




1. 适用场景
本文适用于使用百度智能云数据传输服务DTS(以下简称 DTS),将DTS已经支持的数据源迁移至Kafka目标端中的场景。
2. 将Kafka作为DTS目标端的限制
- 增量同步不支持同步关系型数据库的DDL语句
- DTS向Kafka发送消息满足At-Least-Once约束(消息不丢但可能重复),重启任务等行为会导致下游Kafka出现少量重复数据(建议使用每条数据的GLOBAL_ID做去重)
3. 将Kafka作为DTS目标端的前置条件
3.1 环境要求
已创建作为迁移目标端的Kafka集群或百度消息服务主题。自建Kafka集群支持版本为0.9或0.10
3.2 权限要求
要求给定账号拥有向Kafka指定topic写入数据的权限
3.3 目标端Kafka推荐配置
3.3.1 目标端为百度消息服务主题
无需额外配置,可直接配置DTS任务,步骤参见下文:目标端Kafka任务配置
3.3.2 目标端为自建Kafka集群
由于DTS服务管控节点和目标端自建Kafka集群间存在网络隔离,因而需要配置自建Kafka集群的访问路由规则。您可以根据需要选择不同的访问方式,并按步骤配置您的Kafka集群
3.3.2.1 通过公网访问您的Kafka集群
如果您希望DTS通过公网链路访问您的Kafka集群,您需要为Kafka集群中的每一台机器配置公网访问。假设目标端Kafka集群有三个broker,其公网IP分别为:106.0.0.1、106.0.0.2、106.0.0.3;其内部网络IP分别为:172.16.0.1、172.16.0.2、172.16.0.3。您需要在每个broker的配置文件server.properties做如下配置,以broker1为例(公网IP:106.0.0.1,内网IP:172.16.0.1):
listeners
listeners=INTERNAL://172.16.0.1:9092,PUBLIC://172.16.0.1:19092
listeners是用来定义broker的listener的配置项。 INTERNAL标签下的连接信息(172.16.0.1:9092),用于broker间的内部通信。这里配置了内网IP(172.16.0.1),表示broker间可以通过内部网络实现网络通信。如果您希望broker间的通信走公网链路,可以改为配置公网IP(106.0.0.1)。
PUBLIC标签标记的连接信息(172.16.0.1:19092),用于与公网进行网络通信。注意:这里配置的IP应当与INTERNAL标签下的IP保持一致,但端口务必要不同。
advertised.listeners
advertised.listeners=INTERNAL://172.16.0.1:9092,PUBLIC://106.0.0.1:19092
