,勾选刚刚上传数据集下的所有标签类,点击右下角【确定】。

5、可以选择上传验证集和测试集。验证集用来确定模型训练过程中超参数的调整。测试集用来获得更客观的模型效果评估结果。如果选择不上传,系统也会自动从已上传的训练集中分割出验证和测试集。

6、配置网络,网络选型参考:网络选型介绍。
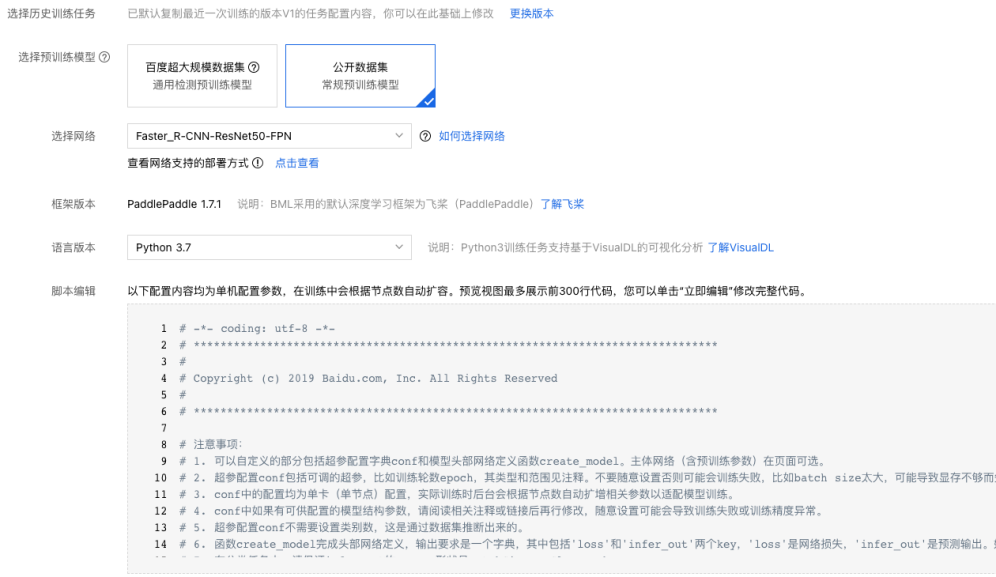
7、配置超参数。如果选择脚本编辑为超参来源,可在脚本编辑部分代码框内自定义超参数。超参数配置参考:超参数选择

