目录
1.实例分割简介
2.平台入口
3.准备数据
3.1 自动驾驶道路实例分割数据介绍
3.2 创建及导入数据集
4.训练模型
5.模型分析和调优
6.部署模型
用BML实现实例分割:以自动驾驶道路实例分割为例
实例分割简介
亲爱的开发者您好,欢迎使用百度BML全功能AI开发平台开启您的AI开发之旅!
实例分割是主流的计算机视觉任务,对比物体检测,支持用多边形标注训练数据,模型可像素级识别目标。适合图中有多个主体、需识别其位置或轮廓的场景。其主要应用场景有:
- 专业检测:应用于专业场景的图像分析,比如在卫星图像中识别建筑、道路、森林,或在医学图像中定位病灶、测量面积等。
- 智能交通:识别道路信息,包括车道标记、交通标志等。
下文中将以自动驾驶道路实例分割任务为例,分步骤向您详细介绍如何使用百度BML全功能AI开发平台开发您自己的实例分割模型。
自动驾驶道路实例分割任务简介:
道路场景分割在自动驾驶领域至关重要,主要应用在自动驾驶中的可行驶区域划分、自动驾驶路径规划、高精地图构建以及辅助驾驶的AR导航。
平台入口
BML全功能AI开发平台为企业及个人开发者提供机器学习和深度学习一站式AI开发服务,并提供高性价比的算力资源,助力企业快速构建高精度AI应用,进入官方网站点击【立即使用】。
准备数据
准备数据是AI模型开发的关键一环,训练数据的质量决定了训练所得模型效果可达到的上限,下面来介绍数据规范与相关操作步骤。
自动驾驶道路实例分割数据介绍
