1. 适用场景
本文适用于使用百度智能云数据传输服务DTS(以下简称 DTS),将DTS已经支持的数据源迁移至Elasticsearch目标端中的场景。
2. 将Elasticsearch作为DTS目标端的限制
- 不支持结构迁移
- 增量同步不支持同步关系型数据库的DDL语句
- 源端数据源为MySQL时,源端二进制日志(binlog)中的enum/set/timestamp类型字段只保留了原始二进制信息,DTS增量迁移到下游的数据与源端binlog保持一致,用户需要自行按照上游MySQL表结构解析其释义
- 不支持同步源端数据源的二进制(binary)类型数据
3. 将Elasticsearch作为DTS目标端的前置条件
3.1 环境要求
已创建作为迁移目标端的Elasticsearch实例,如:百度Elasticsearch实例、自建Elasticsearch实例。DTS支持的Elasticsearch版本为5.0及以上
3.2 权限要求
要求账号拥有在目标端Elasticsearch实例中创建索引、写入数据的权限
3.3 目标端Elasticsearch推荐配置
目前,DTS暂不支持结构迁移。如果您选择全量/增量迁移,向下游写入数据时,Elasticsearch会根据写入数据的格式自动建立索引,并指定相应的索引映射(mapping)。但有可能Elasticsearch自行映射的字段类型并不符合实际的使用需求,因此不推荐这样做。
我们推荐在启动DTS任务前,先建立目标端Elasticsearch的相关索引,并按照实际的查询需求指定每一个字段的类型,然后启动DTS数据迁移任务。
此外,为了避免大批量写入数据给下游的Elasticsearch实例造成过高的负载,我们推荐将集群粒度属性refresh_interval配置为相对合理的值。如果您能接受新写入的数据在写入后1分钟可见,则可以考虑将refresh_interval取值设为1m。