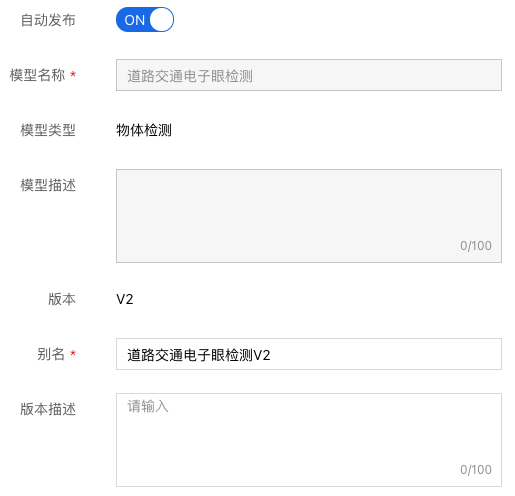
8、可填写相关信息,并发布模型。也可以模型训练完成后再根据训练结果决定是否发布。
9、根据自身的周期和经费安排,配置计算资源。
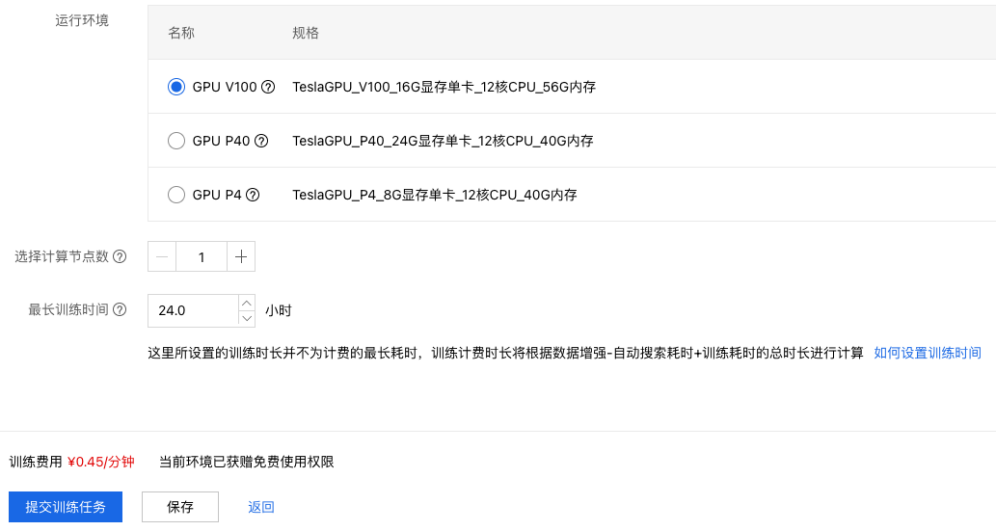
10、最后点击【提交训练任务】,进入模型训练。
模型分析和调优
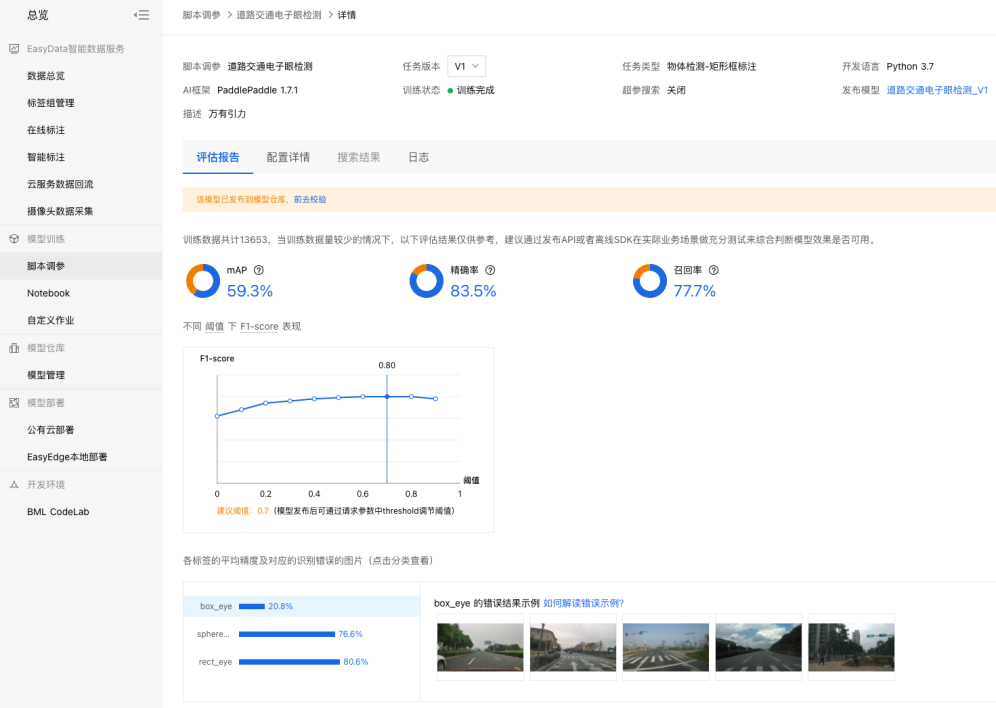
1、获取评估报告:点击【模型仓库】-【模型管理】,点击对应任务的【版本列表】查看训练好的模型,点击【评估报告】。

