

腾讯云容器服务实战教程 - 使用 TKE + 超级节点快速体验 Stable Diffusion
文档简介:
技术背景:
Stable Diffusion 是2022年发布的深度学习文本到图像生成模型,随着开源社区的活跃增长和 Stable Diffusion WebUI 开源项目的推出,已经成为了 AIGC 场景下首选开源方案,深受广大个人用户欢迎。而随着 GPT-4 的推出和 Stable DIffusion 最新版发布,越来越多企业开始认识到基于大模型的 AGI 和 AIGC 技术已经从“玩具”走向生产力工具,并快速拥抱 AI 技术。



技术背景
Stable Diffusion 是2022年发布的深度学习文本到图像生成模型,随着开源社区的活跃增长和 Stable Diffusion WebUI 开源项目的推出,已经成为了 AIGC 场景下首选开源方案,深受广大个人用户欢迎。而随着 GPT-4 的推出和 Stable DIffusion 最新版发布,越来越多企业开始认识到基于大模型的 AGI 和 AIGC 技术已经从“玩具”走向生产力工具,并快速拥抱 AI 技术。然而 AI 模型训练及推理需要消耗大量计算资源,尤其是 GPU 资源。随着 AI 技术的火热落地,GPU 资源也出现一卡难求的场景。对于企业客户来说,低成本获取 GPU 资源,并快速部署 AI 模型,已经成为最紧迫的事情。容器服务 TKE 为客户提供了 GPU 容器托管服务,客户可按需申请 GPU 资源,按秒付费,并快速进行服务扩缩,轻松应对训练推理业务需求波动,并降低整体 GPU 成本。
部署步骤
新建 TKE Serverless 容器集群和超级节点
1. 登录 容器服务控制台。
2. 新建一个 TKE Serverless 集群,操作步骤详情可参见 创建 TKE Serverless 集群。在创建 Serverless 集群时,请参考以下提示配置集群:
集群名称:例如 “Stable Diffusion 体验集群”。
Kubernetes 版本:选择默认的 Kubernetes 版本。
所在地域:建议选择使用上海地域体验,当前 GPU 资源较为充足。
集群网络:选择已有私有网络 VPC,或新建私有网络。
配置超级节点配置:
可用区:建议选择上海五区 ,当前可用区资源较为充足。
计费模式:选择按量计费,按秒粒度计费,按小时生成账单。
容器网络:选择可用区内已有的子网,或新建子网。
其他参数:保持默认值即可。
新建 Stable Diffusion 应用,并配置访问入口
集群创建完成后,在 容器服务控制台 单击集群名称进入集群详情页,并选择左侧导航中的工作负载。可以使用 YAML 文件快速部署,也可以使用控制台手动部署,建议使用 YAML 文件方式。
使用 YAML 快速部署
1. 登录 容器服务控制台,在集群列表中,单击集群名称。
2. 进入集群详情页,选择左侧导航中的工作负载。
3. 单击右上角 YAML 创建资源,复制以下内容并粘贴到 YAML 编辑器中:
apiVersion: apps/v1kind: Deploymentmetadata:labels:k8s-app: stable-diffusionqcloud-app: stable-diffusionname: stable-diffusionnamespace: defaultspec:replicas: 1selector:matchLabels:k8s-app: stable-diffusionqcloud-app: stable-diffusiontemplate:metadata:annotations:eks.tke.cloud.tencent.com/gpu-type: A10*GNV4veks.tke.cloud.tencent.com/root-cbs-size: "40"labels:k8s-app: stable-diffusionqcloud-app: stable-diffusionspec:containers:- args:- --listenimage: ccr.ccs.tencentyun.com/ai-aigc/stable-diffusion:taco.gpu.v1imagePullPolicy: IfNotPresentname: stable-diffusionresources:limits:cpu: "28"memory: 116Ginvidia.com/gpu: "1"requests:cpu: "28"memory: 116Ginvidia.com/gpu: "1"securityContext:privileged: falseterminationMessagePath: /dev/termination-logterminationMessagePolicy: FilednsPolicy: ClusterFirstimagePullSecrets:- name: qcloudregistrykeyrestartPolicy: AlwaysterminationGracePeriodSeconds: 30---apiVersion: v1kind: Servicemetadata:labels:k8s-app: stable-diffusionqcloud-app: stable-diffusionname: stable-diffusionnamespace: defaultspec:externalTrafficPolicy: ClusterinternalTrafficPolicy: ClusteripFamilies:- IPv4ipFamilyPolicy: SingleStackports:- name: 7860-7860-tcpport: 7860protocol: TCPtargetPort: 7860selector:k8s-app: stable-diffusionqcloud-app: stable-diffusionsessionAffinity: Nonetype: LoadBalancer
4. 单击完成,即可创建工作负载,并配置访问入口。
使用控制台手动部署
1. 登录 容器服务控制台,在集群列表中,单击集群名称。
2. 进入集群详情页,选择左侧导航中的工作负载 > Deployment,在 Deployment 页面单击新建。
3. 在新建 Deployment 页面,请参考以下提示进行配置:
名称:例如 “stable-diffusion-webui”。
Labels:一个键 - 值对(Key-Value),用于对资源进行分类管理。
命名空间:选择默认命名空间 Default。
实例类型:选择 GPU,并选择具体显卡型号,建议选择 A10 显卡,如 A10*GNV4。
系统盘大小:配置40GiB,因包含模型文件及加速框架,镜像体积较大。
实例内容器:
名称:输入容器名称,如 “stable-diffusion-webui ”。
镜像:直接输入或选择 ccr.ccs.tencentyun.com/ai-aigc/stable-diffusion 镜像,镜像版本为 taco.gpu.v1。
CPU/内存:可按照所选的 GPU 自带的 CPU、内存进行配置,如使用 A10*GNV4 显卡可配置最高 CPU 12 核,内存 44GiB = 45056 MiB。
GPU 限制:调整为1卡,即该容器会使用上面指定的 GPU 型号 * 1。
运行参数:新增运行参数,输入 --listen。
配置访问入口:
Service:勾选“启用”。
服务访问方式:选择公网 LB 访问。
配置端口映射:容器端口设置为7860,服务端口设置为7860。
其他参数:保持默认值即可。
4. 确认 Pod 规格,单击创建 Deployment。如按照上述配置,则为:12核44GiB 1×A10*GNV4、实例数量 ~ 1个、配置费用10.14元/小时(具体费用与登录账号有关,此处为官网刊例价)。
5. 启动部署后,返回工作负载 > Deployment 页面,可查看到正在部署的工作负载。因镜像体积较大,预计需要一定时间才能完成部署。当“运行/期望 Pod 数量”变为“1/1”时,即说明完成部署。也可以进入工作负载内,通过事件查看部署日志。
访问 Stable Diffusion WebUI 体验极速出图
1. 在集群左侧导航中选择服务与路由 > Service,查看与工作负载名称一致的 Service,复制访问入口的公网 IP,如 175.xx.xxx.174。
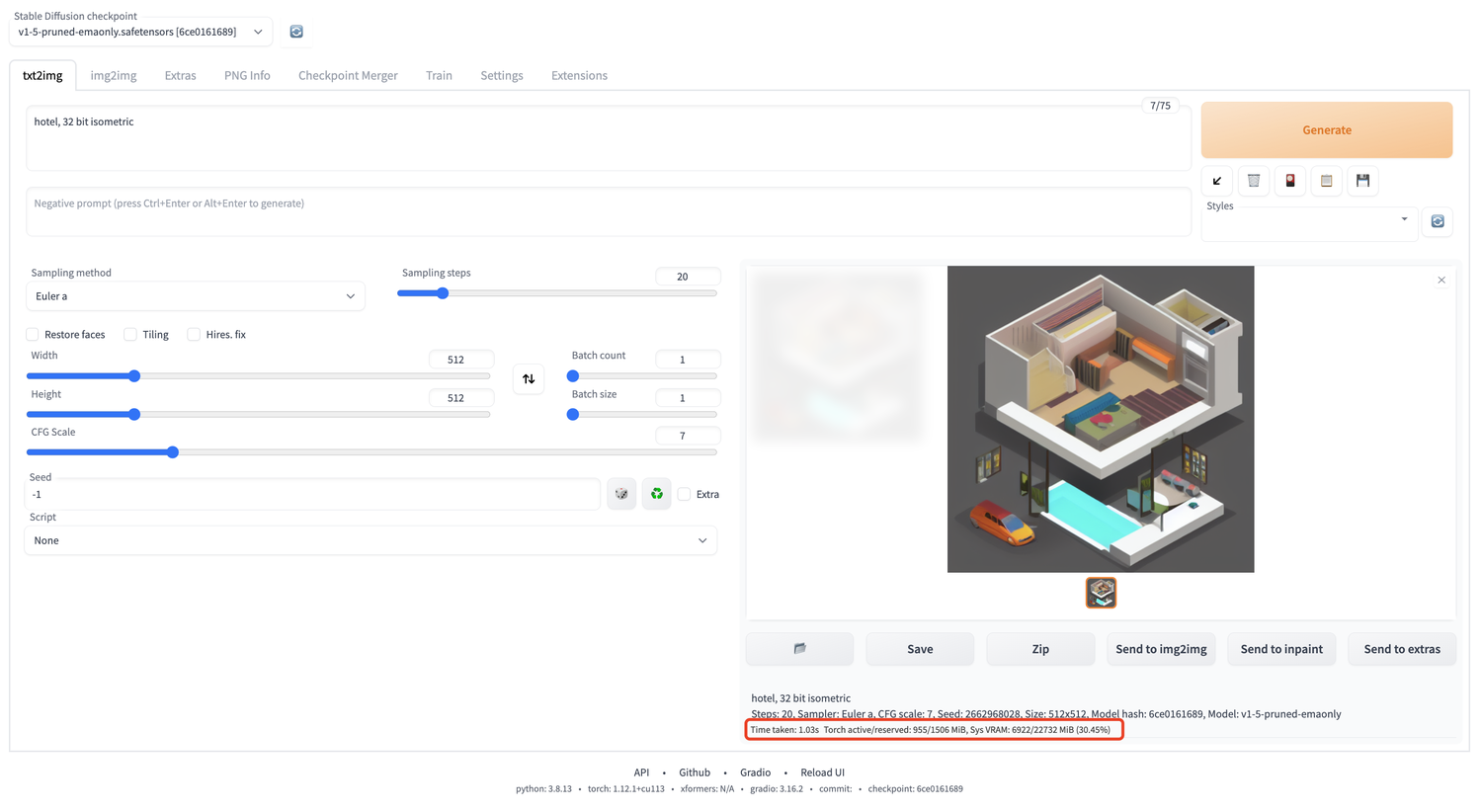
2. 打开浏览器,输入http:\\175.xx.xxx.174:7860(替换为实际 IP),即可进入 Stable Diffusion WebUI。
3. 输入 Prompt,单击 Generate,即可体验一秒出图的功能。
随时调整服务状态,按需使用,按秒付费
相对于直接使用 GPU 服务器,超级节点底层基于 Serverless 容器技术,支持缩容至0,停止计费。您可以根据实际使用需求,随时调整服务状态,降低使用费用。具体操作步骤如下:
1. 在集群左侧导航中选择工作负载 > Deployment,在 stable-diffusion 工作负载对应操作中选择更新 Pod 数量。
2. 在更新 Pod 数量页面,
暂停服务:将 Pod 实例数量调整为0,对应 GPU 资源自动销毁,停止计费。
恢复服务:将 Pod 实例数量调整为1~N,无需重新配置,实例自动重新部署,开始计费。
相关文档
TKE Serverless - 新建集群
TKE Serverless - 工作负载管理