advertised.listeners用于将broker的listener信息发布到Zookeeper中,供客户端或其他broker查询。如果配置了advertised.listeners,那么就不会将listeners配置的信息发布到Zookeeper中。
INTERNAL标签下的连接信息(172.16.0.1:9092)与上文listeners配置保持一致,但PUBLIC标签下的连接信息(106.0.0.1:19092)需要填入公网IP。
listener.security.protocol.map
listener.security.protocol.map=INTERNAL:PLAINTEXT,PUBLIC:PLAINTEXT
listener.security.protocol.map用于配置监听者的安全协议。 这里您可以按照自己的需要为不同的连接方式配置不同的安全协议。示例中默认为INTERNAL和PUBLIC都配置了无访问控制(PLAINTEXT)的安全协议。
inter.broker.listener.name
inter.broker.listener.name=INTERNAL
inter.broker.listener.name用于指定某一个标签作为internal listener的连接方式,这个标签所代表的listener专门用于Kafka集群中broker之间的通信。 示例中将字段取值配置为INTERNAL,表示希望broker之间通过内部网络进行通信。
启动broker
完成上述4个参数的配置后,保存修改并退出到kafka根目录,重新启动broker1。然后按照相同步骤配置并启动broker2和broker3
3.3.2.2 通过百度云内部网络访问您的Kafka集群
除了公网自建实例外,目前DTS还支持下游是BBC或BCC自建的Kafka集群。由于集群部署在百度云上,用户可以选择绑定EIP后,让DTS通过公网访问Kafka集群,或直接通过百度云内部网络访问Kafka集群。
公网访问请参见上一章节,本章节介绍如何配置BBC/BCC自建的Kafka集群,使DTS能够通过百度云内部网络访问Kafka集群。
查询PNET IP
在百度云内部网络中,PNET IP用于唯一标识某一虚机实例,DTS使用PNET IP才能在百度云内部网络中正确访问到您的Kafka集群。在自己的BBC/BCC实例命令行执行如下命令,可以获得实例的PNET IP
curl http://169.254.169.254/2009-04-04/meta-data/public-ipv4

这里同样以broker1为例(PNET IP:10.0.0.1,内网IP:192.168.0.1),修改server.properties中的4个网络通信配置项,各个配置项含义详见上文通过公网访问章节。