评估报告如下所示:
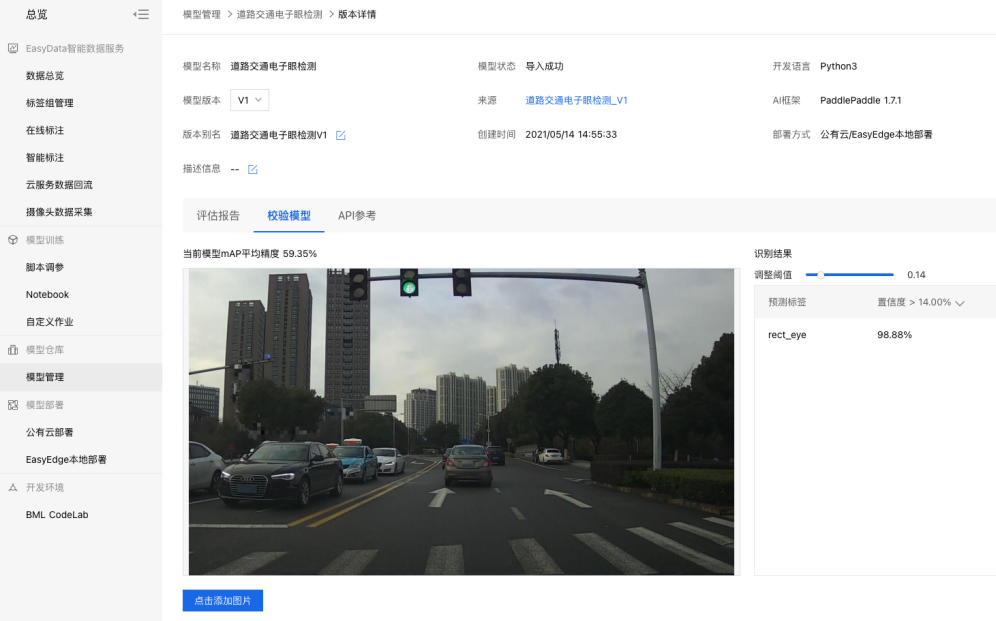
2、点击【校验模型】。
3、模型调优:新建模型时添加如下配置,可提高模型效果。
策略一:数据增强策略(数据增强算子参考)

策略二:百度超大规模数据集预训练(预训练模型参考)

策略三:自动超参搜索(自动超参配置参考)

采用以上优化策略之后,重新打开评估报告,可以看到效果有明显的提升。

部署模型
1、在模型管理中,可选择公有云部署, 端云协同服务,批量预测,和纯离线服务四种方式部署模型。具体参考:如何选择部署方式
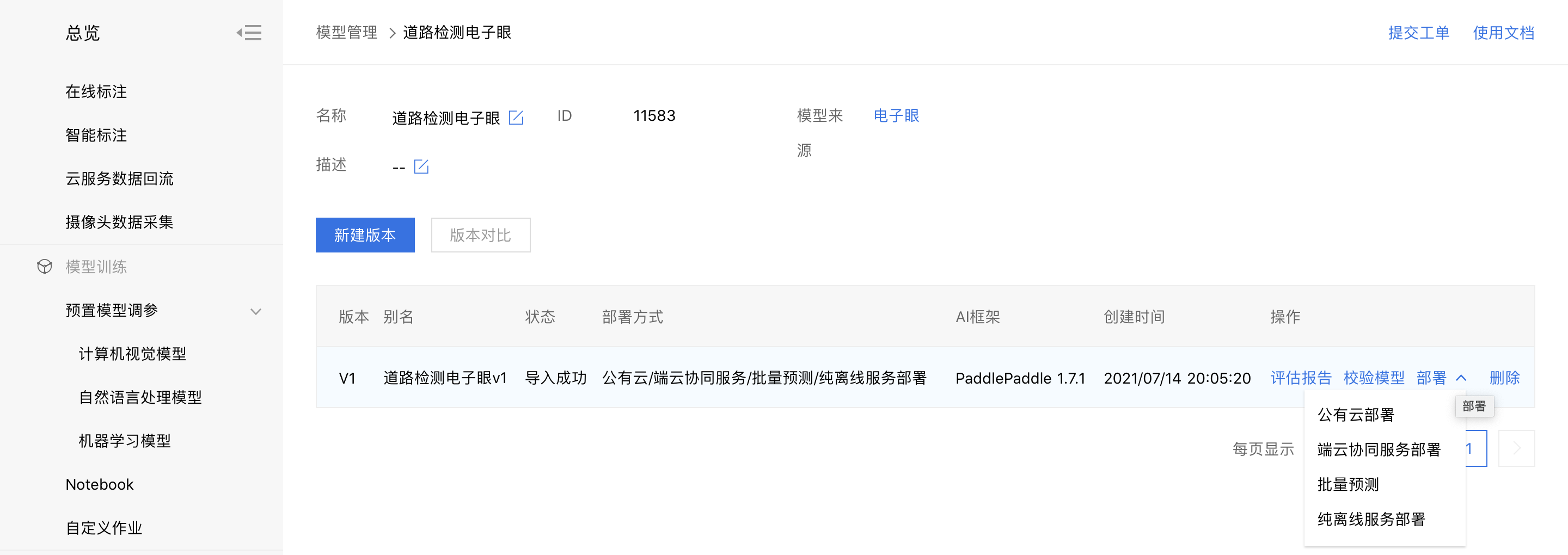
2、在模型部署中,用户按照自己情况填写信息完成模型部署。下图以本地部署纯离线服务为例。