PUT /indice/_settings
{
"index" : {
"refresh_interval" : "1m"
}
}
4. 使用Elasticsearch作为DTS目标端
使用Elasticsearch作为目标端,在任务创建、前置检查、任务启动、任务暂停、任务终止的操作流程请参考操作指南。
在任务配置和对象映射部分与其他数据源有些许不同。
4.1 任务配置
首先配置数据传输任务的上下游连接信息
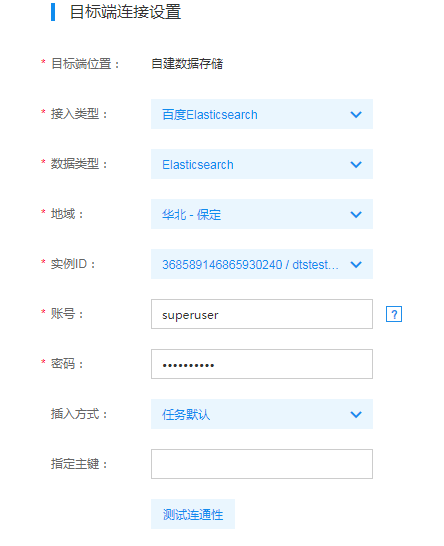
如上图所示,目标端应选择Elasticsearch实例。目前DTS的目标端支持云上托管产品百度Elasticsearch和自建Elasticsearch实例。图中选择了华北-保定地域的百度Elasticsearch实例。Elasticsearch目标端配置参数说明如下:
- 接入类型:支持公网/BCC/BBC/DCC自建Elasticsearch实例和百度Elasticsearch实例
- 数据类型:固定选择Elasticsearch
- 地域:自建实例/百度Elasticsearch实例所在的百度云逻辑地域。接入类型选择公网时不需要选择地域
- 实例ID:接入类型选择BCC/BBC/DCC时,表示BCC/BBC/DCC实例ID;接入类型选择百度Elasticsearch时,表示百度Elasticsearch实例ID。接入类型选择公网时,不需要选择实例ID,但需要填入实例IP。
- 端口:Elasticsearch实例的访问端口,百度Elasticsearch实例不需要填写该字段。
如果您的Elasticsearch实例为自建集群,且集群中包含多个节点,配置任务时只需要填写集群中某一个节点连接信息即可,推荐使用主节点配置任务
- 账号鉴权:接入类型选择百度Elasticsearch时,默认要求填写账号和密码,可在百度Elasticsearch实例详情页查得。接入类型选择公网/BCC/BBC/DCC时,可按照自建Elasticsearch实例的实际配置,选择是否需要填写账号鉴权信息