本文采用来自apollo道路实例分割数据集作为示例,总共268张图片,分为rider、bicycle、motorbicycle、truck、person、bicycle_group、bus、car、motorbicycle_group、tricycle十个类别。
导入平台即可使用,数据下载链接:Apollo道路实例分割数据集-json格式。
创建及导入数据集
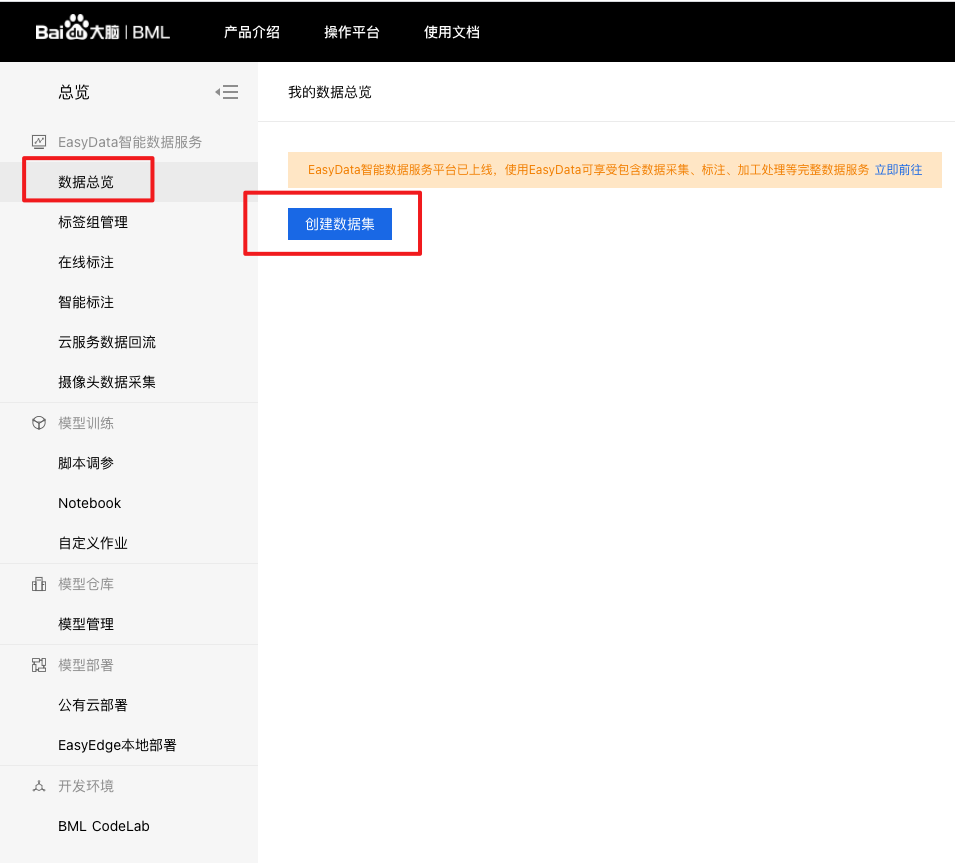
1、在官网界面点击【数据总览】,进入数据集操作界面,点击【创建数据集】。
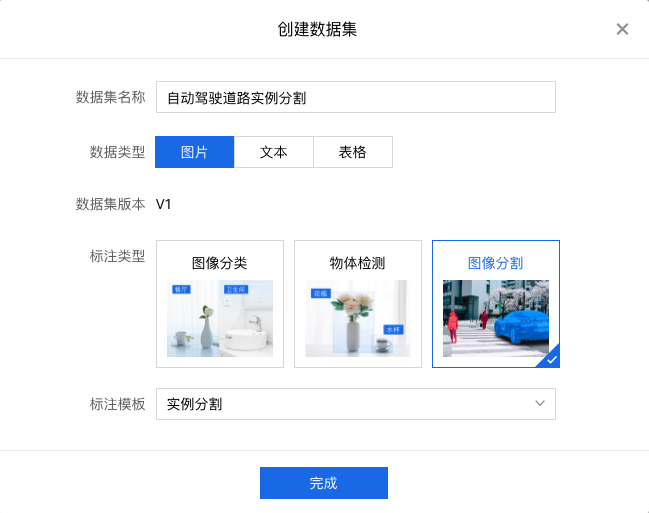
2、进入创建数据集界面,填写相关信息,选择数据和标注类型(注意训练集、验证集、测试集需要分开创建)。