公有云调用
模型仓库中的视觉模型,发布为公有云部署时储在云端,可通过独立Rest API调用模型,实现AI能力与业务系统或硬件设备整合。BML具有完善的鉴权、流控等安全机制,并配置丰富的资源集群稳定承载高并发请求。 并且支持查找云端模型识别错误的数据,纠正结果并将其加入模型迭代的训练集,不断优化模型效果。
使用流程
1、在BML平台公有云部署的操作页面,点击『部署模型』,新建模型部署的任务。

2、填写相关信息,完成创建。
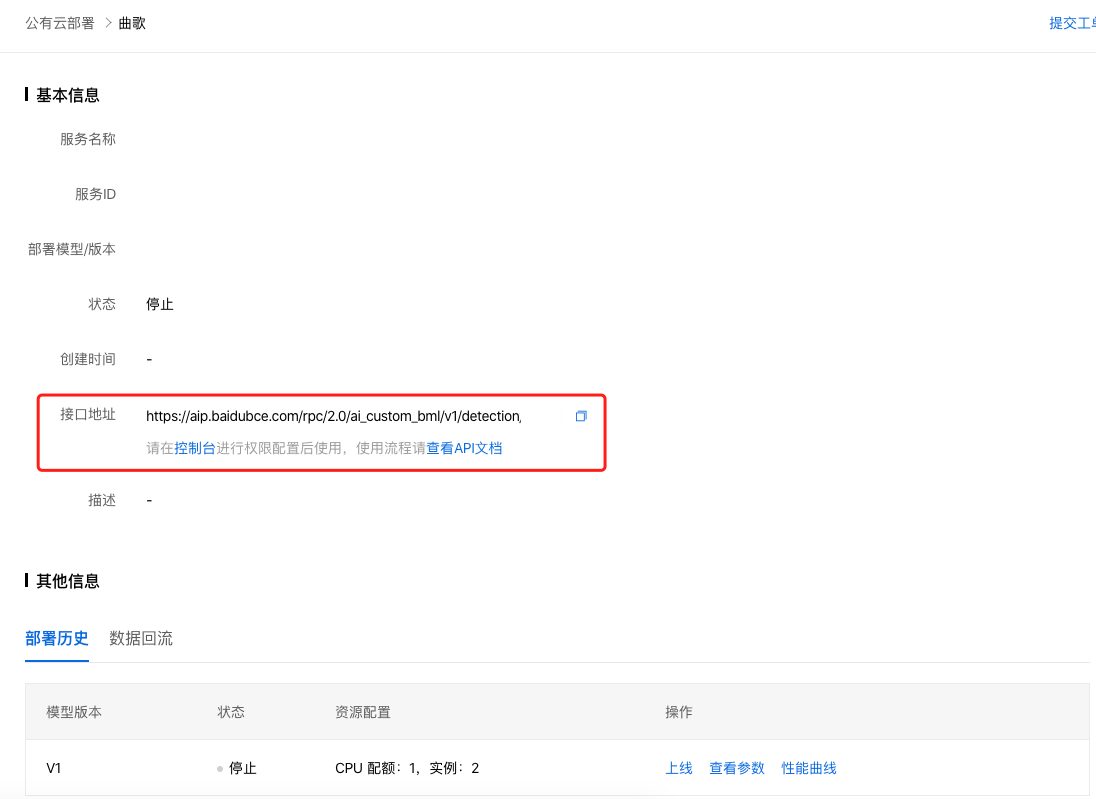
2、完成创建后回到操作页面,点击『查看详情』,查看配置信息,并获取『接口地址』信息。