listeners
listeners=INTERNAL://192.168.0.1:9092,EXTERNAL://192.168.0.1:19092
这里INTERNAL配置的IP是百度云VPC内网IP,您可以在BCC或BBC的实例详情页查询到实例的内网IP
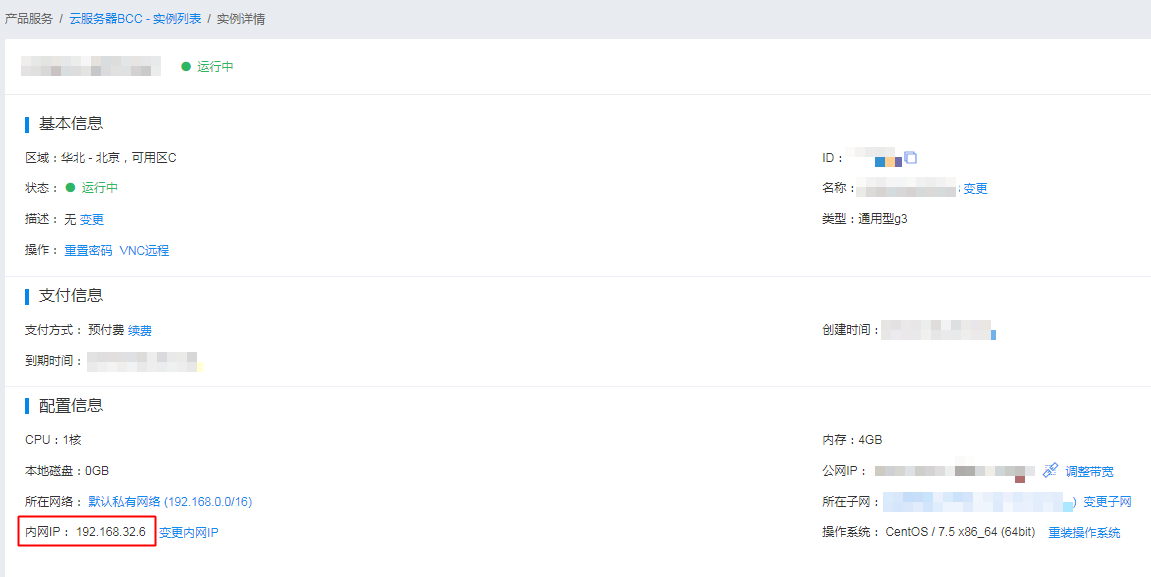
EXTERNAL标签下的listener表示通过PNET IP访问broker的连接信息,注意:这里配置的IP应当与INTERNAL标签下的IP保持一致,但端口务必要不同。
advertised.listeners
advertised.listeners=INTERNAL://192.168.0.1:9092,EXTERNAL://10.0.0.1:19092
这里EXTERNAL标签对应的advertised.listeners配置为PNET IP:监听端口,INTERNAL标签的内容与配置项listeners一致
listener.security.protocol.map
listener.security.protocol.map=INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
这里您可以按照自己的需要为不同的连接方式配置不同的安全协议。示例中默认为INTERNAL和EXTERNAL都配置了无访问控制(PLAINTEXT)的安全协议。
inter.broker.listener.name
inter.broker.listener.name=INTERNAL
示例中将字段取值配置为INTERNAL,表示broker之间可以通过百度云VPC子网进行通信。
4. 使用Kafka作为DTS目标端
使用Kafka作为目标端,在任务创建、前置检查、任务启动、任务暂停、任务终止的操作流程请参考操作指南。在任务配置和对象映射部分与其他数据源有些许不同。
4.1 任务配置
首先进入任务连接配置页,图中以源端为百度智能云数据库RDS for MySQL为例,选择源端实例即可
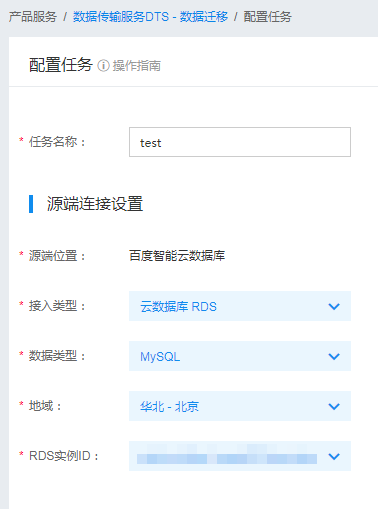
配置目标端连接信息时,首先要根据目标端Kafka集群的访问方式选择接入类型。
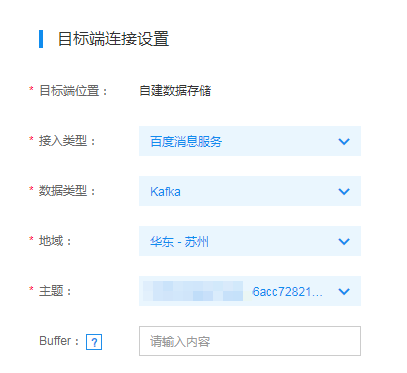
若目标端为百度消息服务主题,则接入类型选择百度消息服务,并选择相应的地域和主题ID
若目标端为自建Kafka集群,则如下图所示,按照公网访问和百度云内部网络访问两种方式选择对应的接入类型。
注意:Broker列表中的IP必须填PNET IP
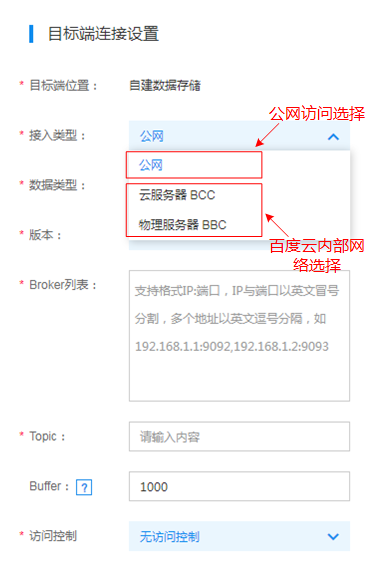