3、数据集创建完成后,可以在数据总览界面看到刚才创建好的数据集ID,点击【导入】,将自己要训练的数据集导入。
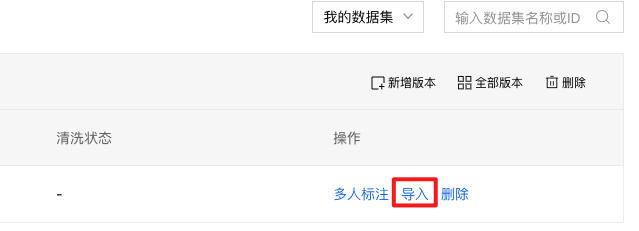
以本地导入-上传压缩包为例:导入方式选择【本地导入】,选择标注格式,点击【上传压缩包】。
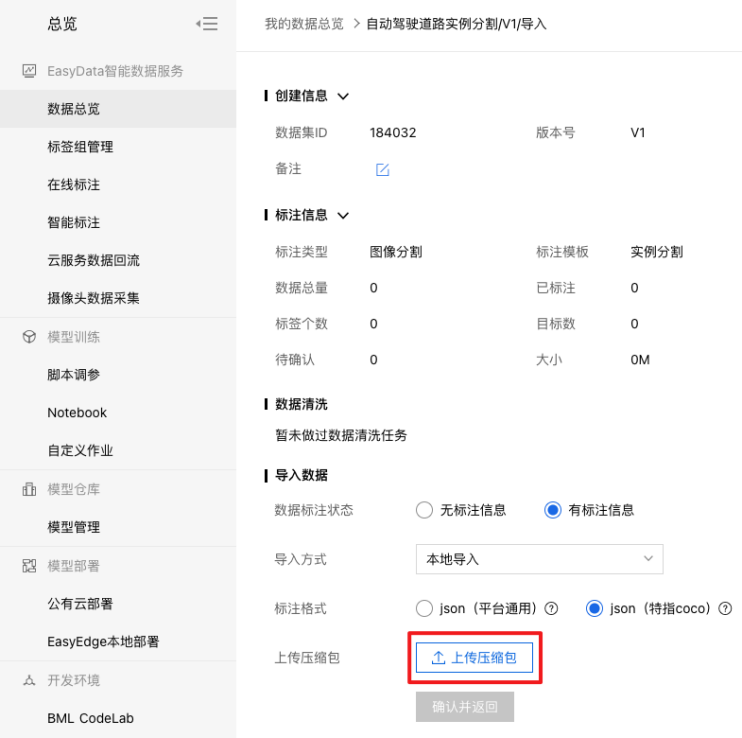
仔细阅读上传压缩包格式要求,可点击【下载示例压缩包】确认格式:
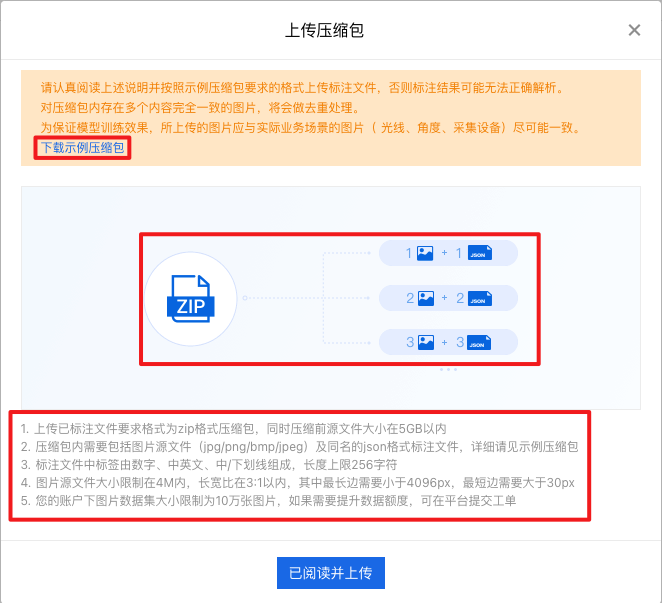
确认格式无误后,点击【已阅读并上传】, 注意上传时不要关闭网页:
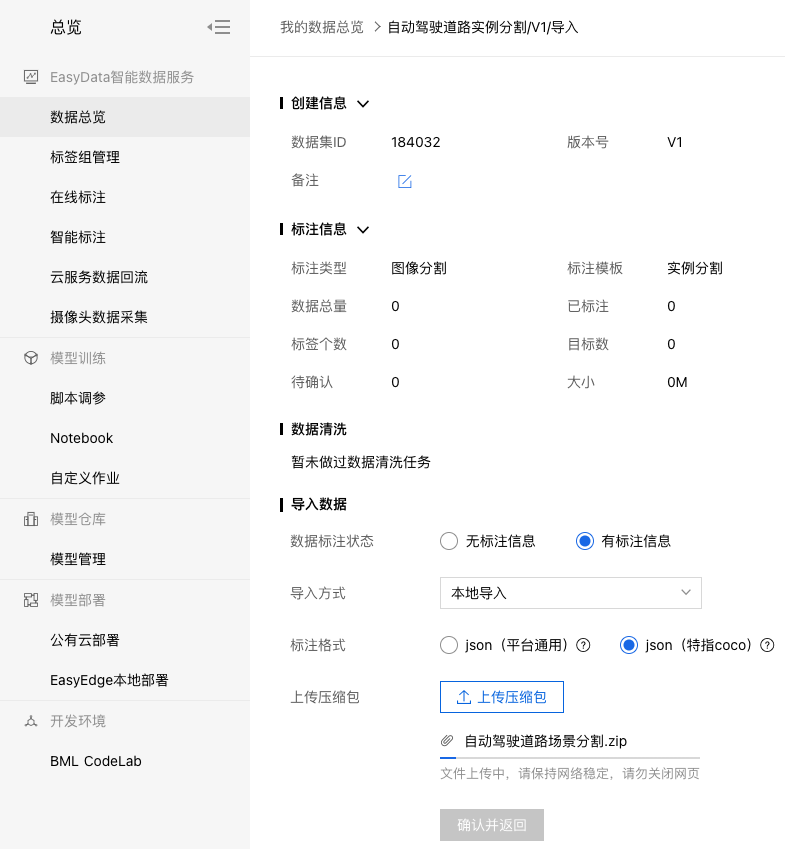
点击【确认并返回】后自动开始导入:
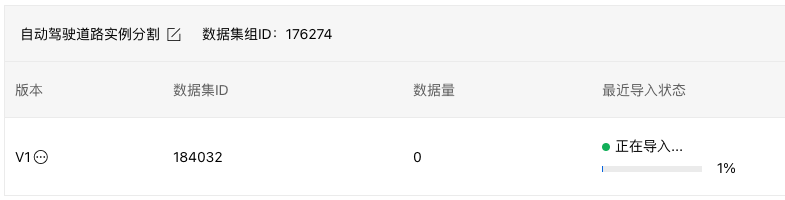
可看到【标注状态】为100%,如果数据集没有全部标注,可使用平台【智能标注】功能。
训练模型
BML上提供了预置模型调参、NoteBook建模、自定义作业三种开发模式,开发难度和开发的灵活性程度不一,分别满足不同水平和需求的开发者。
本文以使用者最多的预置模型调参开发模式为例,示意训练模型的基本步骤。
1、进入bml官方平台点击【预置模型调参】-【计算机视觉模型】,点击【创建】。
2、填写项目信息并点击【新建】。
3、点击【新建任务】。

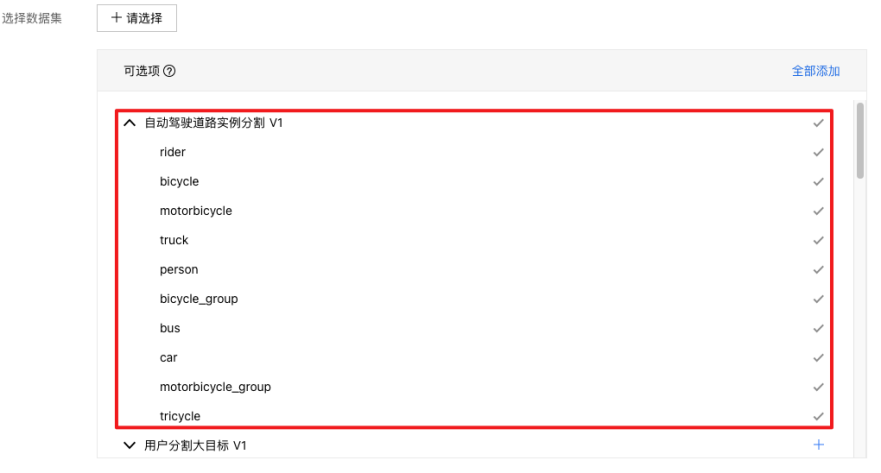
4、点击【+请选择】,勾选刚刚上传数据集下的所有标签类,点击右下角【确定】。