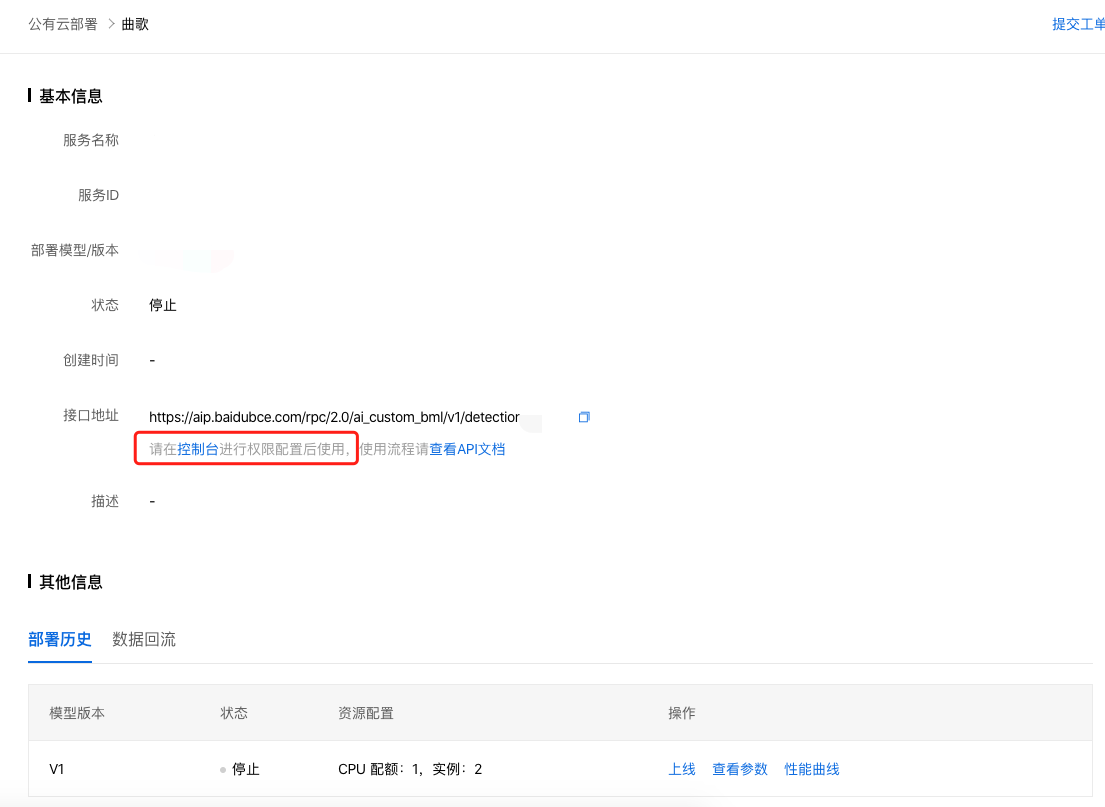
3、点击控制台,进入百度智能云-BML控制台,创建应用。
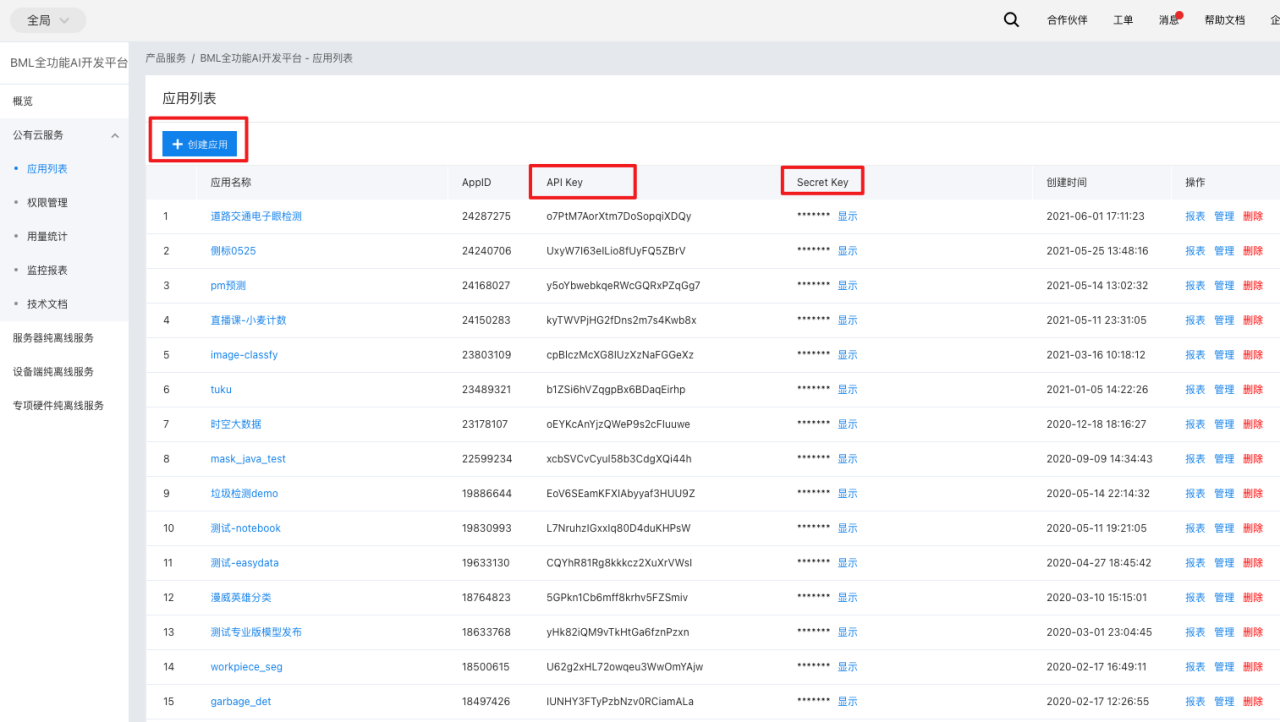
4、创建应用后,在应用列表页可获取『API Key』和『Secret Key』两个信息。
5、请求示例如下。
HTTP方法:POST
请求URL: 请首先进行自定义模型训练,完成训练后申请上线,上线成功后可在服务列表中查看并获取url。
URL参数如下:
| 参数 | 值 |
|---|---|
| access_token | 通过API Key和Secret Key获取的access_token |
Header如下:
| 参数 | 值 |
|---|---|
| Content-Type | application/json |
注意:如果出现336001的错误码很可能是因为请求方式错误,与其他图像识别服务不同的是定制化图像识别服务以json方式请求。
6、请求参数注意事项如下。
| 参数 | 是否必选 | 类型 | 可选值范围 | 说明 |
|---|---|---|---|---|
| image | 是 | string | - | 图像数据,base64编码,要求base64编码后大小不超过4M,最短边至少15px,最长边最大4096px,支持jpg/png/bmp格式,注意请去掉头部 |
| threshold | 否 | number | - | 阈值,默认值为推荐阈值(0-1之间),具体值可在我的训练任务列表-模型效果查看 |
7、按照下述示例代码,填入相关信息即可完成调用API服务。
以python3.7为例:
# coding:utf-8
"""
Copyright (c) 2021 Baidu.com, Inc. All Rights Reserved
Author: test@baidu.com
"""
import requests
import json
import base64
import cv2 as cv
def data_form(image_path):
"""
Convert data format.
"""
with open(image_path, 'rb') as f:
base64_data = base64.b64encode(f.read())
data = base64_data.decode()
return data
def show_result(image_path, result, out_path):
"""
Draw results on image.
"""
image = cv.imread(image_path)
for target in result:
box = target['location']
label = target['name']
score = target['score']
first_point = (box['left'], box['top'])
last_point = (box['left'] + box['width'], box['top'] + box['height'])
cv.rectangle(image, first_point, last_point, (0, 255, 0), 2)
cv.putText(image, label + ':' + '%.4f' % score, first_point, cv.FONT_HERSHEY_SIMPLEX,