- 插入方式:属于数据视图相关功能,配置方式详见下文【数据视图】->【如何配置任务】。正常的数据迁移任务选择任务默认即可
- 指定主键:属于数据视图相关功能,配置方式详见下文【数据视图】->【如何配置任务】。正常的数据迁移任务无需配置该字段
- 负载均衡:仅当接入类型选择公网/BCC/BBC/DCC自建时可选。若打开负载均衡,则DTS在数据迁移过程中,会查询并维护Elasticsearch集群全局拓扑,并在写入时将请求随机发到集群的任意存活节点中。
完成配置后点击【授权白名单进入下一步】,进入对象映射配置页
4.2 对象映射
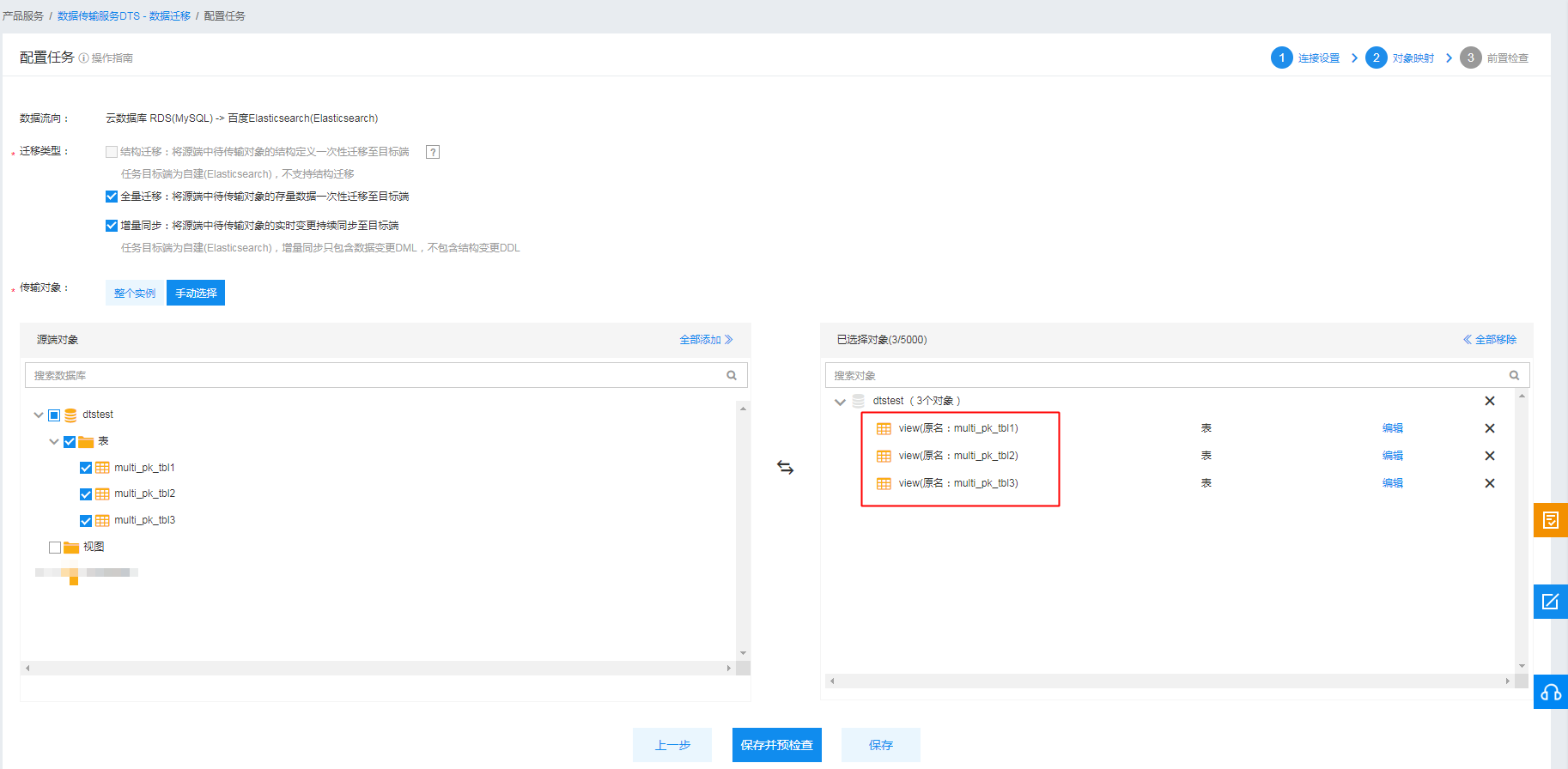
如上图所示,数据流向为:云数据库 RDS(MySQL) -> 百度Elasticsearch(Elasticsearch),迁移类型选择全量迁移+增量同步。传输对象可以选择迁移源端整个实例,也可以选择手动筛选迁移对象。图中选择将dtstest库下的multi_pk_tbl1、multi_pk_tbl2、multi_pk_tbl3三张表作为迁移对象。
选择好的迁移对象会出现在右边的已选择对象列表中。DTS支持上下游库表名映射、行过滤、列过滤黑白名单等功能。可以点击【编辑】,对每一个迁移对象配置映射和过滤规则。
上图中,示例任务配置了multi_pk_tbl1和multi_pk_tbl2的表名映射规则,将其目标端表名改为tbl1和tbl2。您也可以按照自己需要配置行过滤规则和列过滤黑白名单。
DTS数据迁移的映射规则为源端一张表对应Elasticsearch中一个索引,索引名为:映射后库名_映射后表名。如dtstest.multi_pk_tbl1表,配置了表名映射规则multi_pk_tbl1->tbl1后,对应下游的索引名为:dtstest_tbl1。