5、可以选择上传验证集和测试集。验证集用来确定模型训练过程中超参数的调整。测试集用来获得更客观的模型效果评估结果。如果选择不上传,系统也会自动从已上传的训练集中分割出验证和测试集。

6、配置网络,网络选型参考:网络选型介绍。
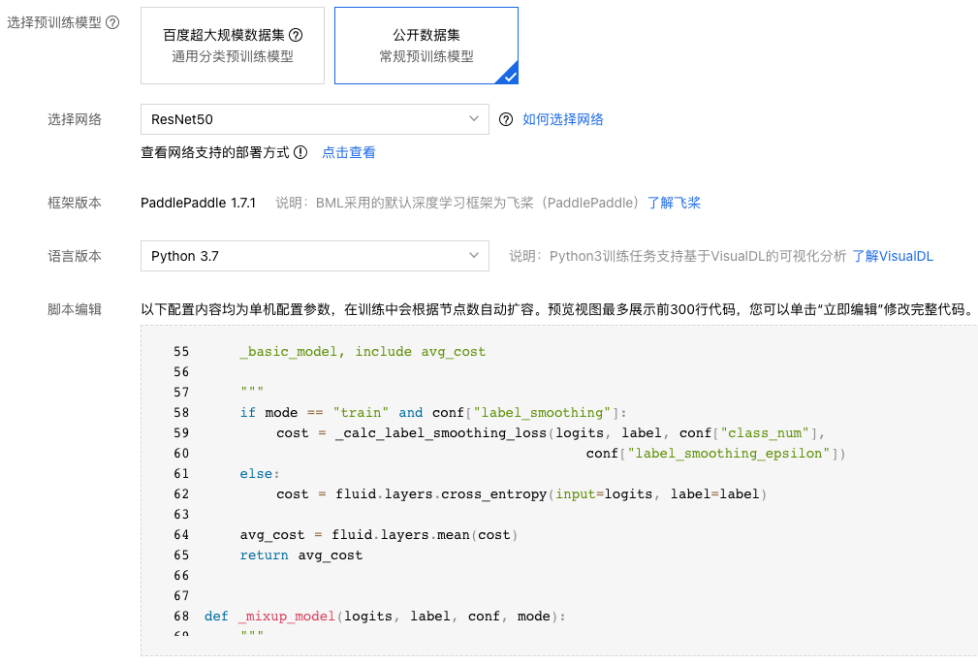
7、配置超参数。 如果选择脚本编辑为超参来源,可在脚本编辑部分代码框内自定义超参数。超参数配置参考:超参数选择

8、可填写相关信息,并发布模型。也可以模型训练完成后再根据训练结果决定是否发布。

9、根据自身的周期和经费安排,配置计算资源。
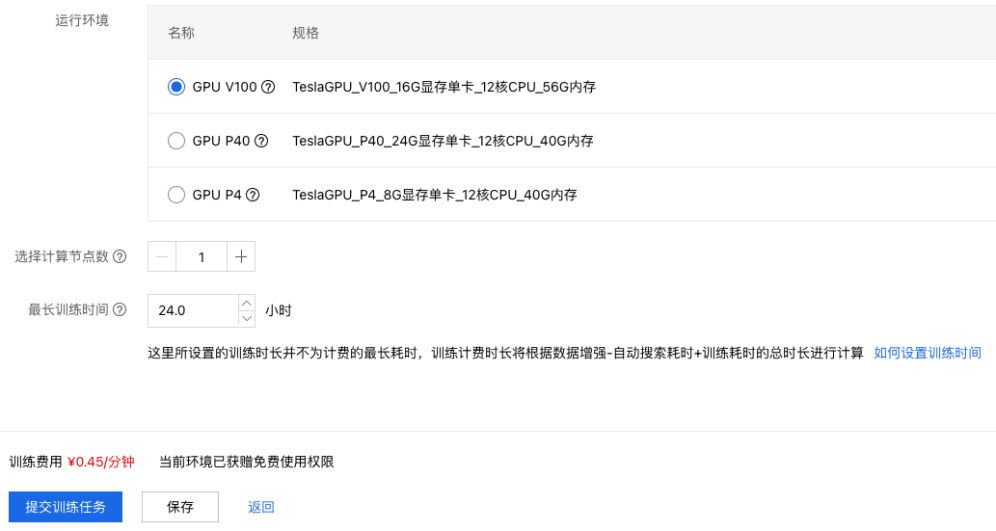