然后按要求填入其他信息即可。注意:目前DTS仅支持0.9和0.10版本的Kafka集群,并支持0.10版本Kafka集群配置SASL访问控制
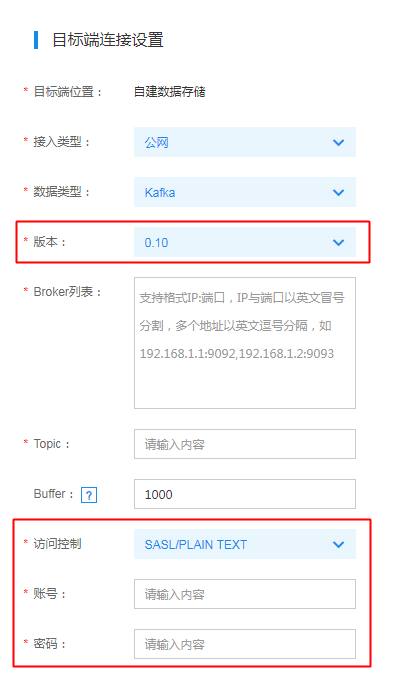
点击【授权白名单进入下一步】,选择源端实例的迁移对象。
4.2 对象映射
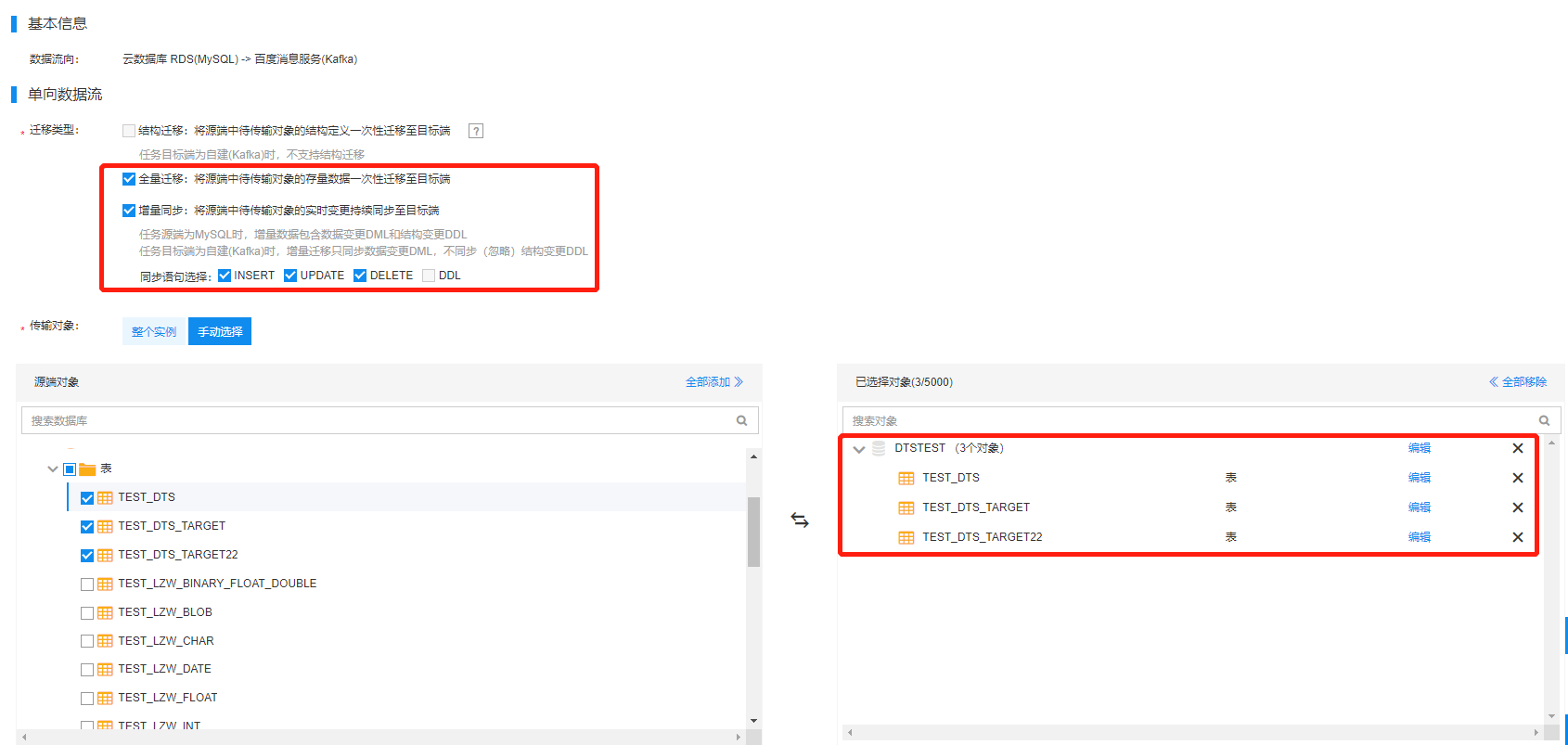
完成迁移类型和迁移对象的选择后,点击【保存并预检查】,完成新建任务,然后在任务列表查看任务状态。
- 状态列显示“前置检查通过”,可以勾选并启动迁移任务,任务启动后可以在任务进度列查看迁移进度。
- 状态列显示“前置检查失败”,点击旁边的按钮查看失败原因并修改,重新启动检查直到成功后再启动迁移任务。
前置检查项详细解释参见:数据迁移操作指南-预检查
5. Kafka数据格式
任务启动后,DTS将从源端数据库实例拉取到全量基准或增量变更数据,并以固定的格式写入目标端Kafka集群的指定Topic中。具体格式如下:
//json结构
[ //最外层是数组
{ //第一行记录,一条message可能包含1到多行记录
"TIME":"20180831165311", //时间戳
"GLOBAL_ID":"xxxxxxxx", //全局唯一ID,消费者可用此ID来去重
"DATABASE":"db1", //数据库名
"SCHEMA":"schema1", //SCHEMA名,仅在上游为PostgreSQL、SQLServer时存在
"TABLE":"tbl1", //表名
"TYPE":"U", //变更类型,I为insert,U为update,D为delete
"LOGICAL_CLOCK":"1617327447310000011", //逻辑时钟,用于批处理时判断消息先后顺序
"OLD_VALUES":{ //变更前每列的”列名”:”列值”组,变更类型为I时无OLD_VALUES
"key1":"old-value1",
"key2":"old-value2",
...
},
"NEW_VALUES":{ //变更后每列的”列名”:”列值”组,变更类型为D时无NEW_VALUES
"key1":"new-value1",
"key2":"new-value2",
...
},
"OFFSET":{ //该条记录的位置信息,仅在上游为MySQL时的增量迁移阶段有值,对消费者无用
"BINLOG_NAME":"mysql-bin.xxx",
"BINLOG_POS":"xxx",
"GTID":"server_id:transaction_id" //仅在使用GTID方式同步时存在
}
},
{ //第二行记录
"TIME":"20180831165311",
"DATABASE":"db1",
...
}
... //更多行记录
]