同理,dtstest.multi_pk_tbl2表对应的下游索引名为dtstest_tbl2。而图中dtstest.multi_pk_tbl3表并未配置表名映射,因此其映射后表名仍为multi_pk_tbl3,所以其对应的下游索引名为:dtstest_multi_pk_tbl3。
如果选择库级别迁移,则只能配置库名映射,无法配置表名映射。下游索引名:映射后库名_表名。如:test库下有tbl1一张表,任务选择迁移test库,并配置库名映射为:test->alpha。则下游Elasticsearch实例中新建的索引名为:alpha_tbl1。
另外,Elasticsearch要求索引名必须为全小写。因此DTS会默认将上游库表名转为全小写的索引名。如:上游的dtsTEST.TESTTABLE表对应的下游Elasticsearch索引名为:dtstest_testtable。
完成对象映射配置后,点击【保存并预检查】,启动任务的前置检查
5. 数据视图
5.1 业务场景
数据视图就是将源端数据源多张实体表的数据拼成一个视图,并保存到目标端Elasticsearch实例的同一个索引中。
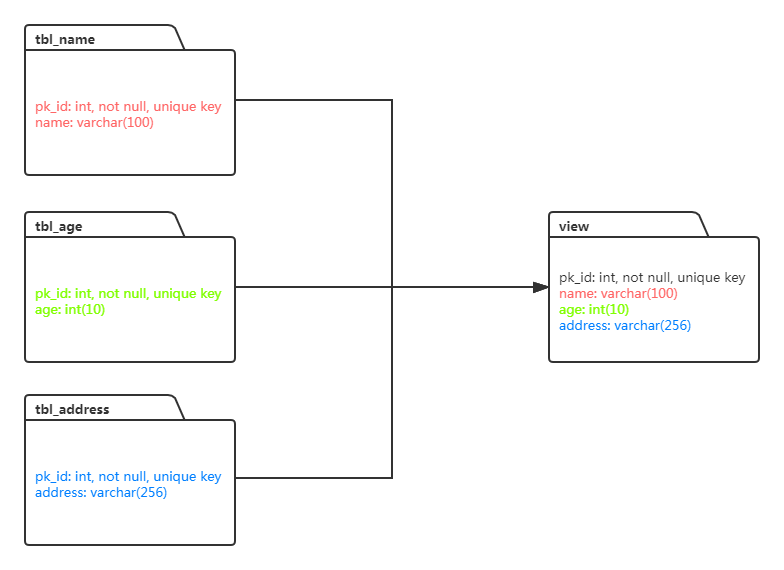
如上图所示,源端数据源中存在三张实体表:tbl_name、tbl_age、tbl_address。其中,三张表中主键相同且均为pk_id,但表中其他字段相异。DTS支持建立源端多张实体表的数据同步到目标端某一个或某几个索引的数据迁移任务,同步任务以pk_id为索引指定主键,支持同步全量或增量数据。
5.2 使用限制
- 同一视图内的表均包含索引指定主键。如上图中,tbl_name、tbl_age、tbl_address三张表中均包含索引指定主键pk_id
- 源端数据视图一致性由用户保证。同一视图内的表新增和删除数据时应尽可能保证原子性
- 不支持修改数据视图的指定主键列,会导致任务执行失败