10、最后点击【提交训练任务】,进入模型训练。
模型分析和调优
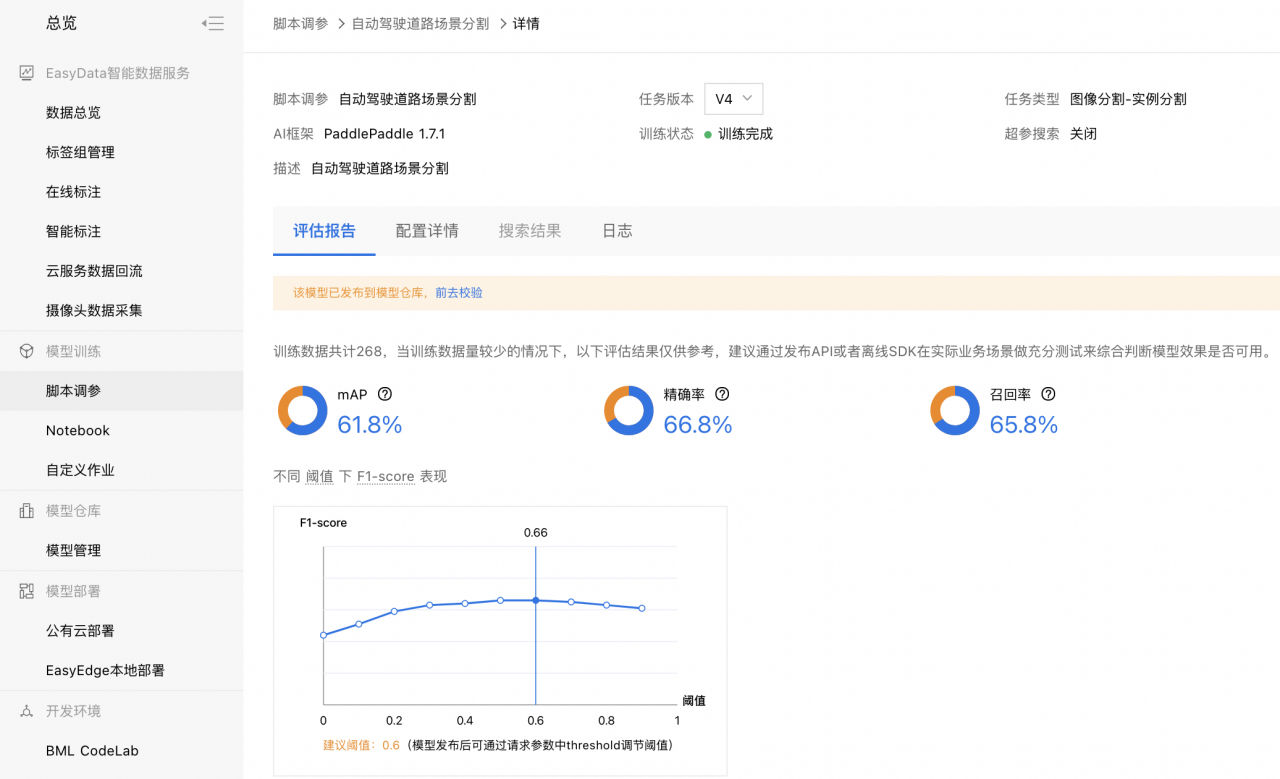
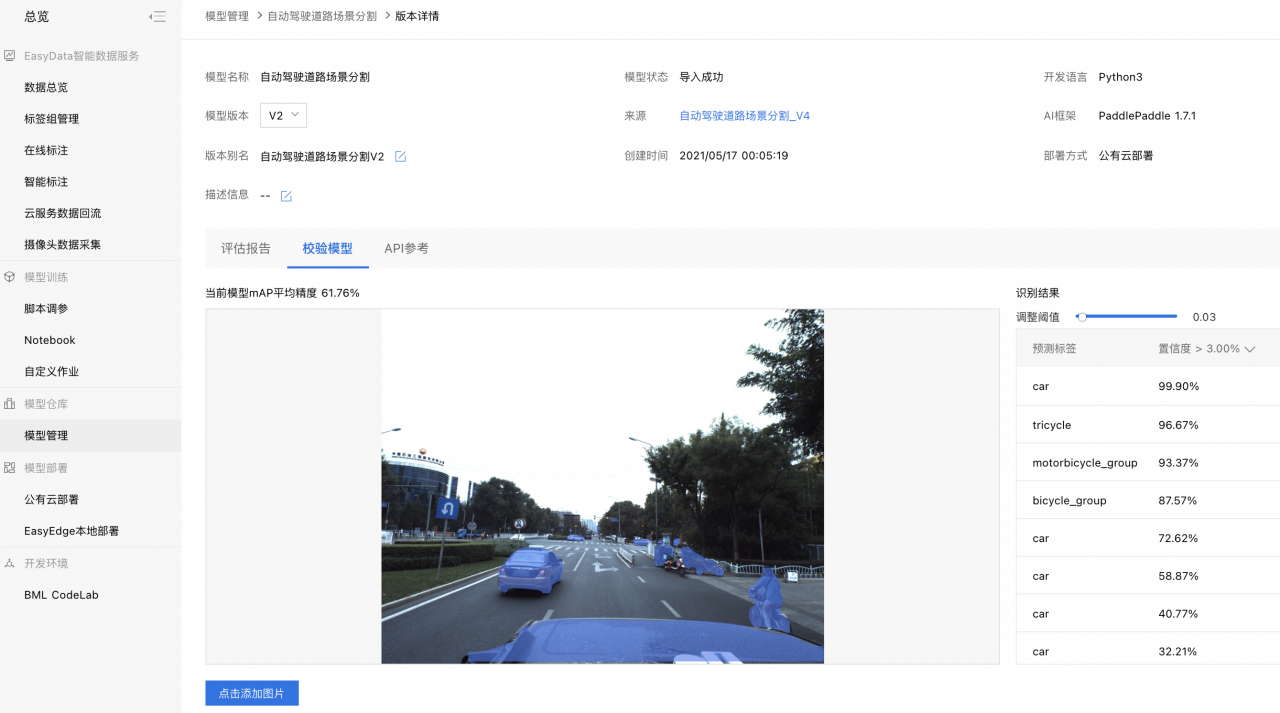
1、获取评估报告:点击【模型仓库】-【模型管理】,点击对应任务的【版本列表】查看训练好的模型,点击【评估报告】,评估报告如下图所示。
2、点击【校验模型】。
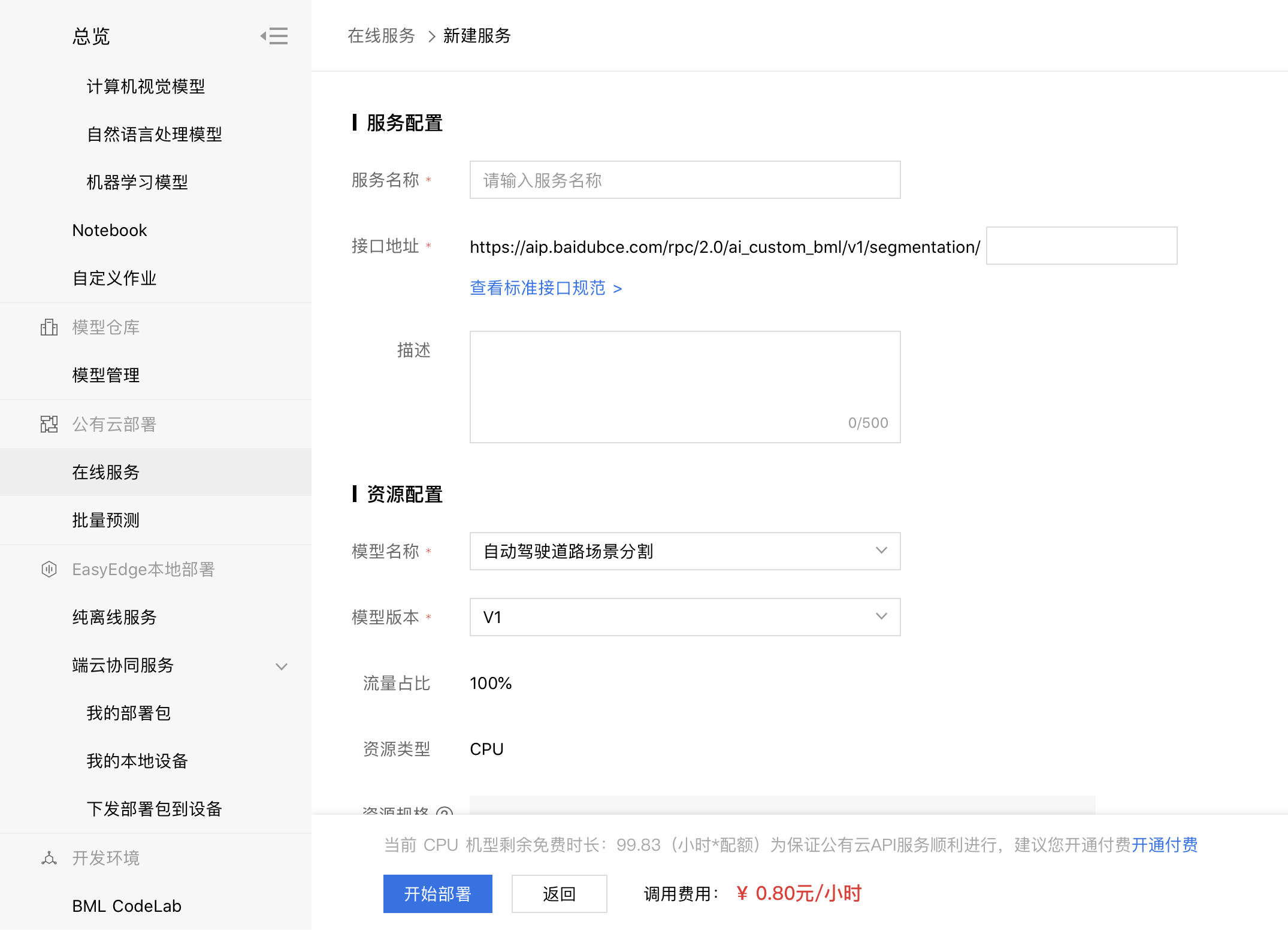
部署模型
1、在模型管理中,可选择公有云部署,端云协同服务,和批量预测三种方式发布模型。具体参考:如何选择部署方式

2、在模型部署中,用户按照自己情况填写信息完成模型部署。下图以公有云部署为例。