0.5,(255,0,0), 1, cv.LINE_AA)
cv.imwrite(out_path, image)
img = cv.resize(image, (600,600))
def detection(image_path, header, request_url, out_path):
"""
Processing detection results.
"""
data = data_form(image_path)
request_payload = {
"image": data,
"threshold": "0.7"}
response = requests.post(request_url,data=json.dumps(request_payload),headers=header).text
print('response : ', response)
tt = json.loads(response)
result = tt['results']
show_result(image_path, result, out_path)
# 打印预测结果
print('result : ', result)
# 调用鉴权接口获取token
def get_access_token(host):
"""
get access_token.
"""
response = requests.get(host)
if response:
return response.json()['access_token']
else:
print('fail to get access_token')
return None
if __name__ == "__main__":
# 获取API Key、Secret Key(需要修改)
AK = '【控制台应用列表处复制】'
SK = '【控制台应用列表处复制】'
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&
client_id={}&client_secret={}'.format(AK, SK)
# 获取access_token
access_token = get_access_token(host)
# 本地数据集存放地址 (需要修改)
image_path = './检测/道路交通电子眼检测/道路交通电子眼检测_测试集/image/19530.jpg'
# Header
header = {"Content-Type": "application/json"}
# API接口地址 (需要修改)
request_address = 'https://aip.baidubce.com/rpc/2.0/ai_custom_bml/v1/detection/trafficV1'【配置详情页处复制】
# 拼接API接口地址和access_token
request_url = '{}?access_token='.format(request_address) + access_token
# 预测输出路径 (需要修改)
out_path = './output/detection_result.jpg'
# 调用API
detection(image_path, header, request_url, out_path)