5.3 如何配置任务
5.3.1 连接配置
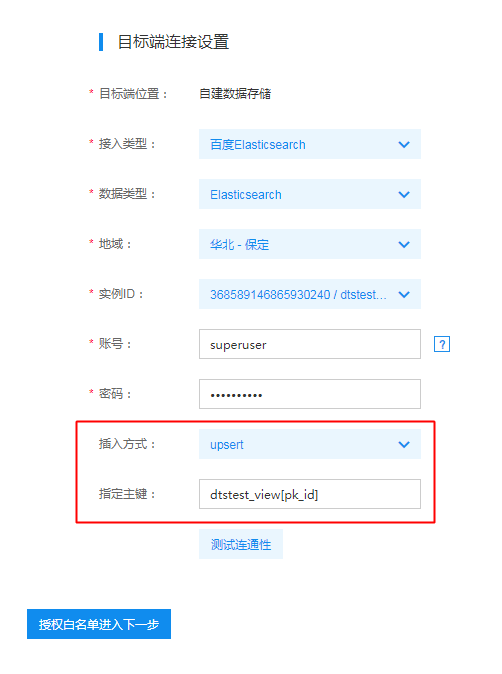
回到任务配置中的连接配置页,数据视图功能与正常迁移任务的区别在于需要多配置两个字段
- 插入方式:固定选择upsert
- 指定主键:用户需要指定一个数据视图中的主键列,格式为:下游索引名1[主键列];下游索引名2[主键列1,主键列2]。
如上文中【5.1 业务场景】中的示例。tbl_name、tbl_age、tbl_address三张表组成的数据视图主键列为pk_id。源端数据视图对应的Elasticsearch索引名为:dtstest_view,此时指定主键中就应当配置为dtstest_view[pk_id]。
此外,一个数据迁移任务中可以配置多个数据视图的同步规则。如:一个数据迁移任务内打算配置dtstest_view1(主键列为id)、dtstest_view2(主键列为user_id和name)两个数据视图的全量迁移+增量迁移,指定主键可以配置为:dtstest_view1[id];dtstest_view2[user_id,name]。不同视图间用分号(;)连接,同一视图的不同主键列间用逗号(,)连接。
5.3.2 对象映射
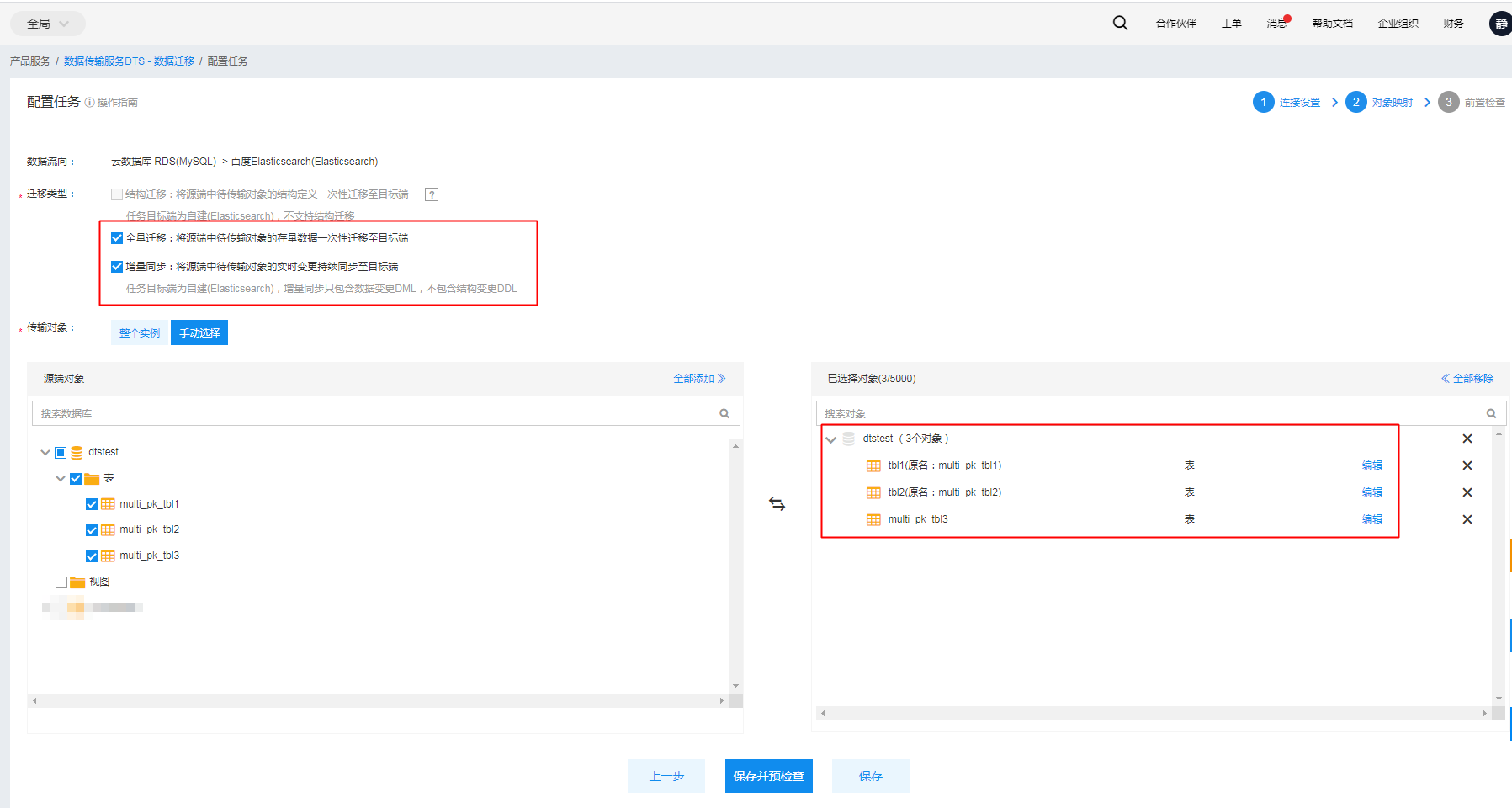
在对象映射配置页中,数据视图功能与正常迁移任务的区别在于同一数据视图的实体表需要配置表名映射,以确保源端多张表的全量数据和增量变更记录能够写入目标端同一个Elasticsearch索引中。
如下图所示,multipktbl1、multipktbl2、multipktbl3三张表同属同一个数据视图,因此三张表的目标端表名配置为view。配置后的目标端Elasticsearch索引名为:映射后库名_映射后表名(dtstest_view)。索引名与上一步中指定主键配置(dtstest_view[pk_id])中的索引名保持一致